这篇文章主要介绍“spark 3.0 sql的动态分区裁剪机制的具体使用过程”,在日常操作中,相信很多人在spark 3.0 sql的动态分区裁剪机制的具体使用过程问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”spark 3.0 sql的动态分区裁剪机制的具体使用过程”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
本文主要讲讲,spark 3.0之后引入的动态分区裁剪机制,这个会大大提升应用的性能,尤其是在bi等场景下,存在大量的where条件操作。
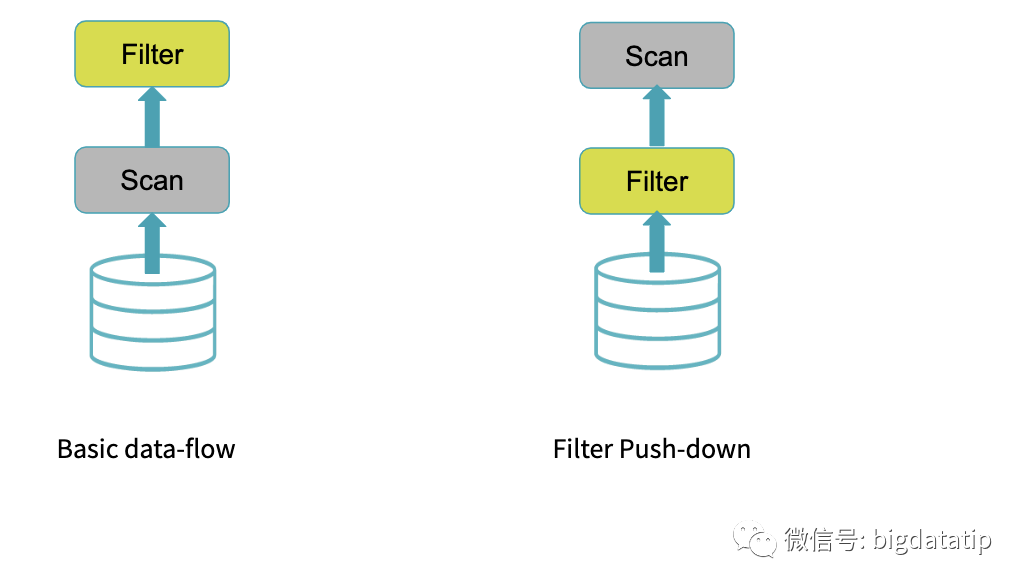
动态分区裁剪比谓词下推更复杂点,因为他会整合维表的过滤条件,生成filterset,然后用于事实表的过滤,从而减少join。当然,假设数据源能直接下推执行就更好了,下推到数据源处,是需要有索引和预计算类似的内容。
SELECT * FROM Sales WHERE day_of_week = ‘Mon’
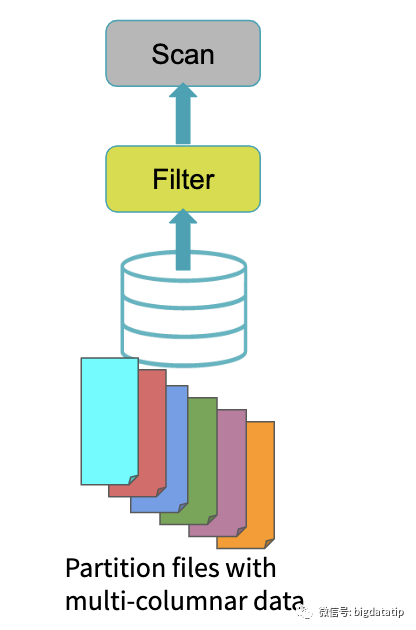
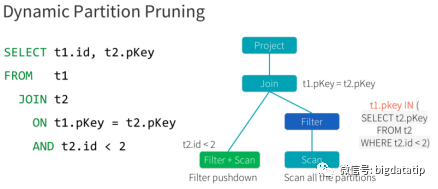
假如表按照day_of_week字段分区,那sql应该是将filter下推,先过滤,然后在scan。这就是传统数据库存在索引及预计算的时候所说的谓词下推执行。Spark 3.0的分区裁剪的场景主要是基于谓词下推执行filter(动态生成),然后应用于事实表和维表join的场景。如果存在分区表和维表上的filter,则通过添加dynamic-partition-pruning filter来实现对另一张表的动态分区修剪。有下面一个简单的sql,完成的功能是事实表(sales)和维表(Date)的join:
SELECT * FROM Sales JOIN Date WHERE Date.day_of_week = ‘Mon’;
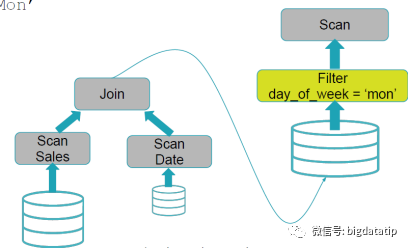
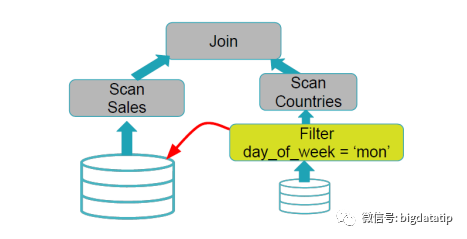
假如不存在任何下推执行的优化,执行过程就应该如下图:
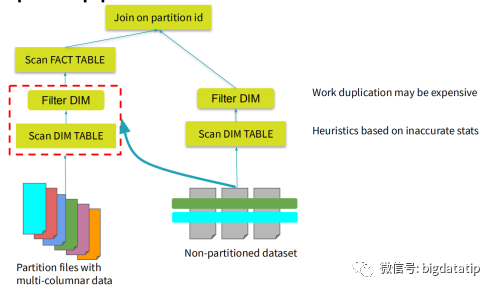
上图就是不存在任何谓词下推执行优化的计算过程,全量扫描事实表sales和维表date表,然后完成join,生成的表基础上进行filter操作,然后再scan计算,显然这样做很浪费性能。
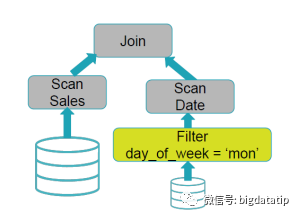
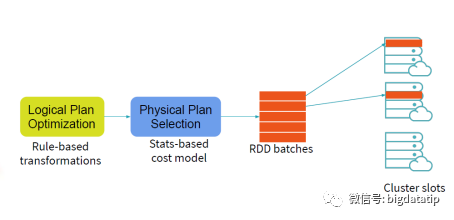
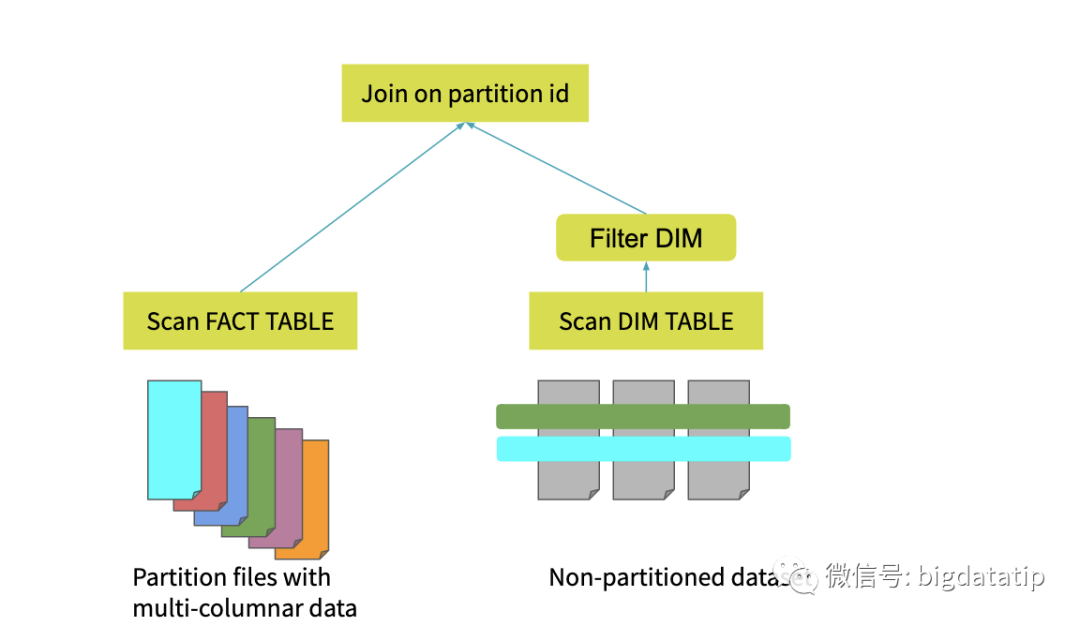
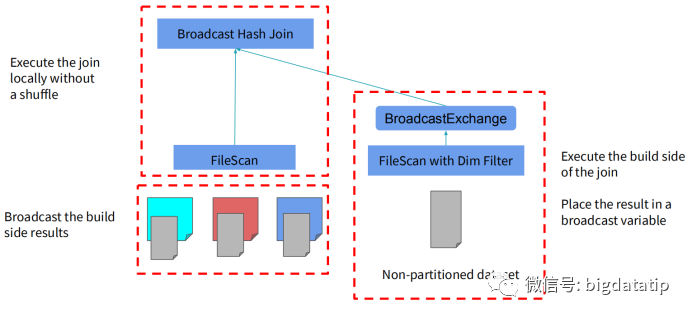
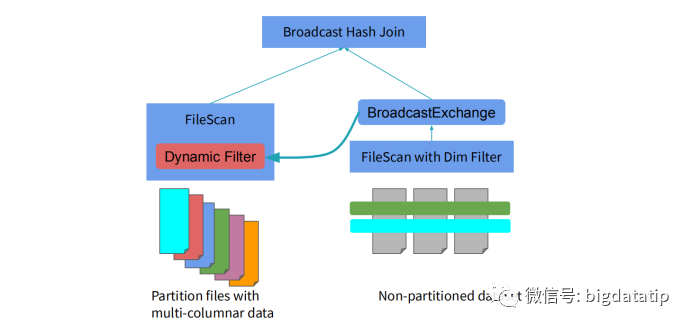
假如维表支持下推执行,那么就可以先进行维表的filter操作,减少维表Date的数据量加载,然后在进行事实表sales的scan和维表date的scan,最后进行join操作。想一想,由于where条件的filter是维表Date的,spark读取事实表的时候也是需要使用扫描的全表数据来和维表Date实现join,这就大大增加了计算量。假如能进一步优化,通过维表date的filter,生成一个新的事实表的salesFilterSet,应用到事实表sales,那么就可以大大减少join计算性能消耗。