您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
两年多没有搭建过apache hadoop的环境了,昨天再次搭建hadoop环境,将过程记录下来,以便以后查阅。
主机角色分配:
NameNode、DFSZKFailoverController 角色由 oversea-stable、bus-stable 服务器承担;需要安装软件有:JDK、Hadoop2.9.1
ResourceManager角色由 oversea-stable 服务器承担;需要安装软件有:JDK、Hadoop2.9.1
JournalNode、DataNode、NodeManager角色由open-stable、permission-stable、sp-stable服务器承担;需要安装软件有:JDK、Hadoop2.9.1
zookeeper cluster的QuorumPeerMain角色由open-stable、permission-stable、sp-stable服务器承担;需要安装软件有:JDK、zookeeper3.4.12
1、环境设置
(1) 设置主机名,并配置本地解析(主机名与解析必须配置一致,否则journalnode无法启动)
[root@oversea-stable ~]# cat /etc/hosts
192.168.20.68 oversea-stable
192.168.20.67 bus-stable
192.168.20.66 open-stable
192.168.20.65 permission-stable
192.168.20.64 sp-stable
[root@oversea-stable ~]# 并将该文件同步到所有机器 上。
(2) 各节点同步时间
(3) 同步jdk,并在所有节点上安装jdk
(4) 配置环境变量
在/etc/profile文件中加入如下设置:
export JAVA_HOME=/usr/java/latest
export HADOOP_HOME=/opt/hadoop
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$PATH2、配置SSH 密钥,并复制给本机(ssh本机时也需要免密码登录)
在所有机器上如下操作:
(1) 创建hadoop用户,useradd hadoop
(2) 设置hadoop用户的密码: echo "xxxxxxxx" | passwd --stdin hadoop
在其中一台server上切换hadoop: su - hadoop
并生成 ssh 密钥: ssh-keygen -b 2048 -t rsa
同步密钥到其它server 上 : scp -r .ssh server_name:~/
每台server 切换 hadoop用户,验证是否能够免密登录其它server
3、配置zookeeper
在 open-stable 、permission-stable、sp-stable server 上配置zookeeper cluster,如下操作:
[root@open-stable ~]# chmod o+w /opt
[root@open-stable ~]# su - hadoop
[hadoop@open-stable ~]$ wget http://mirrors.hust.edu.cn/apache/zookeeper/zookeeper-3.4.12/zookeeper-3.4.12.tar.gz
[hadoop@open-stable ~]$ tar xfz zookeeper-3.4.12.tar.gz -C /opt
[hadoop@open-stable ~]$ cd /opt/
[hadoop@open-stable opt]$ mv zookeeper{-3.4.12,}
[hadoop@open-stable opt]$ cd zookeeper/
[hadoop@open-stable zookeeper]$ cp conf/zoo_sample.cfg conf/zoo.cfg
[hadoop@open-stable zookeeper]$ vim conf/zoo.cfg
[hadoop@open-stable zookeeper]$ grep -Pv "^(#|$)" conf/zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/opt/zookeeper/zkdata
dataLogDir=/opt/zookeeper/zklogs
clientPort=2181
server.6=open-stable:2888:3888
server.5=permission-stable:2888:3888
server.4=sp-stable:2888:3888
[hadoop@open-stable zookeeper]$ mkdir zkdata
[hadoop@open-stable zookeeper]$ mkdir zklogs
[hadoop@open-stable zookeeper]$ echo 6 > zkdata/myid
[hadoop@open-stable zookeeper]$ bin/zkServer.sh start
其它server 配置相同
[hadoop@open-stable zookeeper]$ bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper/bin/../conf/zoo.cfg
