жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жң¬зҜҮж–Үз« з»ҷеӨ§е®¶еҲҶдә«зҡ„жҳҜжңүе…іжҖҺд№ҲйҖҡиҝҮеўһеҠ жЁЎеһӢзҡ„еӨ§е°ҸжқҘеҠ йҖҹTransformerзҡ„и®ӯз»ғе’ҢжҺЁзҗҶпјҢе°Ҹзј–и§үеҫ—жҢәе®һз”Ёзҡ„пјҢеӣ жӯӨеҲҶдә«з»ҷеӨ§е®¶еӯҰд№ пјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеҸҜд»ҘжңүжүҖ收иҺ·пјҢиҜқдёҚеӨҡиҜҙпјҢи·ҹзқҖе°Ҹзј–дёҖиө·жқҘзңӢзңӢеҗ§гҖӮ
дҪ жІЎжңүзңӢй”ҷпјҢзЎ®е®һжҳҜйҖҡиҝҮеўһеӨ§жЁЎеһӢзҡ„еӨ§е°ҸпјҢеӨ§е®¶еҲ«еҝҳдәҶпјҢеңЁи®ӯз»ғзҡ„ж—¶еҖҷпјҢжңүдёӘйҡҗеҗ«жқЎд»¶пјҢйӮЈе°ұжҳҜжЁЎеһӢйңҖиҰҒи®ӯз»ғеҲ°ж”¶ж•ӣгҖӮ
еңЁж·ұеәҰеӯҰд№ дёӯпјҢдҪҝз”ЁжӣҙеӨҡзҡ„и®Ўз®—(дҫӢеҰӮпјҢеўһеҠ жЁЎеһӢеӨ§е°ҸгҖҒж•°жҚ®йӣҶеӨ§е°ҸжҲ–и®ӯз»ғжӯҘйӘӨ)йҖҡеёёдјҡеҜјиҮҙжӣҙй«ҳзҡ„еҮҶзЎ®жҖ§гҖӮиҖғиҷ‘еҲ°жңҖиҝ‘еғҸBERTиҝҷж ·зҡ„ж— зӣ‘зқЈйў„и®ӯз»ғж–№жі•зҡ„жҲҗеҠҹпјҢиҝҷдёҖзӮ№е°Өе…¶жӯЈзЎ®пјҢе®ғеҸҜд»Ҙе°Ҷи®ӯз»ғжү©еұ•еҲ°йқһеёёеӨ§зҡ„жЁЎеһӢе’Ңж•°жҚ®йӣҶгҖӮдёҚе№ёзҡ„жҳҜпјҢеӨ§и§„жЁЎзҡ„и®ӯз»ғеңЁи®Ўз®—дёҠйқһеёёжҳӮиҙөзҡ„пјҢе°Өе…¶жҳҜеңЁжІЎжңүеӨ§еһӢе·Ҙдёҡз ”з©¶е®һйӘҢе®Өзҡ„硬件иө„жәҗзҡ„жғ…еҶөдёӢгҖӮеӣ жӯӨпјҢеңЁе®һи·өдёӯпјҢжҲ‘们зҡ„зӣ®ж ҮйҖҡеёёжҳҜеңЁдёҚи¶…еҮә硬件预算е’Ңи®ӯз»ғж—¶й—ҙзҡ„жғ…еҶөдёӢиҺ·еҫ—иҫғй«ҳзҡ„еҮҶзЎ®жҖ§гҖӮ
