您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这期内容当中小编将会给大家带来有关基于RNN网络的Deepfake检测是怎样的,文章内容丰富且以专业的角度为大家分析和叙述,阅读完这篇文章希望大家可以有所收获。
今天给大家介绍的是一篇基于CNN+RNN结构的检测Deepfakes框架
大部分检测假脸工作是在图片上进行的,而针对deepfake视频往往有很少检测方法。这个工作里我们提出了一种基于时间序列的处理方法,用于检测Deepfake视频。我们采用了CNN去提取帧级别的高维特征,并用这些高维特征训练RNN。我们展示了通过一个简单的架构也能在检测任务上达到不俗的效果。
深度学习方法可用于图片压缩性能, 最常用的就是自编解码器(AutoEncoder-Decoder)。自编码器可以通过最小化损失函数,将图片压缩成一个高维特征,这比现有的压缩方法都要来的高效
而编码器则是将高维特征映射回图片,如Figure2所示
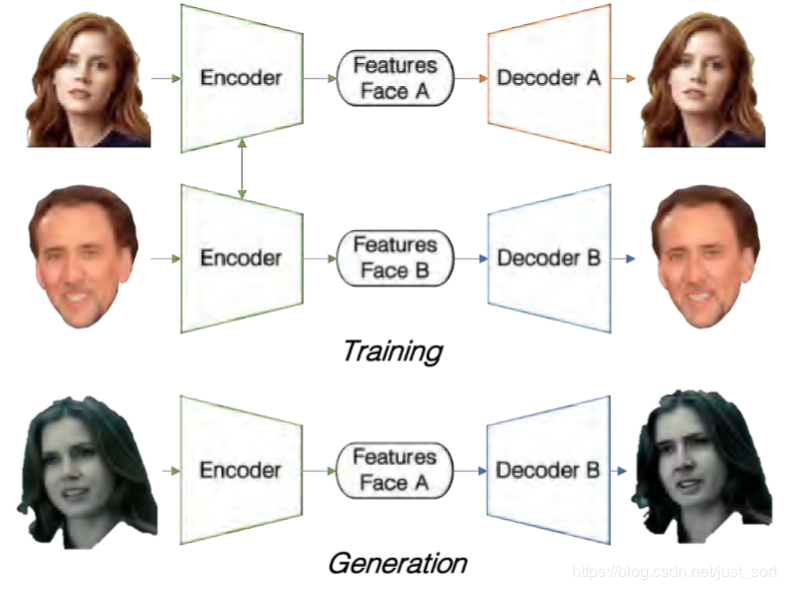
使得Deepfakes生效,关键是将两个潜在的人脸编码到相同的特征上
我们通过共享一个自编码器权重,而去分别训练两个自解码器。
当我们去替换人脸的时候,先对输入图像编码,再用目标人脸解码器去解码
但是自编解码器在不同摄像角度,不同光照等复杂条件下,很难去生成人脸。种种条件变化导致人脸替换部分与背景在视觉上不一致,这种帧级别的场景不一致性将是我们方法利用的第一个特性
第二个特性来自于替换人脸需要用到人脸检测器,而自编解码器只关注人脸部分,很少去关注余下的背景信息,因此最后融合很容易出现边界效应
第三个特性是自编解码器是独立于每一帧的,它并不考虑前后帧生成人脸图片效果。最突出的是帧与帧之间光源的不一致性,导致假脸有闪烁现象,这种特征是很适合使用CNN来进行像素级别的检测。
至此我们确定了基础架构,由CNN提取帧特征,由LSTM进行时间序列上的分析,我们的网络还包含2个全连接层加Dropout以防模型过拟合
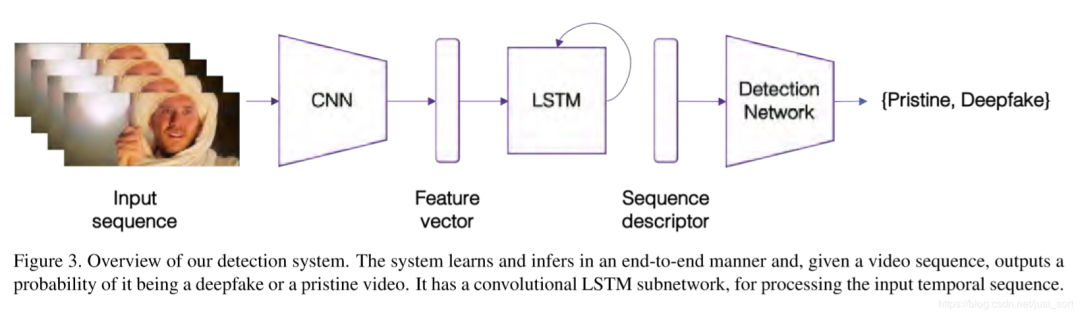
我们使用预训练后的InceptionV3网络作为CNN结构,对输入的图片抽取出2048个特征。
抽取得到的2048特征,送入LSTM单元,接一个512单元的全连接层,0.5概率的Dropout,最后通过softmax计算概率,做最终的二分类
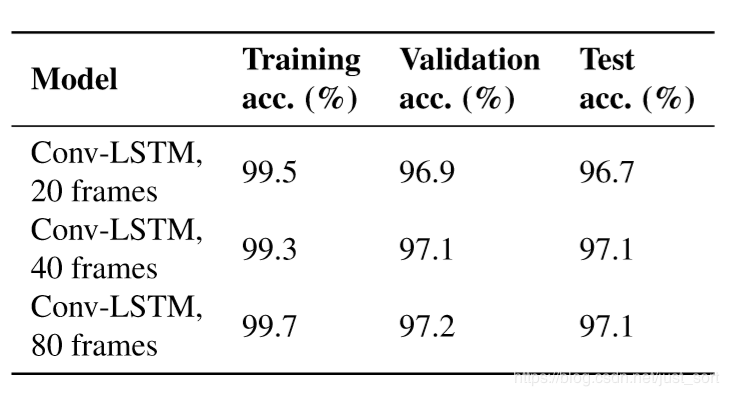
最终结果显示增加帧序列,能提高一定的准确率,但是提升幅度不是很大
上述就是小编为大家分享的基于RNN网络的Deepfake检测是怎样的了,如果刚好有类似的疑惑,不妨参照上述分析进行理解。如果想知道更多相关知识,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。