жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
[TOC]
1гҖҒSpark 1.0зүҲжң¬д»ҘеҗҺпјҢSparkе®ҳж–№жҺЁеҮәдәҶSpark SQLгҖӮе…¶е®һжңҖж—©дҪҝз”Ёзҡ„пјҢйғҪжҳҜHadoopиҮӘе·ұзҡ„HiveжҹҘиҜўеј•ж“ҺпјӣжҜ”еҰӮMR2пјҢжҲ‘们еә•еұӮйғҪжҳҜиҝҗиЎҢзҡ„MR2жЁЎеһӢпјҢеә•еұӮйғҪжҳҜеҹәдәҺHiveзҡ„жҹҘиҜўеј•ж“ҺгҖӮ
2гҖҒеҗҺжқҘSparkжҸҗдҫӣдәҶSharkпјӣеҶҚеҗҺжқҘSharkиў«ж·ҳжұ°пјҲSharkеҲ¶зәҰдәҶSpark SQLзҡ„ж•ҙдҪ“еҸ‘еұ•пјүпјҢжҺЁеҮәдәҶSpark SQLгҖӮSharkзҡ„жҖ§иғҪжҜ”Hiveе°ұиҰҒй«ҳеҮәдёҖдёӘж•°йҮҸзә§пјҢиҖҢSpark SQLзҡ„жҖ§иғҪеҸҲжҜ”Sharkй«ҳеҮәдёҖдёӘж•°йҮҸзә§гҖӮ
3гҖҒSparkSQLзҡ„еүҚиә«жҳҜSharkпјҢз»ҷзҶҹжӮүRDBMSдҪҶеҸҲдёҚзҗҶи§ЈMapReduceзҡ„жҠҖжңҜдәәе‘ҳжҸҗдҫӣеҝ«йҖҹдёҠжүӢзҡ„е·Ҙе…·пјҢHiveеә”иҝҗиҖҢз”ҹпјҢе®ғжҳҜеҪ“ж—¶е”ҜдёҖиҝҗиЎҢеңЁHadoopдёҠзҡ„SQL-on-Hadoopе·Ҙе…·гҖӮдҪҶжҳҜMapReduceи®Ўз®—иҝҮзЁӢдёӯеӨ§йҮҸзҡ„дёӯй—ҙзЈҒзӣҳиҗҪең°иҝҮзЁӢж¶ҲиҖ—дәҶеӨ§йҮҸзҡ„I/OпјҢйҷҚдҪҺзҡ„иҝҗиЎҢж•ҲзҺҮпјҢдёәдәҶжҸҗй«ҳSQL-on-Hadoopзҡ„ж•ҲзҺҮпјҢеӨ§йҮҸзҡ„SQL-on-Hadoopе·Ҙе…·ејҖе§Ӣдә§з”ҹпјҢе…¶дёӯиЎЁзҺ°иҫғдёәзӘҒеҮәзҡ„жҳҜпјҡ
MapRзҡ„Drill
Clouderaзҡ„Impala