еҜ№дәҺеӨ§еӨҡж•°и®ӯз»ғйў„з®—пјҢйқһеёёеӨ§зҡ„жЁЎеһӢдјјд№ҺдёҚеҲҮе®һйҷ…гҖӮзӣёеҸҚпјҢжңҖеӨ§йҷҗеәҰжҸҗй«ҳи®ӯз»ғж•ҲзҺҮзҡ„зӯ–з•ҘжҳҜдҪҝз”Ёйҡҗи—ҸиҠӮзӮ№ж•°иҫғе°ҸжҲ–еұӮж•°йҮҸиҫғе°‘зҡ„жЁЎеһӢпјҢеӣ дёәиҝҷдәӣжЁЎеһӢиҝҗиЎҢйҖҹеәҰжӣҙеҝ«пјҢдҪҝз”Ёзҡ„еҶ…еӯҳжӣҙе°‘гҖӮ
然иҖҢпјҢеңЁжҲ‘们зҡ„жңҖиҝ‘зҡ„и®әж–ҮдёӯпјҢжҲ‘们表жҳҺиҝҷз§ҚеҮҸе°‘жЁЎеһӢеӨ§е°Ҹзҡ„еёёи§ҒеҒҡжі•е®һйҷ…дёҠдёҺжңҖдҪізҡ„и®Ўз®—ж•ҲзҺҮи®ӯз»ғзӯ–з•ҘзӣёеҸҚгҖӮзӣёеҸҚпјҢеҪ“еңЁйў„з®—еҶ…и®ӯз»ғTransformerжЁЎеһӢж—¶пјҢдҪ еёҢжңӣеӨ§е№…еәҰеўһеҠ жЁЎеһӢеӨ§е°ҸпјҢдҪҶжҳҜж—©зӮ№еҒңжӯўи®ӯз»ғгҖӮжҚўеҸҘиҜқиҜҙпјҢжҲ‘们йҮҚж–°жҖқиҖғдәҶжЁЎеһӢеҝ…йЎ»иў«и®ӯз»ғзӣҙеҲ°ж”¶ж•ӣзҡ„йҡҗеҗ«еҒҮи®ҫпјҢеұ•зӨәдәҶеңЁзүәзүІж”¶ж•ӣжҖ§зҡ„еҗҢж—¶пјҢжңүжңәдјҡеўһеҠ жЁЎеһӢзҡ„еӨ§е°ҸгҖӮ
иҝҷз§ҚзҺ°иұЎеҸ‘з”ҹзҡ„еҺҹеӣ жҳҜпјҢдёҺиҫғе°Ҹзҡ„жЁЎеһӢзӣёжҜ”пјҢиҫғеӨ§зҡ„жЁЎеһӢеңЁиҫғе°‘зҡ„жўҜеәҰжӣҙж–°дёӯеҸҜд»Ҙ收ж•ӣдәҺиҫғдҪҺзҡ„жөӢиҜ•иҜҜе·®гҖӮжӯӨеӨ–пјҢиҝҷз§Қ收ж•ӣйҖҹеәҰзҡ„жҸҗй«ҳи¶…иҝҮдәҶдҪҝз”ЁжӣҙеӨ§жЁЎеһӢзҡ„йўқеӨ–и®Ўз®—жҲҗжң¬гҖӮеӣ жӯӨпјҢеңЁиҖғиҷ‘и®ӯз»ғж—¶й—ҙж—¶пјҢиҫғеӨ§зҡ„жЁЎеһӢеҸҜд»Ҙжӣҙеҝ«ең°иҺ·еҫ—жӣҙй«ҳзҡ„зІҫеәҰгҖӮ