Mode: leader
[hadoop@open-stable zookeeper]$
[hadoop@permission-stable zookeeper]$ bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper/bin/../conf/zoo.cfg
Mode: follower
[hadoop@permission-stable zookeeper]$
[hadoop@sp-stable zookeeper]$ bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper/bin/../conf/zoo.cfg
Mode: follower
[hadoop@sp-stable zookeeper]$ 4、配置hadoop
(1) 在其中一台上配置hadoop ,如下操作:
[hadoop@oversea-stable ~]$ wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.9.1/hadoop-2.9.1.tar.gz
[hadoop@oversea-stable ~]$ tar xfz hadoop-2.9.1.tar.gz -C /opt/
[hadoop@oversea-stable ~]$ cd /opt/
[hadoop@oversea-stable opt]$ ln -s hadoop-2.9.1 hadoop
[hadoop@oversea-stable opt]$ cd hadoop/etc/hadoop
[hadoop@oversea-stable hadoop]$ grep JAVA_HOME hadoop-env.sh
export JAVA_HOME=/usr/java/latest
[hadoop@oversea-stable hadoop]$
[hadoop@oversea-stable hadoop]$ tail -14 core-site.xml
<configuration>
<!-- 指定hdfs的nameservice为inspiryhdfs -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://inspiryhdfs</value>
</property>
<!-- 指定hadoop临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/tmp</value>
</property>
<!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>open-stable:2181,permission-stable:2181,sp-stable:2181</value>
</property>
</configuration>
[hadoop@oversea-stable hadoop]$
[hadoop@oversea-stable hadoop]$ tail -50 hdfs-site.xml
<configuration>
<!--指定hdfs的nameservice为inspiryhdfs,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>inspiryhdfs</value>
</property>
<!-- 定义inspiryhdfs下有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.inspiryhdfs</name>
<value>nn1,nn2</value>
</property>
<!-- 分别指定nn1的RPC通信地址、与http通信地址 -->
<property>
<name>dfs.namenode.rpc-address.inspiryhdfs.nn1</name>
<value>oversea-stable:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.inspiryhdfs.nn1</name>
<value>oversea-stable:50070</value>
</property>
<!-- 分别指定nn2的RPC通信地址、与http通信地址 -->
<property>
<name>dfs.namenode.rpc-address.inspiryhdfs.nn2</name>
<value>bus-stable:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.inspiryhdfs.nn2</name>
<value>bus-stable:50070</value>
</property>
<!-- 指定NameNode 元数据存放的JournalNode -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://open-stable:8485;permission-stable:8485;sp-stable:8485/inspiryhdfs</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/hadoop/journal</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换的方式 -->
