您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这期内容当中小编将会给大家带来有关怎么实现数据库内部存储结构探索,文章内容丰富且以专业的角度为大家分析和叙述,阅读完这篇文章希望大家可以有所收获。
我一直以来都在不断的研究和探索数据库的内部存储原理。我认为这个话题是非常巨大且复杂的,我努力所学也只占其千万分之一。我将会讲解一些数据库存储的内部机制,数据库是如何进行优化操作来提供惊人速度及其优势和缺点。
当我们谈起数据库内部存储结构时,人们都会想到B树或者B+树,但是我们在这里并不会谈论这些数据结构的原理,我们会展示这些数据结构为什么适合作为数据库存储的内部结构以及使用这些数据结构的目的。
传统的关系型数据将数据以B树的形式存储在磁盘上,它们也会在RAM上使用B树维护这些数据的索引,来保证更快的访问速度。插入的行存储在B树的叶子节点上,所有的中间节点用来存储用于导航查询语句的原数据。
因此,当有数以百万计的数据被插入到数据库中时,索引和数据存储会变得十分大。因此,为了快速的访问,需要从磁盘中加载所有数据到内存,但是RAM一般没有这么大的空间来存储所有的数据。因此,数据库必须从磁盘中读取部分数据。这种加载数据的场景如下图所示:
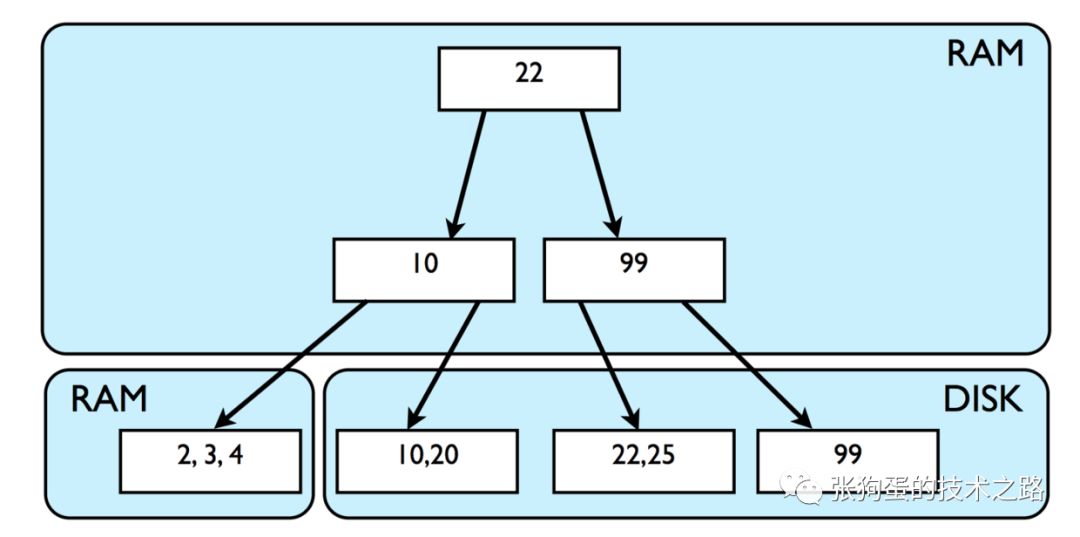
磁盘I/O花费的时间很长,是影响数据库性能的主要原因之一。B树是支持随机读写,in-place 替换,十分紧凑并且自平衡的数据结构,但是受磁盘I/O速度的限制。随机读意味着当访问磁盘数据时,磁头必须移动到柱面上的指定位置,因此会消耗大量时间。
B树被设计为使用block的形式存储数据,因为操作系统读取读取一个block的数据要比读取单独字节数据要快的多。MySQL的InnoDB存储引擎的block大小为16KB。这意味着每次你读取或者写入数据时,大小为16KB的block数据会被从磁盘加载到RAM中,它会被写入新的数据,并且再次写回到磁盘上。假设数据库表的每一行数据为128字节(实际大小会变化),一个block(叶子节点)为16KB,存储了(16 * 1024) / 128 = 128行数据。
B树的高度一般小于10,但是每一层的节点数量却很多,由此可以管理数以万计的数据。基于上述特性,B树适合作为数据内部存储结构。
因此,在B树上进行读操作是相对来说比较快速的,因为该操作只需要遍历一些节点并且进行较少次数的磁盘I/O请求。而且,范围查询因为可以将数据以block的形式进行获取和操作而速度更快。你可以进行下列操作来让基于B-Tree的数据库性能更好:
减少索引节点数量:这是提升关系型数据库性能的常用策略。索引越多,插入和更新操作需要管理的索引数量也越多。当数据库数据运行时间越来越久时,就需要删除一些老旧或者无用的索引,并且谨慎地添加新的索引。但是你也要注意,索引越少意味着查询性能越差,你需要在查询性能和插入更新性能之间进行取舍(译者注:可以考虑数据库的读写比率)。
顺序插入:如果你能以主键大小为基础进行大量数据的顺序插入,那么插入数据的速度会十分的快。因为在插入过程中,插入行所属的block已经在内存中,所以数据库可以直接将行插入到内存的数据结构中,然后通过一次磁盘I/O提交到数磁盘中。当然,这些都取决于数据库的具体实现,但是我认为现代的数据库一般都会进行类似的优化。
但是B树并不是适合所有情景的最优存储结构。对B树结构的写操作性能很差,比随机读还要差,因为数据库必须从磁盘中加载数据对应的页,然后修改它并冲洗新写入到磁盘中。随机写入时平均有100字节每秒写入速度,这个限制是由于磁盘的基本工作原理。
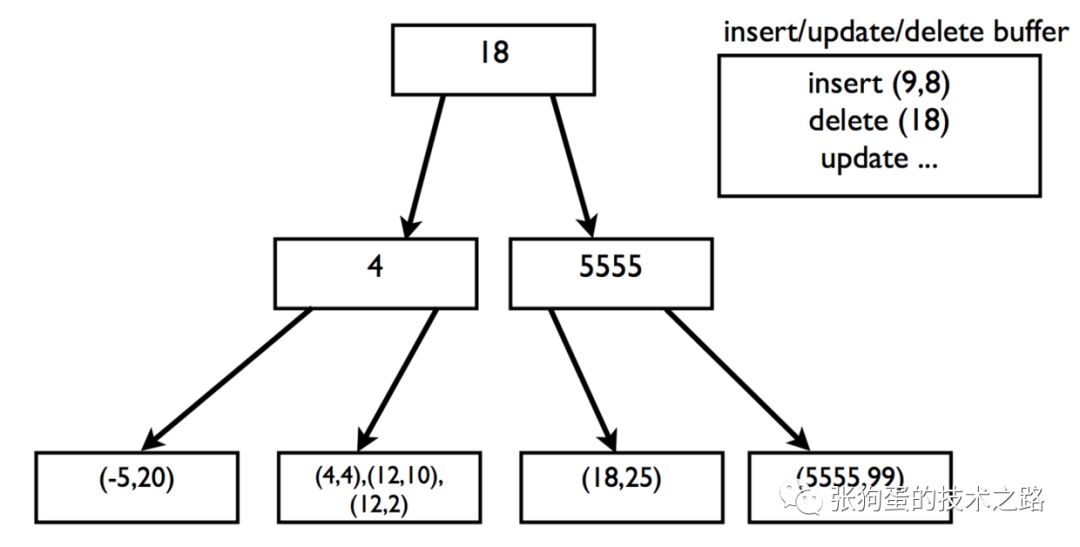
事实上,简单依赖于缓存的使用,索引搜索和更多的内存可以处理更多的读操作,但是应付更多的写操作就比较麻烦。当你需要写入或更新大量的数据时,B树结构并不是最正确的选择。长久以来,传统数据库进行了大量的优化,比如说InnoDB尝试使用缓冲来减少磁盘I/O操作。具体操作如下所示:
数据库写操作可以通过提升磁盘的带宽来提升速度,但是目前关系型数据库都没有这样做。而且关系型数据库管理系统一般都是十分复杂的,因为他们使用锁,并发,ACID事务等操作,这使得写入操作更加复杂。
当今信息时代,在比如消息、聊天、实时通讯和物联网等客户为中心的服务和大量无结构化数据的分布式系统中,每小时都会进行数百万计的写入操作。因此,这些系统是以写为主的系统,为了迎合这些系统的需要,数据库需要能够拥有快速插入数据的能力。典型的数据库并不能很好的满足类似的场景,因为它们无法应付高可用性,尽可能的最终一致性,无格式数据的灵活性和低延迟等要求。
LSM树(Log Structured Merge Tree)应运而生。LSM并不是一种类似于B树的数据结构,而是一个系统。在LSM系统中,并没有对数据的in-place替换;一旦数据被写入磁盘,它就再也不会被修改。显然,它是一种只能在末尾添加(append only)的写入系统。一些日志结构的文件系统比如ext3/4也使用类似的原理。
