您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章将为大家详细讲解有关如何进行EMR Spark-SQL性能极致优化的分析,文章内容质量较高,因此小编分享给大家做个参考,希望大家阅读完这篇文章后对相关知识有一定的了解。
从上述的 TPCDS Perf 链接中,我们可以看到,其实 EMR 团队在 10TB 规模总共提交了三次成绩。第三次也就是这一次打榜,背后还有一个小故事。因为在 Perf 页面中,最终 TPCDS 关注的指标有两个,一个是性能指标一个是性价比指标。这次项目立项的时候,我们就给自己立下了一个艰难的 Flag ,我们要在物理硬件保持不变的条件下,纯靠软件优化提升 2 倍+,这样子性能指标和性价比指标就都能翻倍了。
在提交完成绩后,我们用开源 Spark V2.4.3 版本进行了 TPCDS 99 Query 测试,以下是性能数据对比
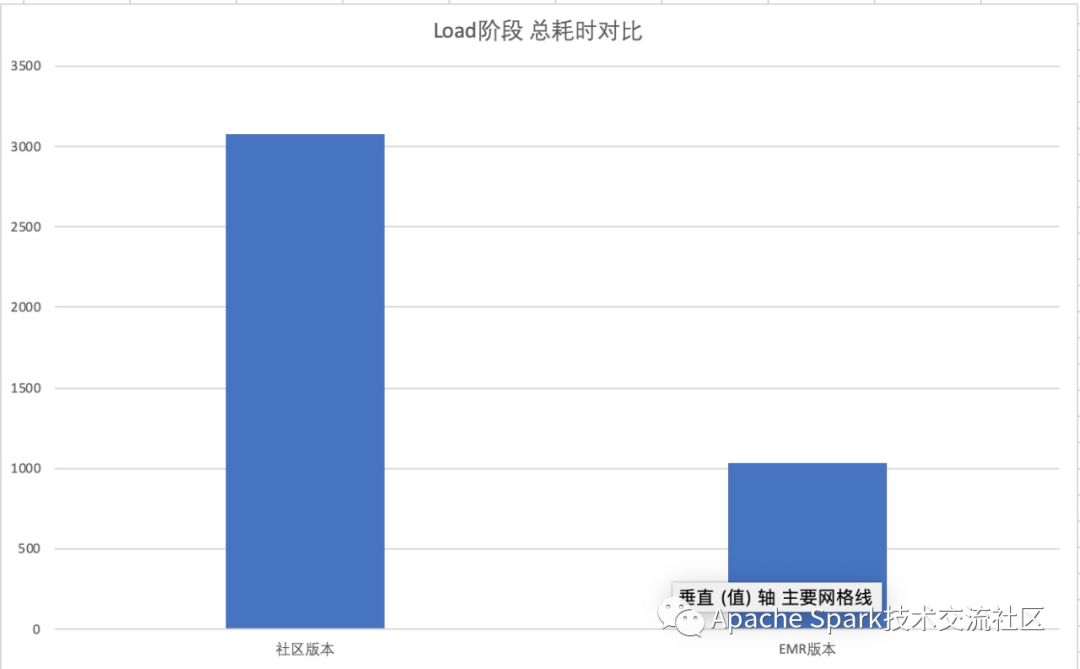
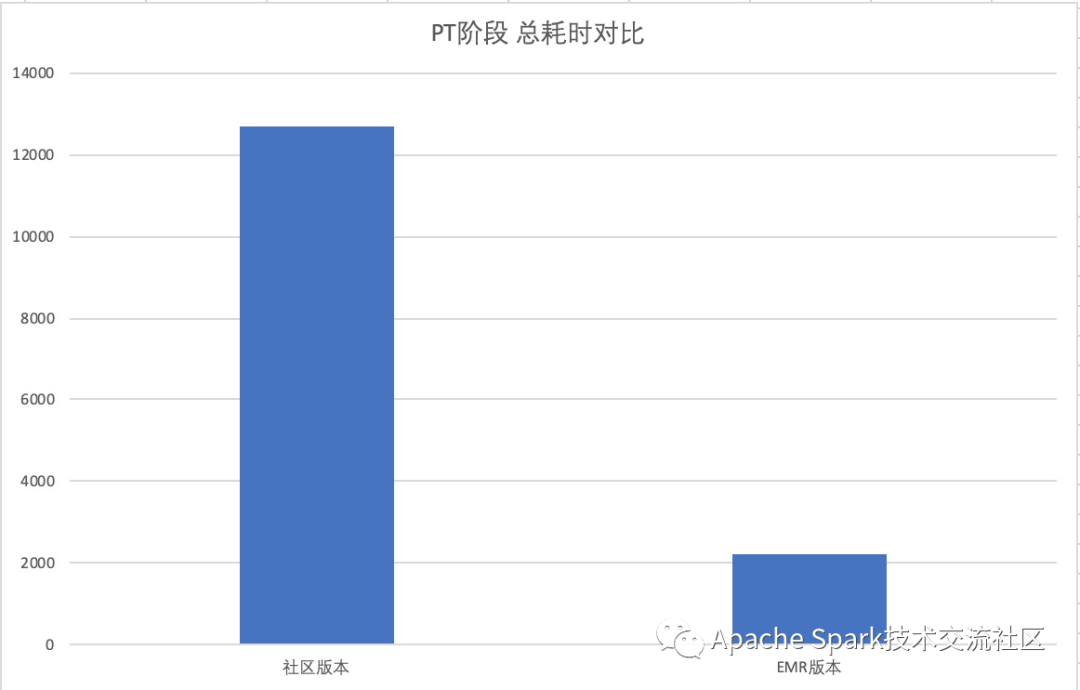
PS. 其中社区 Spark V2.4.3 版本中 Query 14 以及 Query 95 因为 OOM 的原因没法跑出来,不纳入计算
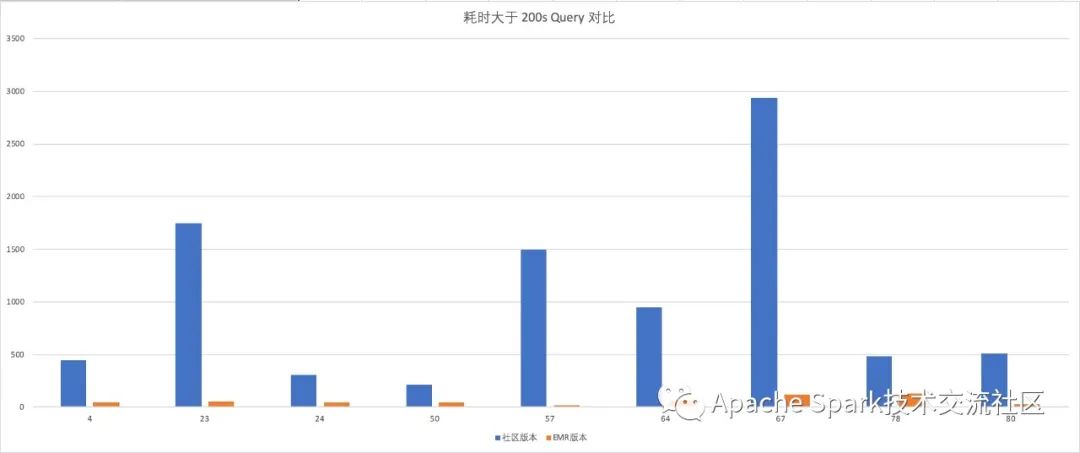
PS. 这几个 Query 最低的 Query 78 有 3X 性能提升,Query 57有接近 100 倍的性能提升。
基于 InMemoryTable Cache 的 CTE 物化
简单来说,就是尽量更合理的利用 InMemoryTable Cache 去减少不必要的重复计算,比如说 Query 23A/B 中的标量计算,本身是非常重的操作,并且又必须重复的计算,通过 CTE 优化的模式匹配,识别出需要重复计算且比较耗时的操作,并利用 InMemoryTable 缓存,整体减少 E2E 时间
更加有效的 Filter 相关优化
Dynamic Partition Pruning 这个在社区最新的3.0版本才有这个功能
小表广播复用 一个具有过滤性的小表,如果可以过滤 2 个或以上的打表数据时,可以复用该小表的过滤效果 Query 64 就是一个好例子
BloomFilter before SMJ 在 SMJ 真正实施之前,通过前置 BloomFilter ,Join 过程的数据进一步减少,最大限度的消除 SpillDisk 的问题
PK/FK Constraint 优化 通过主键外键信息,对优化器提供更多的优化建议