жҲ‘们еңЁдёӢйқўзҡ„дёӨжқЎи®ӯз»ғжӣІзәҝдёӯеұ•зӨәдәҶиҝҷдёҖи¶ӢеҠҝгҖӮеңЁе·Ұдҫ§пјҢжҲ‘们з»ҳеҲ¶дәҶйў„и®ӯз»ғзҡ„йӘҢиҜҒиҜҜе·®RoBERTaпјҢиҝҷжҳҜBERTзҡ„дёҖдёӘеҸҳдҪ“гҖӮRoBERTaжЁЎеһӢи¶Ҡж·ұпјҢе…¶ж··д№ұеәҰе°ұи¶ҠдҪҺ(жҲ‘们зҡ„и®әж–ҮиЎЁжҳҺпјҢеҜ№дәҺжӣҙе®Ҫзҡ„жЁЎеһӢд№ҹжҳҜеҰӮжӯӨ)гҖӮиҝҷдёҖи¶ӢеҠҝд№ҹйҖӮз”ЁдәҺжңәеҷЁзҝ»иҜ‘гҖӮеңЁеҸідҫ§пјҢжҲ‘们з»ҳеҲ¶дәҶйӘҢиҜҒBLEUеҲҶж•°(и¶Ҡй«ҳи¶ҠеҘҪ)пјҢеҪ“и®ӯз»ғдёҖдёӘиӢұиҜӯеҲ°жі•иҜӯзҡ„TransformerжңәеҷЁзҝ»иҜ‘жЁЎеһӢгҖӮеңЁзӣёеҗҢзҡ„и®ӯз»ғж—¶й—ҙдёӢпјҢж·ұеәҰе’Ңе®ҪеәҰжЁЎеһӢжҜ”е°ҸжЁЎеһӢиҺ·еҫ—жӣҙй«ҳзҡ„BLEUеҲҶж•°гҖӮ
жңүи¶Јзҡ„жҳҜпјҢеҜ№дәҺи®ӯз»ғеүҚзҡ„RoBERTaжқҘиҜҙпјҢеўһеҠ жЁЎеһӢзҡ„е®ҪеәҰе’Ң/жҲ–ж·ұеәҰйғҪдјҡеҜјиҮҙжӣҙеҝ«зҡ„и®ӯз»ғгҖӮеҜ№дәҺжңәеҷЁзҝ»иҜ‘пјҢжӣҙе®Ҫзҡ„жЁЎеһӢжҜ”жӣҙж·ұзҡ„жЁЎеһӢиЎЁзҺ°еҫ—жӣҙеҘҪгҖӮеӣ жӯӨпјҢжҲ‘们е»әи®®еңЁж·ұе…Ҙд№ӢеүҚе°қиҜ•еўһеҠ е®ҪеәҰгҖӮ
жҲ‘们иҝҳе»әи®®еўһеҠ жЁЎеһӢеӨ§е°ҸпјҢиҖҢдёҚжҳҜbatch sizeеӨ§е°ҸгҖӮе…·дҪ“ең°иҜҙпјҢжҲ‘们确и®ӨдёҖж—Ұbatch sizeжҺҘиҝ‘дёҙз•ҢиҢғеӣҙпјҢеўһеҠ batch sizeеӨ§е°ҸеҸӘдјҡеңЁи®ӯз»ғж—¶й—ҙдёҠжҸҗдҫӣеҫ®е°Ҹзҡ„ж”№иҝӣгҖӮеӣ жӯӨпјҢеңЁиө„жәҗеҸ—йҷҗзҡ„жғ…еҶөдёӢпјҢжҲ‘们е»әи®®еңЁиҝҷдёӘе…ій”®еҢәеҹҹеҶ…дҪҝз”Ёbatch sizeеӨ§е°ҸпјҢ然еҗҺдҪҝз”ЁжӣҙеӨ§зҡ„жЁЎеһӢгҖӮ
