您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章主要为大家展示了“Hadoop基础知识有哪些”,内容简而易懂,条理清晰,希望能够帮助大家解决疑惑,下面让小编带领大家一起研究并学习一下“Hadoop基础知识有哪些”这篇文章吧。
Hadoop这个单词本身并没有什么特殊的含义,而只是其作者Doug Cutting孩子的一个棕黄色的大象玩具的名字。
Hadoop是一个高可靠的(reliable),规模可扩展的(scalable),分布式(distributed computing)的开源软件框架。它使我们能用一种简单的编程模型来处理存储于集群上的大数据集。
Hadoop是Apache基金会的一个开源项目,是一个提供了分布式存储和分布式计算功能的基础架构平台。可以应用于企业中的数据存储,日志分析,商业智能,数据挖掘等。
1. hadoop包含的模块:
Hadoop common:提供一些通用的功能支持其他hadoop模块。
Hadoop Distributed File System:即分布式文件系统,简称HDFS。主要用来做数据存储,并提供对应用数据高吞吐量的访问。
Hadoop Yarn:用于作业调度和集群资源管理的框架。
Hadoop MapReduce:基于yarn的,能用来并行处理大数据集的计算框架。
2. HDFS:
HDFS是谷歌GFS的一个开源实现,具有扩展性,容错性,海量数据存储的特点:
扩展性,主要指很容易就可以在当前的集群上增加一台或者多台机器,扩展计算资源。
容错性,主要指其多副本的存储机制。HDFS将文件切分成固定大小的block(默认是128M),并以多副本形式存储在多台机器上,当其中一台机器发生故障,仍然有其他副本供我们使用。但这个容错并不是绝对的,当所有节点都发生故障,文件就会丢失,不过这样的概率较小。
海量数据存储:多台机器构成了一个集群,相对单机能存储更多量的数据。这也是Hadoop解决的最主要问题之一。
数据切分,多副本,容错等机制都是Hadoop底层已经设计好的,对用户透明,用户不需要关系细节。只需要按照对单机文件的操作方式,就可以进行分布式文件的操作。如文件的上传,查看,下载等。
多副本存储示例:
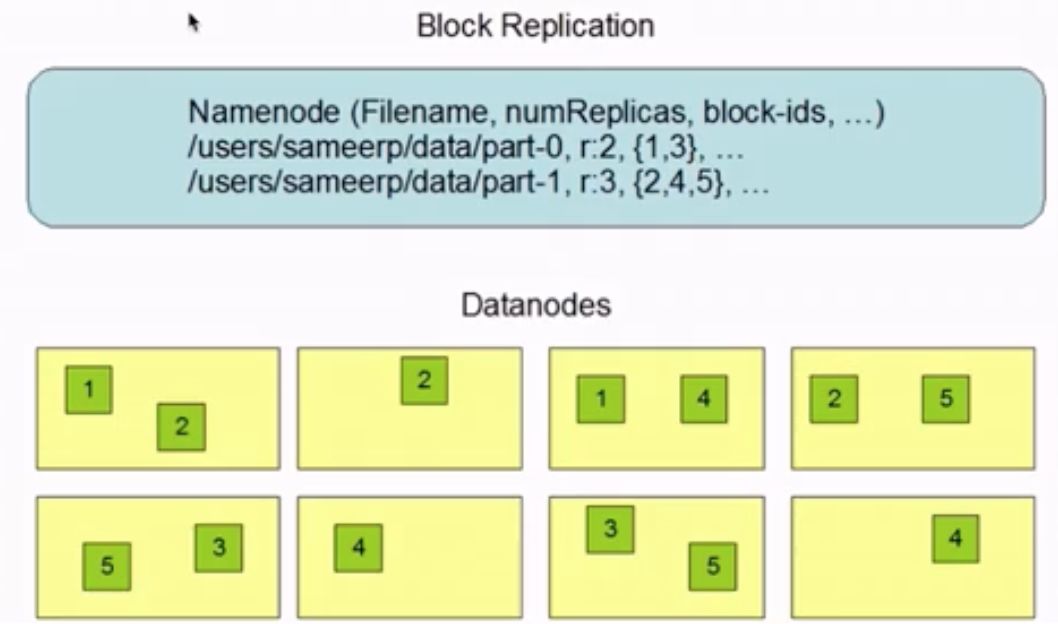
