жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
з”ЁжҲ·иЎҢдёәж—Ҙеҝ—пјҡ
дёәд»Җд№ҲиҰҒи®°еҪ•з”ЁжҲ·и®ҝй—®иЎҢдёәж—Ҙеҝ—пјҡ
з”ЁжҲ·иЎҢдёәж—Ҙеҝ—з”ҹжҲҗжё йҒ“пјҡ
з”ЁжҲ·иЎҢдёәж—Ҙеҝ—еӨ§иҮҙеҶ…е®№пјҡ
з”ЁжҲ·иЎҢдёәж—Ҙеҝ—еҲҶжһҗзҡ„ж„Ҹд№үпјҡ
зҰ»зәҝж•°жҚ®еӨ„зҗҶжөҒзЁӢпјҡ
жөҒзЁӢзӨәж„Ҹеӣҫпјҡ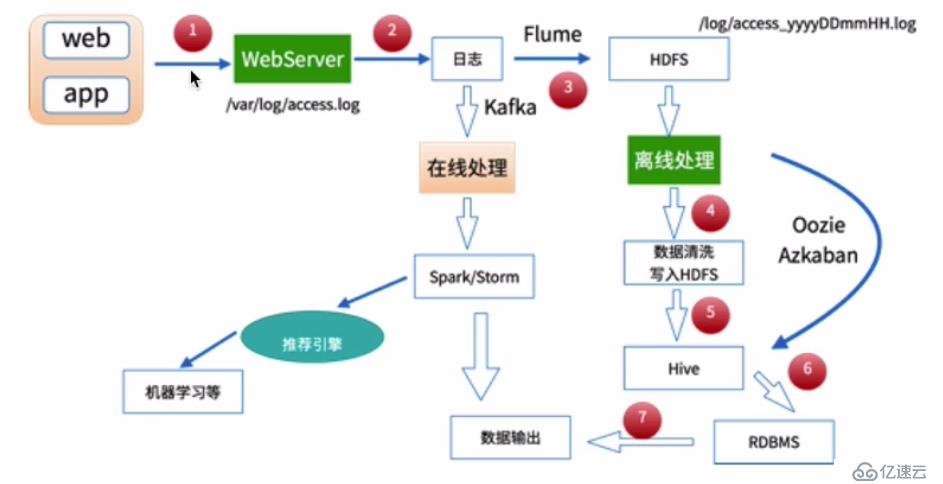
йңҖжұӮ:
ж—Ҙеҝ—зүҮж®өеҰӮдёӢпјҡ
183.162.52.7 - - [10/Nov/2016:00:01:02 +0800] "POST /api3/getadv HTTP/1.1" 200 813 "www.xxx.com" "-" cid=0Г—tamp=1478707261865&uid=2871142&marking=androidbanner&secrect=a6e8e14701ffe9f6063934780d9e2e6d&token=f51e97d1cb1a9caac669ea8acc162b96 "mukewang/5.0.0 (Android 5.1.1; Xiaomi Redmi 3 Build/LMY47V),Network 2G/3G" "-" 10.100.134.244:80 200 0.027 0.027
10.100.0.1 - - [10/Nov/2016:00:01:02 +0800] "HEAD / HTTP/1.1" 301 0 "117.121.101.40" "-" - "curl/7.19.7 (x86_64-redhat-linux-gnu) libcurl/7.19.7 NSS/3.16.2.3 Basic ECC zlib/1.2.3 libidn/1.18 libssh3/1.4.2" "-" - - - 0.000йҰ–е…ҲжҲ‘们йңҖиҰҒж №жҚ®ж—Ҙеҝ—дҝЎжҒҜжҠҪеҸ–еҮәжөҸи§ҲеҷЁдҝЎжҒҜпјҢй’ҲеҜ№дёҚеҗҢзҡ„жөҸи§ҲеҷЁиҝӣиЎҢз»ҹи®Ўж“ҚдҪңгҖӮиҷҪ然еҸҜд»ҘиҮӘе·ұе®һзҺ°иҝҷдёӘеҠҹиғҪпјҢдҪҶжҳҜжҮ’еҫ—еҶҚйҖ иҪ®еӯҗдәҶпјҢжүҖд»ҘжҲ‘еңЁGitHubжүҫеҲ°дәҶдёҖдёӘе°Ҹе·Ҙе…·еҸҜд»Ҙе®ҢжҲҗиҝҷдёӘеҠҹиғҪпјҢGitHubең°еқҖеҰӮдёӢпјҡ
https://github.com/LeeKemp/UserAgentParser
йҖҡиҝҮgit cloneжҲ–иҖ…жөҸи§ҲеҷЁдёӢиҪҪеҲ°жң¬ең°еҗҺпјҢдҪҝз”Ёе‘Ҫд»ӨиЎҢиҝӣе…ҘеҲ°е…¶дё»зӣ®еҪ•дёӢпјҢ然еҗҺйҖҡиҝҮmavenе‘Ҫд»ӨеҜ№е…¶иҝӣиЎҢжү“еҢ…并е®үиЈ…еҲ°жң¬ең°д»“еә“йҮҢпјҡ
$ mvn clean package -DskipTest
$ mvn clean install -DskipTestе®үиЈ…е®ҢжҲҗеҗҺпјҢеңЁе·ҘзЁӢдёӯж·»еҠ дҫқиө–д»ҘеҸҠжҸ’件пјҡ