е°Ҫз®ЎжӣҙеӨ§зҡ„жЁЎеһӢе…·жңүжӣҙй«ҳзҡ„вҖңи®ӯз»ғж•ҲзҺҮвҖқпјҢдҪҶе®ғ们д№ҹеўһеҠ дәҶвҖңжҺЁзҗҶвҖқзҡ„и®Ўз®—е’ҢеҶ…еӯҳйңҖжұӮгҖӮиҝҷжҳҜжңүй—®йўҳзҡ„пјҢеӣ дёәжҺЁзҗҶзҡ„жҖ»жҲҗжң¬иҝңиҝңеӨ§дәҺеӨ§еӨҡж•°е®һйҷ…еә”з”Ёзҡ„и®ӯз»ғжҲҗжң¬гҖӮ然иҖҢпјҢеҜ№дәҺRoBERTaжқҘиҜҙпјҢжҲ‘们иҜҒжҳҺдәҶиҝҷз§ҚеҸ–иҲҚеҸҜд»ҘдёҺжЁЎеһӢеҺӢзј©зӣёеҚҸи°ғгҖӮзү№еҲ«жҳҜпјҢдёҺе°ҸеһӢжЁЎеһӢзӣёжҜ”пјҢеӨ§еһӢжЁЎеһӢеҜ№жЁЎеһӢеҺӢзј©жҠҖжңҜжӣҙеҒҘеЈ®гҖӮеӣ жӯӨпјҢдәә们еҸҜд»ҘйҖҡиҝҮи®ӯз»ғйқһеёёеӨ§зҡ„жЁЎеһӢпјҢ然еҗҺеҜ№е®ғ们иҝӣиЎҢеӨ§йҮҸзҡ„еҺӢзј©пјҢд»ҺиҖҢиҫҫеҲ°дёӨе…Ёе…¶зҫҺзҡ„ж•ҲжһңгҖӮ
жҲ‘们дҪҝз”ЁйҮҸеҢ–е’ҢеүӘжһқзҡ„еҺӢзј©ж–№жі•гҖӮйҮҸеҢ–д»ҘдҪҺзІҫеәҰж јејҸеӯҳеӮЁжЁЎеһӢжқғйҮҚпјҢдҝ®еүӘе°ҶжҹҗдәӣзҘһз»ҸзҪ‘з»ңзҡ„жқғеҖји®ҫзҪ®дёәйӣ¶гҖӮиҝҷдёӨз§Қж–№жі•йғҪеҸҜд»ҘеҮҸе°‘жҺЁзҗҶ延иҝҹе’ҢеӯҳеӮЁжЁЎеһӢжқғеҖјзҡ„еҶ…еӯҳйңҖжұӮгҖӮ
жҲ‘们йҰ–е…ҲеңЁзӣёеҗҢзҡ„ж—¶й—ҙеҶ…йў„и®ӯз»ғдёҚеҗҢе°әеҜёзҡ„RoBERTaжЁЎеһӢгҖӮ然еҗҺпјҢжҲ‘们еңЁдёӢжёёж–Үжң¬еҲҶзұ»д»»еҠЎ(MNLI)дёӯеҜ№иҝҷдәӣжЁЎеһӢиҝӣиЎҢеҫ®и°ғпјҢ并дҪҝз”Ёдҝ®еүӘжҲ–йҮҸеҢ–гҖӮжҲ‘们еҸ‘зҺ°пјҢеҜ№дәҺз»ҷе®ҡзҡ„жөӢиҜ•ж—¶й—ҙйў„з®—пјҢжңҖеҘҪзҡ„жЁЎеһӢжҳҜйӮЈдәӣз»ҸиҝҮеӨ§йҮҸи®ӯз»ғ然еҗҺз»ҸиҝҮеӨ§йҮҸеҺӢзј©зҡ„жЁЎеһӢгҖӮ
