жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жң¬зҜҮж–Үз« з»ҷеӨ§е®¶еҲҶдә«зҡ„жҳҜжңүе…іжҖҺд№ҲжҺўи®ЁRPCжЎҶжһ¶дёӯзҡ„жңҚеҠЎзәҝзЁӢйҡ”зҰ»пјҢе°Ҹзј–и§үеҫ—жҢәе®һз”Ёзҡ„пјҢеӣ жӯӨеҲҶдә«з»ҷеӨ§е®¶еӯҰд№ пјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеҸҜд»ҘжңүжүҖ收иҺ·пјҢиҜқдёҚеӨҡиҜҙпјҢи·ҹзқҖе°Ҹзј–дёҖиө·жқҘзңӢзңӢеҗ§гҖӮ
еҫ®жңҚеҠЎеҰӮд»Ҡеә”еҪ“жҳҜдёҖдёӘдјҳз§Җзҡ„зЁӢеәҸе‘ҳеҝ…йЎ»еӯҰд№ зҡ„дёҖз§Қжһ¶жһ„жҖқжғіпјҢиҖҢRPCжЎҶжһ¶дҪңдёәеҫ®жңҚеҠЎзҡ„ж ёеҝғпјҢдёҚиҜҙиҜ»дёҖйҒҚжәҗз Ғеҗ§пјҢиө·з Ғе®ғзҡ„е®һзҺ°еҺҹзҗҶиҝҳжҳҜеә”иҜҘзҹҘйҒ“зҡ„гҖӮ
然иҖҢзӣ®еүҚзҡ„RPCжңҚеҠЎжЎҶжһ¶пјҢеӨ§еӨҡеӯҳеңЁдёҖдёӘй—®йўҳпјҢе°ұжҳҜеҪ“жңҚеҠЎжҸҗдҫӣз«ҜProviderеә”з”ЁдёӯпјҢжңүзҡ„жңҚеҠЎжөҒйҮҸеӨ§пјҢиҖ—ж—¶й•ҝпјҢеҜјиҮҙзәҝзЁӢжұ иө„жәҗиў«иҝҷдәӣжңҚеҠЎеҚ е°ҪпјҢд»ҺиҖҢеҪұе“ҚеҗҢдёҖеә”з”Ёдёӯзҡ„е…¶д»–жңҚеҠЎжӯЈеёёжҸҗдҫӣгҖӮдёәжӯӨпјҢдёӢйқўдё»иҰҒд»Ӣз»ҚдёҖдёӢжҲ‘еҜ№дәҺиҝҷж–№йқўзҡ„жҖқиҖғгҖӮ
еңЁиҝӣе…ҘжӯЈж–Үд№ӢеүҚпјҢеҸҜд»Ҙе…ҲзңӢдёҖдёӢйҳҝйҮҢдёӯй—ҙ件еІӣйЈҺеӨ§дҪ¬зҡ„иҝҷзҜҮеҚҡж–ҮпјҲдј йҖҒй—ЁпјүпјҢиҝҷзҜҮеҚҡж–ҮеӨҚзҺ°дәҶDubboеә”з”ЁдёӯпјҢзәҝзЁӢжұ иҖ—е°Ҫзҡ„еңәжҷҜгҖӮиҝҷе…¶е®һеңЁзәҝдёҠжҳҜеҚҒеҲҶжҷ®йҒҚпјҢи§ЈеҶіж–№жі•ж— йқһжҳҜж №жҚ®дёҡеҠЎи°ғж•ҙеҸӮж•°пјҢжҲ–иҖ…еј•е…Ҙе…¶д»–зҡ„йҷҗжөҒгҖҒиө„жәҗйҡ”зҰ»жЎҶжһ¶пјҢдҫӢеҰӮHystrixгҖҒSentinelзӯүпјҢдҪҝеҫ—иө„жәҗй—ҙдә’дёҚе№Іжү°гҖӮе…¶е®һжң¬иә«Dubboд№ҹеҸҜд»ҘеҜ№дёҚеҗҢзҡ„жңҚеҠЎй…ҚзҪ®дёҚеҗҢзҡ„дёҡеҠЎзәҝзЁӢжұ пјҲйҖҡиҝҮй…ҚзҪ®protocolпјүд»ҺиҖҢе®һзҺ°жңҚеҠЎзҡ„иө„жәҗйҡ”зҰ»пјҢдҪҶжҳҜиҝҷз§Қж–№ејҸзҡ„ејҠз«ҜеңЁдәҺпјҢдёҖж—ҰжңҚеҠЎеўһеӨҡпјҢзәҝзЁӢж•°йҮҸдјҡиҝ…йҖҹиҶЁиғҖгҖӮзәҝзЁӢжұ иҝҮеӨҡдёҚдҫҝдәҺз»ҹдёҖз®ЎзҗҶпјҢеҗҢж—¶иҝҮеӨҡзҡ„зәҝзЁӢжүҖеёҰжқҘиҝҮеӨҡзҡ„дёҠдёӢж–ҮеҲҮжҚўд№ҹдјҡеҪұе“ҚжңҚеҠЎеҷЁжҖ§иғҪгҖӮ
