您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
本节内容:
背景
分布式日志系统架构图
创建和使用roles
产品组在开发一个分布式日志系统,用的组件较多,单独手工部署一各个个软件比较繁琐,花的时间比较长,于是就想到了使用ansible playbook + roles进行部署,效率大大提高。
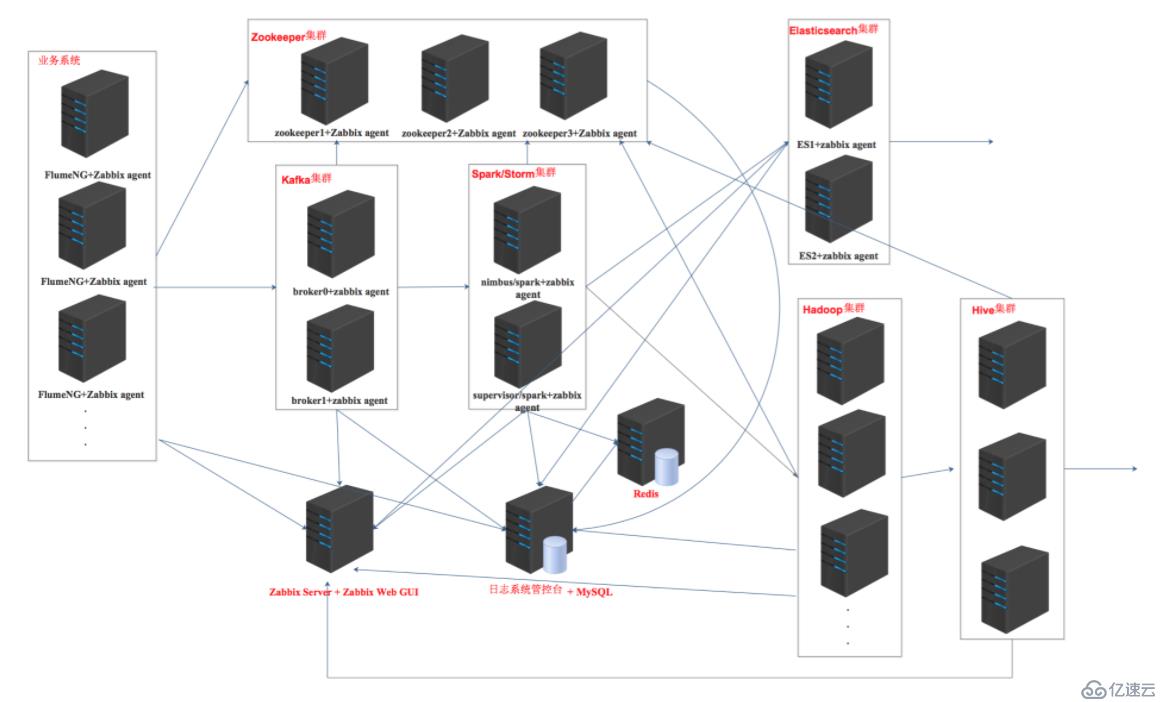
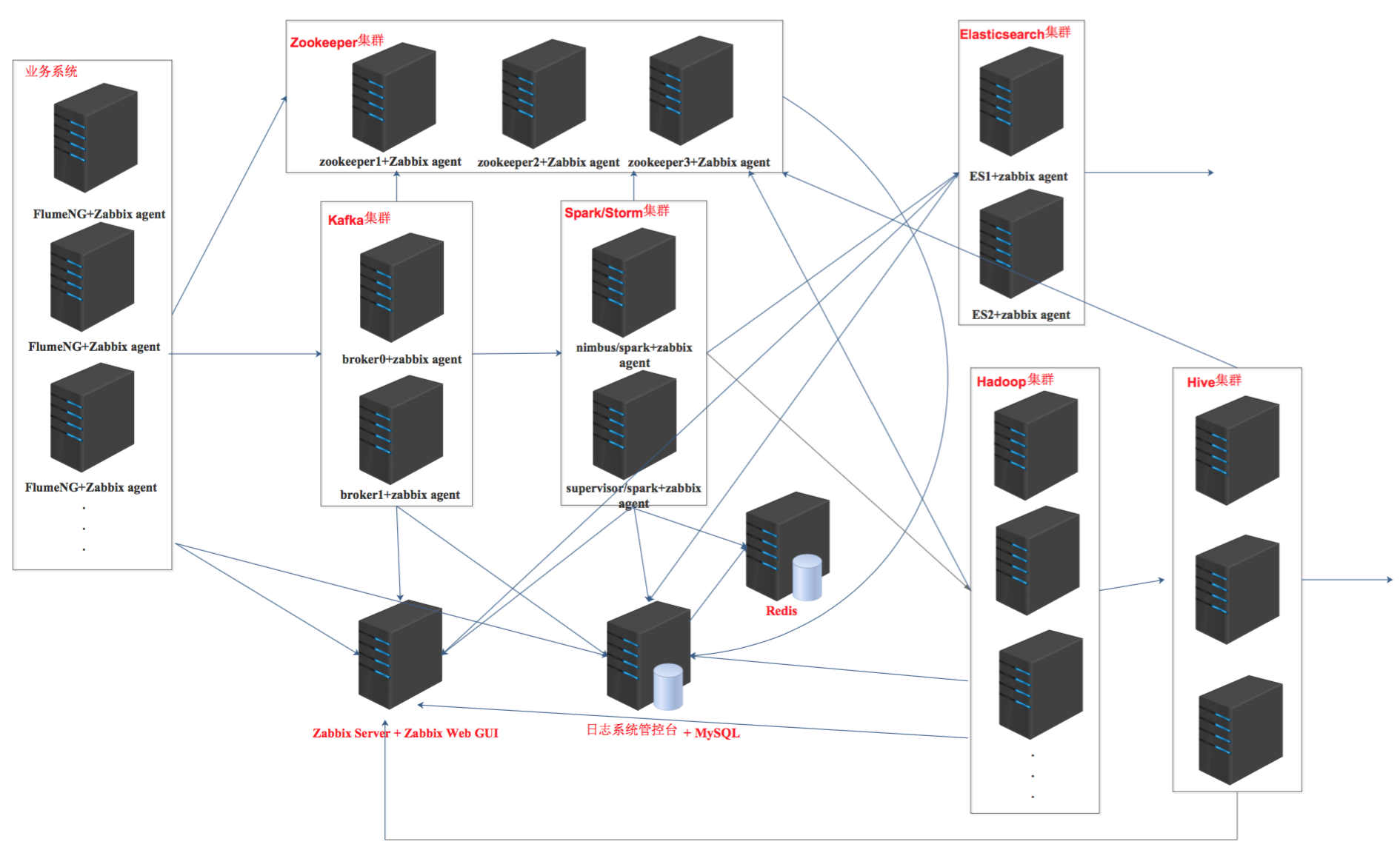
每一个软件或集群都创建一个单独的角色。
[root@node1 ~]# mkdir -pv ansible_playbooks/roles/{db_server,web_server,redis_server,zk_server,kafka_server,es_server,tomcat_server,flume_agent,hadoop,spark,hbase,hive,jdk7,jdk8}/{tasks,files,templates,meta,handlers,vars}
[root@node1 jdk7]# pwd/root/ansible_playbooks/roles/jdk7 [root@node1 jdk7]# lsfiles handlers meta tasks templates vars
1. 上传软件包
将jdk-7u80-linux-x64.gz上传到files目录下。
2. 编写tasks


[root@node1 jdk7]# vim tasks/main.yml
- name: mkdir necessary catalog
file: path=/usr/java state=directory mode=0755- name: copy and unzip jdk
unarchive: src={{jdk_package_name}} dest=/usr/java/
- name: set env
lineinfile: dest={{env_file}} insertafter="{{item.position}}" line="{{item.value}}" state=present
with_items: - {position: EOF, value: "\n"} - {position: EOF, value: "export JAVA_HOME=/usr/java/{{jdk_version}}"} - {position: EOF, value: "export PATH=$JAVA_HOME/bin:$PATH"} - {position: EOF, value: "export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar"}- name: enforce env
shell: source {{env_file}}
3. 编写vars
[root@node1 jdk7]# vim vars/main.yml jdk_package_name: jdk-7u80-linux-x64.gz env_file: /etc/profile jdk_version: jdk1.7.0_80
4. 使用角色
在roles同级目录,创建一个jdk.yml文件,里面定义好你的playbook。
[root@node1 ansible_playbooks]# vim jdk.yml - hosts: jdk remote_user: root roles: - jdk7
运行playbook安装JDK7:
[root@node1 ansible_playbooks]# ansible-playbook jdk.yml
使用jdk7 role可以需要根据实际环境修改vars/main.yml里的变量以及/etc/ansible/hosts文件里定义的主机。
[root@node1 jdk8]# pwd/root/ansible_playbooks/roles/jdk8 [root@node1 jdk8]# lsfiles handlers meta tasks templates vars
1. 上传安装包
将jdk-8u73-linux-x64.gz上传到files目录下。
2. 编写tasks
[root@node1 jdk8]# vim tasks/main.yml
- name: mkdir necessary catalog
file: path=/usr/java state=directory mode=0755- name: copy and unzip jdk
