жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
еҰӮдҪ•еҲ©з”ЁscrapyиҝӣиЎҢе…«еҚғдёҮз”ЁжҲ·ж•°жҚ®зҲ¬еҸ–дёҺдјҳеҢ–пјҢзӣёдҝЎеҫҲеӨҡжІЎжңүз»ҸйӘҢзҡ„дәәеҜ№жӯӨжқҹжүӢж— зӯ–пјҢдёәжӯӨжң¬ж–ҮжҖ»з»“дәҶй—®йўҳеҮәзҺ°зҡ„еҺҹеӣ е’Ңи§ЈеҶіж–№жі•пјҢйҖҡиҝҮиҝҷзҜҮж–Үз« еёҢжңӣдҪ иғҪи§ЈеҶіиҝҷдёӘй—®йўҳгҖӮ
жңҖиҝ‘еҮҶеӨҮжҠҠж•°жҚ®еҲҶжһҗиҝҷеқ—иЎҘдёҖдёӢпјҢеҠ дёҠдёҖзӣҙеңЁеҗ¬е–ң马жӢүйӣ…зҡ„зӣҙж’ӯпјҢжңүдёҖдёӘжҜ”иҫғе–ңж¬ўзҡ„дё»ж’ӯпјҢзӘҒ然иҗҢз”ҹдәҶзҲ¬еҸ–е–ң马жӢүйӣ…жүҖжңүдё»ж’ӯдҝЎжҒҜд»ҘеҸҠжү“иөҸдҝЎжҒҜпјҢжқҘжүҫдёҖжүҫе–ң马жӢүйӣ…дёҠжҜ”иҫғзҒ«зҡ„дё»ж’ӯе’Ңжңүй’ұзҡ„еӨ§е“ҘпјҢзңӢзңӢиҝҷдәӣжңүй’ұдәәжҳҜжҖҺд№ҲжҢҘйңҚзҡ„гҖӮ
жү“ејҖе–ң马жӢүйӣ…зҡ„дё»ж’ӯйЎөйқўпјҢжҹҘзңӢдәәж°”дё»ж’ӯ
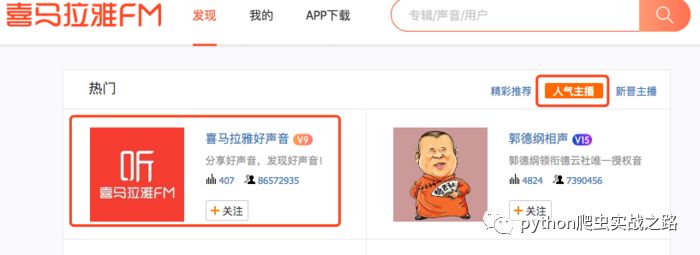
第дёҖдёӘжҳҜе–ң马жӢүйӣ…еҘҪеЈ°йҹіпјҢе®ҳж–№зҡ„иҙҰеҸ·пјҢеҫҲеӨҡдәәзҡ„е–ң马жӢүйӣ…иҙҰеҸ·еә”иҜҘдјҡй»ҳи®Өе…іжіЁиҝҷдёӘгҖӮжҲ‘们зңӢеҲ°зІүдёқе…іжіЁж•°жңүе…«еҚғеӨҡдёҮпјҢе®һйҷ…зҡ„е–ң马жӢүйӣ…з”ЁжҲ·йҮҸиӮҜе®ҡи¶…иҝҮиҝҷдёӘж•°еҖјпјҢжҲ‘们жҡӮдё”дј°и®ЎеҸҜзҲ¬еҸ–ж•°йҮҸдёәдёҖдәҝпјҢдё»ж’ӯйЎөйқўеҸӘжҳҫзӨәдә”50йЎөпјҢжҜҸйЎө20дёӘз”ЁжҲ·пјҢжҲ‘зҡ„жҖқи·ҜжҳҜзҲ¬еҸ–жҳҫзӨәзҡ„дё»ж’ӯдҝЎжҒҜпјҢиҝӣе…Ҙдё»ж’ӯдё»йЎө
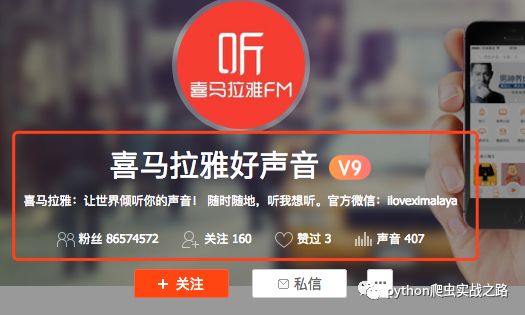
зҲ¬еҸ–зӣёе…ідҝЎжҒҜпјҢ然еҗҺжҹҘзңӢзІүдёқдҝЎжҒҜ

