您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
如何理解Spark Streaming实现,针对这个问题,这篇文章详细介绍了相对应的分析和解答,希望可以帮助更多想解决这个问题的小伙伴找到更简单易行的方法。
要说流式微批处理类似Spark Streaming,就不得不说一下TCP流。典型的tcp IO流模型有,bio,伪异步IO,NIO,AIO,Rector模型等。我们这里主要是说伪异步IO。
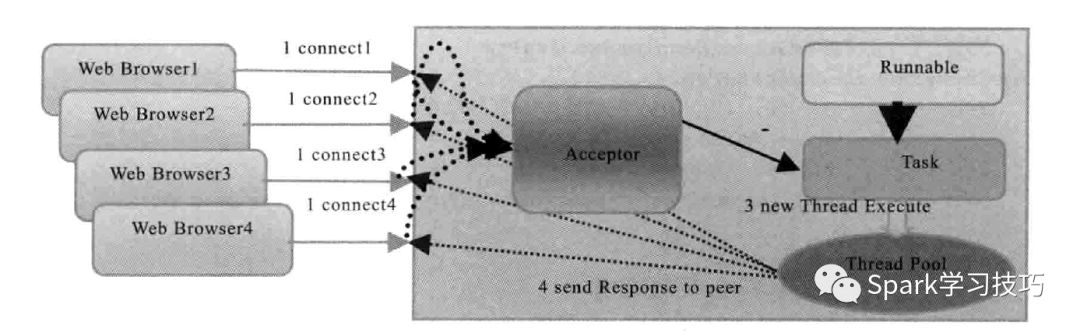
下面浪尖带领一步步将其改造成spark Streaming的 SocketStream。
在伪异步模式,我们是客户端通过TCP链接到服务端。这种在分布式模式下不可行,对于Spark Streaming的微批处理,我们根本不知道Receiver运行在何处。所以,客户端链接都不知道请求到何处,当然,我们也可以做一个复杂的操作来报告我们Receiver的位置。所以,第一步要修改的是将我们的后端改为TCP的client端,然后是client主动链接于外部数据中心也即server端,去拉去或者被push数据。
然后,在上一步改装之后,我们的模型就可能变成如下模式:
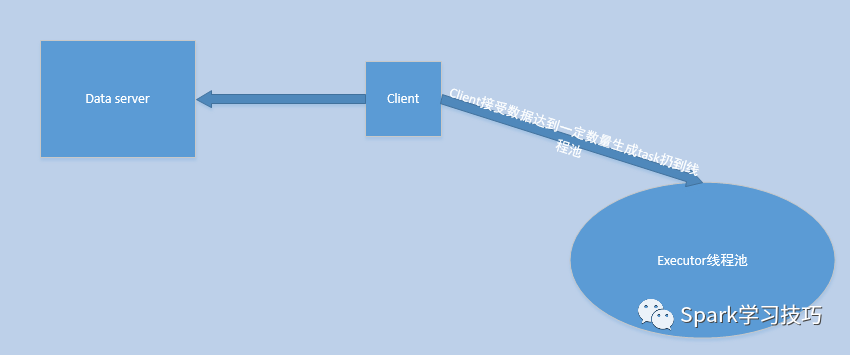
也即,client主动去data server建立连接请求,然后开始接收数据,接收数据达到一定的数目,比如1000条(也要有超时机制),然后封装成task扔到线程池中执行。
当然,我们可以对他进行进一步完善,比如,一个线程专门负责接收数据,然后将数据缓存到map或者 Array里,我们在启动一个RecurringTimer也即一个定时线程,每隔一定毫秒,比如200ms,将map或者Array里面的数据封装成一个数据块叫做block,存储于一个内存的Array,然后用一个后台线程阻塞的消费Array中的block并将block存储于一个数据管理器里,比如叫做blockmanager。此时我们再用一个RecurringTimer用来每隔一定时间,如batch=5s,生成一个task,task中有task自身要处理的数据的描述信息,然后放入线程池中去执行,在执行的时候根据数据的描述信息去取0-n个block然后处理。
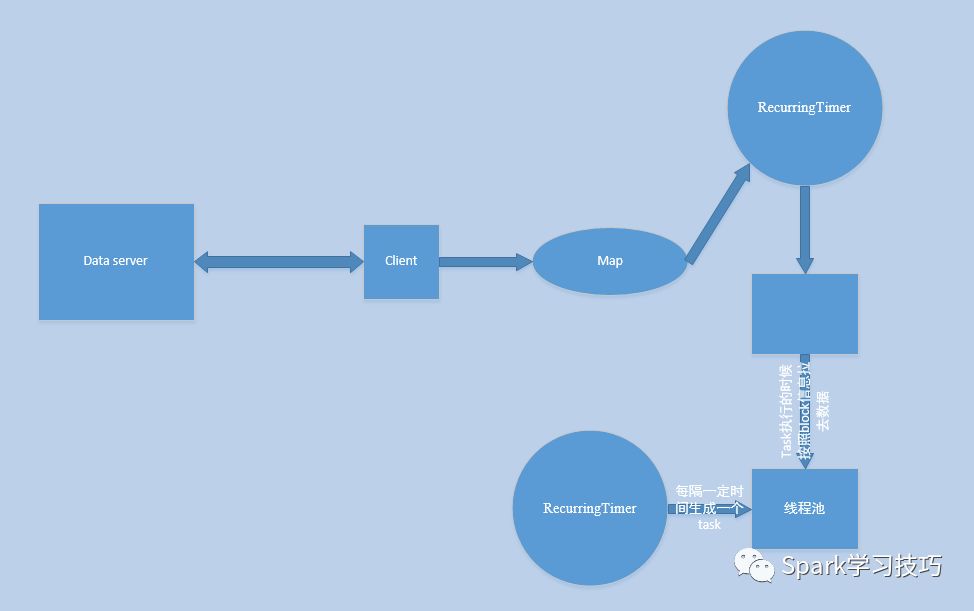
其实,上述步骤和spark Streaming基于Receiver这种模式很类似。
Spark Streaming在执行任务之前必须要先完成receiver的调度启动,过程类似spark core的job调度执行。所以在receiver模式下,给executor分配core的时候,也要考虑receiver会占用一个cpu的。