<property>
<name>dfs.client.failover.proxy.provider.inspiryhdfs</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
</configuration>
指定MapReduce运行在yarn框架之上
[hadoop@oversea-stable hadoop]$ cp mapred-site.xml{.template,}
[hadoop@oversea-stable hadoop]$ tail -6 mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
[hadoop@oversea-stable hadoop]$
指定DataNode节点
[hadoop@oversea-stable hadoop]$ cat slaves
open-stable
permission-stable
sp-stable
[hadoop@oversea-stable hadoop]$
[hadoop@oversea-stable hadoop]$ tail -11 yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- 指定resourcemanager地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>oversea-stable</value>
</property>
<!-- 指定nodemanager启动时加载server的方式为shuffle server -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
[hadoop@oversea-stable hadoop]$(2) 将配置完毕的hadoop 同步到其它servers上
[hadoop@oversea-stable opt]$ rsync -avzoptgl hadoop-2.9.1 bus-stable:/opt/
[hadoop@oversea-stable opt]$ rsync -avzoptgl hadoop-2.9.1 open-stable:/opt/
[hadoop@oversea-stable opt]$ rsync -avzoptgl hadoop-2.9.1 permission-stable:/opt/
[hadoop@oversea-stable opt]$ rsync -avzoptgl hadoop-2.9.1 sp-stable:/opt/其它各servers 创建 hadoop 的 soft link
(3) 启动journalnode
sbin/hadoop-daemons.sh start journalnode 在oversea-stable上格式化namenode,并启动主namenode
hadoop namenode -format
sbin/hadoop-daemon.sh start namenode
[hadoop@oversea-stable hadoop]$ ls /opt/hadoop/tmp/dfs/name/current/
fsimage_0000000000000000000 seen_txid
fsimage_0000000000000000000.md5 VERSION(4) standby_namenode同步数据
在oversea-stable 节点格式化namenode,并启动namenode之后,在bus-stable节点上同步namenode信息,避免再次对namenode格式化(同时保证bus-stable上也有/opt/hadoop/tmp目录)。在bus-stable上如下操作:
bin/hdfs namenode -bootstrapStandby
sbin/hadoop-daemon.sh start namenode 5、格式化zkfs(让namenode可以将本机状态汇报给zookeeper)
hdfs zkfc -formatZK
(如果格式化失败,要检查 core-site.xml中指定的zookeeper地址是否完全正确)
6、启动hdfs
[hadoop@oversea-stable hadoop]$ sbin/start-dfs.sh
Starting namenodes on [oversea-stable bus-stable]
bus-stable: starting namenode, logging to /opt/hadoop-2.9.1/logs/hadoop-hadoop-namenode-bus-stable.out
oversea-stable: starting namenode, logging to /opt/hadoop-2.9.1/logs/hadoop-hadoop-namenode-oversea-stable.out
sp-stable: starting datanode, logging to /opt/hadoop-2.9.1/logs/hadoop-hadoop-datanode-sp-stable.out
permission-stable: starting datanode, logging to /opt/hadoop-2.9.1/logs/hadoop-hadoop-datanode-permission-stable.out
