本篇文章给大家分享的是有关为正确的工作该如何选择正确的SQL引擎,小编觉得挺实用的,因此分享给大家学习,希望大家阅读完这篇文章后可以有所收获,话不多说,跟着小编一起来看看吧。
我们都渴望获得数据。不仅是更多的数据……还有新的数据类型,以便我们能够最好地了解我们的产品、客户和市场。我们正在寻找有关各种形状和大小(结构化和非结构化)的最新可用数据的实时洞察力。我们希望拥抱新一代的业务和技术专业人员,这些人员是对数据和能够改变数据与我们生活息息相关的新一代技术有真正热情。
我可以举例说明我的意思。大约两年前,数据挽救了我朋友女儿的性命。出生时,她被诊断出患有七个心脏缺陷。由于采用了3D交互式、虚拟建模和更智能的EKG分析,现代化的病床监控解决方案以及其他以数据为依据的改进的医疗程序等新技术,她在两次心脏直视手术中幸存下来,如今过着健康的生活。数据挽救了她的生命。这就是让我每天都有动力去寻找新的创新和方法,以便尽快向最需要的人提供数据。CDP从头开始构建为企业数据云(EDC)。EDC具有多种功能,能够在一个平台上实现许多用例。通过使用混合和多云部署,CDP可以存在于从裸机到公共云和私有云的任何地方。随着我们在中央IT计划中采用更多云解决方案,我们看到混合云和多云是新常态。但是,大多数混合匹配环境都会在管理方面造成差距,从而在安全性、可追溯性和合规性方面带来新的风险。为解决此问题,CDP具有先进的安全性和控制功能,可以使数据民主化,而不会冒未能遵守法规遵从性和安全性政策的风险。 CDP上的CDW是一项新服务,使您能够为商业智能(BI)分析师团队创建自助数据仓库。您可以快速配置新的数据仓库,并与特定团队或部门共享任何数据集。您还记得何时可以自行设置数据仓库吗?没有基础架构和平台团队的参与?这是
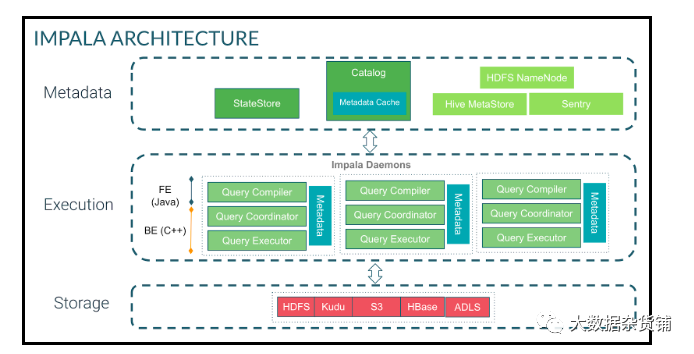
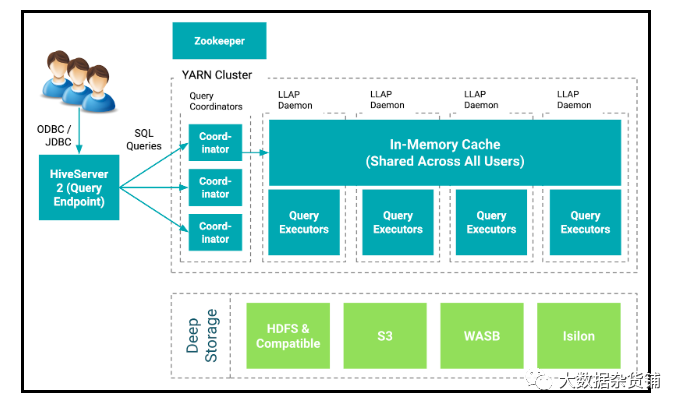
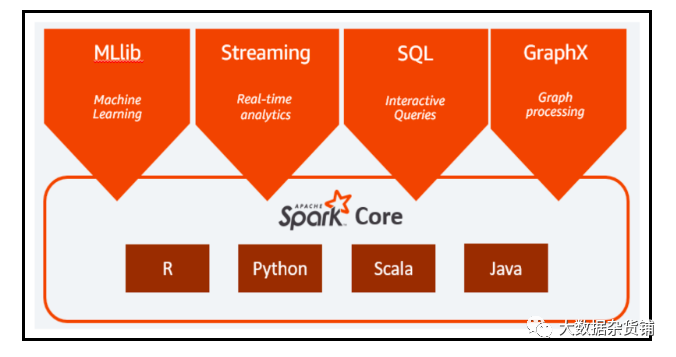
永远不可能的。CDW完成了这一任务。 但是,CDW使几个SQL引擎可用,带来了更多的选择同时带来了更多的混乱。让我们探索CDP上CDW中可用的SQL引擎,并讨论哪种是针对正确用例的正确SQL选项。如此多的选择!Impala?Hive LLAP?Spark?什么时候使用?让我们来探索。Impala是Cloudera Distribution Hadoop(CDH)和CDP中流行的开源、可大规模扩展的MPP引擎。Impala在低延迟、高度交互的SQL查询上赢得了市场信任。Impala具有非常好的可扩展性,不仅支持Parquet的Hadoop分布式文件系统(HDFS)、优化行列(ORC)、JavaScript对象表示法(JSON)、Avro和文本格式,还提供对Kudu、Microsoft Azure Data Lake Storage的本地支持(ADLS)和Amazon Simple Storage Service(S3)。