您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章将为大家详细讲解有关常见优化器的PyTorch实现是怎样的,文章内容质量较高,因此小编分享给大家做个参考,希望大家阅读完这篇文章后对相关知识有一定的了解。
这里主要讲不同常见优化器代码的实现,以及在一个小数据集上做一个简单的比较。
其中,SGD和SGDM,还有Adam是pytorch自带的优化器,而RAdam是最近提出的一个说是Adam更强的优化器,但是一般情况下真正的大佬还在用SGDM来做优化器。
导入必要库:
import torchimport torch.nn as nnimport torch.nn.functional as Fimport torch.optim as optimimport matplotlib.pyplot as pltimport torch.utils.data as Datafrom torch.optim.optimizer import Optimizerimport math
主程序部分:
LR = 0.01BATCH_SIZE = 32EPOCH = 12# fake datasetx = torch.unsqueeze(torch.linspace(-1, 1, 300), dim=1)y = x.pow(2) + 0.1 * torch.normal(torch.zeros(*x.size()))torch_dataset = Data.TensorDataset(x, y)loader = Data.DataLoader(dataset=torch_dataset,batch_size=BATCH_SIZE,shuffle=True,num_workers=2)class Net(nn.Module):def __init__(self):super(Net, self).__init__()self.hidden = nn.Linear(1, 20)self.prediction = nn.Linear(20, 1)def forward(self, x):x = F.relu(self.hidden(x))x = self.prediction(x)return xdef main():net_SGD = Net()net_Momentum = Net()net_Adam = Net()net_RAdam = Net()nets = [net_SGD, net_Momentum, net_Adam, net_RAdam]opt_SGD = optim.SGD(net_SGD.parameters(), lr=LR)opt_Momentum = optim.SGD(net_Momentum.parameters(), lr=LR, momentum=0.9)opt_Adam = optim.Adam(net_Adam.parameters(), lr=LR, betas=(0.9, 0.99))opt_RAdam = RAdam(net_RAdam.parameters(),lr=LR,weight_decay=0)optimizers = [opt_SGD, opt_Momentum, opt_Adam, opt_RAdam]loss_func = nn.MSELoss()losses_his = [[], [], [], []]# trainingfor epoch in range(EPOCH):print('EPOCH:', epoch)for step, (batch_x, batch_y) in enumerate(loader):b_x = batch_xb_y = batch_yfor net, opt, l_his in zip(nets, optimizers, losses_his):out = net(b_x)loss = loss_func(out, b_y)opt.zero_grad()loss.backward()opt.step()l_his.append(loss.item())labels = ['SGD', 'Momentum', 'Adam','RAdam']for i, l_his in enumerate(losses_his):plt.plot(l_his, label=labels[i])plt.legend(loc='best')plt.xlabel('Steps')plt.ylabel('Loss')plt.ylim((0, 0.2))plt.show()if __name__ == '__main__':main()
下图是优化器的对比:
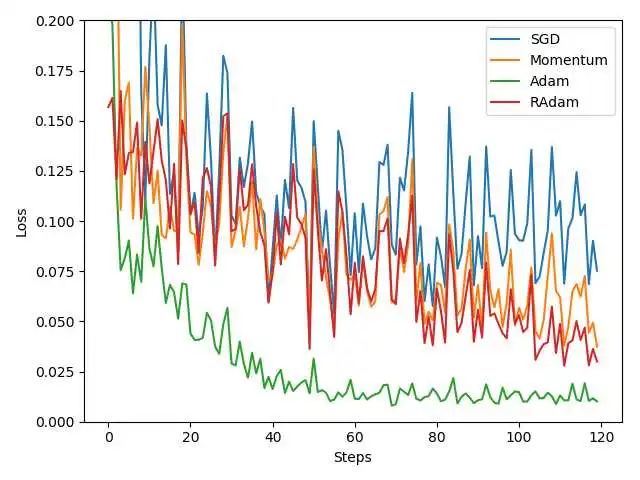
可以看出来,Adam的效果可以说是非常好的。然后SGDM其次,SGDM是大佬们经常会使用的,所以在这里虽然看起来SGDM效果不如Adam,但是依然推荐在项目中,尝试一下SGDM的效果。
关于常见优化器的PyTorch实现是怎样的就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。