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<hadoop.version>2.6.0-cdh6.7.0</hadoop.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
<scope>provided</scope>
</dependency>
<!-- ж·»еҠ UserAgentи§Јжһҗзҡ„дҫқиө– -->
<dependency>
<groupId>com.kumkee</groupId>
<artifactId>UserAgentParser</artifactId>
<version>0.0.1</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.10</version>
<scope>test</scope>
</dependency>
</dependencies>
<!-- mvn assembly:assembly -->
<build>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<archive>
<manifest>
<mainClass></mainClass>
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
</plugin>
</plugins>
</build>然еҗҺжҲ‘们编еҶҷдёҖдёӘжөӢиҜ•з”ЁдҫӢжқҘжөӢиҜ•дёҖдёӢиҝҷдёӘи§Јжһҗзұ»пјҢеӣ дёәд№ӢеүҚ并没жңүдҪҝз”ЁиҝҮиҝҷдёӘе·Ҙе…·пјҢжүҖд»ҘеҜ№дәҺдёҖдёӘжңӘдҪҝз”ЁиҝҮзҡ„е·Ҙе…·пјҢиҰҒе…»жҲҗеңЁе·ҘзЁӢдёӯдҪҝз”Ёд№ӢеүҚеҜ№е…¶иҝӣиЎҢжөӢиҜ•зҡ„еҘҪд№ жғҜпјҡ
package org.zero01.project;
import com.kumkee.userAgent.UserAgent;
import com.kumkee.userAgent.UserAgentParser;
/**
* @program: hadoop-train
* @description: UserAgentи§ЈжһҗжөӢиҜ•зұ»
* @author: 01
* @create: 2018-04-01 22:43
**/
public class UserAgentTest {
public static void main(String[] args) {
String source = "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.71 Safari/537.36";
UserAgentParser userAgentParser = new UserAgentParser();
UserAgent agent = userAgentParser.parse(source);
String browser = agent.getBrowser();
String engine = agent.getEngine();
String engineVersion = agent.getEngineVersion();
String os = agent.getOs();
String platform = agent.getPlatform();
boolean isMobile = agent.isMobile();
System.out.println("жөҸи§ҲеҷЁпјҡ" + browser);
