您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
如何利用DC/OS构建深度学习平台,针对这个问题,这篇文章详细介绍了相对应的分析和解答,希望可以帮助更多想解决这个问题的小伙伴找到更简单易行的方法。
以下是今年在北美MesosCon上Uber的Min Cai,Alex Sergeev,Paul Mikesell和Anne Holler发表的“利用 Apache Mesos (GPU资源调度与Gang调度器)构建分布式深度学习平台”的概要。 Uber团队分享了他们如何在Apache Mesos(底层核心技术是Mesosphere DC / OS)上构建分布式学习平台,用于自动驾驶的研究,预测搭车、共享车趋势,并防止欺诈行为。Uber采用了名为Horovod的分布式深度学习平台,该平台优化了使用GPU的运算模型,通过运用名为Peloton的自定义调度算法来对GPU资源进行调度,让多个GPU像一个GPU一样简单运行。
分布式深度学习优化Uber操作
Uber在很多关键领域成功的秘诀是对分布式深度学习技术的运用。 Uber的无人驾驶是公司未来业务的核心部分。计算集群在处理计算机视觉和深度感知的三维模型,区域地图、天气以及其他很多涉及导航的因素时,需要大量的数据处理和计算。这样一个程序成功的一个关键指标是多快能通过深度学习集群来训练完成一个新的计算模型。无人驾驶的研究是Uber未来的重要内容,Uber同时也搭建了很多围绕共享出行服务模型,它面临着任何其他供应链模型相同的问题。在出行预测中,需求随时间推移可预测,数据输入由在线且可用的司机组成。 Uber会分析历史数据,结合天气,即将发生的区域事件和其他数据来提醒Uber司机即将到来的出行需求高峰,以便他们应对。同样的深度学习系统也被用来标记和防止顾客和司机的欺诈行为。
为速度和规模而生的分布式深度学习
Uber以相当大的规模来处理数据。Uber用于训练模型的数据集和深度学习模型要比单个主机,单个GPU,单个任务能处理的规模大的多。通常使用的一个主进程,多个工作线程的单一线程模型无法扩展到能开发训练基于大数据,并能满足Uber和其他硅谷领先公司紧张上市时间需求的深度学习模型。Uber工程师意识到,一个完全分布式的,多对多的模型会更具价值,因为它可以按照服务组来进行编排,优先级定义,资源规划并处理。通过在集群中进行数据分片以达到缩短网络延时,进而最小化延时,在数百个GPU中产生训练模型等方式提升模型训练的效率。Uber分布式深度学习平台核心是基于Apache Mesos, Peloton和Horovod来组合构建的。
基于Apache Mesos的深入学习