еңЁз»қеӨ§еӨҡж•°еңәжҷҜдёӢпјҢеҜ№жңҚеҠЎиө„жәҗзҡ„йҡ”зҰ»еҸҜд»ҘйҖҡиҝҮејҖжәҗжЎҶжһ¶SentinelжқҘе®һзҺ°пјҢе…¶йҖҡиҝҮй…ҚзҪ®жҹҗдёӘжңҚеҠЎзҡ„并еҸ‘ж•°пјҢжқҘиҫҫеҲ°йҷҗжөҒе’ҢзәҝзЁӢиө„жәҗйҡ”зҰ»зҡ„зӣ®зҡ„гҖӮеқҰзҷҪзҡ„и®ІпјҢиҝҷе·Із»ҸиғҪеӨҹж»Ўи¶із»қеӨ§еӨҡж•°йңҖжұӮдәҶпјҢдҪҶжҳҜжүӢеҠЁеҸ–й…ҚзҪ®иҝҷдәӣеҸӮж•°иҝҳжҳҜжҜ”иҫғжңүйҡҫеәҰзҡ„пјҢеӨ§еӨҡеҫ—йқ еӨ§дҪ¬д»¬зҡ„з»ҸйӘҢдәҶпјҢиҖҢдё”д№ҹдёҚеӨҹзҒөжҙ»гҖӮ
жҲ‘еңЁеӯҰд№ зҡ„ж—¶еҖҷпјҢд№ҹзӘҒеҸ‘еҘҮжғіпјҢжңүжІЎжңүеҸҜиғҪдёҚдҫқиө–еӨ–йғЁзҡ„组件пјҢиҖҢе®һзҺ°еҶ…йғЁзҡ„жңҚеҠЎиө„жәҗйҡ”зҰ»пјҹеҶҚжӣҙиҝӣдёҖжӯҘпјҢжңүжІЎжңүеҸҜиғҪж №жҚ®еә”з”ЁеҶ…еҗ„дёӘжңҚеҠЎзҡ„жөҒйҮҸж•°жҚ®пјҢеҜ№жҜҸдёӘжңҚеҠЎиө„жәҗиҝӣиЎҢеҠЁжҖҒзҡ„еҲҶй…Қе’Ңз»‘е®ҡе‘ўпјҹ
жү“дёӘжҜ”ж–№иҜҙпјҢжҹҗдёӘеә”з”ЁйҮҢеӯҳеңЁAгҖҒBдёӨдёӘжңҚеҠЎпјҢ100дёӘзәҝзЁӢгҖӮзҷҪеӨ©зҡ„ж—¶еҖҷпјҢAжңҚеҠЎзҡ„жөҒйҮҸеӨ§пјҢBжңҚеҠЎзҡ„жөҒйҮҸеҫҲе°ҸпјҢйӮЈд№ҲеңЁиҝҷдёӘж—¶й—ҙж®өеҶ…пјҢжҲ‘们зҡ„еә”з”ЁеҲҶй…Қз»ҷAзҡ„иө„жәҗзҗҶеә”жӣҙеӨҡгҖӮдҪҶжҳҜд№ҹдёҚиғҪе…Ёз»ҷAжӢҝиө°дәҶпјҢBд№ҹеҫ—е–қеҸЈжұӨпјҢдёҚ然еҸҲдјҡеҮәзҺ°зәҝзЁӢиҖ—е°Ҫзҡ„жғ…еҶөпјҢжүҖд»ҘжӯӨж—¶жҲ‘们еҸҜиғҪж №жҚ®жөҒйҮҸж•°жҚ®зҡ„жҜ”еҜ№еҲҶз»ҷAжңҚеҠЎ80дёӘзәҝзЁӢпјҢBжңҚеҠЎ20дёӘзәҝзЁӢпјӣиҖҢеҲ°дәҶжҷҡдёҠпјҢAжңҚеҠЎжІЎе•Ҙдәәз”ЁдәҶпјҢBжңҚеҠЎжөҒйҮҸжқҘдәҶпјҢйӮЈжҲ‘们е°ұз»ҷBжӣҙеӨҡзҡ„иө„жәҗпјҢдҪҶд№ҹиҰҒдҝқиҜҒAеҸҜз”ЁпјҢжҜ”еҰӮиҜҙпјҢAжңҚеҠЎ20зәҝзЁӢпјҢBжңҚеҠЎ80зәҝзЁӢгҖӮ
жҲ‘жүҝи®ӨжҲ‘дёҖејҖе§ӢеҸӘжҳҜжғіз®ҖеҚ•еҶҷдёӘRPCжЎҶжһ¶пјҢеӯҰд№ е®һзҺ°еҺҹзҗҶиҖҢе·ІгҖӮдҪҶзӘҒ然жңүдәҶиҝҷж ·дёҖдёӘжғіжі•пјҢжҲ‘е°ұжқҘдәҶеҠЁеҠӣпјҢжғізңӢзңӢиҮӘе·ұзҡ„жғіжі•иЎҢдёҚиЎҢеҫ—йҖҡпјҢдёӢйқўжҲ‘дҫҝд»Ӣз»ҚдёӢжҲ‘зҡ„жҖқиҖғпјҢиҜҙзҡ„жңүдёҚеҜ№зҡ„ең°ж–№д№ҹж¬ўиҝҺеӨ§е®¶жҢҮеҮәе’ҢжҺўи®ЁгҖӮ