Shark4гҖҒдҪҶжҳҜHiveжңүдёӘиҮҙе‘Ҫзҡ„зјәйҷ·пјҢе°ұжҳҜе®ғзҡ„еә•еұӮеҹәдәҺMR2пјҢиҖҢMR2зҡ„shuffleеҸҲжҳҜеҹәдәҺзЈҒзӣҳзҡ„пјҢеӣ жӯӨеҜјиҮҙHiveзҡ„жҖ§иғҪејӮеёёдҪҺдёӢгҖӮз»ҸеёёеҮәзҺ°еӨҚжқӮзҡ„SQL ETLпјҢиҰҒиҝҗиЎҢж•°дёӘе°Ҹж—¶пјҢз”ҡиҮіж•°еҚҒдёӘе°Ҹж—¶зҡ„жғ…еҶөгҖӮ
5гҖҒSparkжҺЁеҮәдәҶSharkпјҢSharkдёҺHiveе®һйҷ…дёҠиҝҳжҳҜзҙ§еҜҶе…іиҒ”зҡ„пјҢSharkеә•еұӮеҫҲеӨҡдёңиҘҝиҝҳжҳҜдҫқиө–дәҺHiveпјҢдҪҶжҳҜдҝ®ж”№дәҶеҶ…еӯҳз®ЎзҗҶгҖҒзү©зҗҶи®ЎеҲ’гҖҒжү§иЎҢдёүдёӘжЁЎеқ—пјҢеә•еұӮдҪҝз”ЁSparkзҡ„еҹәдәҺеҶ…еӯҳзҡ„и®Ўз®—жЁЎеһӢпјҢд»ҺиҖҢи®©жҖ§иғҪжҜ”HiveжҸҗеҚҮдәҶж•°еҖҚеҲ°дёҠзҷҫеҖҚгҖӮ
1гҖҒдҪҶжҳҜпјҢйҡҸзқҖSparkзҡ„еҸ‘еұ•пјҢеҜ№дәҺйҮҺеҝғеӢғеӢғзҡ„SparkеӣўйҳҹжқҘиҜҙпјҢSharkеҜ№дәҺHiveзҡ„еӨӘеӨҡдҫқиө–пјҲеҰӮйҮҮз”ЁHiveзҡ„иҜӯжі•и§ЈжһҗеҷЁгҖҒжҹҘиҜўдјҳеҢ–еҷЁзӯүзӯүпјүпјҢеҲ¶зәҰдәҶSparkзҡ„One Stack Rule Them Allзҡ„ж—ўе®ҡж–№й’ҲпјҢеҲ¶зәҰдәҶSparkеҗ„дёӘ组件зҡ„зӣёдә’йӣҶжҲҗпјҢжүҖд»ҘжҸҗеҮәдәҶSparkSQLйЎ№зӣ®гҖӮSparkSQLжҠӣејғеҺҹжңүSharkзҡ„д»Јз ҒпјҢжұІеҸ–дәҶSharkзҡ„дёҖдәӣдјҳзӮ№пјҢеҰӮеҶ…еӯҳеҲ—еӯҳеӮЁпјҲIn-Memory Columnar StorageпјүгҖҒHiveе…је®№жҖ§зӯүпјҢйҮҚж–°ејҖеҸ‘дәҶSparkSQLд»Јз Ғпјӣз”ұдәҺж‘Ҷи„ұдәҶеҜ№Hiveзҡ„дҫқиө–жҖ§пјҢSparkSQLж— и®әеңЁж•°жҚ®е…је®№гҖҒжҖ§иғҪдјҳеҢ–гҖҒ组件жү©еұ•ж–№йқўйғҪеҫ—еҲ°дәҶжһҒеӨ§зҡ„ж–№дҫҝпјҢзңҹеҸҜи°“вҖңйҖҖдёҖжӯҘпјҢжө·йҳ”еӨ©з©әвҖқгҖӮ