System.out.println("еј•ж“Һпјҡ" + engine);
System.out.println("еј•ж“ҺзүҲжң¬пјҡ" + engineVersion);
System.out.println("ж“ҚдҪңзі»з»ҹпјҡ" + os);
System.out.println("е№іеҸ°пјҡ" + platform);
System.out.println("жҳҜеҗҰжҳҜ移еҠЁи®ҫеӨҮпјҡ" + isMobile);
}
}жҺ§еҲ¶еҸ°иҫ“еҮәз»“жһңеҰӮдёӢпјҡ
жөҸи§ҲеҷЁпјҡChrome
еј•ж“ҺпјҡWebkit
еј•ж“ҺзүҲжң¬пјҡ537.36
ж“ҚдҪңзі»з»ҹпјҡWindows 7
е№іеҸ°пјҡWindows
жҳҜеҗҰжҳҜ移еҠЁи®ҫеӨҮпјҡfalseд»Һжү“еҚ°з»“жһңеҸҜд»ҘзңӢеҲ°пјҢUserAgentзҡ„зӣёе…ідҝЎжҒҜйғҪжӯЈеёёиҺ·еҸ–еҲ°дәҶпјҢжҲ‘们е°ұеҸҜд»ҘеңЁе·ҘзЁӢдёӯиҝӣиЎҢдҪҝз”ЁиҝҷдёӘе·Ҙе…·дәҶгҖӮ
еҲӣе»әдёҖдёӘзұ»пјҢзј–еҶҷд»Јз ҒеҰӮдёӢпјҡ
package org.zero01.hadoop.project;
import com.kumkee.userAgent.UserAgent;
import com.kumkee.userAgent.UserAgentParser;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @program: hadoop-train
* @description: дҪҝз”ЁMapReduceжқҘе®ҢжҲҗз»ҹи®ЎжөҸи§ҲеҷЁзҡ„и®ҝй—®ж¬Ўж•°
* @author: 01
* @create: 2018-04-02 14:20
**/
public class LogApp {
/**
* Map: иҜ»еҸ–иҫ“е…Ҙзҡ„ж–Ү件еҶ…е®№
*/
public static class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
LongWritable one = new LongWritable(1);
private UserAgentParser userAgentParser;
protected void setup(Context context) throws IOException, InterruptedException {
userAgentParser = new UserAgentParser();
}
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// жҺҘ收еҲ°зҡ„жҜҸдёҖиЎҢж—Ҙеҝ—дҝЎжҒҜ
String line = value.toString();
String source = line.substring(getCharacterPosition(line, "\"", 7) + 1);
UserAgent agent = userAgentParser.parse(source);
String browser = agent.getBrowser();
// йҖҡиҝҮдёҠдёӢж–ҮжҠҠmapзҡ„еӨ„зҗҶз»“жһңиҫ“еҮә