open-stable: starting datanode, logging to /opt/hadoop-2.9.1/logs/hadoop-hadoop-datanode-open-stable.out
Starting journal nodes [open-stable permission-stable sp-stable]
sp-stable: starting journalnode, logging to /opt/hadoop-2.9.1/logs/hadoop-hadoop-journalnode-sp-stable.out
open-stable: starting journalnode, logging to /opt/hadoop-2.9.1/logs/hadoop-hadoop-journalnode-open-stable.out
permission-stable: starting journalnode, logging to /opt/hadoop-2.9.1/logs/hadoop-hadoop-journalnode-permission-stable.out
Starting ZK Failover Controllers on NN hosts [oversea-stable bus-stable]
oversea-stable: starting zkfc, logging to /opt/hadoop-2.9.1/logs/hadoop-hadoop-zkfc-oversea-stable.out
bus-stable: starting zkfc, logging to /opt/hadoop-2.9.1/logs/hadoop-hadoop-zkfc-bus-stable.out
[hadoop@oversea-stable hadoop]$ 7、启动yarn(Namenode和ResourceManger如果不是同一台机器,不能在NameNode上启动 yarn,必须在ResouceManager机器上启动yarn)
[hadoop@oversea-stable hadoop]$ sbin/start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /opt/hadoop-2.9.1/logs/yarn-hadoop-resourcemanager-oversea-stable.out
sp-stable: starting nodemanager, logging to /opt/hadoop-2.9.1/logs/yarn-hadoop-nodemanager-sp-stable.out
open-stable: starting nodemanager, logging to /opt/hadoop-2.9.1/logs/yarn-hadoop-nodemanager-open-stable.out
permission-stable: starting nodemanager, logging to /opt/hadoop-2.9.1/logs/yarn-hadoop-nodemanager-permission-stable.out
[hadoop@oversea-stable hadoop]$ 8、验证各节点的角色
[hadoop@oversea-stable hadoop]$ sbin/start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /opt/hadoop-2.9.1/logs/yarn-hadoop-resourcemanager-oversea-stable.out
sp-stable: starting nodemanager, logging to /opt/hadoop-2.9.1/logs/yarn-hadoop-nodemanager-sp-stable.out
open-stable: starting nodemanager, logging to /opt/hadoop-2.9.1/logs/yarn-hadoop-nodemanager-open-stable.out
permission-stable: starting nodemanager, logging to /opt/hadoop-2.9.1/logs/yarn-hadoop-nodemanager-permission-stable.out
[hadoop@oversea-stable hadoop]$
[hadoop@oversea-stable ~]$ jps
4389 DFSZKFailoverController
5077 ResourceManager
25061 Jps
4023 NameNode
[hadoop@oversea-stable ~]$
[hadoop@bus-stable ~]$ jps
9073 Jps
29956 NameNode
30095 DFSZKFailoverController
[hadoop@bus-stable ~]$
[hadoop@open-stable ~]$ jps
2434 DataNode
421 QuorumPeerMain
2559 JournalNode
2847 NodeManager
11903 Jps
[hadoop@open-stable ~]$
[hadoop@permission-stable ~]$ jps