2гҖҒSpark SQLзҡ„зү№зӮ№
1пјүгҖҒж”ҜжҢҒеӨҡз§Қж•°жҚ®жәҗпјҡHiveгҖҒRDDгҖҒParquetгҖҒJSONгҖҒJDBCзӯүгҖӮ
2пјүгҖҒеӨҡз§ҚжҖ§иғҪдјҳеҢ–жҠҖжңҜпјҡin-memory columnar storageгҖҒbyte-code generationгҖҒcost modelеҠЁжҖҒиҜ„дј°зӯүгҖӮ
3пјүгҖҒ组件жү©еұ•жҖ§пјҡеҜ№дәҺSQLзҡ„иҜӯжі•и§ЈжһҗеҷЁгҖҒеҲҶжһҗеҷЁд»ҘеҸҠдјҳеҢ–еҷЁпјҢз”ЁжҲ·йғҪеҸҜд»ҘиҮӘе·ұйҮҚж–°ејҖеҸ‘пјҢ并且еҠЁжҖҒжү©еұ•гҖӮ
ж•°жҚ®е…је®№ж–№йқў дёҚдҪҶе…је®№HiveпјҢиҝҳеҸҜд»Ҙд»ҺRDDгҖҒparquetж–Ү件гҖҒJSONж–Ү件дёӯиҺ·еҸ–ж•°жҚ®пјҢжңӘжқҘзүҲжң¬з”ҡиҮіж”ҜжҢҒиҺ·еҸ–RDBMSж•°жҚ®д»ҘеҸҠcassandraзӯүNOSQLж•°жҚ®пјӣ
жҖ§иғҪдјҳеҢ–ж–№йқў йҷӨдәҶйҮҮеҸ–In-Memory Columnar StorageгҖҒbyte-code generationзӯүдјҳеҢ–жҠҖжңҜеӨ–гҖҒе°Ҷдјҡеј•иҝӣCost ModelеҜ№жҹҘиҜўиҝӣиЎҢеҠЁжҖҒиҜ„дј°гҖҒиҺ·еҸ–жңҖдҪізү©зҗҶи®ЎеҲ’зӯүзӯүпјӣ
组件жү©еұ•ж–№йқў ж— и®әжҳҜSQLзҡ„иҜӯжі•и§ЈжһҗеҷЁгҖҒеҲҶжһҗеҷЁиҝҳжҳҜдјҳеҢ–еҷЁйғҪеҸҜд»ҘйҮҚж–°е®ҡд№үпјҢиҝӣиЎҢжү©еұ•гҖӮ
