您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
Faster R-CNN的四个模块分别是什么,相信很多没有经验的人对此束手无策,为此本文总结了问题出现的原因和解决方法,通过这篇文章希望你能解决这个问题。
Faster R-CNN是目标检测中较早提出来的两阶段网络,其网络架构如下图所示:
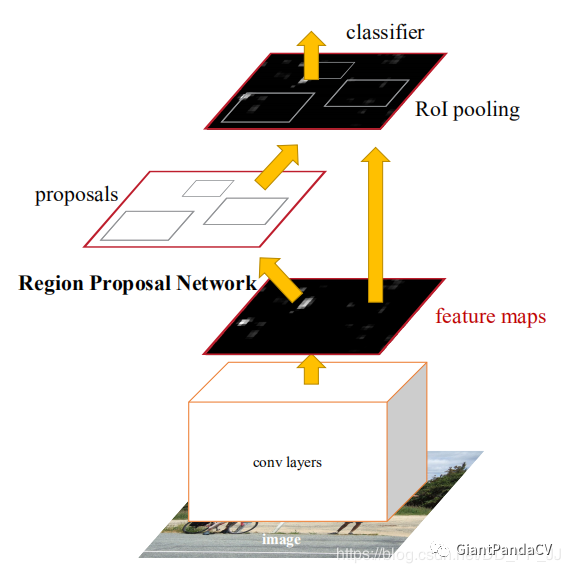
可以看出可以大体分为四个部分:
在Conv Layers中,对输入的图片进行卷积和池化,用于提取图片特征,最终希望得到的是feature map。在Faster R-CNN中,先将图片Resize到固定尺寸,然后使用了VGG16中的13个卷积层、13个ReLU层、4个maxpooling层。(VGG16中进行了5次下采样,这里舍弃了第四次下采样后的部分,将剩下部分作为Conv Layer提取特征。)
与YOLOv3不同,Faster R-CNN下采样后的分辨率为原始图片分辨率的1/16(YOLOv3是变为原来的1/32)。feature map的分辨率要比YOLOv3的Backbone得到的分辨率要大,这也可以解释为何Faster R-CNN在小目标上的检测效果要优于YOLOv3。
简称RPN网络,用于推荐候选区域(Region of Interests),接受的输入为原图片经过Conv Layer后得到的feature map。
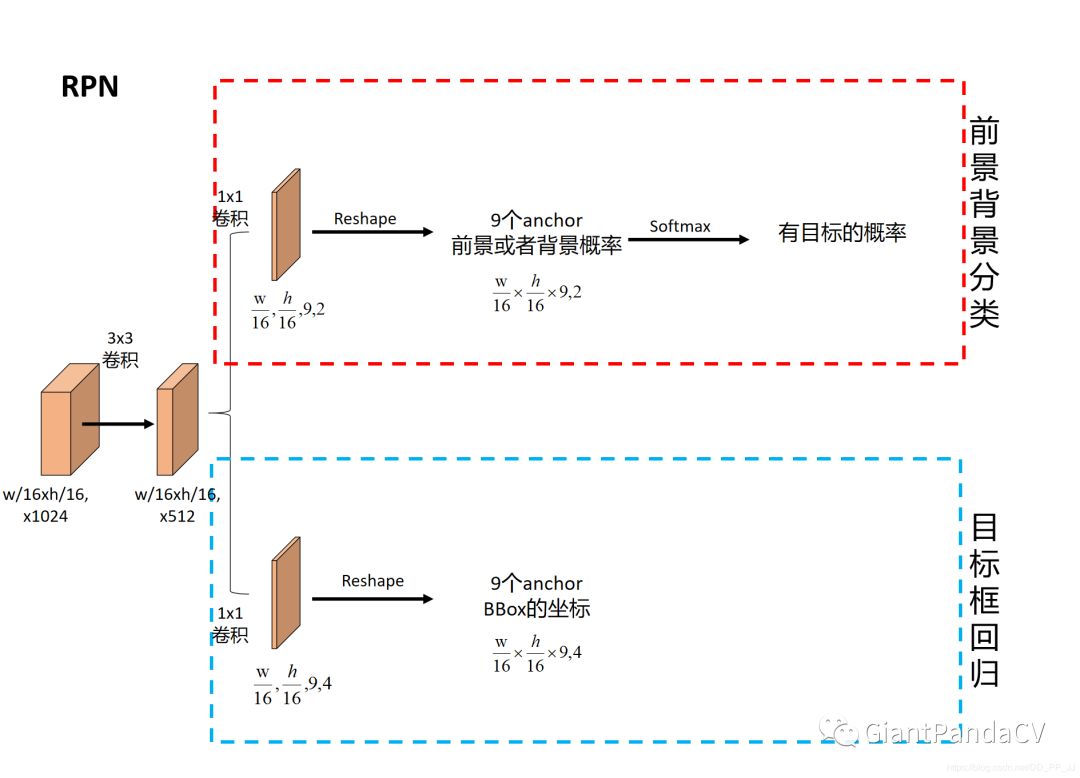
RPN网络将feature map作为输入,然后用了一个3x3卷积将filter减半为512,然后进入两个分支:
一个分支用于计算对应anchor的foreground和background的概率,目标是foreground。
一个分支用于计算对应anchor的Bounding box的偏移量,来获得其目标的定位。
通过RPN网络,我们就得到了每个anchor是否含有目标和在含有目标情况下目标的位置信息。
对比RPN和YOLOv3:
都说YOLOv3借鉴了RPN,这里对比一下两者:
RPN: 分两个分支,一个分支预测目标框,一个分支预测前景或者背景。将两个工作分开来做的,并且其中前景背景预测分支功能是判断这个anchor是否含有目标,并不会对目标进行分类。另外就是anchor的设置是通过先验得到的。