unarchive: src={{jdk_package_name}} dest=/usr/java/
- name: set env
lineinfile: dest={{env_file}} insertafter="{{item.position}}" line="{{item.value}}" state=present
with_items: - {position: EOF, value: "\n"} - {position: EOF, value: "export JAVA_HOME=/usr/java/{{jdk_version}}"} - {position: EOF, value: "export PATH=$JAVA_HOME/bin:$PATH"} - {position: EOF, value: "export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar"}- name: enforce env
shell: source {{env_file}}
3. 编写vars
[root@node1 jdk8]# vim vars/main.yml jdk_package_name: jdk-8u73-linux-x64.gz env_file: /etc/profile jdk_version: jdk1.8.0_73
4. 使用角色
在roles同级目录,创建一个jdk.yml文件,里面定义好你的playbook。
[root@node1 ansible_playbooks]# vim jdk.yml - hosts: jdk remote_user: root roles: - jdk8
运行playbook安装JDK8:
[root@node1 ansible_playbooks]# ansible-playbook jdk.yml
使用jdk8 role可以需要根据实际环境修改vars/main.yml里的变量以及/etc/ansible/hosts文件里定义的主机。
Zookeeper集群节点配置好/etc/hosts文件,配置集群各节点主机名和ip地址的对应关系。
[root@node1 zk_server]# pwd/root/ansible_playbooks/roles/zk_server [root@node1 zk_server]# lsfiles handlers meta tasks templates vars
1. 上传安装包
将zookeeper-3.4.6.tar.gz和clean_zklog.sh上传到files目录。clean_zklog.sh是清理Zookeeper日志的脚本。
2. 编写tasks
 zookeeper tasks
zookeeper tasks
3. 编写templates
将zookeeper-3.4.6.tar.gz包中的默认配置文件上传到../roles/zk_server/templates/目录下,重命名为zoo.cfg.j2,并修改其中的内容。
[root@node1 ansible_playbooks]# vim roles/zk_server/templates/zoo.cfg.j2
配置文件内容过多,具体见github,地址是https://github.com/jkzhao/ansible-godseye。配置文件内容也不在解释,在前面博客中的文章中都已写明。
4. 编写vars
[root@node1 zk_server]# vim vars/main.yml server1_hostname: hadoop27 server2_hostname: hadoop28 server3_hostname: hadoop29
另外在tasks中还使用了个变量{{myid}},该变量每台主机的值是不一样的,所以定义在了/etc/ansible/hosts文件中:
[zk_servers]172.16.206.27 myid=1172.16.206.28 myid=2172.16.206.29 myid=3
5. 设置主机组
/etc/ansible/hosts文件:
[zk_servers]172.16.206.27 myid=1172.16.206.28 myid=2172.16.206.29 myid=3
6. 使用角色
在roles同级目录,创建一个zk.yml文件,里面定义好你的playbook。
[root@node1 ansible_playbooks]# vim zk.yml - hosts: zk_servers remote_user: root roles: - zk_server
运行playbook安装Zookeeper集群:
[root@node1 ansible_playbooks]# ansible-playbook zk.yml
使用zk_server role需要根据实际环境修改vars/main.yml里的变量以及/etc/ansible/hosts文件里定义的主机。
[root@node1 kafka_server]# pwd/root/ansible_playbooks/roles/kafka_server [root@node1 kafka_server]# lsfiles handlers meta tasks templates vars
1. 上传安装包
将kafka_2.11-0.9.0.1.tar.gz、kafka-manager-1.3.0.6.zip和clean_kafkalog.sh上传到files目录。clean_kafkalog.sh是清理kafka日志的脚本。
2. 编写tasks
kafka tasks
3. 编写templates
[root@node1 kafka_server]# vim templates/server.properties.j2
配置文件内容过多,具体见github,地址是https://github.com/jkzhao/ansible-godseye。配置文件内容也不再解释,在前面博客中的文章中都已写明。
4. 编写vars
[root@node1 kafka_server]# vim vars/main.yml zk_cluster: 172.16.7.151:2181,172.16.7.152:2181,172.16.7.153:2181kafka_manager_ip: 172.16.7.151
另外在template的文件中还使用了个变量{{broker_id}},该变量每台主机的值是不一样的,所以定义在了/etc/ansible/hosts文件中:
[kafka_servers]172.16.206.17 broker_id=0172.16.206.31 broker_id=1172.16.206.32 broker_id=2
5. 设置主机组
/etc/ansible/hosts文件:
[kafka_servers]172.16.206.17 broker_id=0172.16.206.31 broker_id=1172.16.206.32 broker_id=2
6. 使用角色
在roles同级目录,创建一个kafka.yml文件,里面定义好你的playbook。
[root@node1 ansible_playbooks]# vim kafka.yml - hosts: kafka_servers remote_user: root roles: - kafka_server
运行playbook安装kafka集群:
[root@node1 ansible_playbooks]# ansible-playbook kafka.yml
使用kafka_server role需要根据实际环境修改vars/main.yml里的变量以及/etc/ansible/hosts文件里定义的主机。
[root@node1 es_server]# pwd/root/ansible_playbooks/roles/es_server [root@node1 es_server]# lsfiles handlers meta tasks templates vars
1. 上传安装包
将elasticsearch-2.3.3.tar.gz elasticsearch-analysis-ik-1.9.3.zip上传到files目录。
2. 编写tasks
Elasticsearch tasks
3. 编写templates
将模板elasticsearch.in.sh.j2和elasticsearch.yml.j2放入templates目录下
注意模板里的变量名中间不能用.。比如:{{node.name}}这样的变量名是不合法的。
配置文件内容过多,具体见github,地址是https://github.com/jkzhao/ansible-godseye。配置文件内容也不再解释,在前面博客中的文章中都已写明。
4. 编写vars
[root@node1 es_server]# vim vars/main.yml ES_MEM: 2g cluster_name: wisedu master_ip: 172.16.7.151
另外在template的文件中还使用了个变量{{node_master}},该变量每台主机的值是不一样的,所以定义在了/etc/ansible/hosts文件中:
[es_servers]172.16.7.151 node_master=true172.16.7.152 node_master=false172.16.7.153 node_master=false
5. 设置主机组
/etc/ansible/hosts文件:
[es_servers]172.16.7.151 node_master=true172.16.7.152 node_master=false172.16.7.153 node_master=false
6. 使用角色
在roles同级目录,创建一个es.yml文件,里面定义好你的playbook。
[root@node1 ansible_playbooks]# vim es.yml - hosts: es_servers remote_user: root roles: - es_server
运行playbook安装Elasticsearch集群:
[root@node1 ansible_playbooks]# ansible-playbook es.yml
使用es_server role需要根据实际环境修改vars/main.yml里的变量以及/etc/ansible/hosts文件里定义的主机。
[root@node1 db_server]# pwd/root/ansible_playbooks/roles/db_server [root@node1 db_server]# lsfiles handlers meta tasks templates vars
1. 上传安装包
将制作好的rpm包mysql-5.6.27-1.x86_64.rpm放到/root/ansible_playbooks/roles/db_server/files/目录下。
【注意】:这个rpm包是自己打包制作的,打包成rpm会使得部署的效率提高。关于如何打包成rpm见之前的博客《速成RPM包制作》。
2. 编写tasks
mysql tasks
3. 设置主机组
# vim /etc/ansible/hosts [db_servers]172.16.7.152
4. 使用角色
在roles同级目录,创建一个db.yml文件,里面定义好你的playbook。
[root@node1 ansible_playbooks]# vim db.yml - hosts: mysql_server remote_user: root roles: - db_server
运行playbook安装MySQL:
[root@node1 ansible_playbooks]# ansible-playbook db.yml
使用db_server role需要根据实际环境修改/etc/ansible/hosts文件里定义的主机。
[root@node1 web_server]# pwd/root/ansible_playbooks/roles/web_server [root@node1 web_server]# lsfiles handlers meta tasks templates vars
1. 上传安装包
将制作好的rpm包openresty-for-godseye-1.9.7.3-1.x86_64.rpm放到/root/ansible_playbooks/roles/web_server/files/目录下。
【注意】:做成rpm包,在安装时省去了编译nginx的过程,提升了部署效率。这个包里面打包了很多与我们系统相关的文件。
2. 编写tasks
Nginx tasks
3. 编写templates
将模板nginx.conf.j2放入templates目录下.
配置文件内容过多,具体见github,地址是https://github.com/jkzhao/ansible-godseye。配置文件内容也不再解释,在前面博客中的文章中都已写明。
4. 编写vars
[root@node1 web_server]# vim vars/main.yml elasticsearch_cluster: server 172.16.7.151:9200;server 172.16.7.152:9200;server 172.16.7.153:9200; kafka_server1: 172.16.7.151kafka_server2: 172.16.7.152kafka_server3: 172.16.7.153
经过测试,变量里面不能有逗号。
5. 设置主机组
/etc/ansible/hosts文件:
# vim /etc/ansible/hosts [nginx_servers]172.16.7.153
6. 使用角色
在roles同级目录,创建一个nginx.yml文件,里面定义好你的playbook。