зІүдёқйЎөеҸӘжҳҫзӨә10йЎөпјҢжҜҸйЎө10дёӘз”ЁжҲ·гҖӮиҷҪ然зңӢиө·жқҘдёҚеӨҡпјҢдҪҶжҳҜжҲ‘们еҸҜд»ҘиҝӣиЎҢжү©еұ•пјҢжҜҸдёӘзІүдёқзӮ№иҝӣеҺ»еҗҺеҸҲжҳҜдёҖдёӘз”ЁжҲ·дё»йЎөпјҢеҸҲеҸҜд»ҘзҲ¬еҸ–д»–зҡ„зІүдёқдҝЎжҒҜгҖӮе°ұиҝҷж ·дёҖзӣҙиҝӣиЎҢжү©еұ•пјҢ然еҗҺдҪҝз”ЁеҺ»йҮҚеӨ„зҗҶпјҢиҝҮж»Өе·Із»ҸзҲ¬еҸ–иҝҮзҡ„з”ЁжҲ·ж•°жҚ®гҖӮ
жҲ‘们иҰҒзҲ¬еҸ–зҡ„ж•°жҚ®пјҡз”ЁжҲ·еҗҚгҖҒз®Җд»ӢгҖҒзІүдёқж•°гҖҒе…іжіЁж•°гҖҒеЈ°йҹігҖҒдё“иҫ‘ж•°гҖӮ
еҸҰеӨ–иҝҳжңүиөһиөҸдҝЎжҒҜйңҖиҰҒйҖҡиҝҮAPPжҠ“еҸ–пјҢжҲ‘们е…ҲжҠ“з”ЁжҲ·дҝЎжҒҜеҗ§гҖӮ
иҝҷд№ҲеӨ§йҮҸзҡ„ж•°жҚ®зҲ¬еҸ–пјҢдјҳз§Җзҡ„жЎҶжһ¶жҳҜеҝ…дёҚеҸҜе°‘зҡ„пјҢжҲ‘们е°ұдҪҝз”ЁеӨ§еҗҚйјҺйјҺзҡ„scrapyжЎҶжһ¶дёәеҹәзЎҖжқҘиҝӣиЎҢзҲ¬еҸ–гҖӮеҸҰеӨ–еҲҶеёғејҸзҲ¬еҸ–д№ҹжҳҜеҝ…дёҚеҸҜе°‘пјҢиҷҪ然жҲ‘жІЎжңүйӮЈд№ҲеӨҡжңәеҷЁеҺ»еҒҡпјҢдҪҶжҳҜжҲ‘зҗўзЈЁдәҶдёҖдёӢпјҢзҷҫеәҰдә‘гҖҒйҳҝйҮҢдә‘гҖҒи…ҫи®Ҝдә‘гҖҒеҚҺдёәдә‘зӯүдёҖзі»еҲ—дә‘жңҚеҠЎеҷЁж–°з”ЁжҲ·йғҪжңүеҮ еӨ©иҜ•з”ЁжңҹпјҢиҝҷйӣҶзҫӨжңәеҷЁдёҚе°ұжңүдәҶеҗ—пјҹеҳҝеҳҝ

ж•°жҚ®еә“жҲ‘们дҪҝз”ЁMongoDBпјҢеӣ дёәжҲ‘们зҡ„ж•°жҚ®е№¶дёҚиҰҒжұӮеӨҡзІҫзЎ®гҖӮRedisиӮҜе®ҡжҳҜеҝ…йҖүдәҶгҖӮдҪҶжҳҜдҪңдёәеҶ…еӯҳж•°жҚ®еә“пјҢеҚ з”ЁеҶ…еӯҳзҡ„еӨ§е°Ҹиҝҷе°ұжҳҜжҲ‘们еҝ…йЎ»иҰҒиҖғиҷ‘зҡ„гҖӮжҲ‘们зҡ„еҺ»йҮҚиҝҮж»ӨйғҪжҳҜж”ҫеңЁredisдёӯзҡ„пјҢжүҖд»Ҙеҝ…йЎ»еҜ№йҪҗиҝӣиЎҢдјҳеҢ–гҖӮе…·дҪ“еҺҹеӣ иҜ·зңӢпјҡ
жҲ‘е…ҲеңЁиҮӘе·ұжңәеҷЁдёҠжҠ“еҸ–дәҶйғЁеҲҶж•°жҚ®пјҢжҹҘзңӢredisдёӯзҡ„иҜ·жұӮеҲ—иЎЁе’ҢеҺ»йҮҚеҲ—иЎЁ
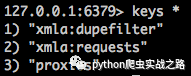

д»ҺиҜ·жұӮеҲ—иЎЁдёӯзҡ„ж•°жҚ®йҮҸеҸҜд»ҘзҹҘйҒ“дёӢиҪҪиҝҳжҳҜжҜ”иҫғж…ўзҡ„пјҢиҝҷе°ұжҳҜдёәд»Җд№ҲжҲ‘们иҰҒз”ЁеҲҶеёғејҸиҝӣиЎҢзҲ¬еҸ–дәҶгҖӮ然еҗҺеҶҚзңӢеҺ»йҮҚж•°жҚ®пјҢдёғеҚҒдә”дёҮжқЎгҖӮдёҚеӨ§зҡ„ж•°жҚ®йҮҸпјҢдҪҶжҳҜзңӢдёӢеҶ…еӯҳеҚ з”Ёжғ…еҶөгҖӮ