еҖҹйүҙдәҶдј з»ҹзҡ„RPCжЎҶжһ¶зҡ„е®һзҺ°еҺҹзҗҶеҗҺпјҢжҲ‘们еҸӘйңҖиҰҒдҝ®ж”№жҲ–иҖ…еўһеҠ дёүж ·дёңиҘҝпјҢе°ұеҸҜд»Ҙе®ҢжҲҗдёҠиҝ°зҡ„еҠҹиғҪпјҢеҲҶеҲ«дёәпјҡзәҝзЁӢжұ гҖҒж•°жҚ®зӣ‘жҺ§иҠӮзӮ№Metricе’ҢзәҝзЁӢеҠЁжҖҒеҲҶй…Қзҡ„MonitorгҖӮиҝҷдёүиҖ…д№Ӣй—ҙзҡ„е…ізі»еҸҜд»Ҙе…ҲзңӢдёҖдёӢиҝҷеј еӣҫжңүдёӘеӨ§жҰӮзҡ„еҚ°иұЎгҖӮ
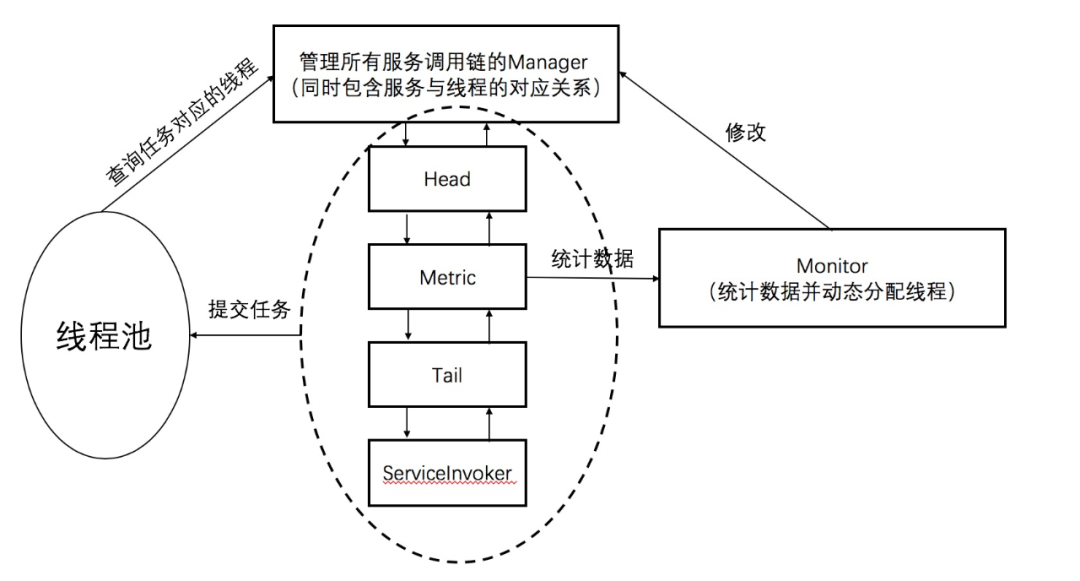
йҰ–е…ҲйңҖиҰҒдҝ®ж”№зҡ„иҮӘ然жҳҜзәҝзЁӢжұ гҖӮд»ҘDubboдёәдҫӢпјҢе…¶й»ҳи®Өзҡ„зәҝзЁӢжұ дёәfixedзәҝзЁӢжұ пјҢioзәҝзЁӢжҺҘ收еҲ°иҜ·жұӮеҗҺпјҢ委жүҳDubboзәҝзЁӢжұ е®ҢжҲҗеҗҺз»ӯзҡ„еӨ„зҗҶпјҢйҖҡиҝҮи°ғз”ЁExecutorService.executeгҖӮ
дҪҶжҳҜеңЁиҝҷйҮҢпјҢдҪҝз”ЁJDKдёӯзҡ„зәҝзЁӢжұ жҳҫ然жҳҜиЎҢдёҚйҖҡдәҶгҖӮзәҝзЁӢжұ дёӯзҡ„Threadд№ҹдёҚеҶҚжҳҜеҚ•зәҜзҡ„ThreadпјҢиҖҢйңҖиҰҒжӣҙиҝӣдёҖжӯҘзҡ„жҠҪиұЎгҖӮиҝҷйҮҢеҸӮиҖғNettyдёӯNioEventLoopзҡ„и®ҫи®ЎжҖқжғіпјҢе°ҶжҜҸжқЎThreadжҠҪиұЎдёәдёҖжқЎLoopпјҢе…¶ж—ўжҳҜд»»еҠЎжү§иЎҢзҡ„жң¬дҪ“ThreadпјҢд№ҹжҳҜExecutorServiceзҡ„жҠҪиұЎпјҢиҖҢжүҖжңүLoopдәӨз”ұLoopGroupз»ҹдёҖз®ЎзҗҶпјҢз”ұLoopGroupеҶіе®ҡе°Ҷд»»еҠЎжҸҗдәӨиҮіе“ӘдёҖдёӘзәҝзЁӢгҖӮиҝҷйҮҢжҲ‘е®һзҺ°зҡ„жҜ”иҫғз®ҖеҚ•пјҢжҜҸдёӘзәҝзЁӢжңүдёӘдё“еұһзҡ„idпјҢйҖҡиҝҮжӢҝеҲ°зәҝзЁӢзҡ„idпјҢе°Ҷд»»еҠЎжҸҗдәӨеҲ°еҜ№еә”зҡ„зәҝзЁӢпјҢеҺҹзҗҶеҸҜд»ҘеҸӮиҖғдёӢеӣҫпјҡ
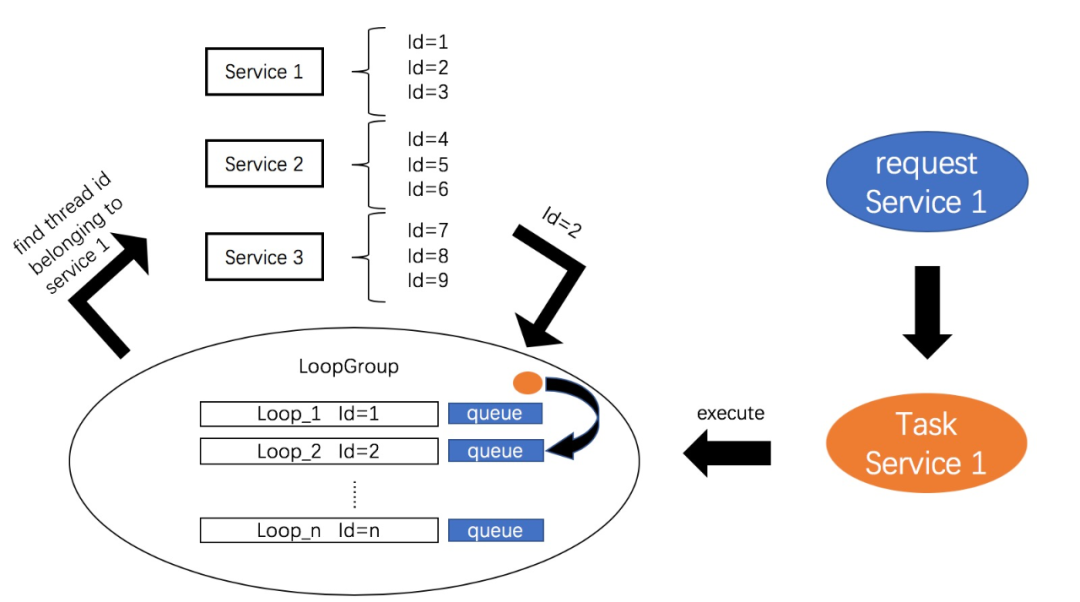
з§Ғд»Ҙдёәж ёеҝғеңЁдәҺз»ҙжҠӨжңҚеҠЎдёҺзәҝзЁӢidзҡ„еҜ№еә”е…ізі»пјҢд»ҘеҸҠеңЁиҜ·жұӮеҲ°жқҘж—¶пјҢLoopGroupдјҡж №жҚ®иҜ·жұӮдёӯжңҚеҠЎзҡ„зұ»еһӢпјҢйҖүжӢ©еҜ№еә”idзҡ„зәҝзЁӢпјҢ并дәӨз”ұиҜҘзәҝзЁӢеҺ»еӨ„зҗҶиҜ·жұӮгҖӮ