YOLOv3: 将整个问题当做回归问题,直接就可以获取目标类别和坐标。Anchor是通过IoU聚类得到的。
区别:Anchor的设置,Ground truth和Anchor的匹配细节不一样。
联系:两个都是在最后的feature map(w/16,h/16或者w/32,h/32)上每个点都分配了多个anchor,然后进行匹配。虽然具体实现有较大的差距,但是这个想法有共同点。
这里看一个来自deepsense.ai提供的例子:
RoI Pooling输入是feature map和RoIs:
假设feature map是如下内容:
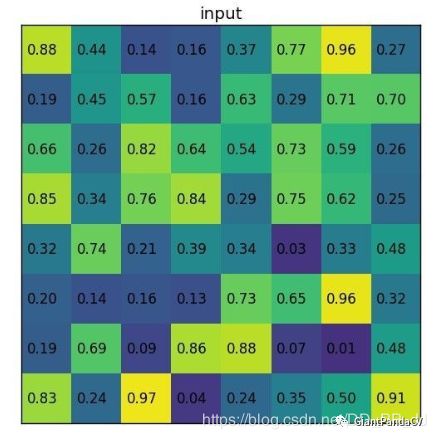
RPN提供的其中一个RoI为:左上角坐标(0,3),右下角坐标(7,8)
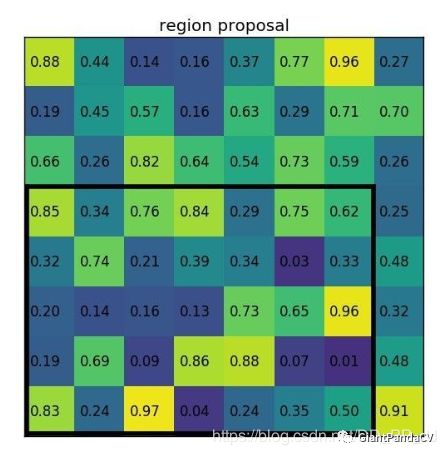
然后将RoI对应到feature map上的部分切割为2x2大小的块:
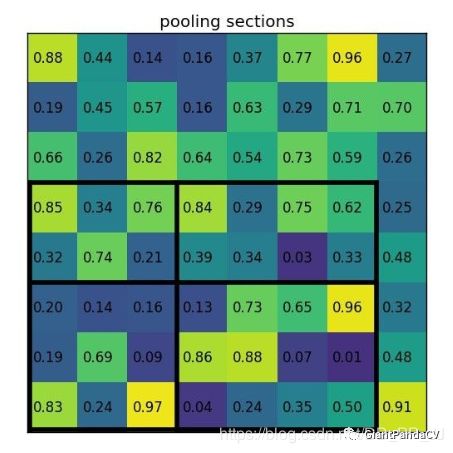
将每个块做类似maxpooling的操作,得到以下结果:
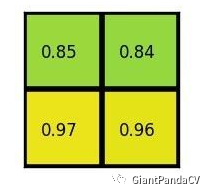
以上就是ROI pooling的完整操作,想一想为何要这样做?
在RPN阶段,我们得知了当前图片是否有目标,在有目标情况下目标的位置。现在唯一缺少的信息就是这个目标到底属于哪个类别(通过RPN只能得知这个目标属于前景,但并不能得到具体类别)。
如果想要得知这个目标属于哪个类别,最简单的想法就是将得到的框内的图片放入一个CNN进行分类,得到最终类别。这就涉及到最后一个模块:classification
ROIPooling后得到的是大小一致的feature,然后分为两个分支,靠下的一个分支去进行分类,上一个分支是用于Bounding box回归。
分类这个分支很容易理解,用于计算到底属于哪个类别。Bounding box回归的分支用于调整RPN预测得到的Bounding box,让回归的结果更加精确。
看完上述内容,你们掌握Faster R-CNN的四个模块分别是什么的方法了吗?如果还想学到更多技能或想了解更多相关内容,欢迎关注亿速云行业资讯频道,感谢各位的阅读!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。