жү§иЎҢеҲ йҷӨиҜӯеҸҘflushallеҗҺпјҢеҶҚжҹҘзңӢеҶ…еӯҳдҪҝз”Ёжғ…еҶө
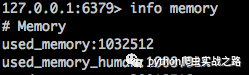

еңЁжҲ‘8GеҶ…еӯҳзҡ„MacдёҠеҚ з”Ё260Mзҡ„еҶ…еӯҳеҸҜд»ҘеҝҚеҸ—пјҢдҪҶжҳҜеңЁжҲ‘йӮЈеҸҜжҖңзҡ„еҸӘжңү1Gзҡ„дә‘жңҚеҠЎеҷЁдёҠпјҢеҚЎеҲ°жҲ‘йғҪеҝ«й“ҫжҺҘдёҚдёҠдәҶпјҢжҲ‘们еҸҜжҳҜд»Ҙе…«еҚғдёҮж•°жҚ®дёәзӣ®ж Үзҡ„пјҢе®һйҷ…жүҚзҲ¬еҸ–дәҶдәҢеҚҒеӨҡдёҮжқЎжңүж•Ҳж•°жҚ®пјҢеҺ»йҮҚи®°еҪ•йғҪдёғеҚҒеӨҡдёҮдәҶпјҢеҰӮжһңеҲ°дәҶдёҖдәҝжқЎж•°жҚ®пјҢд»Ҙзӣ®еүҚзҡ„жғ…еҶөжқҘзңӢпјҢеҚЎзҲҶжңҚеҠЎеҷЁд№ҹеҲ°дёҚдәҶгҖӮ
жң¬жқҘиҝҳжңүдёҖдёӘxmla:itemsз»“жһ„пјҢеӯҳеӮЁжҲ‘们зҡ„жҠ“еҸ–ж•°жҚ®пјҢжҲ‘жҠҠе®ғжҸҗеҸ–еҲ°дәҶMongoDBеҪ“дёӯгҖӮxmla:requestsдёӯжҳҜеҫ…зҲ¬еҸ–иҜ·жұӮеҲ—иЎЁпјҢжҲ‘们зҲ¬еҸ–дёӢиҪҪзҡ„ж—¶еҖҷиҝҷдёӘж•°жҚ®йҮҸиҝҳжҳҜдјҡйҖҗжёҗеҮҸе°‘зҡ„пјҢиҮіе°‘дёҚдјҡж— йҷҗеўһеӨ§гҖӮдҪҶжҳҜиҝҷдёӘxmla:dupefilterдёӯеӯҳеҸ–зҡ„жҳҜеҺ»йҮҚж•°жҚ®пјҢжҜҸдёҖж¬ЎиҜ·жұӮйғҪдјҡи®°еҪ•дёӢжқҘпјҢжүҖд»ҘиҝҷдёӘж•°жҚ®еҸӘдјҡйҡҸзқҖжҲ‘们зҡ„зҲ¬еҸ–дёҖзӣҙеўһеӨ§гҖӮйӮЈд№Ҳиҝҷе°ұжҳҜжҲ‘们иҰҒиҝӣиЎҢдјҳеҢ–зҡ„йҮҚзӮ№гҖӮ
дёӢйқўжҲ‘们жқҘ规еҲ’дёҖдёӢдёӢжқҘиҰҒеҒҡзҡ„дәӢжғ…пјҢжҢүжӯҘйӘӨжқҘпјҡ
dockerзҺҜеўғе®үиЈ…йғЁзҪІ
redisйӣҶзҫӨй…ҚзҪ®ж“ҚдҪң
з”ЁжҲ·ж•°жҚ®жҠ“еҸ–жөҒзЁӢеҲҶжһҗ
з”ЁжҲ·жү“иөҸдҝЎжҒҜжҠ“еҸ–жөҒзЁӢеҲҶжһҗ
дҪҝз”ЁBloomFilterдҝ®ж”№scrapy-redisпјҢеҮҸе°‘иҝҮж»ӨеҶ…еӯҳеҚ з”Ё
еҸҚзҲ¬еӨ„зҗҶпјҡIPд»ЈзҗҶжұ гҖҒUser-Agentжұ
дҪҝз”ЁGerapyе’ҢdockerйғЁзҪІеҲҶеёғејҸзҺҜеўғ
жҠ“еҸ–ж•°жҚ®жё…зҗҶпјҢж•°жҚ®еҲҶжһҗ规еҲ’
зңӢе®ҢдёҠиҝ°еҶ…е®№пјҢдҪ 们жҺҢжҸЎеҰӮдҪ•еҲ©з”ЁscrapyиҝӣиЎҢе…«еҚғдёҮз”ЁжҲ·ж•°жҚ®зҲ¬еҸ–дёҺдјҳеҢ–зҡ„ж–№жі•дәҶеҗ—пјҹеҰӮжһңиҝҳжғіеӯҰеҲ°жӣҙеӨҡжҠҖиғҪжҲ–жғідәҶи§ЈжӣҙеӨҡзӣёе…іеҶ…е®№пјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