您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
第一部分:准备Linux环境
创建虚拟机安装系统的步骤在这里就不讲了,详细步骤请看本人其他文章
打开建好的虚拟机
一、修改Hostname
1、 临时修改hostname
hostname bigdata-01.liu.com
这种修改方式,系统重启后就会失效
2、 永久修改hostname
vim /etc/sysconfig/network
打开后编辑如下内容
NETWORKING=yes #使用网络
HOSTNAME=bigdata-01.liu.com #设置主机名
二、配置Host
vim /etc/hosts
添加如下内容
172.18.74.172 bigdata-01.liu.com
三、关闭防火墙
查看防火墙状态
service iptables status
临时关闭防火墙
service iptables stop
永久关闭防火墙(需要重启才能生效)
chkconfig iptables off
四、关闭selinux
selinux是Linux一个子安全机制,学习环境可以将它禁用
vim /etc/sysconfig/selinux
把SELINUX设置成disabled
SELINUX=disabled
五、安装JDK
检测系统是否安装jdk
java -version
如果显示有openjdk需要先卸载,再安装Oracle的jdk(其他版本的jdk对hadoop的一些命令不是很支持)
rpm -qa | grep java
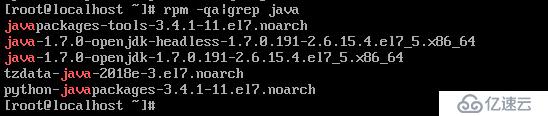
卸载openjdk,.noarch的文件可以不用删除
rpm -e --nodeps java-1.7.0-openjdk-headless-1.7.0.191-2.6.15.4.e17_5.x86_64
rpm -e --nodeps java-1.7.0-openjdk-1.7.0.191-2.6.15.4.e17_5.x86_64
然后再次使用rpm -qa | grep java 查看是否已经卸载openjdk,如果还有就再卸载一遍
用xshell远程工具远程虚拟机,安装lrzsz命令
yum -y install lrzsz
导入jdk包并解压到 /opt/modules目录下
rz
tar -zvxf jdk-8u181-linux-x64.tar.gz -C /opt/modules
添加环境变量
设置JDK的环境变量 JAVA_HOME,需要修改配置文件/etc/profile,追加
export JAVA_HOME="/opt/modules/jdk1.8.0_181"
export PATH=$JAVA_HOME/bin:$PATH
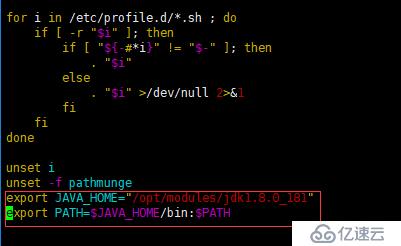
修改完毕后,执行 source /etc/profile 使修改生效
再次执行 java –version,可以看见已经安装完成
第二部分:hadoop安装
完全分部式是真正利用多台Linux主机来进行部署Hadoop,对Linux机器集群进行规划,使得Hadoop各个模块分别部署在不同的多台机器上。
一、环境准备
1.克隆虚拟机
Vmware左侧选中要克隆的机器,这里对原有的BigData01机器进行克隆,虚拟机菜单中,选中管理菜单下的克隆命令。
选择“创建完整克隆”,虚拟机名称为BigData02,选择虚拟机文件保存路径,进行克隆。
再次克隆一个名为BigData03的虚拟机。
2.配置网络
修改网卡名称
在BigData02和BigData03机器上编辑网卡信息。执行sudo vim /etc/udev/rules.d/70-persistent-net.rules命令。因为是从BigData01机器克隆来的,所以会保留BigData01的网卡eth0,并且再添加一个网卡eth2。并且eth0的Mac地址和BigData01的地址是一样的,Mac地址不允许相同,所以要删除eth0,只保留eth2网卡,并且要将eth2改名为eth0。将修改后的eth0的mac地址复制下来,修改network-scripts文件中的HWADDR属性。
vim /etc/sysconfig/network-scripts/ifcfg-eth0
修改网络参数:
BigData02机器IP改为172.18.74.173
BigData03机器IP改为172.18.74.174
!!如果是在真实的服务器里搭建Hadoop环境就需要再建两个虚拟机,按照上面的步骤再来一遍了,服务器里克隆主机不是很理想!!