[root@node1 ansible_playbooks]# vim nginx.yml - hosts: nginx_servers remote_user: root roles: - web_server
运行playbook安装Nginx:
[root@node1 ansible_playbooks]# ansible-playbook nginx.yml
使用web_server role需要根据实际环境修改vars/main.yml里的变量以及/etc/ansible/hosts文件里定义的主机。
[root@node1 redis_server]# pwd/root/ansible_playbooks/roles/redis_server [root@node1 redis_server]# lsfiles handlers meta tasks templates vars
1. 上传安装包
将制作好的rpm包redis-3.2.2-1.x86_64.rpm放到/root/ansible_playbooks/roles/redis_server/files/目录下。
2. 编写tasks
Redis tasks
3. 设置主机组
/etc/ansible/hosts文件:
# vim /etc/ansible/hosts [redis_servers]172.16.7.152
4. 使用角色
在roles同级目录,创建一个redis.yml文件,里面定义好你的playbook。
[root@node1 ansible_playbooks]# vim redis.yml - hosts: redis_servers remote_user: root roles: - redis_server
运行playbook安装redis:
[root@node1 ansible_playbooks]# ansible-playbook redis.yml
使用redis_server role需要根据实际环境修改vars/main.yml里的变量以及/etc/ansible/hosts文件里定义的主机。
完全分布式集群部署,NameNode和ResourceManager高可用。
提前配置集群节点的/etc/hosts文件、节点时间同步、某些集群主节点登录其他节点不需要输入密码。
[root@node1 hadoop]# pwd/root/ansible_playbooks/roles/hadoop [root@node1 hadoop]# lsfiles handlers meta tasks templates vars
1. 上传安装包
将hadoop-2.7.2.tar.gz放到/root/ansible_playbooks/roles/hadoop/files/目录下。
2. 编写tasks
- name: install dependency package yum: name={{ item }} state=present
with_items: - openssh - rsync- name: create hadoop user
user: name=hadoop password={{password}}
vars:
# created with:
# python -c 'import crypt; print crypt.crypt("This is my Password", "$1$SomeSalt$")'
# >>> import crypt
# >>> crypt.crypt('wisedu123', '$1$bigrandomsalt$')
# '$1$bigrando$wzfZ2ifoHJPvaMuAelsBq0'
password: $1$bigrando$wzfZ2ifoHJPvaMuAelsBq0- name: copy and unzip hadoop
#unarchive module owner and group only effect on directory.
unarchive: src=hadoop-2.7.2.tar.gz dest=/usr/local/
- name: create hadoop soft link file: src=/usr/local/hadoop-2.7.2 dest=/usr/local/hadoop state=link- name: create hadoop logs directory file: dest=/usr/local/hadoop/logs mode=0775 state=directory- name: change hadoop soft link owner and group