在结合了社区的优势和平台的特性,评估了许多解决方案之后,Uber最终选择了Apache Mesos。该平台被市场广泛采纳,并应用于传统企业和互联网公司,这引起了Uber的关注。 Mesos社区的成熟确保了上游社区代码提交的及时性,相关性和稳定性。 在甄选专注于分布式深度学习的调度平台过程中,Uber同时考虑了经过实际验证的可扩展性,可靠性和高度定制化,以及诸如原生GPU支持,嵌套容器和Nvidia GPU隔离等特性。Apache Mesos提供了对GPU的原生支持,而对于其他容器框架,Uber可能需要自行提取上游代码补丁,开发自己的代码库并在生产环境中自行支持。Apache Mesos还在其容器中嵌入了正确的CUDA版本,这简化了分布式深度学习框架的部署。 Uber利用Apache Mesos独特的功能来以容器化的方式运行分布式TensorFlow,将TensorFlow的管理代码封装到子容器或是嵌套容器中,使之独立于开发人员的工作流。因此,Uber的开发人员变得更高效,他们可以专注于模型开发和训练,而不用管理TensorFlow本身。
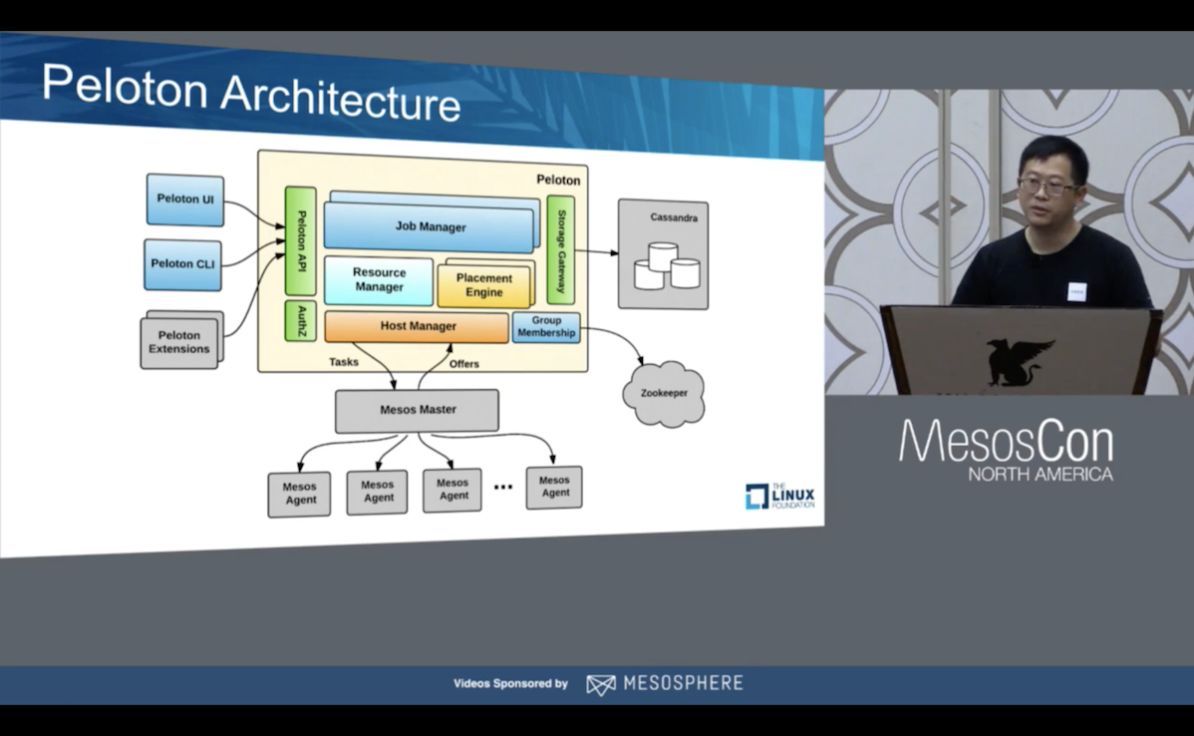
Uber Peloton批次调度
虽然Apache Mesos是一个非常好的任务调度,资源管理和任务故障恢复的工具,但Uber希望添加自己的功能,以便按照自己的方式来运行分布式深度学习工作流。 特别是,Uber为TensorFlow工作流管理和调度增加了更细的粒度。 出于这个原因,Uber研发团队开发了Peloton,一个Uber自己的工作流管理器,侧重于定制化的工作流/任务的生命周期管理,任务编排以及任务抢占。现在,Uber可以以更好的粒度来管理任务,一次工作流的提交可以包含数百个任务,这数百个任务被认为是一个批次。批次在Peloton被视为单个原子单位,而其中每个任务都运行在独立的容器中。
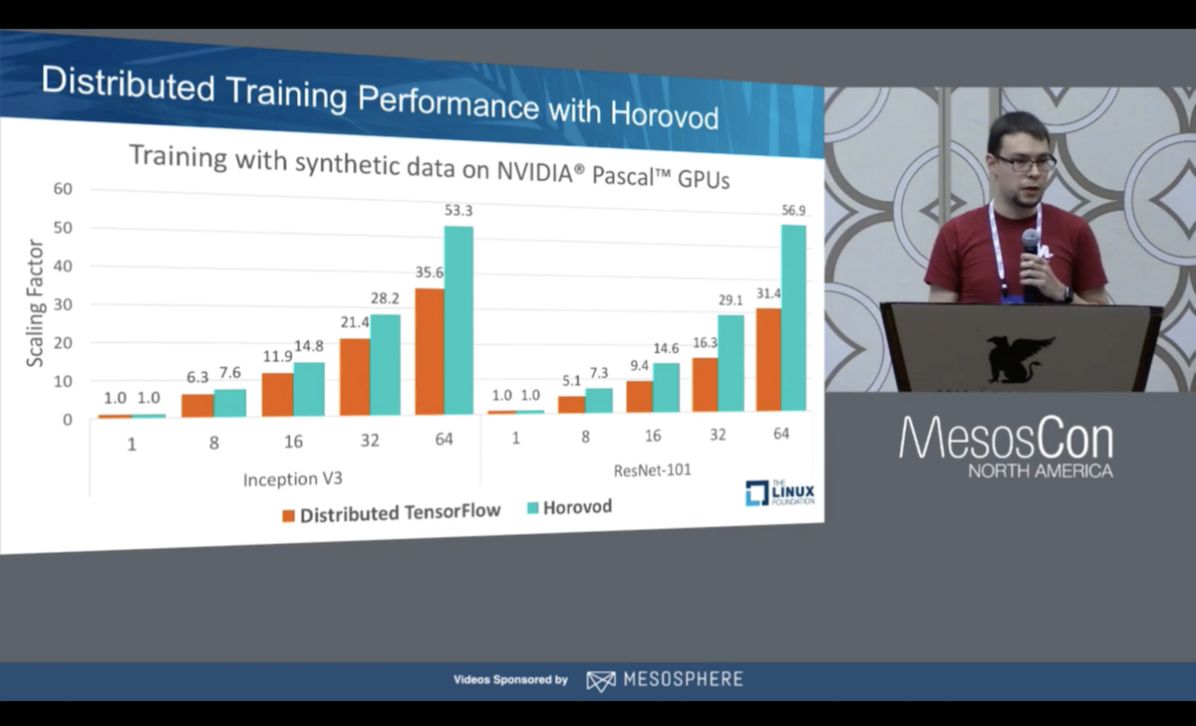
Uber Horovod提升了TensorFlow对多GPU的支持
在Uber解决了核心的资源管理和批次调度之后,研发团队将注意力转向开发一种对研发人员友好的多GPU任务调度的解决方案。 在Uber,他们使用TensorFlow作为深度学习模型,但是发现对于研发人员来说多GPU支持很麻烦和并容易出错。 为了改善这一点,该团队开发了Horovod,这是一个基于单一GPU模型作业而开发的多GPU工作流提交接口。 因此,他们大大减少了开发人员出错的概率和工作完成的时间。 在MesosCon北美地区展示的一个实例中,有了Horovod,他们的GPU集群效率大约从56%提高到82%,提高了28%。
关于如何利用DC/OS构建深度学习平台问题的解答就分享到这里了,希望以上内容可以对大家有一定的帮助,如果你还有很多疑惑没有解开,可以关注亿速云行业资讯频道了解更多相关知识。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。