RI-Join 去除 事实表与维表于主键外键上做 Join ,但是维表的列并没有被 Project 的情况下,这次 Join 其实完全没有必要执行
GroupBy Keys 去除非主键列 当GroupBy Keys 中同时包括主键列以及非主键列,其实非主键列对 GroupBy 结果已经没有影响了,因为主键列已经隐含了 Unique 的信息
GroupBy Push Down before Join
Fast Decimal
基于 Table Analyze 以及运行时中的 Stat 信息,优化器可以决定把某些 Decimal 优化为 Long 或者 Int 的计算,这会有极大的提升,而 TPCDS 99 Query 里有大量的 Decimal 计算
这次的优化里面,还有一个很好玩的优化,就是我们引入的 Native Runtime,如果说上述的优化器优化都是一些特殊 Case 的杀手锏,Native Runtime 就是一个广谱大杀器,根据我们后期统计,引入 Native Runtime,可以普适性的提高 SQL Query 15~20%的 E2E 耗时,这个在TPCDS Perf 里面也是一个很大的性能提升点。
大致的介绍一下 Native Runtime
基于开源版本的 WholeStageCodeGeneration 的框架,在原有的生成的 Java 代码,替换成 Weld IR 来真实运行。在整个项目里,Weld IR 的替换其实是非常小的一部分工作,为了Weld IR 能够运行起来,我们还需要做以下的工作
Expression Weld IR CodeGen ( TPCDS 范围内全支持)
Operators Weld IR CodeGen (除了 SortMergeJoin 用 C++ 实现,其他均可以用 Weld IR 代替)
统一内存布局 (OffHeap UnsafeRow => C++ & Weld Runtime)
Batch 化执行框架 (因为如果按照 Java 运行时,每次都是一条记录的在生成代码里流转,在 NativeRuntime 的时间里代价太高, JNI 以及WeldRuntime 明显不能这么玩)
其他高性能Native算子 SortMergeJoin、PartitionBy、CSV Parsing,这几个算子目前用 Weld IR 提供的接口无法直接实现,我们通过 C++来实现这些算子的 Native 执行
关于如何进行EMR Spark-SQL性能极致优化的分析就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。