2014е№ҙ6жңҲ1ж—ҘSharkйЎ№зӣ®е’ҢSparkSQLйЎ№зӣ®зҡ„дё»жҢҒдәәReynold Xinе®ЈеёғпјҡеҒңжӯўеҜ№Sharkзҡ„ејҖеҸ‘пјҢеӣўйҳҹе°ҶжүҖжңүиө„жәҗж”ҫSparkSQLйЎ№зӣ®дёҠпјҢиҮіжӯӨпјҢSharkзҡ„еҸ‘еұ•з”»дёҠдәҶеҸҘиҜқпјҢдҪҶд№ҹеӣ жӯӨеҸ‘еұ•еҮәдёӨдёӘзӣҙзәҝпјҡSparkSQLе’ҢHive on SparkгҖӮ
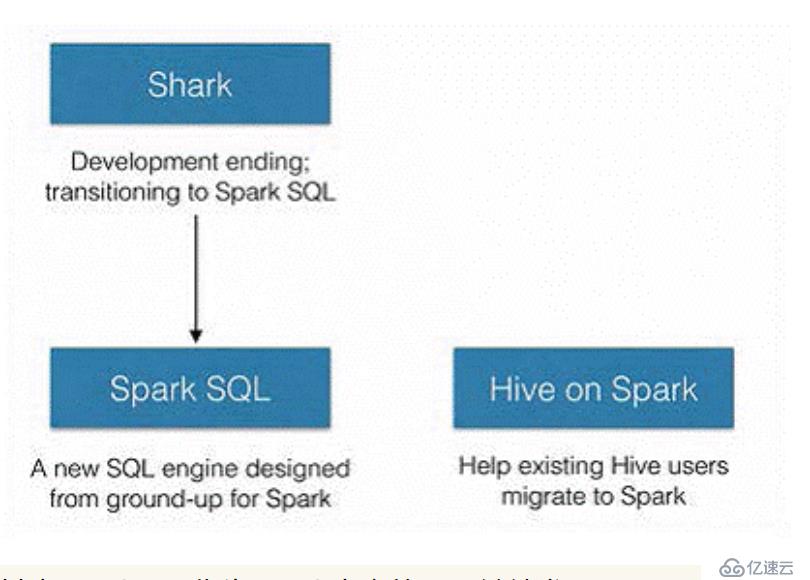
е…¶дёӯSparkSQLдҪңдёәSparkз”ҹжҖҒзҡ„дёҖе‘ҳ继з»ӯеҸ‘еұ•пјҢиҖҢдёҚеҶҚеҸ—йҷҗдәҺHiveпјҢеҸӘжҳҜе…је®№HiveпјӣиҖҢHive on SparkжҳҜдёҖдёӘHiveзҡ„еҸ‘еұ•и®ЎеҲ’пјҢиҜҘи®ЎеҲ’е°ҶSparkдҪңдёәHiveзҡ„еә•еұӮеј•ж“Һд№ӢдёҖпјҢд№ҹе°ұжҳҜиҜҙпјҢHiveе°ҶдёҚеҶҚеҸ—йҷҗдәҺдёҖдёӘеј•ж“ҺпјҢеҸҜд»ҘйҮҮз”ЁMap-ReduceгҖҒTezгҖҒSparkзӯүеј•ж“ҺгҖӮ
Sharkзҡ„еҮәзҺ°пјҢдҪҝеҫ—SQL-on-Hadoopзҡ„жҖ§иғҪжҜ”HiveжңүдәҶ10-100еҖҚзҡ„жҸҗй«ҳпјҡ
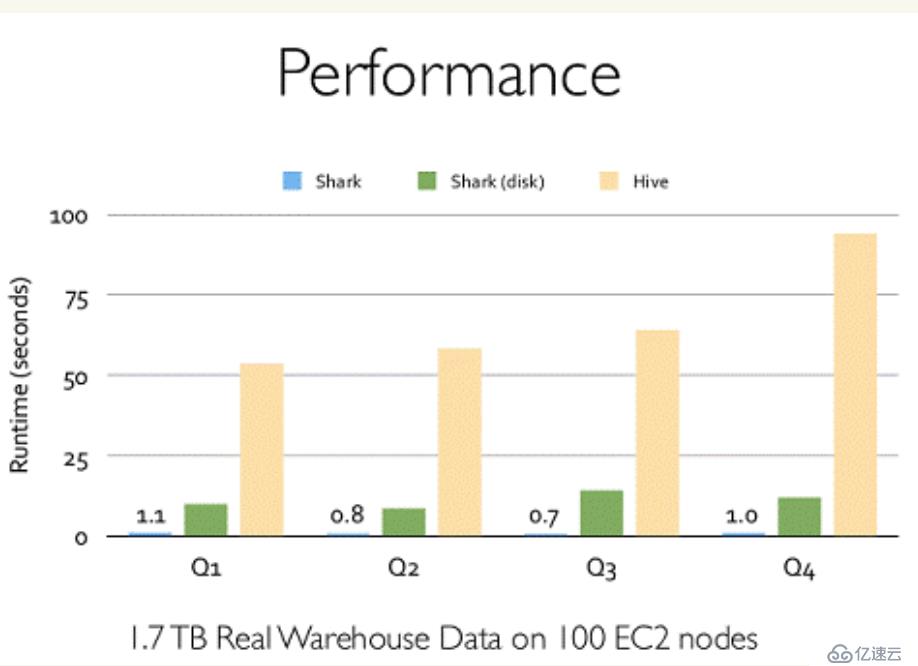
йӮЈд№ҲпјҢж‘Ҷи„ұдәҶHiveзҡ„йҷҗеҲ¶пјҢSparkSQLзҡ„жҖ§иғҪеҸҲжңүжҖҺд№Ҳж ·зҡ„иЎЁзҺ°е‘ўпјҹиҷҪ然没жңүSharkзӣёеҜ№дәҺHiveйӮЈж ·зһ©зӣ®ең°жҖ§иғҪжҸҗеҚҮпјҢдҪҶд№ҹиЎЁзҺ°еҫ—йқһеёёдјҳејӮпјҡ
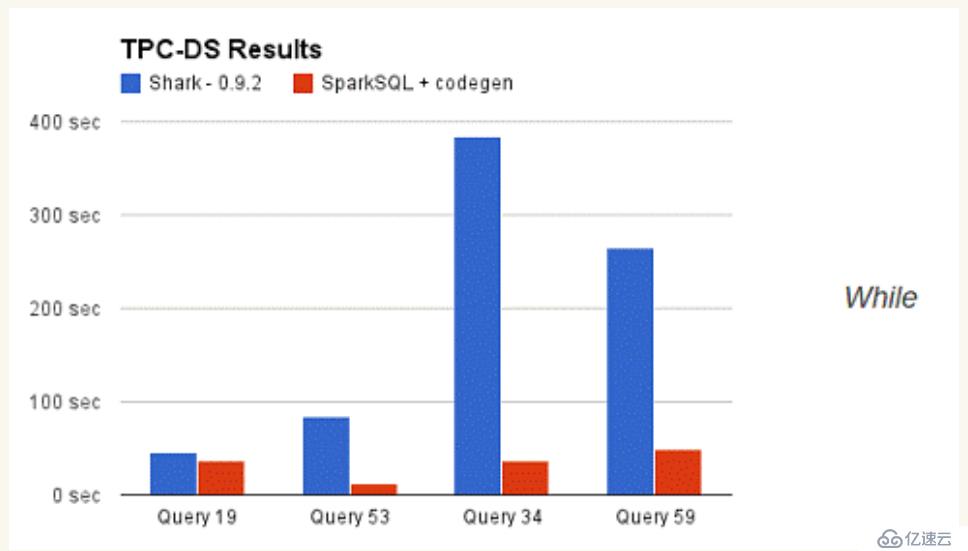
SparkSQLзҡ„иЎЁж•°жҚ®еңЁеҶ…еӯҳдёӯеӯҳеӮЁдёҚжҳҜйҮҮз”ЁеҺҹз”ҹжҖҒзҡ„JVMеҜ№иұЎеӯҳеӮЁж–№ејҸпјҢиҖҢжҳҜйҮҮз”ЁеҶ…еӯҳеҲ—еӯҳеӮЁпјҢеҰӮдёӢеӣҫжүҖзӨәпјҡ