дҫӢеҰӮпјҢиҖғиҷ‘жңҖж·ұеәҰжЁЎеһӢзҡ„дҝ®еүӘз»“жһң(е·Ұеӣҫдёӯзҡ„ж©ҷиүІжӣІзәҝ)гҖӮдёҚйңҖиҰҒдҝ®еүӘжЁЎеһӢпјҢе®ғиҫҫеҲ°дәҶеҫҲй«ҳзҡ„зІҫеәҰпјҢдҪҶжҳҜдҪҝз”ЁдәҶеӨ§зәҰ2дәҝдёӘеҸӮж•°(еӣ жӯӨйңҖиҰҒеӨ§йҮҸзҡ„еҶ…еӯҳе’Ңи®Ўз®—)гҖӮдҪҶжҳҜпјҢеҸҜд»ҘеҜ№иҝҷдёӘжЁЎеһӢиҝӣиЎҢеӨ§йҮҸзҡ„дҝ®еүӘ(жІҝзқҖжӣІзәҝеҗ‘е·Ұ移еҠЁзҡ„зӮ№)пјҢиҖҢдёҚдјҡдёҘйҮҚеҪұе“ҚеҮҶзЎ®жҖ§гҖӮиҝҷдёҺиҫғе°Ҹзҡ„жЁЎеһӢеҪўжҲҗдәҶйІңжҳҺзҡ„еҜ№жҜ”пјҢеҰӮзІүзәўиүІжҳҫзӨәзҡ„6еұӮжЁЎеһӢпјҢе…¶зІҫеәҰеңЁдҝ®еүӘеҗҺдёҘйҮҚдёӢйҷҚгҖӮйҮҸеҢ–д№ҹжңүзұ»дјјзҡ„и¶ӢеҠҝ(дёӢеӣҫ)гҖӮжҖ»зҡ„жқҘиҜҙпјҢеҜ№дәҺеӨ§еӨҡж•°жөӢиҜ•йў„з®—(еңЁxиҪҙдёҠйҖүжӢ©дёҖдёӘзӮ№)жқҘиҜҙпјҢжңҖеҘҪзҡ„жЁЎеһӢжҳҜйқһеёёеӨ§дҪҶжҳҜй«ҳеәҰеҺӢзј©зҡ„жЁЎеһӢгҖӮ
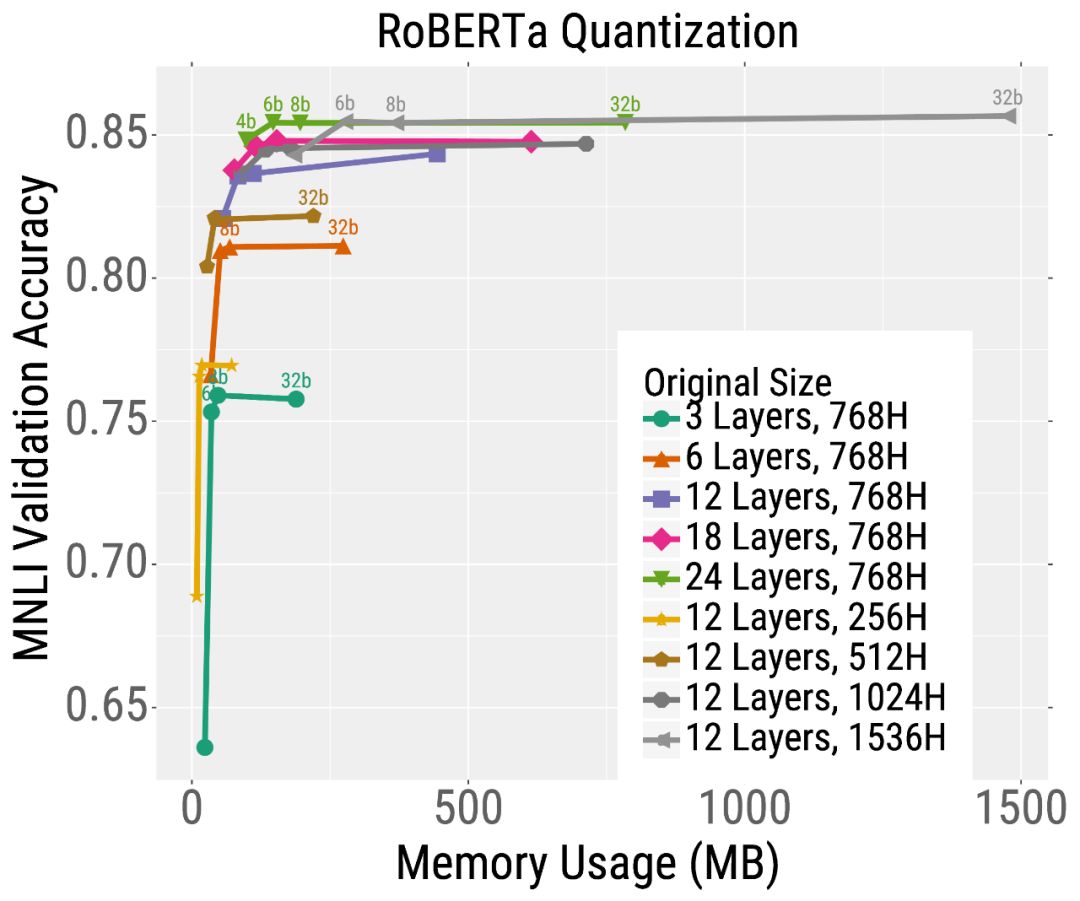
жҲ‘们已з»ҸиҜҒжҳҺдәҶеўһеҠ TransformerжЁЎеһӢзҡ„еӨ§е°ҸеҸҜд»ҘжҸҗй«ҳи®ӯз»ғе’ҢжҺЁзҗҶзҡ„ж•ҲзҺҮпјҢеҚіпјҢеә”иҜҘе…ҲвҖңеӨ§жЁЎеһӢи®ӯз»ғвҖқпјҢ然еҗҺеҶҚвҖңеҺӢзј©вҖқгҖӮиҝҷдёҖеҸ‘зҺ°еј•еҮәдәҶи®ёеӨҡе…¶д»–жңүи¶Јзҡ„й—®йўҳпјҢжҜ”еҰӮдёәд»Җд№ҲеӨ§зҡ„жЁЎеһӢ收ж•ӣеҫ—жӣҙеҝ«пјҢеҺӢзј©еҫ—жӣҙеҘҪгҖӮ
д»ҘдёҠе°ұжҳҜжҖҺд№ҲйҖҡиҝҮеўһеҠ жЁЎеһӢзҡ„еӨ§е°ҸжқҘеҠ йҖҹTransformerзҡ„и®ӯз»ғе’ҢжҺЁзҗҶпјҢе°Ҹзј–зӣёдҝЎжңүйғЁеҲҶзҹҘиҜҶзӮ№еҸҜиғҪжҳҜжҲ‘们ж—Ҙеёёе·ҘдҪңдјҡи§ҒеҲ°жҲ–з”ЁеҲ°зҡ„гҖӮеёҢжңӣдҪ иғҪйҖҡиҝҮиҝҷзҜҮж–Үз« еӯҰеҲ°жӣҙеӨҡзҹҘиҜҶгҖӮжӣҙеӨҡиҜҰжғ…敬иҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