以part-1为例进行说明,它被分成三个block,block_id分别是2,4,5,且副本系数为3。可以看到在DataNode上,2,4,5都各存储在了三个节点上,这样当其中一个节点故障时,仍然能够保证文件的可用。block_id存在的必要性在于,在用户需要对文件进行操作时,相应的block能够按顺序进行“组合”起来。
3. YARN:
Yarn的全称是Yet Another Resource Negotiator,负责整个集群资源的管理和调度。例如对每个作业,分配CPU,内存等等,都由yarn来管理。它的特点是扩展性,容错性,多框架资源统一调度。
扩展性和HDFS的扩展性类似,yarn也很容易扩展其计算资源。
容错性,主要是指当某个任务出现异常,yarn会对其进行一定次数的重试。
多框架资源统一调度,这个是相对于hadoop1.0版本的一个优势。区别于hadoop1.0只支持MapReduce作业。而yarn之上可以运行不同类型的作业。如下图所示,很多应用都可以运行在yarn之上,由yarn统一进行调度。
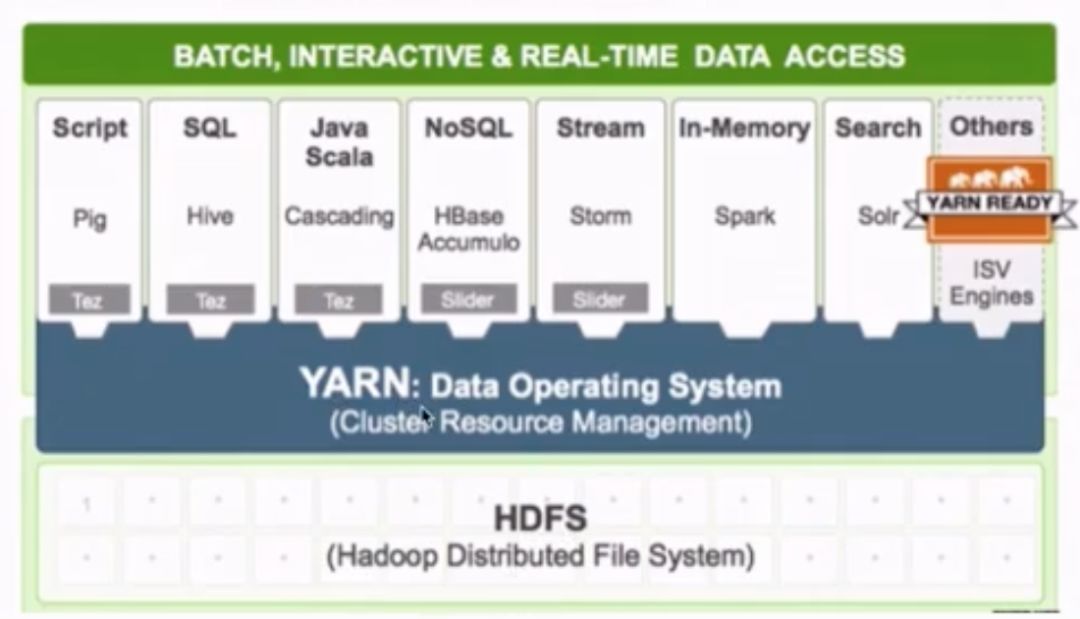
4. mapreduce:
是一个分布式计算框架,是GoogleMapReduce的克隆版。和HDFS、Yarn类似,也具有扩展性和容错性的特点,还将具有海量数据离线处理的特点:能够处理的数据量大,但并不是实时处理,具有较大的延时性。
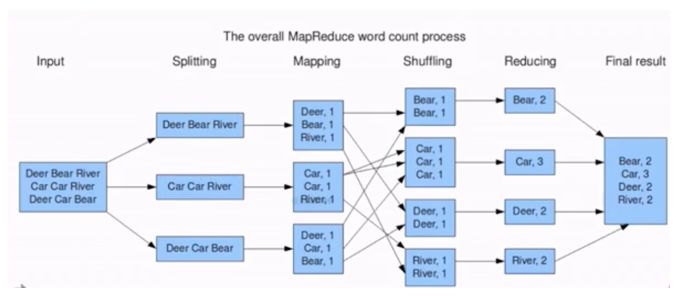
WordCount的MapReduce流程如图所示,主要分为Map和Reduce两个过程。Map阶段做映射,对所有输入的单词赋值为1,Reduce阶段做汇总,相同的单词分发到一个节点上并进行求和,最终就可以统计出单词的个数。
hadoop的优势主要体现在高可靠性,高扩展性等方面。
高可靠性是指多副本的存储机制和失败作业的重新调度计算。
高扩展性是指资源不够时很容易直接扩展机器。一个集群可以包含数以千计的节点。
其他优势还表现在:hadoop完全可以部署在普通廉价的机器上,成本低。同时它具有成熟的生态圈和开源社区。
狭义hadoop:指一个用于大数据分布式存储(HDFS),分布式计算(MapReduce)和资源调度(YARN)的平台,这三样只能用来做离线批处理,不能用于实时处理,因此才需要生态系统的其他的组件。
广义的hadoop:指的是hadoop的生态系统,即其他各种组件在内的一整套软件。hadoop生态系统是一个很庞大的概念,hadoop只是其中最重要最基础的部分,生态系统的每一个子系统只结局的某一个特定的问题域。不是一个全能系统,而是多个小而精的系统。