#recurse=yes make all files in a directory changed. file: path=/usr/local/hadoop owner=hadoop group=hadoop recurse=yes- name: change hadoop-2.7.2 directory owner and group
#recurse=yes make all files in a directory changed. file: path=/usr/local/hadoop-2.7.2 owner=hadoop group=hadoop recurse=yes- name: set hadoop env
lineinfile: dest={{env_file}} insertafter="{{item.position}}" line="{{item.value}}" state=present
with_items: - {position: EOF, value: "\n"} - {position: EOF, value: "# Hadoop environment"} - {position: EOF, value: "export HADOOP_HOME=/usr/local/hadoop"} - {position: EOF, value: "export PATH=$PATH:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin"}- name: enforce env
shell: source {{env_file}}- name: install configuration file hadoop-env.sh.j2 for hadoop
template: src=hadoop-env.sh.j2 dest=/usr/local/hadoop/etc/hadoop/hadoop-env.sh owner=hadoop group=hadoop- name: install configuration file core-site.xml.j2 for hadoop
template: src=core-site.xml.j2 dest=/usr/local/hadoop/etc/hadoop/core-site.xml owner=hadoop group=hadoop- name: install configuration file hdfs-site.xml.j2 for hadoop
template: src=hdfs-site.xml.j2 dest=/usr/local/hadoop/etc/hadoop/hdfs-site.xml owner=hadoop group=hadoop- name: install configuration file mapred-site.xml.j2 for hadoop
template: src=mapred-site.xml.j2 dest=/usr/local/hadoop/etc/hadoop/mapred-site.xml owner=hadoop group=hadoop- name: install configuration file yarn-site.xml.j2 for hadoop
template: src=yarn-site.xml.j2 dest=/usr/local/hadoop/etc/hadoop/yarn-site.xml owner=hadoop group=hadoop- name: install configuration file slaves.j2 for hadoop
template: src=slaves.j2 dest=/usr/local/hadoop/etc/hadoop/slaves owner=hadoop group=hadoop- name: install configuration file hadoop-daemon.sh.j2 for hadoop
template: src=hadoop-daemon.sh.j2 dest=/usr/local/hadoop/sbin/hadoop-daemon.sh owner=hadoop group=hadoop- name: install configuration file yarn-daemon.sh.j2 for hadoop
template: src=yarn-daemon.sh.j2 dest=/usr/local/hadoop/sbin/yarn-daemon.sh owner=hadoop group=hadoop