ж•°жҚ®зҡ„зӣ‘жҺ§зӣёеҜ№жқҘиҜҙжҳҜжңҖеҘҪеҠһзҡ„гҖӮиҝҷйҮҢжҲ‘еҸӮиҖғдәҶSentinelзҡ„е®һзҺ°пјҢдҪҝз”Ёж—¶й—ҙзӘ—еҸЈжі•з»ҹи®Ўеҗ„дёӘжңҚеҠЎзҡ„жөҒйҮҸж•°жҚ®пјҢеҢ…жӢ¬passгҖҒsuccessгҖҒrtгҖҒrejectгҖҒexcetpionзӯүгҖӮпјҲе…ідәҺSentinelдёӯзҡ„ж—¶й—ҙзӘ—еҸЈпјҢеҗҺйқўжңүж—¶й—ҙеҶҚдё“й—ЁеҶҷзҜҮжәҗз ҒеҲҶжһҗпјү
иҖҢиҮідәҺзӣ‘жҺ§иҠӮзӮ№зҡ„еҪўејҸпјҢж №жҚ®и°ғз”Ёй“ҫи·Ҝзҡ„е…·дҪ“е®һзҺ°дёҚеҗҢпјҢеңЁDubboдёӯеҸҜд»ҘжҳҜдёҖдёӘfilterпјҢиҖҢжҲ‘еӣ дёәе°Ҷи°ғз”Ёй“ҫи·ҜжҠҪиұЎдёәдёҖдёӘPipelineпјҢжүҖд»Ҙе®ғдҪңдёәPipelineдёҠзҡ„дёҖдёӘиҠӮзӮ№пјҢеҸӮиҖғдёӢеӣҫпјҡ
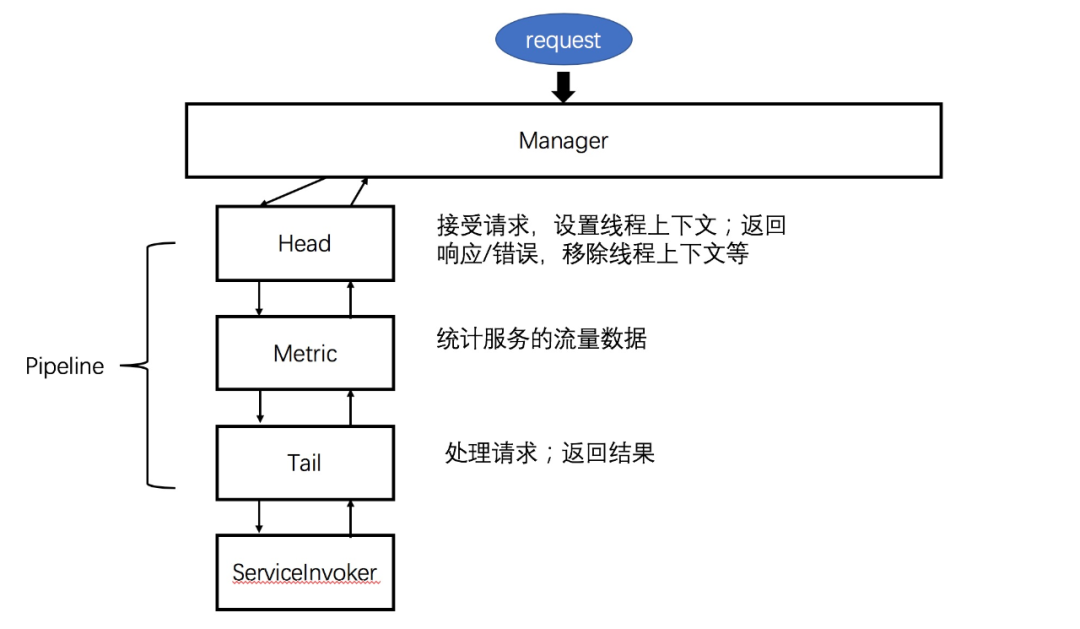
иҝҷйҮҢиҙҙдёҠMetricContextзҡ„е…ій”®жәҗз Ғпјҡ
//еӨ„зҗҶиҜ·жұӮж—¶пјҢpass+1пјҢеҗҢж—¶и®°еҪ•ејҖе§Ӣж—¶й—ҙ并дҝқеӯҳеңЁзәҝзЁӢдёҠдёӢж–Үдёӯ
@Override
protected void handle(Object obj) {
if(obj instanceof RpcRequest){
RpcContext rpcContext=RpcContext.getContext();
rpcContext.setStartTime(TimeUtil.currentTimeMillis());
paladinMetric.addPass(1);
}
}
//е“Қеә”иҜ·жұӮж—¶пјҢиҜҙжҳҺиҜ·жұӮеӨ„зҗҶжӯЈеёёпјҢеҲҷйҖҡиҝҮзәҝзЁӢдёҠдёӢж–ҮжӢҝеҲ°ејҖе§Ӣж—¶й—ҙпјҢ
//и®Ўз®—еҮәе“Қеә”ж—¶й—ҙrtеҗҺе°ҶrtеҶҷе…Ҙз»ҹи®Ўж•°жҚ®пјҢеҗҢж—¶success+1
@Override
protected void response(Object obj) {
RpcContext rpcContext=RpcContext.getContext();
Long startTime=rpcContext.getStartTime();
if(startTime!=null){
Long rt=TimeUtil.currentTimeMillis()-startTime;
paladinMetric.addRT(rt);
paladinMetric.addSuccess(1);
logger.warn(rpcContext.getRpcRequest().getClassName()
+":"
+rpcContext.getRpcRequest().getMethodName()
+" 's RT is "
+rt);
}else{
logger.error(rpcContext.getRpcRequest().getClassName()
+":"
+rpcContext.getRpcRequest().getMethodName()
+"has no start time!");