context.write(new Text(browser), one);
}
protected void cleanup(Context context) throws IOException, InterruptedException {
userAgentParser = null;
}
}
/**
* Reduce: еҪ’并ж“ҚдҪң
*/
public static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long sum = 0;
for (LongWritable value : values) {
// жұӮkeyеҮәзҺ°зҡ„ж¬Ўж•°жҖ»е’Ң
sum += value.get();
}
// е°ҶжңҖз»Ҳзҡ„з»ҹи®Ўз»“жһңиҫ“еҮә
context.write(key, new LongWritable(sum));
}
}
/**
* иҺ·еҸ–жҢҮе®ҡеӯ—з¬ҰдёІдёӯжҢҮе®ҡж ҮиҜҶзҡ„еӯ—з¬ҰдёІеҮәзҺ°зҡ„зҙўеј•дҪҚзҪ®
*
* @param value
* @param operator
* @param index
* @return
*/
private static int getCharacterPosition(String value, String operator, int index) {
Matcher slashMatcher = Pattern.compile(operator).matcher(value);
int mIdex = 0;
while (slashMatcher.find()) {
mIdex++;
if (mIdex == index) {
break;
}
}
return slashMatcher.start();
}
/**
* е®ҡд№үDriverпјҡе°ҒиЈ…дәҶMapReduceдҪңдёҡзҡ„жүҖжңүдҝЎжҒҜ
*/
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration configuration = new Configuration();
// еҮҶеӨҮжё…зҗҶе·ІеӯҳеңЁзҡ„иҫ“еҮәзӣ®еҪ•
Path outputPath = new Path(args[1]);
FileSystem fileSystem = FileSystem.get(configuration);
if (fileSystem.exists(outputPath)) {
fileSystem.delete(outputPath, true);
System.out.println("output file exists, but is has deleted");
}
// еҲӣе»әJobпјҢйҖҡиҝҮеҸӮж•°и®ҫзҪ®Jobзҡ„еҗҚз§°
Job job = Job.getInstance(configuration, "LogApp");
// и®ҫзҪ®Jobзҡ„еӨ„зҗҶзұ»
job.setJarByClass(LogApp.class);
// и®ҫзҪ®дҪңдёҡеӨ„зҗҶзҡ„иҫ“е…Ҙи·Ҝеҫ„
FileInputFormat.setInputPaths(job, new Path(args[0]));
// и®ҫзҪ®mapзӣёе…іеҸӮж•°