# make sure zookeeper started, and then start hadoop.
# start journalnode- name: start journalnode
shell: /usr/local/hadoop/sbin/hadoop-daemon.sh start journalnode
become: true
become_method: su
become_user: hadoop
when: datanode == "true"# format namenode- name: format active namenode hdfs
shell: /usr/local/hadoop/bin/hdfs namenode -format
become: true
become_method: su
become_user: hadoop
when: namenode_active == "true"- name: start active namenode hdfs
shell: /usr/local/hadoop/sbin/hadoop-daemon.sh start namenode
become: true
become_method: su
become_user: hadoop
when: namenode_active == "true"- name: format standby namenode hdfs
shell: /usr/local/hadoop/bin/hdfs namenode -bootstrapStandby
become: true
become_method: su
become_user: hadoop
when: namenode_standby == "true"- name: stop active namenode hdfs
shell: /usr/local/hadoop/sbin/hadoop-daemon.sh stop namenode
become: true
become_method: su
become_user: hadoop
when: namenode_active == "true"# format ZKFC- name: format ZKFC
shell: /usr/local/hadoop/bin/hdfs zkfc -formatZK
become: true
become_method: su
become_user: hadoop
when: namenode_active == "true"# start hadoop cluster- name: start namenode
shell: /usr/local/hadoop/sbin/start-dfs.sh
become: true
become_method: su
become_user: hadoop
when: namenode_active == "true"- name: start yarn
shell: /usr/local/hadoop/sbin/start-yarn.sh
become: true
become_method: su
become_user: hadoop
when: namenode_active == "true"- name: start standby rm
shell: /usr/local/hadoop/sbin/yarn-daemon.sh start resourcemanager
become: true
become_method: su
become_user: hadoop
when: namenode_standby == "true"
3. 编写templates
将模板core-site.xml.j2、hadoop-daemon.sh.j2、hadoop-env.sh.j2、hdfs-site.xml.j2、mapred-site.xml.j2、slaves.j2、yarn-daemon.sh.j2、yarn-site.xml.j2放入templates目录下。
配置文件内容过多,具体见github,地址是https://github.com/jkzhao/ansible-godseye。配置文件内容也不再解释,在前面博客中的文章中都已写明。
4. 编写vars
[root@node1 hadoop]# vim vars/main.yml env_file: /etc/profile # hadoop-env.sh.j2 file variables. JAVA_HOME: /usr/java/jdk1.8.0_73 # core-site.xml.j2 file variables. ZK_NODE1: node1:2181ZK_NODE2: node2:2181ZK_NODE3: node3:2181# hdfs-site.xml.j2 file variables. NAMENODE1_HOSTNAME: node1 NAMENODE2_HOSTNAME: node2 DATANODE1_HOSTNAME: node3 DATANODE2_HOSTNAME: node4 DATANODE3_HOSTNAME: node5 # mapred-site.xml.j2 file variables. MR_MODE: yarn # yarn-site.xml.j2 file variables. RM1_HOSTNAME: node1 RM2_HOSTNAME: node2
5. 设置主机组
/etc/ansible/hosts文件:
# vim /etc/ansible/hosts [hadoop]172.16.7.151 namenode_active=true namenode_standby=false datanode=false172.16.7.152 namenode_active=false namenode_standby=true datanode=false172.16.7.153 namenode_active=false namenode_standby=false datanode=true172.16.7.154 namenode_active=false namenode_standby=false datanode=true172.16.7.155 namenode_active=false namenode_standby=false datanode=true
6. 使用角色
在roles同级目录,创建一个hadoop.yml文件,里面定义好你的playbook。