}
}
//иҝҷйҮҢе°ұжҳҜз»ҹдёҖеӨ„зҗҶејӮеёёзҡ„ж–№жі•пјҢеҢәеҲҶдёәжҷ®йҖҡејӮеёёе’ҢжӢ’з»қејӮеёёпјҢ
//еҰӮжһңжҳҜжӢ’з»қејӮеёёпјҢиҜҙжҳҺзәҝзЁӢе·Іж»ЎпјҢжӢ’з»қж·»еҠ д»»еҠЎпјҢreject+1
@Override
protected void caughtException(Object obj) {
paladinMetric.addException(1);
if(obj instanceof RejectedExecutionException){
paladinMetric.addReject(1);
}
}
жҜҸдёӘContextйғҪдјҡ继жүҝAbstractContextпјҢеҸӘйңҖиҰҒе®һзҺ°handleгҖҒresponseе’ҢcaughtExceptionж–№жі•еҚіеҸҜпјҢз”ұAbstractContextеұҸи”ҪдәҶеә•еұӮpipelineзҡ„йЎәеәҸи°ғз”ЁгҖӮ
жңҖеҗҺе°ұжҳҜеҰӮдҪ•еҠЁжҖҒзҡ„е°ҶзәҝзЁӢеҲҶй…Қз»ҷжңҚеҠЎгҖӮеңЁиҝҷйҮҢпјҢжҲ‘们йңҖиҰҒжҠҪиұЎдёҖдёӘиҜ„д»·жЁЎеһӢпјҢеҺ»иҜ„дј°еҗ„дёӘжңҚеҠЎеә”иҜҘеҚ з”ЁеӨҡе°‘иө„жәҗпјҲзәҝзЁӢпјүпјҢеҸҜд»ҘеҸӮиҖғдёӢеӣҫпјҡ
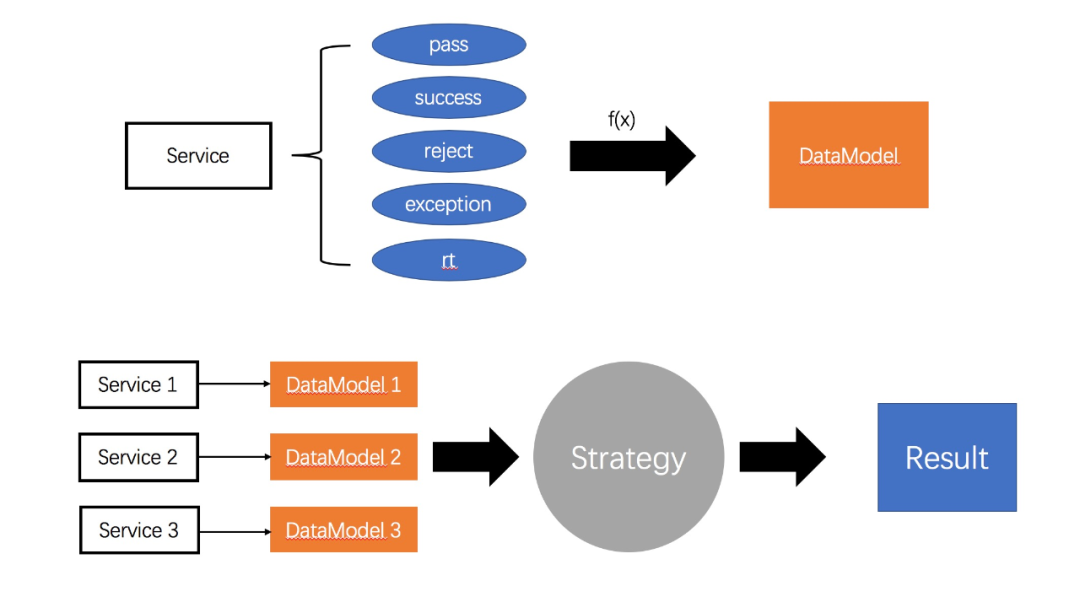
з®ҖеҚ•жқҘиҜҙпјҢз”ұдәҺзӣ‘жҺ§иҠӮзӮ№зҡ„еӯҳеңЁпјҢжҲ‘们еҫҲе®№жҳ“е°ұжӢҝеҲ°жҜҸдёӘжңҚеҠЎзҡ„жөҒйҮҸж•°жҚ®пјҢ然еҗҺжҠҪиұЎеҮәжҜҸдёҖдёӘжңҚеҠЎзҡ„иҜ„д»·жЁЎеһӢпјҢжңҖеҗҺйҖҡиҝҮжҹҗз§Қзӯ–з•ҘпјҢеҫ—еҲ°зәҝзЁӢеҲҶй…Қзҡ„з»“жһңгҖӮ
еҗҢж—¶жңҚеҠЎ-зәҝзЁӢзҡ„еҜ№еә”е…ізі»зҡ„иҜ»еҶҷпјҢжҳҫ然жҳҜдёҖдёӘиҜ»еӨҡеҶҷе°‘зҡ„еңәжҷҜгҖӮеҸҜд»ҘеҗҺеҸ°ејҖеҗҜдёҖдёӘзәҝзЁӢпјҢжҜҸйҡ”дёҖж®өж—¶й—ҙпјҲжҜ”еҰӮ20sпјүпјҢжү§иЎҢдёҖж¬ЎеҠЁжҖҒеҲҶй…Қзҡ„зӯ–з•ҘгҖӮйҮҮз”ЁCopyOnWriteзҡ„жҖқжғіпјҢе°ҶеҜ№еә”е…ізі»зҡ„еј•з”Ёз”Ёvolatileдҝ®йҘ°пјҢзәҝзЁӢйҮҚж–°еҲҶй…Қе®ҢжҲҗд№ӢеҗҺпјҢзӣҙжҺҘжӣҝжҚўжҺүе…¶еј•з”ЁеҚіеҸҜпјҢиҝҷж ·еҜ№жҖ§иғҪзҡ„еҪұе“ҚдҫҝжІЎжңүйӮЈд№ҲеӨ§дәҶгҖӮ
иҝҷйҮҢзҡ„й—®йўҳеңЁдәҺпјҢеҰӮдҪ•еҗҲзҗҶзҡ„еҲ¶е®ҡеҲҶй…Қзҡ„зӯ–з•ҘгҖӮз”ұдәҺжҲ‘е®һеңЁзјәд№Ҹзӣёеә”зҡ„з»ҸйӘҢпјҢжүҖд»ҘеҶҷзҡ„жҜ”иҫғжҚһпјҢеёҢжңӣжңүеӨ§дҪ¬еҸҜд»ҘжҢҮзӮ№дёҖдәҢгҖӮ