30489 QuorumPeerMain
32505 JournalNode
9689 Jps
32380 DataNode
303 NodeManager
[hadoop@permission-stable ~]$
[hadoop@sp-stable ~]$ jps
29955 DataNode
30339 NodeManager
30072 JournalNode
6792 Jps
28060 QuorumPeerMain
[hadoop@sp-stable ~]$ 在浏览器中输入:http://oversea-stable:50070/,以及http://bus-stable:50070/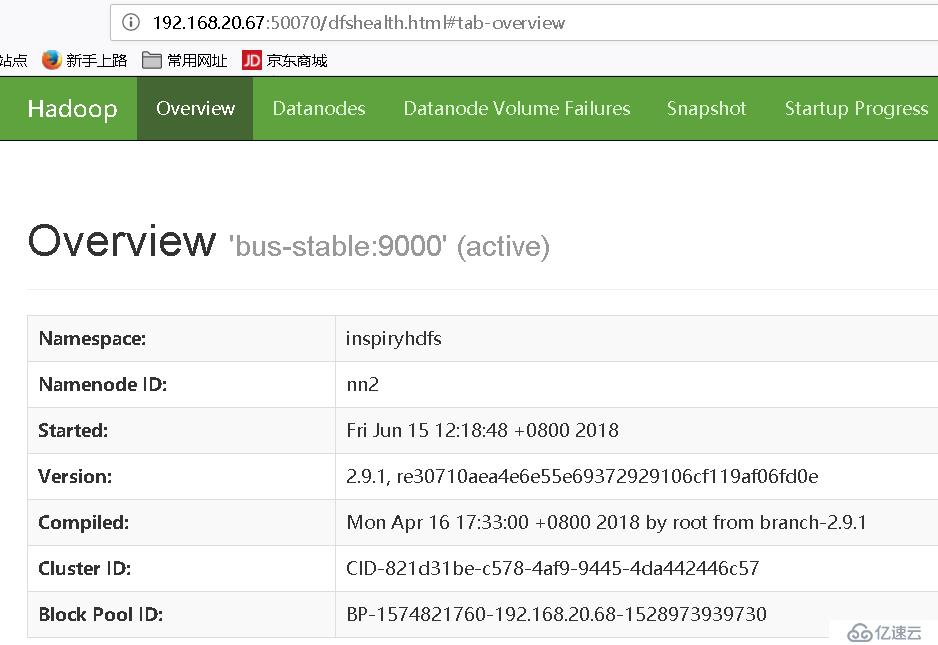
上面可以看到bus-stable是处于active状态,oversea-stable是处于standby,接下来测试以下namenode的高可用,当bus-stable挂掉时oversea-stable是否能够自动切换;
在bus-stable中kill掉NameNode进程
[root@bus-stable ~]# jps
1614 NameNode
2500 Jps
1929 DFSZKFailoverController
[root@bus-stable ~]# kill -9 1614再次刷新http://bus-stable:50070/,无法访问;刷新http://oversea-stable:50070/
这时oversea-stable已经处于active状态了,这说明切换是没有问题的,现在已经完成了hadoop集群的高可用的搭建;
输入:http://oversea-stable:8088 查看hadoop cluster 状态,如下所示: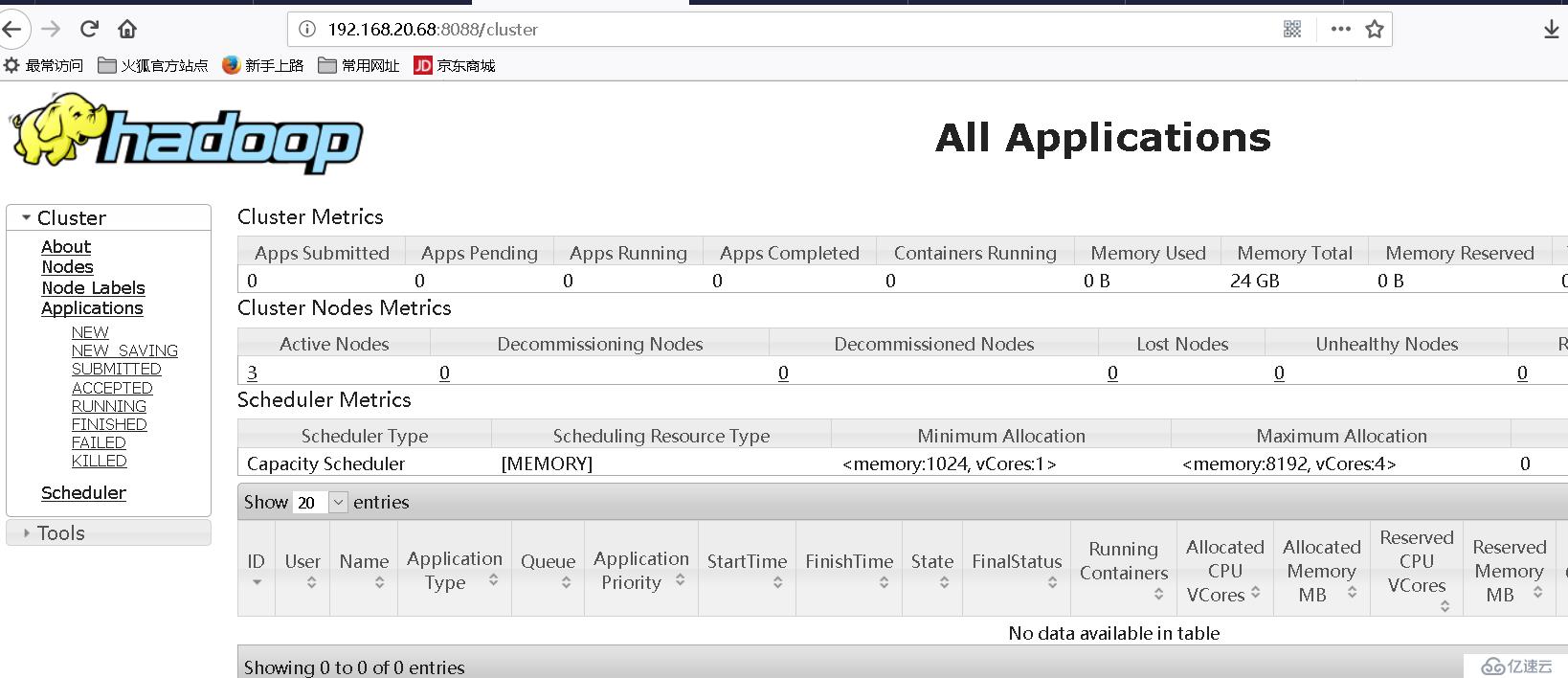
9、hadoop的应用
[hadoop@oversea-stable hadoop]$ hdfs dfs -ls /
Found 2 items
drwxr-xr-x - hadoop supergroup 0 2018-06-15 10:32 /data
[hadoop@oversea-stable ~]$ hdfs dfs -put /tmp/notepad.txt /data/notepad.txt
[hadoop@oversea-stable ~]$ cd /opt/hadoop
[hadoop@oversea-stable hadoop]$ ls share/hadoop/mapreduce/
hadoop-mapreduce-client-app-2.9.1.jar hadoop-mapreduce-client-jobclient-2.9.1.jar lib
hadoop-mapreduce-client-common-2.9.1.jar hadoop-mapreduce-client-jobclient-2.9.1-tests.jar lib-examples
hadoop-mapreduce-client-core-2.9.1.jar hadoop-mapreduce-client-shuffle-2.9.1.jar sources
hadoop-mapreduce-client-hs-2.9.1.jar hadoop-mapreduce-examples-2.9.1.jar
hadoop-mapreduce-client-hs-plugins-2.9.1.jar jdiff
[hadoop@oversea-stable hadoop]$
[hadoop@oversea-stable hadoop]$
[hadoop@oversea-stable hadoop]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.1.jar wordcount /data /out1
18/06/15 11:04:53 INFO client.RMProxy: Connecting to ResourceManager at oversea-stable/192.168.20.68:8032
18/06/15 11:04:54 INFO input.FileInputFormat: Total input files to process : 1
18/06/15 11:04:54 INFO mapreduce.JobSubmitter: number of splits:1
18/06/15 11:04:54 INFO Configuration.deprecation: yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled
18/06/15 11:04:54 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1528979206314_0002
18/06/15 11:04:55 INFO impl.YarnClientImpl: Submitted application application_1528979206314_0002
18/06/15 11:04:55 INFO mapreduce.Job: The url to track the job: http://oversea-stable:8088/proxy/application_1528979206314_0002/