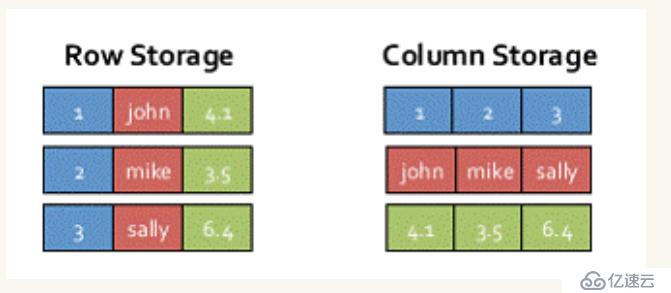
1гҖҒиҜҘеӯҳеӮЁж–№ејҸж— и®әеңЁз©әй—ҙеҚ з”ЁйҮҸе’ҢиҜ»еҸ–еҗһеҗҗзҺҮдёҠйғҪеҚ жңүеҫҲеӨ§дјҳеҠҝгҖӮ
еҜ№дәҺеҺҹз”ҹжҖҒзҡ„JVMеҜ№иұЎеӯҳеӮЁж–№ејҸпјҢжҜҸдёӘеҜ№иұЎйҖҡеёёиҰҒеўһеҠ 12-16еӯ—иҠӮзҡ„йўқеӨ–ејҖй”ҖпјҢеҜ№дәҺдёҖдёӘ270MBзҡ„ж•°жҚ®пјҢдҪҝз”Ёиҝҷз§Қж–№ејҸиҜ»е…ҘеҶ…еӯҳпјҢиҰҒдҪҝз”Ё970MBе·ҰеҸізҡ„еҶ…еӯҳз©әй—ҙпјҲйҖҡеёёжҳҜ2пҪһ5еҖҚдәҺеҺҹз”ҹж•°жҚ®з©әй—ҙпјүпјӣеҸҰеӨ–пјҢдҪҝз”Ёиҝҷз§Қж–№ејҸпјҢжҜҸдёӘж•°жҚ®и®°еҪ•дә§з”ҹдёҖдёӘJVMеҜ№иұЎпјҢеҰӮжһңжҳҜеӨ§е°Ҹдёә200Bзҡ„ж•°жҚ®и®°еҪ•пјҢ32Gзҡ„е Ҷж Ҳе°Ҷдә§з”ҹ1.6дәҝдёӘеҜ№иұЎпјҢиҝҷд№ҲеӨҡзҡ„еҜ№иұЎпјҢеҜ№дәҺGCжқҘиҜҙпјҢеҸҜиғҪиҰҒж¶ҲиҖ—еҮ еҲҶй’ҹзҡ„ж—¶й—ҙжқҘеӨ„зҗҶпјҲJVMзҡ„еһғеңҫ收йӣҶж—¶й—ҙдёҺе Ҷж Ҳдёӯзҡ„еҜ№иұЎж•°йҮҸе‘ҲзәҝжҖ§зӣёе…іпјүгҖӮжҳҫ然иҝҷз§ҚеҶ…еӯҳеӯҳеӮЁж–№ејҸеҜ№дәҺеҹәдәҺеҶ…еӯҳи®Ўз®—зҡ„SparkжқҘиҜҙпјҢеҫҲжҳӮиҙөд№ҹиҙҹжӢ…дёҚиө·гҖӮ
вҖӢ 2гҖҒеҜ№дәҺеҶ…еӯҳеҲ—еӯҳеӮЁжқҘиҜҙпјҢе°ҶжүҖжңүеҺҹз”ҹж•°жҚ®зұ»еһӢзҡ„еҲ—йҮҮз”ЁеҺҹз”ҹж•°з»„жқҘеӯҳеӮЁпјҢе°ҶHiveж”ҜжҢҒзҡ„еӨҚжқӮж•°жҚ®зұ»еһӢпјҲеҰӮarrayгҖҒmapзӯүпјүе…ҲеәҸеҢ–еҗҺ并жҺҘжҲҗдёҖдёӘеӯ—иҠӮж•°з»„жқҘеӯҳеӮЁгҖӮиҝҷж ·пјҢжҜҸдёӘеҲ—еҲӣе»әдёҖдёӘJVMеҜ№иұЎпјҢд»ҺиҖҢеҜјиҮҙеҸҜд»Ҙеҝ«йҖҹзҡ„GCе’Ңзҙ§еҮ‘зҡ„ж•°жҚ®еӯҳеӮЁпјӣйўқеӨ–зҡ„пјҢиҝҳеҸҜд»ҘдҪҝз”ЁдҪҺе»үCPUејҖй”Җзҡ„й«ҳж•ҲеҺӢзј©ж–№жі•пјҲеҰӮеӯ—е…ёзј–з ҒгҖҒиЎҢй•ҝеәҰзј–з ҒзӯүеҺӢзј©ж–№жі•пјүйҷҚдҪҺеҶ…еӯҳејҖй”Җпјӣжӣҙжңүи¶Јзҡ„жҳҜпјҢеҜ№дәҺеҲҶжһҗжҹҘиҜўдёӯйў‘з№ҒдҪҝз”Ёзҡ„иҒҡеҗҲзү№е®ҡеҲ—пјҢжҖ§иғҪдјҡеҫ—еҲ°еҫҲеӨ§зҡ„жҸҗй«ҳпјҢеҺҹеӣ е°ұжҳҜиҝҷдәӣеҲ—зҡ„ж•°жҚ®ж”ҫеңЁдёҖиө·пјҢжӣҙе®№жҳ“иҜ»е…ҘеҶ…еӯҳиҝӣиЎҢи®Ўз®—гҖӮ
еңЁж•°жҚ®еә“жҹҘиҜўдёӯжңүдёҖдёӘжҳӮиҙөзҡ„ж“ҚдҪңжҳҜжҹҘиҜўиҜӯеҸҘдёӯзҡ„иЎЁиҫҫејҸпјҢдё»иҰҒжҳҜз”ұдәҺJVMзҡ„еҶ…еӯҳжЁЎеһӢеј•иө·зҡ„гҖӮ
Spark SQLеңЁе…¶catalystжЁЎеқ—зҡ„expressionsдёӯеўһеҠ дәҶcodegenжЁЎеқ—пјҢеҜ№дәҺSQLиҜӯеҸҘдёӯзҡ„и®Ўз®—иЎЁиҫҫејҸпјҢжҜ”еҰӮselect num + num from tиҝҷз§Қзҡ„sqlпјҢе°ұеҸҜд»ҘдҪҝз”ЁеҠЁжҖҒеӯ—иҠӮз Ғз”ҹжҲҗжҠҖжңҜжқҘдјҳеҢ–е…¶жҖ§иғҪгҖӮ
еҸҰеӨ–пјҢSparkSQLеңЁдҪҝз”ЁScalaзј–еҶҷд»Јз Ғзҡ„ж—¶еҖҷпјҢе°ҪйҮҸйҒҝе…ҚдҪҺж•Ҳзҡ„гҖҒе®№жҳ“GCзҡ„д»Јз Ғпјӣе°Ҫз®ЎеўһеҠ дәҶзј–еҶҷд»Јз Ғзҡ„йҡҫеәҰпјҢдҪҶеҜ№дәҺз”ЁжҲ·жқҘиҜҙпјҢиҝҳжҳҜдҪҝз”Ёз»ҹдёҖзҡ„жҺҘеҸЈпјҢжІЎеҸ—еҲ°дҪҝз”ЁдёҠзҡ„еӣ°йҡҫгҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