иҜҙдәҶиҝҷд№ҲеӨҡпјҢйӮЈжҲ‘们дҫҝжқҘзңӢзңӢж•ҲжһңеҰӮдҪ•гҖӮд»Јз ҒжҲ‘йғҪж”ҫеңЁдәҶgithubдёҠпјҲз”ұдәҺж—¶й—ҙжҜ”иҫғзҹӯеҶҚеҠ дёҠжң¬дәәиҸңпјҢеҶҷеҫ—жҜ”иҫғзІ—зіҷпјҢиҜ·еӨ§е®¶и§Ғи°…T TпјүпјҢд»Јз Ғж ·дҫӢйғҪеңЁpaladin-demoжЁЎеқ—дёӯпјҢиҝҷйҮҢжҲ‘е°ұзӣҙжҺҘдёҠз»“жһңдәҶгҖӮ
е…Ҳе®ҡд№үдёҖдёӢеҸӮж•°пјҢзәҝзЁӢж•°жҖ»е…ұ20пјҢжҜҸдёӘжңҚеҠЎжңҖе°‘иғҪеҲҶй…ҚзәҝзЁӢж•°дёә5пјҢжҜҸжқЎзәҝзЁӢзҡ„йҳ»еЎһйҳҹеҲ—е®№йҮҸдёә4пјҢжңҚеҠЎз«ҜдёӨдёӘжңҚеҠЎпјҢдёҖдёӘйҳ»еЎһж—¶й—ҙй•ҝпјҢеҸҰдёҖдёӘж— йҳ»еЎһгҖӮ
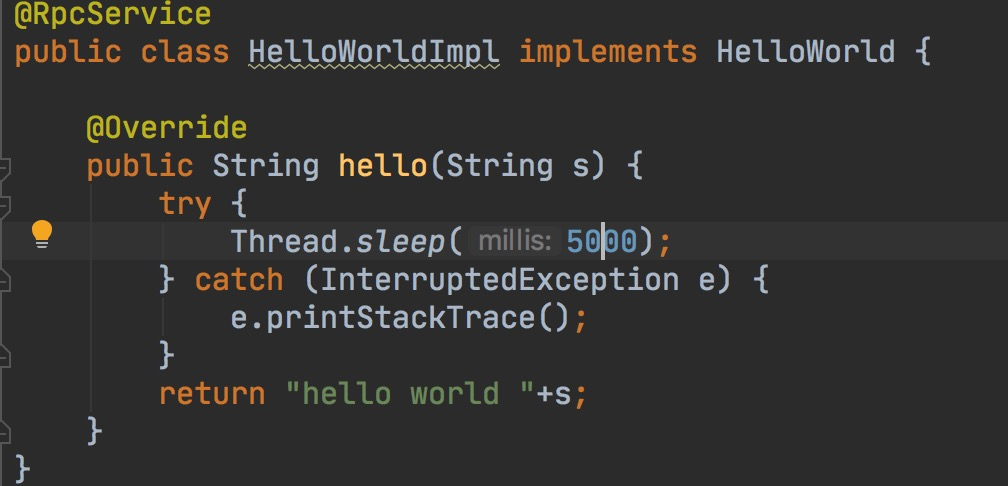
иҝҷйҮҢе…Ҳе®ҡд№үдёҖдёӘйҳ»еЎһж—¶й—ҙй•ҝзҡ„жңҚеҠЎHelloWorldгҖӮ
然еҗҺжҲ‘们йҖҡиҝҮhttpиҜ·жұӮи§ҰеҸ‘д»»еҠЎпјҢжЁЎжӢҹеӨ§жөҒйҮҸиҜ·жұӮгҖӮ
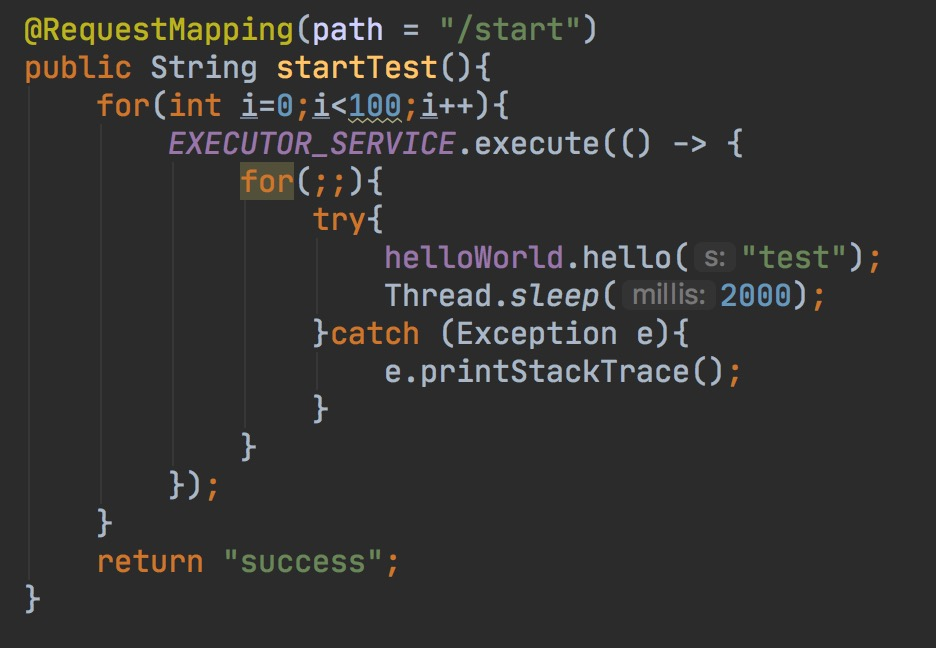
еҗҢж—¶з»ҷеҮәдёҖдёӘж— йҳ»еЎһзҡ„жңҚеҠЎHelloPaladinпјҢеҸҜд»ҘйҖҡиҝҮhttpи®ҝй—®гҖӮ

е…ҲеҗҺеҗҜеҠЁжңҚеҠЎжңҚеҠЎжҸҗдҫӣз«Ҝе’Ңж¶Ҳиҙ№з«ҜпјҢејҖеҗҜд»»еҠЎгҖӮжҺ§еҲ¶еҸ°зӣҙжҺҘзӮёиЈӮгҖӮ
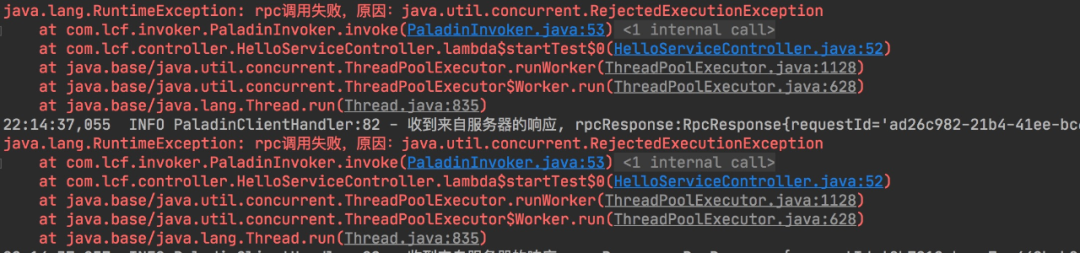
жңҚеҠЎз–ҜзӢӮжҠӣеҮәжӢ’з»қејӮеёёгҖӮжҲ‘们еҶҚиҫ“е…Ҙlocalhost:8080/helloPaladin?value=lalalaпјҢеӨҡзӮ№еҮ ж¬ЎпјҢеҸҜд»ҘеҸ‘зҺ°йЎөйқўеҫҲеҝ«е°ұиғҪиҝ”еӣһз»“жһңпјҢиҝҷд№ҹж„Ҹе‘ізқҖиҝҷдёӘжңҚеҠЎе№¶жІЎжңүиў«е№Іжү°гҖӮ
жңҖеҗҺжҲ‘们жқҘзңӢдёҖдёӢпјҢеңЁд»»еҠЎеҗҜеҠЁеҗҺпјҢзәҝзЁӢеҲҶй…Қзҡ„жғ…еҶөеҰӮдҪ•пјҡ
22:15:06,653 INFO PaladinMonitor:81 - totalScore: 594807
22:15:06,653 INFO PaladinMonitor:91 - service: com.lcf.HelloPaladin:1.0.0_paladin, score: 1646
22:15:06,653 INFO PaladinMonitor:91 - service: com.lcf.HelloWorld:1.0.0_paladin, score: 593161