18/06/15 11:04:55 INFO mapreduce.Job: Running job: job_1528979206314_0002
18/06/15 11:05:02 INFO mapreduce.Job: Job job_1528979206314_0002 running in uber mode : false
18/06/15 11:05:02 INFO mapreduce.Job: map 0% reduce 0%
18/06/15 11:05:08 INFO mapreduce.Job: map 100% reduce 0%
18/06/15 11:05:14 INFO mapreduce.Job: map 100% reduce 100%
18/06/15 11:05:14 INFO mapreduce.Job: Job job_1528979206314_0002 completed successfully
18/06/15 11:05:14 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=68428
FILE: Number of bytes written=535339
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=88922
HDFS: Number of bytes written=58903
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=3466
Total time spent by all reduces in occupied slots (ms)=3704
Total time spent by all map tasks (ms)=3466
Total time spent by all reduce tasks (ms)=3704
Total vcore-milliseconds taken by all map tasks=3466
Total vcore-milliseconds taken by all reduce tasks=3704
Total megabyte-milliseconds taken by all map tasks=3549184
Total megabyte-milliseconds taken by all reduce tasks=3792896
Map-Reduce Framework
Map input records=1770
Map output records=5961
Map output bytes=107433
Map output materialized bytes=68428
Input split bytes=100
Combine input records=5961
Combine output records=2366
Reduce input groups=2366
Reduce shuffle bytes=68428
Reduce input records=2366
Reduce output records=2366
Spilled Records=4732
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=145
CPU time spent (ms)=2730
Physical memory (bytes) snapshot=505479168
Virtual memory (bytes) snapshot=4347928576
Total committed heap usage (bytes)=346554368
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=88822
File Output Format Counters
Bytes Written=58903
[hadoop@oversea-stable hadoop]$
[hadoop@oversea-stable hadoop]$ hdfs dfs -ls /out1/
Found 2 items
-rw-r--r-- 3 hadoop supergroup 0 2018-06-15 11:05 /out1/_SUCCESS
-rw-r--r-- 3 hadoop supergroup 58903 2018-06-15 11:05 /out1/part-r-00000
[hadoop@oversea-stable hadoop]$
[hadoop@oversea-stable hadoop]$ hdfs dfs -cat /out1/part-r-00000自定义map-reduce函数运行任务如下效果:
[hadoop@oversea-stable hadoop]$ hadoop jar /opt/hadoop/share/hadoop/tools/lib/hadoop-streaming-2.9.1.jar -file /opt/map.py -mapper /opt/map.py -file /opt/reduce.py -reducer /opt/reduce.py -input /data/notepad.txt -output /out2
18/06/15 14:30:32 WARN streaming.StreamJob: -file option is deprecated, please use generic option -files instead.