3.配置Hostname以及hosts
BigData02配置hostname为 bigdata-02.liu.com
BigData03配置hostname为 bigdata-03.liu.com
BigData01、BigData02、BigData03三台机器hosts都配置为:
172.18.74.172 bigdata-01.liu.com
172.18.74.173 bigdata-02.liu.com
172.18.74.174 bigdata-03.liu.com
4.配置Windows上的SSH客户端
在本地Windows中的SSH客户端上添加对BigData02、BigData03机器的SSH链接
二、服务器功能规划
| bigdata-01.liu.com | bigdata-02.liu.com | bigdata-03.liu.com | |
|---|---|---|---|
| NameNode | ResourceManage | SecondaryNameNode | |
| DataNode | DataNode | DataNode | |
| NodeManager | NodeManager | NodeManager | |
| HistoryServer |
三、在第一台机器上安装新的Hadoop
创建hadoop目录
mkdir -p /opt/modules/app
导入Hadoop压缩包并解压到Hadoop目录
rz
tar -zxf /opt/sofeware/hadoop-2.7.4-with-centos-6.7.tar.gz -C /opt/modules/app/
切换到/opt/modules/app/hadoop-2.7.4/etc/hadoop目录,配置该目录下的Hadoop JDK路径即修改hadoop-env.sh、mapred-env.sh、yarn-env.sh文件中的JDK路径:
export JAVA_HOME="/opt/modules/jdk1.8.0_181"
配置core-site.xml
vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata-01.liu.com:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/modules/app/hadoop-2.7.4/data/tmp</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/data</value>
</property>
</configuration>
fs.defaultFS为NameNode的地址。
hadoop.tmp.dir为hadoop临时目录的地址,默认情况下,NameNode和DataNode的数据文件都会存在这个目录下的对应子目录下。应该保证此目录是存在的,如果不存在,先创建。
配置hdfs-site.xml
vim hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>bigdata-03.liu.com:50090</value>
</property>
</configuration>
dfs.namenode.secondary.http-address是指定secondaryNameNode的http访问地址和端口号,因为在规划中,我们将BigData03规划为SecondaryNameNode服务器,所以这里设置:bigdata-03.liu.com:50090