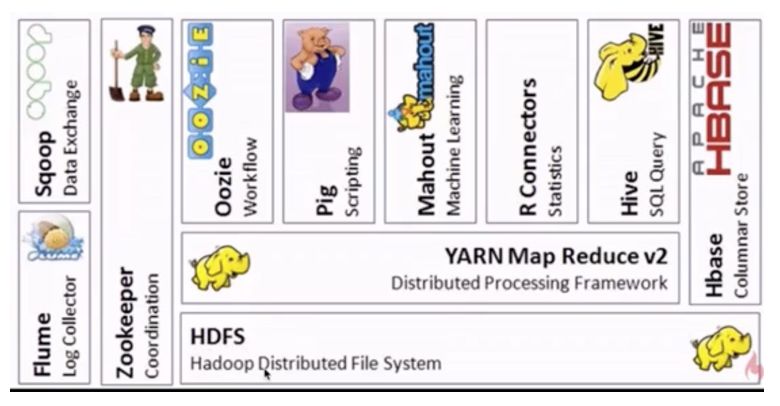
由于MapReduce的学习成本相对较高,这样就诞生了一些其他框架。
Hive 处理的是海量结构化日志数据的统计问题。它定义了一种类似SQL的语言Hive QL,借助于hive引擎能将其转换为MapReduce作业并提交到集群上进行运算。hive适用于离线处理。相比之下,SQL的门槛就低得多
Mahout是一个机器学习算法库,实现了很多数据挖掘的经典算法,帮助用户很方便地创建应用程序。
Pig可以将脚本任务转换为MapReduce作业,同样是适用于离线分析。
Oozie是一个工作流调度引擎,用来处理具有依赖关系的作业调度。类似的框架有Azkaban,airflow等。
Zookeeper:分布式协调服务,“动物园管理员”角色,是一个对集群服务进行管理的框架,如维护故障切换等。
Flume:日志收集框架。将多种应用服务器上的日志,统一收集到HDFS上,这样就可以使用hadoop进行处理
Sqoop:提供关系型数据库与HDFS数据相互传输的功能。
Hbase:面向列存储的数据库。适用于实时快速查询的场景。
除此之外,还有spark,kafka,flink,redis等新兴的一些实用框架。
reference:https://blog.csdn.net/zcb_data/article/details/80402411
开源,社区高活跃
开源意味着源码可获取,可以直接基于源码进行改造实现个性化需求。社区活跃高意味着迭代更新快,维护的人多。
囊括了大数据处理的方方面面
具有成熟的生态圈。
Apache hadoop:解决了单个框架的额问题,综合起来使用会有jar包冲突,不适合于生产环境。
CDH:Cloudera Distributed Hadoop。商业版本。使用Cloudera Manager对集群进行管理,通过浏览器,不需要通过linux就可以安装,与spark结合的很好。没有jar包冲突的问题。但Cloudera Manager不开源,企业版收费。
CDH的下载地址:http://archive.cloudera.com/cdh6/cdh/5/
HDP:Hortonworks Data Platform。商业版本之一,使用Ambari进行统一管理,对服务的用户收费。
以上是“Hadoop基础知识有哪些”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。