因此,该系统就如同顺序的记录数据日志一般。基本上,LSM系统利用了顺序写的优势。传统的磁盘驱动的写操作最高可以达到100MB/s,现代的固态硬盘在顺序写时的速度则更快。事实上,固态硬盘驱动有一些内置的并行机制来让它可以同时写入16到32MB的数据。LSM树和固态硬盘的特性十分匹配。顺序写要比随机写快很多。
为了正确地理解上述场景,让我们简单的看一下Facebook的Cassandra数据库是如何使用LSM原则的。
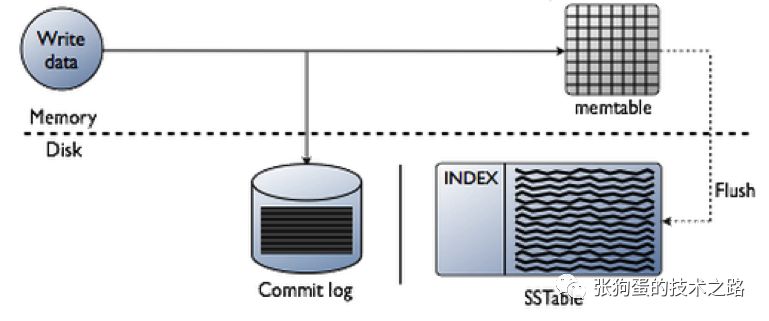
Cassandra或者任何LSM系统都会维护一个或者多个用来在写入磁盘前存储数据的内存数据结构(如上图中的memtable),比如说子平衡树(AVL)、红黑树、B树或者跳表。该内存数据结构维护一个排序的数据集。
不同的LSM实现互使用不同的数据结构来适应不同的需求,并不存在标准的LSM实现。当内存中存储的数据超过配置的阈值时,内存中存储的数据就会被放置在将会被写入磁盘的队列中。为了flush数据,Cassandra顺序地写入排序的数据到磁盘中。
磁盘维护一个叫做“SSTable”(Sorted Strings Table)的数据结构,该数据就是写入文件数据的有序的快照,SSTable是不可变的。LSM系统可以管理磁盘上的多个文件。
因此,如果数据在内存中没有被发现,Cassandra需要扫描所有磁盘上的SSTables来搜索该数据。因此,Cassandra的读操作相对来说要比写操作慢,但是这里有一些可以处理的方法。Cassandra或者其他LSM系统会在后台运行压缩程序来减少SSTable的数量。压缩程序对SSTable进行归并排序,在新的SSTable找那个插入新的排序数据并且删除老的SSTables。但是使用压缩程序有时候无法应付数据库中数以百万计的更新操作。
因此,一些概率数据结构(probabilistic data structures)比如Bloom filters被应用来快速判断是否一些数据存在于SSTable。Bloom filters十分适合对内存中的数据进行判断,因为它需要进行大量的随机查询来进行数据是否存在的概率性判断。Bloom filters算法可以极大地减少遍历查询SSTables的花费。因此,LSM系统解决了在大数据中写操作需要花费大量时间的问题。