配置slaves
vim slaves
bigdata-01.liu.com
bigdata-02.liu.com
bigdata-03.liu.com
slaves文件是指定HDFS上有哪些DataNode节点
配置yarn-site.xml
vim yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdata-02.liu.com</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>106800</value>
</property>
</configuration>
根据规划yarn.resourcemanager.hostname这个指定resourcemanager服务器指向bigdata-02.liu.com
yarn.log-aggregation-enable是配置是否启用日志聚集功能
yarn.log-aggregation.retain-seconds是配置聚集的日志在HDFS上最多保存多长时间
配置mapred-site.xml
从mapred-site.xml.template复制一个mapred-site.xml文件
cp mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>bigdata-01.liu.com:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>bigdata-01.liu.com:19888</value>
</property>
</configuration>
mapreduce.framework.name设置mapreduce任务运行在yarn上
mapreduce.jobhistory.address是设置mapreduce的历史服务器安装在BigData01机器上
mapreduce.jobhistory.webapp.address是设置历史服务器的web页面地址和端口号
四、设置SSH无密码登录
Hadoop集群中的各个机器间会相互地通过SSH访问,每次访问都输入密码是不现实的,所以要配置各个机器间的SSH是无密码登录的
在BigData01上生成公钥
ssh-keygen -t rsa
一路回车,都设置为默认值,然后再当前用户的Home目录下的.ssh目录中会生成公钥文件(id_rsa.pub)和私钥文件(id_rsa), .ssh是隐藏文件在home目录下ls -a就会显示出来
分发公钥
ssh-copy-id bigdata-01.liu.com
ssh-copy-id bigdata-02.liu.com
ssh-copy-id bigdata-03.liu.com
五、分发Hadoop文件
首先在其他两台机器上创建存放Hadoop的目录
mkdir -p /opt/modules/app
通过Scp分发
du -sh /opt/modules/app/hadoop-2.7.4/share/doc
scp -r /opt/modules/app/hadoop-2.7.4/ bigdata-02.liu.com:/opt/modules/app
scp -r /opt/modules/app/hadoop-2.7.4/ bigdata-03.liu.com:/opt/modules/app
格式NameNode
在NameNode机器bigdata-01上执行格式化:
/opt/modules/app/hadoop-2.7.4/bin/hdfs namenode –format
格式化后在 /opt/modules/app/hadoop-2.7.4/data/tmp/dfs/data/ 目录下会生成一个current目录,里面有一系列文件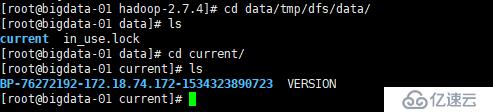
注意:
如果需要重新格式化NameNode,需要先将原来NameNode和DataNode下的文件全部删除,不然会报错,NameNode和DataNode所在的目录是在core-site.xml中hadoop.tmp.dir、dfs.namenode.name.dir、dfs.datanode.data.dir属性里配置的。
因为每次格式化,默认是创建一个集群ID,并写入NameNode和DataNode的VERSION文件中(VERSION文件所在目录为dfs/name/current 和 dfs/data/current),重新格式化时,默认会生成一个新的集群ID,如果不删除原来的目录,会导致namenode中的VERSION文件中是新的集群ID,而DataNode中是旧的集群ID,不一致时会报错。
六、启动集群
切换到/opt/modules/app/hadoop-2.7.4目录下
启动HDFS
/opt/modules/app/hadoop-2.7.4/sbin/start-dfs.sh
jps查看已经启动的服务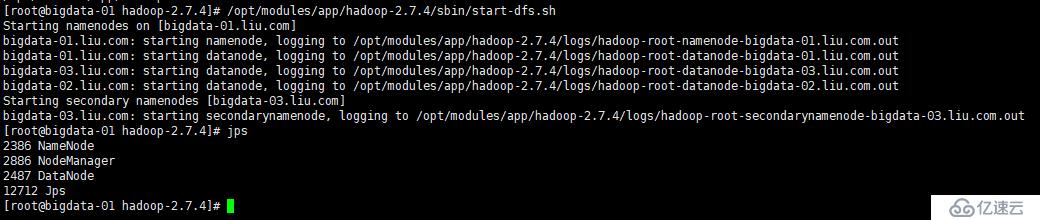
启动YARN
/opt/modules/app/hadoop-2.7.4/sbin/start-yarn.sh

也可以使用这条命令一步到位
/opt/modules/app/hadoop-2.7.4/sbin/start-all.sh
在BigData02上启动ResourceManager:
sbin/yarn-daemon.sh start resourcemanager
启动日志服务器
因为我们规划的是在BigData03服务器上运行MapReduce日志服务,所以要在BigData03上启动
/opt/modules/app/hadoop-2.7.4/sbin/mr-jobhistory-daemon.sh start historyserver

查看HDFS Web页面
http://bigdata-01.liu.com:50070/
如果域名没有解析可以在搜索栏中输入ip+端口如:
172.18.74.172:50070

查看YARN Web 页面
http://bigdata-02.liu.com:8088/cluster
172.18.74.173:8088/cluster
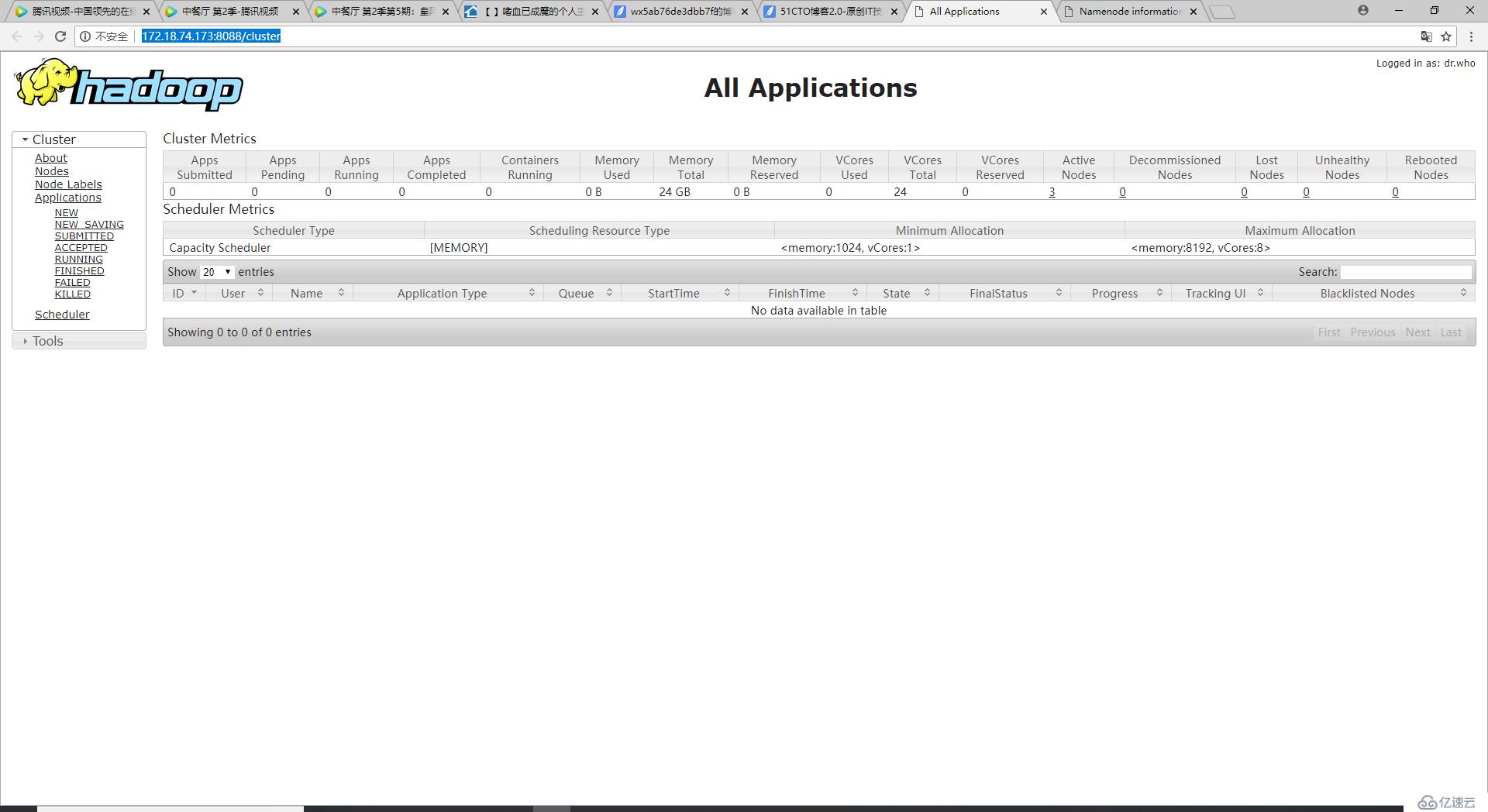
好啦,到这里Hadoop集群环境的搭建就完成啦。建议Ha友们搭建Hadoop环境时先去了解一下各个组件是什么这样更有利于你顺利的完成Hadoop环境的搭建,我的一些同学他们学这个比较早,那时候也没人了解Hadoop是什么,听他们说搭建了10天半个月的才搭建出来,我就是在他们的影响下逐渐了解了点Hadoop的知识,用了一天多的时间搭建好了,搭建过程中还遇到了不少突发情况,所以如果搭建过程中没有什么意外情况再加上提前了解过,半天就能搞定了,千万不要遇到困难就放弃,坚持一定会胜利的!!
。。。从前车马很慢,书信很远,一生只够爱一个人!!!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。