您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
怎么进行RabbitMQ镜像队列分析,相信很多没有经验的人对此束手无策,为此本文总结了问题出现的原因和解决方法,通过这篇文章希望你能解决这个问题。
镜像队列的主要作用是用来解决队列的单点故障。
镜像队列主要有两种类型:master和slave。master和slave节点位于同一个集群中。master只要一个节点,slave可以有多个节点。
生产者发送到主节点消息会同时被发往各个slave节点,除了发送消息,其他动作只会发给master,然后通过master广播给其他slave。
master挂掉以后,根据slave加入的时间顺序排列,时间长的提升为master。
镜像队列的backing_queue不再使用rabbit_variable_queue。master节点的queue使用rabbit_mirror_queue_master,它内部包裹了普通backing_queue进行本地消息消息持久化处理,在此基础上增加了将消息和ack复制到所有镜像的功能,slave节点的queue使用rabbit_mirror_queue_slave。
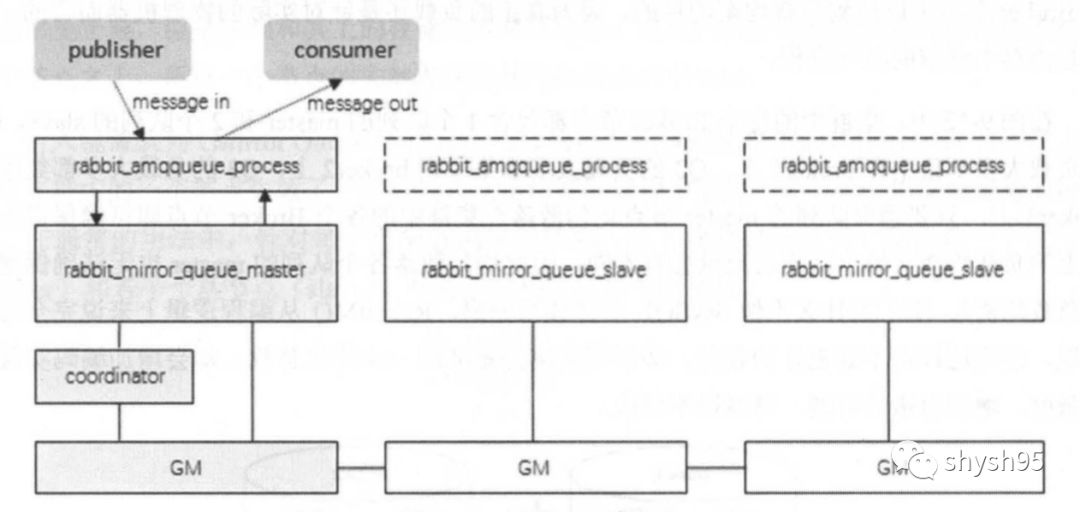
rabbit_mirror_queue_master的操作都会通过组播GM的方式同步到各个slave中。GM负责消息的广播,rabbitmirrorqueueslave负责回调处理,而master上的回调处理是由coordinator负责完成的。如前所述,除了Basic.Publish,所有的操作都是通过master来完成的,master对消息进行处理的同时将消息的处理通过GM广播给所有的slave,slave的GM收到消息后,通过回调交由rabbit_mirror_queue_slave进行实际的处理。
GM模块实现的是一种可靠的组播通信协议,该协议能够保证组播消息的原子性,即保证组中活着的节点要么都收到消息要么都收不到,它的实现大致为:将所有的节点形成一个循环链表,每个节点都会监控位于自己左右两边的节点,当有节点新增时,相邻的节点保证当前广播的消息会复制到新的节点上;当有节点失效时,相邻的节点会接管以保证本次广播的消息会复制到所有的节点。
在master和slave上的这些GM形成一个组(gm_group),这个组的信息会记录在Mnesia中。不同的镜像队列形成不同的组。操作命令从master对应的GM发出后,顺着链表传送到所有的节点。由于所有节点组成了一个循环链表, master对应的GM最终会收到自己发送的操作命令,这个时候master就知道该操作命令都同步到了所有的slave上。
当master挂掉之后,会有以下连锁反应:
与master连接的客户端连接全部断开。
选举最老的slave作为新的master,因为最老的slave与旧的master之间的同步状态应该是最好的。如果此时所有slave处于未同步状态,则未同步的消息会丢失。
新的master重新入队所有unack的消息,因为新的slave无法区分这些unack的消息是否己经到达客户端,或者是ack信息丢失在老的master链路上,再或者是丢失在老的master 组播ack消息到所有slave的链路上,所以出于消息可靠性的考虑,重新入队所有unack的消息,不过此时客户端可能会有重复消息。
如果客户端连接着slave,并且Basic.Consume消费时指定了x-cancel-on-hafailover参数,那么断开之时客户端会收到一个Consumer Cancellation Notification的通知,消费者客户端中会回调Consumer接口的handleCancel方法。如果未指定x-cancelon-ha-failover参数,那么消费者将无法感知master宕机。
rabbitmqctl set_policy [-p vhost] [--priority priority] [--apply-to apply-to] {name} {pattern} {definition}definition中需要包含3个部分:
ha-mode:指明镜像队列的模式,有效值为all、exactly、nodes,默认为all。all表示在集群中所有的节点上进行镜像;exactly表示在指定个数的节点上进行镜像,节点个数由ha-params指定;nodes表示在指定节点上进行镜像,节点名称过ha-params指定,节点的名称通常类似于rabbit@hostname。
ha-params:不同的ha-mode配置中需要用到的参数。
ha-sync-mode:队列中消息的同步方式,有效值为automatic和manual。
ha-promote-on-shutdown:加后面的讲述
将新节点加入己存在的镜像队列时,默认情况下ha-sync-mode取值为manual。镜像队列中的消息不会主动同步到新的slave中,除非显式调用同步命令。当调用同步命令后,队列开始阻塞,无法对其进行其他操作,直到同步完成。当ha-sync-mode设置为automatic时, 新加入的slave会默认同步己知的镜像队列
当所有slave都出现未同步状态,并且ha-promote-on-shutdown设置为when-synced(默认)时,如果master因为主动原因停掉,比如通过rabbitmqctl stop命令或者优雅关闭操作系统,那么slave不会接管master,也就是此时镜像队列不可用;但是如果master因为被动原因停掉,比如Erlang虚拟机或者操作系统崩溃,那么slave会接管master。这个配置项隐含的价值取向是保证消息可靠不丢失,同时放弃了可用性。如果ha-promote-on-shutdown设置为always,那么不论master因为何种原因停止,slave都会接管master,优先保证可用性,不过消息可能会丢失。
# 命令可以查看哪些slaves已经完成同步rabbitmqctl list_queues name slave_pids synchronised_slave_pids
# 手动同步队列rabbitmqctl sync_queue {name}
# 取消队列的同步操作rabbitmqctl cancel_sync_queue {name}看完上述内容,你们掌握怎么进行RabbitMQ镜像队列分析的方法了吗?如果还想学到更多技能或想了解更多相关内容,欢迎关注亿速云行业资讯频道,感谢各位的阅读!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。