LSM系统也有Read amplification的问题-会读取出比它实际需要更多的数据。因此,还有介于B Tree和LSM Tree之间的解决方法来给出我们最优(不一定准确)的读写效率吗?
Fractal Tree Index是基于B-Tree的数据结构。依据开发人员给出的benchmark,该数据结构有比B-Tree更优良的性能。Fractal tree支持在非叶节点上的信息缓存。MySQL的高性能存储引擎Tokudb就使用了Fractal tree。
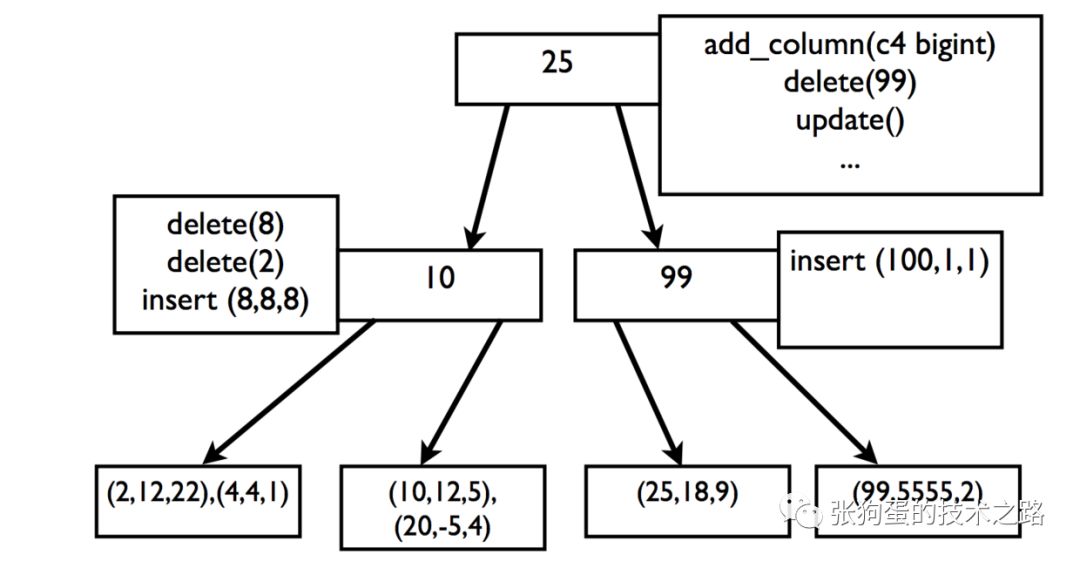
如上图所示,在Fractal Tree中,你进行的添加列,删除列,插入,更新等任何操作都会被当做操作消息存储在非叶节点上。由于操作只是被简单地存储在缓存或者任何次级索引缓存(secondary index buffer)中,所以,所有的操作都会被迅速执行结束。
当某一个节点的缓存满了之后,这些操作消息会依次从根节点,经过非叶节点,向叶节点进行传递。叶节点仍然存储着真实数据。当进行读时,读操作会考虑查询路径节点上的所有操作消息来获取真实的数据状态。但是由于tokudb会尽力将所有非叶节点缓存在内存中,所以这一过程也很快。
tokubd中的block最大可以达到4MB,而不是InnoDB中的16KB。这样的大小可以允许一次I/O操作时加载或写回更多的数据,这也有助于一次压缩更多数据来减少磁盘上数据的存储大小。
因此,tokudb强调借助更大的block大小能够实现更好的数据压缩和更少的磁盘I/O。tokudb宣称它们的存储引擎比InnoDB更快,提供比InnoDB更快的读写吞吐,并且tokudb也宣称自己有更少的碎片(fragmentation)问题,它也支持多集群索引等。下图是benchmark的相关统计图:
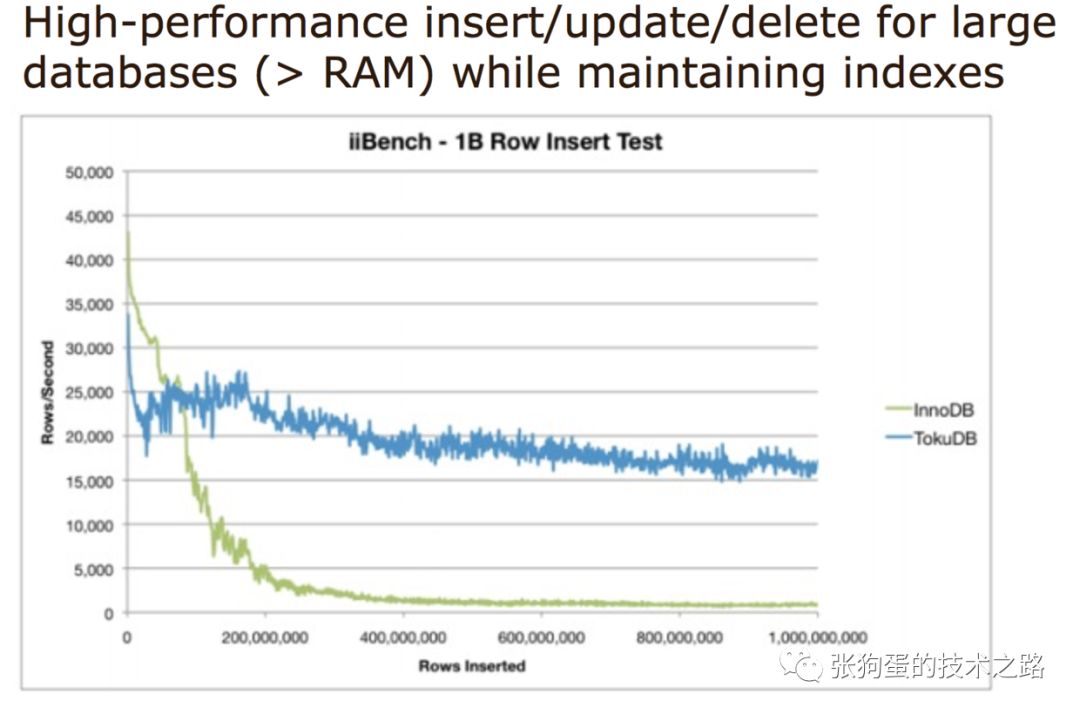
只有你系统中的benchmark可以帮助你判断正确的数据点和需求解决方案。但是MySQL的存储引擎会持续地不断改进和支持新出现的需求。LSM树是为了高写入场景的系统,然而B树是为了传统的场景应用。Fractal树的索引改进了B树索引存在的一些缺陷。因此,未来会不断地出现技术上的革新,包括数据库存储技术,硬件,磁盘驱动和操作系统,让我们拭目以待。
上述就是小编为大家分享的怎么实现数据库内部存储结构探索了,如果刚好有类似的疑惑,不妨参照上述分析进行理解。如果想知道更多相关知识,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。