packageJobJar: [/opt/map.py, /opt/reduce.py, /tmp/hadoop-unjar5706672822735184593/] [] /tmp/streamjob6067385394162603509.jar tmpDir=null
18/06/15 14:30:33 INFO client.RMProxy: Connecting to ResourceManager at oversea-stable/192.168.20.68:8032
18/06/15 14:30:33 INFO client.RMProxy: Connecting to ResourceManager at oversea-stable/192.168.20.68:8032
18/06/15 14:30:34 INFO mapred.FileInputFormat: Total input files to process : 1
18/06/15 14:30:34 INFO mapreduce.JobSubmitter: number of splits:2
18/06/15 14:30:34 INFO Configuration.deprecation: yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled
18/06/15 14:30:35 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1529036356241_0004
18/06/15 14:30:35 INFO impl.YarnClientImpl: Submitted application application_1529036356241_0004
18/06/15 14:30:35 INFO mapreduce.Job: The url to track the job: http://oversea-stable:8088/proxy/application_1529036356241_0004/
18/06/15 14:30:35 INFO mapreduce.Job: Running job: job_1529036356241_0004
18/06/15 14:30:42 INFO mapreduce.Job: Job job_1529036356241_0004 running in uber mode : false
18/06/15 14:30:42 INFO mapreduce.Job: map 0% reduce 0%
18/06/15 14:30:48 INFO mapreduce.Job: map 100% reduce 0%
18/06/15 14:30:54 INFO mapreduce.Job: map 100% reduce 100%
18/06/15 14:30:54 INFO mapreduce.Job: Job job_1529036356241_0004 completed successfully
18/06/15 14:30:54 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=107514
FILE: Number of bytes written=823175
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=93092
HDFS: Number of bytes written=58903
HDFS: Number of read operations=9
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=2
Launched reduce tasks=1
Data-local map tasks=2
Total time spent by all maps in occupied slots (ms)=7194
Total time spent by all reduces in occupied slots (ms)=3739
Total time spent by all map tasks (ms)=7194
Total time spent by all reduce tasks (ms)=3739
Total vcore-milliseconds taken by all map tasks=7194
Total vcore-milliseconds taken by all reduce tasks=3739
Total megabyte-milliseconds taken by all map tasks=7366656
Total megabyte-milliseconds taken by all reduce tasks=3828736
Map-Reduce Framework
Map input records=1770
Map output records=5961
Map output bytes=95511
Map output materialized bytes=107520
Input split bytes=174
Combine input records=0
Combine output records=0
Reduce input groups=2366
Reduce shuffle bytes=107520
Reduce input records=5961
Reduce output records=2366
Spilled Records=11922
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=292
CPU time spent (ms)=4340
Physical memory (bytes) snapshot=821985280
Virtual memory (bytes) snapshot=6525067264
Total committed heap usage (bytes)=548929536
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=92918
File Output Format Counters
Bytes Written=58903
18/06/15 14:30:54 INFO streaming.StreamJob: Output directory: /out2
[hadoop@oversea-stable hadoop]$
[hadoop@oversea-stable hadoop]$ hdfs dfs -ls /out2
Found 2 items
-rw-r--r-- 3 hadoop supergroup 0 2018-06-15 14:30 /out2/_SUCCESS
-rw-r--r-- 3 hadoop supergroup 58903 2018-06-15 14:30 /out2/part-00000
[hadoop@oversea-stable hadoop]$
[hadoop@oversea-stable hadoop]$ cat /opt/map.py
#!/usr/bin/python
import sys
for line in sys.stdin:
line = line.strip()
words = line.split()
for word in words:
print "%s\t%s" % (word, 1)
[hadoop@oversea-stable hadoop]$
[hadoop@oversea-stable hadoop]$ cat /opt/reduce.py
#!/usr/bin/python
from operator import itemgetter
import sys
current_word = None
current_count = 0
word = None
for line in sys.stdin:
line = line.strip()
word, count = line.split('\t',1)
try:
count = int(count)
except ValueError:
continue
if current_word == word:
current_count += count
else:
if current_word:
print "%s\t%s" % (current_word, current_count)
current_count = count
current_word = word
if word == current_word:
print "%s\t%s" % (current_word, current_count)
[hadoop@oversea-stable hadoop]$ 免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。