job.setMapperClass(LogApp.MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
// и®ҫзҪ®reduceзӣёе…іеҸӮж•°
job.setReducerClass(LogApp.MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// и®ҫзҪ®дҪңдёҡеӨ„зҗҶе®ҢжҲҗеҗҺзҡ„иҫ“еҮәи·Ҝеҫ„
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}еңЁе·ҘзЁӢзӣ®еҪ•дёӢжү“ејҖжҺ§еҲ¶еҸ°пјҢиҫ“е…ҘеҰӮдёӢе‘Ҫд»ӨиҝӣиЎҢжү“еҢ…пјҡ
mvn assembly:assemblyжү“еҢ…жҲҗеҠҹпјҡ
е°ҶиҝҷдёӘjarеҢ…дёҠдј еҲ°жңҚеҠЎеҷЁдёҠпјҡ
[root@localhost ~]# rz # дҪҝз”Ёзҡ„жҳҜXshellе·Ҙе…·пјҢжүҖд»ҘзӣҙжҺҘдҪҝз”Ёrzе‘Ҫд»ӨеҚіеҸҜдёҠдј ж–Ү件
[root@localhost ~]# ls |grep hadoop-train-1.0-jar-with-dependencies.jar # жҹҘзңӢжҳҜеҗҰдёҠдј жҲҗеҠҹ
hadoop-train-1.0-jar-with-dependencies.jar
[root@localhost ~]#жҠҠдәӢе…ҲеҮҶеӨҮеҘҪзҡ„ж—Ҙеҝ—ж–Ү件дёҠдј еҲ°HDFSж–Ү件系з»ҹдёӯпјҡ
[root@localhost ~]# hdfs dfs -put ./10000_access.log /
[root@localhost ~]# hdfs dfs -ls /10000_access.log
-rw-r--r-- 1 root supergroup 2769741 2018-04-02 22:33 /10000_access.log
[root@localhost ~]#жү§иЎҢеҰӮдёӢе‘Ҫд»Ө
[root@localhost ~]# hadoop jar ./hadoop-train-1.0-jar-with-dependencies.jar org.zero01.hadoop.project.LogApp /10000_access.log /browseroutжү§иЎҢжҲҗеҠҹпјҡ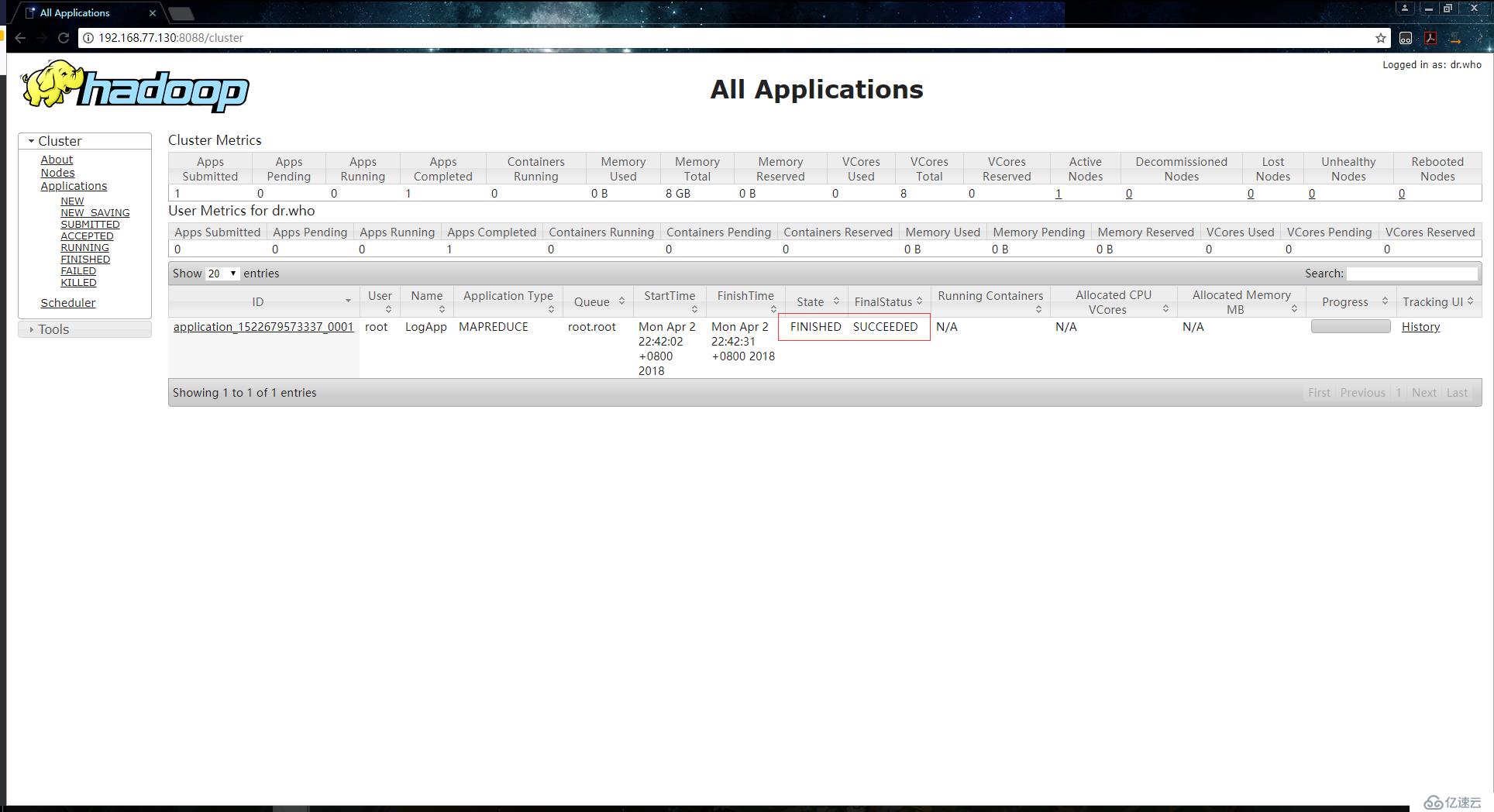
жҹҘзңӢеӨ„зҗҶз»“жһңпјҡ
[root@localhost ~]# hdfs dfs -ls /browserout
Found 2 items
-rw-r--r-- 1 root supergroup 0 2018-04-02 22:42 /browserout/_SUCCESS
-rw-r--r-- 1 root supergroup 56 2018-04-02 22:42 /browserout/part-r-00000
[root@localhost ~]# hdfs dfs -text /browserout/part-r-00000
Chrome 2775
Firefox 327
MSIE 78
Safari 115
Unknown 6705
[root@localhost ~]# е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