22:15:06,654 INFO PaladinMonitor:113 - Threads re-distribution result: {com.lcf.HelloPaladin:1.0.0_paladin=[1, 2, 3, 4, 5], com.lcf.HelloWorld:1.0.0_paladin=[6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19]}
第дёҖиЎҢиҫ“еҮәзҡ„жҳҜжүҖжңүжңҚеҠЎжҖ»е…ұзҡ„еҲҶж•°пјҢжҺҘдёӢжқҘдёӨиЎҢеҲҶеҲ«жҳҜдёӨдёӘжңҚеҠЎжүҖеҫ—еҲ°зҡ„еҲҶж•°пјҢжңҖеҗҺдёҖиЎҢжҳҜзәҝзЁӢеҲҶй…Қд№ӢеҗҺзҡ„з»“жһңгҖӮ
жҲ‘们з©ҝжҸ’и°ғз”Ёзҡ„HelloPaladinжңҚеҠЎеҫ—еҲ°зҡ„еҲҶж•°иҝңиҝңдҪҺдәҺи·‘д»»еҠЎзҡ„жңҚеҠЎHelloWorldпјҢдҪҶжҳҜз”ұдәҺи®ҫзҪ®дәҶжңҖе°ҸзәҝзЁӢж•°пјҢжүҖд»ҘHelloPaladinжңҚеҠЎеҲҶеҲ°дәҶ5жқЎзәҝзЁӢпјҢиҖҢHelloWorldжңҚеҠЎеҚ жҚ®дәҶе…¶дҪҷзҡ„зәҝзЁӢгҖӮпјҲиҝҷйҮҢз”ұдәҺиҝҳејҖеҗҜдәҶдёҖдёӘеҚ•зәҝзЁӢжңҚеҠЎпјҢжүҖд»ҘжІЎжңү0еҸ·зәҝзЁӢпјҢиҮідәҺд»Җд№ҲжҳҜеҚ•зәҝзЁӢжңҚеҠЎеҸҜд»ҘзңӢеҗҺж–Үпјү
еҸҜд»ҘзңӢеҲ°пјҢжңҚеҠЎй—ҙзҡ„зәҝзЁӢиө„жәҗзЎ®е®һйҡ”зҰ»дәҶпјҢжҹҗдёҖдёӘжңҚеҠЎзҡ„дёҚеҸҜз”ЁдёҚдјҡеҪұе“ҚеҲ°е…¶д»–жңҚеҠЎпјҢеҗҢж—¶иө„жәҗд№ҹдјҡеҗ‘еӨ§жөҒйҮҸзҡ„жңҚеҠЎеҖҫж–ңгҖӮ
еңЁе®һзҺ°дёҠйқўзҡ„еҠҹиғҪд№ӢеҗҺпјҢжҲ–и®ёиҝҳжңүжӣҙеҠ иҠұе“Ёзҡ„зҺ©жі•гҖӮиҖғиҷ‘иҝҷж ·дёҖдёӘеңәжҷҜпјҢеҰӮжһңжҹҗдёӘжңҚеҠЎеӯҳеңЁйў‘з№ҒеҠ й”Ғзҡ„еңәжҷҜпјҢйӮЈд№ҲеӨҡдёӘзәҝзЁӢ并еҸ‘еҠ й”Ғжү§иЎҢпјҢжңӘеҝ…дјҡжңүеҚ•дёӘзәҝзЁӢдёІиЎҢж— й”Ғжү§иЎҢжқҘзҡ„ж•ҲзҺҮй«ҳпјҢжҜ•з«ҹй”Ғе’ҢзәҝзЁӢеҲҮжҚўзҡ„ејҖй”Җд№ҹдёҚе®№еҝҪи§ҶгҖӮ
еңЁе®һзҺ°дәҶжңҚеҠЎдёҺзәҝзЁӢзҡ„еҜ№еә”е…ізі»д№ӢеҗҺпјҢиҝҷз§ҚдёІиЎҢж— й”Ғжү§иЎҢзҡ„жҖқи·Ҝе°ұеҫҲе®№жҳ“е®һзҺ°дәҶпјҢеңЁеҲқе§ӢеҢ–зҡ„ж—¶еҖҷпјҢзӣҙжҺҘеҲҶй…Қз»ҷиҝҷдёӘжңҚеҠЎеӣәе®ҡзҡ„зәҝзЁӢidеҸ·еҚіеҸҜпјҢиҝҷдёӘзәҝзЁӢд№ҹдёҚдјҡеҸӮдёҺеҗҺз»ӯзҡ„еҠЁжҖҒеҲҶй…ҚжөҒзЁӢгҖӮеҸҜд»ҘйҖҡиҝҮжіЁи§ЈеҸӮж•°зҡ„ж–№ејҸжқҘе®һзҺ°пјҡ
@RpcService(type = RpcConstans.SINGLE)
public class HelloSynWorldImpl implements HelloSynWorld