receiver启动后,其功能就像前面的说的伪异步IO模型一样。由Receiver来完成数据收集缓存,然后定时器线程完成block生成并存储于blockmanager的过程。
除了block数据生成,Spark Streaming还有一个spark core任务生成的过程。spark Streaming来说在生成job的时候,实际上是根据当前批次的数据block信息(由于窗口的存在也可能是批次的若干倍),封装成了一个叫做BlockRDD的对象,blockrdd的分区数就是block数,然后就可以根据我们的Spark core的计算方式执行计算操作了,在每个分区生成的task根据其对应的blockid去取对应的block,实际上对于BlockRDD每个block对应与一个partition。
当然了,有些人该问了,spark Streaming不是还可以不基于Receiver么,另一种方式是什么情况呢?
在讨论这个问题之前,我们先谈另一个问题,那就是:有些数据源,比如kafka,数据本身是有分区的概念,而且可以使用offset灵活的获取数据,也即是我们可以通过控制请求偏移,随便去请求我们想要的数据。对于这种数据源,我们完全没必要先把数据取回来存储于blockmanager,然后再从blockmanager里面取出来再去处理(请注意这里先暂时忽略预写日志),这明显很浪费性能。网络IO流这种,由于数据不能像kafka那样存储与本地,然后随意取数据,只能先存下来再处理了。其实基于receiver的形式,才是Spark streaming的最多场景。
针对kafka这种消息队列出现了一个模式那就是direct模式。也即是我们不用Receiver,生成block,然后构建blockRDD,每个Block当成一个partition;而是在生成job的时候,根据offset信息构建一个叫做KafkaRDD的对象,kafkaRDD里面分区的概念是与kafka内部topic分区一一对应的。然后,再执行spark core的job,计算每个分区生成的task时候,根据KafkaRDD内部的信息去kafka里面具体取数据。
可以看出direct这里面少了,Receiver相关的内容,不需要预写日志,不需要数据来回落地等。提升了很大的性能。
关于如何理解Spark Streaming实现问题的解答就分享到这里了,希望以上内容可以对大家有一定的帮助,如果你还有很多疑惑没有解开,可以关注亿速云行业资讯频道了解更多相关知识。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。