也即是这个样子:表t1和t2进行join,为了减少参加join计算的数据量,就为t1表计算(上图右侧sql)生成了一个filter数据集,然后再扫描之后过滤。当然,这个就要权衡一下,filter数据集生成的子查询及保存的性能消耗,与对数据过滤对join的性能优化的对比了,这就要讲到spark sql的优化模型了。spark sql 是如何实现sql优化操作的呢?现在sql解析的过程中完成sql语法优化,然后再根据统计代价模型来进行动态执行优化。逻辑执行计划的优化都是静态的,物理计划的选择可以基于统计代价模型来计算动态选择。下图是一个基于分区ID的join实现。维表的数据是没有分区的,事实表的数据是分区的。假如没有动态分区裁剪,那么完成的执行过程就如图所示。事实表和维表都需要全表扫描,然后对维表执行filter操作,最后再进行join操作。假如对维表的filter操作,进行一些计算然后可以生成事实表的filter set,那么就可以减少维表和事实表join的数据量了。就如前面的t1和t2的join例子一样。
当然,上面的例子要考虑计算和保存事实表的filter set集合的开销是否远小于其减少join数据量的增益,否则就得不偿失了。还有一种join大家都比较熟悉,那就是Broadcast Hash Join。这种主要是重用广播的结果,来实现filter功能。这个的理解要基于BroadcastExchangeExec。后面出文章详细聊吧。至于效果码,可以关注浪尖微信公众号:bigdatatip。然后输入 :dpp 获取完整的ppt。
到此,关于“spark 3.0 sql的动态分区裁剪机制的具体使用过程”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!