е°ұжҳҜиҝҷд№Ҳз®ҖеҚ•пјҢжңҚеҠЎеҷЁеҗҜеҠЁд№ӢеҗҺдҪ е°ұдјҡеҸ‘зҺ°пјҢиҝҷдёӘжңҚеҠЎйғҪдјҡдҪҝз”ЁжҹҗжқЎеӣәе®ҡзҡ„зәҝзЁӢеҺ»жү§иЎҢпјҢиҮӘ然д№ҹе°ұз”ЁдёҚзқҖеҠ й”ҒдәҶпјҲйҷӨйқһиҰҒи·ҹе…¶д»–жңҚеҠЎеҗҢж—¶ж“ҚдҪңе…ұдә«иө„жәҗпјҢйӮЈе°ұдёҚйҖӮз”ЁдәҺиҝҷз§ҚеңәжҷҜпјүпјҢдёҚиҝҮиҝҷз§ҚдёІиЎҢеңәжҷҜжҲ‘жғідәҶжғіпјҢеҘҪеғҸ并дёҚеӨҡпјҢеҸӘжңүеңЁйӮЈз§ҚзәҜеҶ…еӯҳзҡ„ж“ҚдҪңдёӯеҸҜиғҪдјҡжҜ”иҫғжңүжҖ§иғҪдјҳеҠҝпјҲжҳҜдёҚжҳҜеҫҲеғҸRedisпјүпјҢжүҖд»Ҙд№ҹе°ұеӣҫдёҖд№җгҖӮ
иҜқеҸҲиҜҙеӣһжқҘдәҶпјҢиҷҪ然解еҶідәҶжңҚеҠЎиө„жәҗйҡ”зҰ»е’ҢеҲҶй…Қзҡ„й—®йўҳпјҢйӮЈд№ҲзӣёжҜ”еҺҹжқҘзҡ„зәҝзЁӢжЁЎеһӢжҳҜеҗҰе°ұжІЎжңүеҠЈеҠҝдәҶе‘ўпјҹ
еӣ дёәеҠ е…ҘдәҶжӣҙеӨҡзҡ„组件пјҢиҖғиҷ‘еҲ°зӣ‘жҺ§иҠӮзӮ№зҡ„жҖ§иғҪжҚҹиҖ—пјҢеўһеҠ дәҶеҲҶй…ҚзәҝзЁӢгҖҒйҖүжӢ©зәҝзЁӢзҡ„йҖ»иҫ‘пјҢжҲ–и®ёеңЁжҖ§иғҪдёҠзӣёжҜ”еҺҹжқҘзҡ„зәҝзЁӢжЁЎеһӢдјҡе·®дёҖзӮ№пјҢиҮідәҺе·®еӨҡе°‘пјҢжҲ‘еҸҜиғҪд№ҹжІЎжі•е®ҡйҮҸз»ҷеҮәи§Јзӯ”пјҢиҝҳйңҖиҰҒиҝӣдёҖжӯҘзҡ„жөӢиҜ•гҖӮдёҚиҝҮеҸҜд»ҘиӮҜе®ҡзҡ„жҳҜпјҢеҸҜд»ҘйҖҡиҝҮжӣҙеӨҡзҡ„дјҳеҢ–пјҢдҪҝеҫ—дёӨиҖ…зҡ„жҖ§иғҪжӣҙеҠ жҺҘиҝ‘пјҢдҫӢеҰӮпјҡз”ЁJcToolзҡ„ж— й”ҒйҳҹеҲ—жӣҝжҚўJDKдёӯзҡ„йҳ»еЎһйҳҹеҲ—пјӣз»ҷеҮәеҗҲйҖӮзҡ„иҜ„д»·жЁЎеһӢпјҢдҪҝеҫ—иө„жәҗеҲҶй…ҚжӣҙеҗҲзҗҶд»ҘеҸҠеҲҶй…ҚиҝҮзЁӢжҖ§иғҪжӣҙдјҳзӯүзӯүгҖӮ
еҪ“然жңҖе…ій”®зҡ„иҝҳжҳҜдҪ дёҡеҠЎд»Јз ҒеҶҷзҡ„е’Ӣж ·пјҢжҜ•з«ҹжЎҶжһ¶дјҳеҢ–зҡ„еҶҚеҘҪпјҢдёҡеҠЎд»Јз ҒдёҚеӨ§иЎҢпјҢйӮЈзӮ№дјҳеҢ–ж•Ҳжһңеҫ®д№Һе…¶еҫ®гҖӮ
д»ҘдёҠе°ұжҳҜжҖҺд№ҲжҺўи®ЁRPCжЎҶжһ¶дёӯзҡ„жңҚеҠЎзәҝзЁӢйҡ”зҰ»пјҢе°Ҹзј–зӣёдҝЎжңүйғЁеҲҶзҹҘиҜҶзӮ№еҸҜиғҪжҳҜжҲ‘们ж—Ҙеёёе·ҘдҪңдјҡи§ҒеҲ°жҲ–з”ЁеҲ°зҡ„гҖӮеёҢжңӣдҪ иғҪйҖҡиҝҮиҝҷзҜҮж–Үз« еӯҰеҲ°жӣҙеӨҡзҹҘиҜҶгҖӮжӣҙеӨҡиҜҰжғ…敬иҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