Impala对Sentry或Ranger都具有强大的安全性,并且已知能够在1000 PB大小的数据集上支持1000多个用户的群集。让我们简要看一下整个Impala架构。Impala使用StateStore检查集群的运行状况。如果Impala节点由于任何原因脱机,则StateStore会通知所有其他节点,并且避免了无法访问的节点。Impala目录服务管理到群集中所有节点的所有SQL语句的元数据。StateStore和目录服务与Hive MetaStore进行通信以获取块和文件的位置,然后将元数据与工作节点进行通信。当查询请求进入时,它转到许多查询协调器之一,在该查询协调器中编译请求并开始计划。返回计划片段,协调员安排执行。中间结果在Impala服务之间进行流传输并返回。该体系结构非常适合当我们需要商业智能数据集市具有低延迟查询响应时(通常在探索性临时,自助服务和发现用例类型中发现)。在这种情况下,我们让客户报告了对复杂查询的亚秒级到五秒级的响应时间。 对于物联网(IoT)数据和相关用例,Impala与流解决方案(如NiFi,Kafka或Spark Streaming)以及适当的数据存储(如Kudu)一起可以提供不到十秒的端到端管道延迟。Impala具有对S3,ADLS,HDFS,Hive,HBase等的原生的读/写功能,是运行低于1000个节点的集群(有100万亿行或更多的表,或者50PBB大小或者更大的数据集)时使用的出色SQL引擎。“实时长期处理”或“长期延迟分析处理”(也称为LLAP)是Hive下的执行引擎,它通过利用相同的资源进行缓存和处理来支持长期运行的流程。该执行引擎为我们提供了非常低的延迟SQL响应,因为我们没有资源的加速时间。最重要的是,LLAP遵守并执行了安全策略,因此对于用户而言,它是完全透明的,从而帮助Hive工作负载的性能甚至可以与当今最流行的传统数据仓库环境匹敌。 Hive LLAP提供了大数据生态系统中最成熟的SQL引擎。Hive LLAP专为大数据而构建,为用户提供了高度可扩展的企业数据仓库(EDW),该数据库支持繁重的转换,长期运行的查询或蛮力风格的SQL(具有数百个联接)。Hive支持物化视图、代理键和约束,以提供类似于传统关系系统的SQL体验,包括对查询结果和查询数据的内置缓存。Hive LLAP可以减少重复查询的负载,以提供亚秒级的响应时间。通过与Kafka和Druid的合作,Hive LLAP可以支持对HDFS和对象存储以及流和实时的联合查询。 因此,Hive LLAP非常适合作为企业数据仓库(EDW)解决方案,在该解决方案中,我们将遇到许多需要长时间进行的长时间运行的查询,这些查询需要进行大量转换,或者在海量数据集的表之间进行多次联接。