[root@node1 ansible_playbooks]# vim hadoop.yml - hosts: hadoop remote_user: root roles: - jdk8 - hadoop
运行playbook安装hadoop集群:
[root@node1 ansible_playbooks]# ansible-playbook hadoop.yml
使用hadoop role需要根据实际环境修改vars/main.yml里的变量以及/etc/ansible/hosts文件里定义的主机。
Standalone模式部署spark (无HA)
[root@node1 spark]# pwd/root/ansible_playbooks/roles/spark [root@node1 spark]# lsfiles handlers meta tasks templates vars
1. 上传安装包
将scala-2.10.6.tgz和spark-1.6.1-bin-hadoop2.6.tgz放到/root/ansible_playbooks/roles/hadoop/files/目录下。
2. 编写tasks
- name: copy and unzip scala
unarchive: src=scala-2.10.6.tgz dest=/usr/local/
- name: set scala env
lineinfile: dest={{env_file}} insertafter="{{item.position}}" line="{{item.value}}" state=present
with_items:
- {position: EOF, value: "\n"}
- {position: EOF, value: "# Scala environment"}
- {position: EOF, value: "export SCALA_HOME=/usr/local/scala-2.10.6"}
- {position: EOF, value: "export PATH=$SCALA_HOME/bin:$PATH"}
- name: copy and unzip spark
unarchive: src=spark-1.6.1-bin-hadoop2.6.tgz dest=/usr/local/
- name: rename spark directory
command: mv /usr/local/spark-1.6.1-bin-hadoop2.6 /usr/local/spark-1.6.1
- name: set spark env
lineinfile: dest={{env_file}} insertafter="{{item.position}}" line="{{item.value}}" state=present
with_items:
- {position: EOF, value: "\n"}
- {position: EOF, value: "# Spark environment"}
- {position: EOF, value: "export SPARK_HOME=/usr/local/spark-1.6.1"}
- {position: EOF, value: "export PATH=$SPARK_HOME/bin:$PATH"}
- name: enforce env
shell: source {{env_file}}
- name: install configuration file for spark
template: src=slaves.j2 dest=/usr/local/spark-1.6.1/conf/slaves
- name: install configuration file for spark
template: src=spark-env.sh.j2 dest=/usr/local/spark-1.6.1/conf/spark-env.sh
- name: start spark cluster
shell: /usr/local/spark-1.6.1/sbin/start-all.sh
tags:
- start
Spark tasks
3. 编写templates
将模板slaves.j2和spark-env.sh.j2放到/root/ansible_playbooks/roles/spark/templates/目录下。
配置文件内容过多,具体见github,地址是https://github.com/jkzhao/ansible-godseye。配置文件内容也不再解释,在前面博客中的文章中都已写明。
4. 编写vars
[root@node1 spark]# vim vars/main.yml env_file: /etc/profile # spark-env.sh.j2 file variables JAVA_HOME: /usr/java/jdk1.8.0_73 SCALA_HOME: /usr/local/scala-2.10.6SPARK_MASTER_HOSTNAME: node1 SPARK_HOME: /usr/local/spark-1.6.1SPARK_WORKER_MEMORY: 256M HIVE_HOME: /usr/local/apache-hive-2.1.0-bin HADOOP_CONF_DIR: /usr/local/hadoop/etc/hadoop/# slave.j2 file variables SLAVE1_HOSTNAME: node2 SLAVE2_HOSTNAME: node3
5. 设置主机组
/etc/ansible/hosts文件:
# vim /etc/ansible/hosts [spark]172.16.7.151172.16.7.152172.16.7.153
6. 使用角色
在roles同级目录,创建一个spark.yml文件,里面定义好你的playbook。
[root@node1 ansible_playbooks]# vim spark.yml - hosts: spark remote_user: root roles: - spark
运行playbook安装spark集群:
[root@node1 ansible_playbooks]# ansible-playbook spark.yml
使用spark role需要根据实际环境修改vars/main.yml里的变量以及/etc/ansible/hosts文件里定义的主机。
【注】:所有的文件都在github上,https://github.com/jkzhao/ansible-godseye。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。