借助Hive LLAP中包含的缓存技术,我们的客户能够将3,300亿条记录与920亿条记录(无论是否具有分区键)连接在一起,并在数秒内返回结果。 Spark是一种通用的高性能数据引擎,旨在支持分布式数据处理,并且适用于各种用例。有许多用于数据科学和机器学习的Spark库,它们支持更高级别的编程模型以加快开发速度。在Spark之上是Spark SQL,MLlib,Spark Streaming和GraphX。
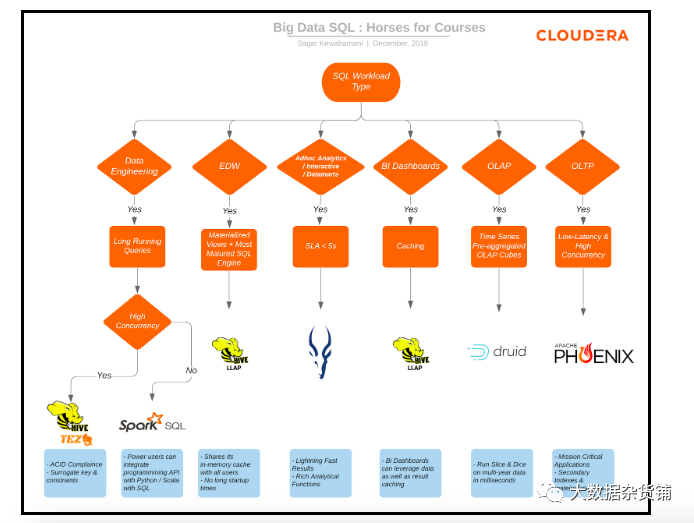
Spark SQL是用于结构化数据处理的模块,与Hive,Avro,Parquet,ORC,JSON和JDBC固有的各种数据源兼容。Spark SQL在半结构化数据集上非常有效,并与Hive MetaStore和NoSQL存储(例如HBase)原生集成。Spark通常与我们喜欢的语言(例如Java,Python,R和Scala)中的编程API很好地结合在一起使用。 当您需要将SQL查询和Spark程序一起嵌入数据工程工作负载中时,Spark非常有用。我们在运行Spark的全球100强企业中拥有许多用户,以减少对流数据工作负载的整体处理。将其与MLlib结合使用,我们看到许多客户都喜欢Spark来进行数据仓库应用程序的机器学习。凭借高性能、低延迟和出色的第三方工具集成,Spark SQL为在编程和SQL之间切换提供了最佳环境。由于您可以在CDP的CDW中混合和匹配相同的数据,因此您可以根据工作负载类型为每个工作负载选择合适的引擎,例如数据工程,传统EDW,临时分析,BI仪表板,在线分析处理(OLAP)或在线交易处理(OLTP)。下面的图表提供了一些指导原则,说明哪些引擎和技术适合每种目的。如果您正在运行支持BI仪表板的EDW,则Hive LLAP将为您带来最佳效果。当您需要临时的、自助式和探索性数据集市时,请查看Impala的优势。如果您正在使用长时间运行的查询而没有高并发性的数据工程,Spark SQL是一个不错的选择。如果需要高并发支持,可以查看Hive on Tez。为了获得对带有时间序列数据的OLAP的支持,请考虑将Druid添加到混合中,如果您正在寻找需要低延迟和高并发性的OLTP,请考虑将Phoenix添加到混合中。
底线– CDP上的CDW中有很多SQL引擎,这是有目的的。提供选择是在不折衷的情况下针对海量数据进行大规模高并发性优化的最终方法。CDP上的CDW通过单一的安全性、治理、可追溯性和元数据层,可提供通用的数据上下文和共享的数据体验,从而可在优化的存储上混合使用SQL引擎。这使您可以自由使用针对您的工作负载进行了优化的最佳SQL引擎。以上就是为正确的工作该如何选择正确的SQL引擎,小编相信有部分知识点可能是我们日常工作会见到或用到的。希望你能通过这篇文章学到更多知识。更多详情敬请关注亿速云行业资讯频道。