您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
在之前我们已经介绍了如何在Linux上进行HDFS伪分布式环境的搭建,也介绍了hdfs中一些常用的命令。但是要如何在代码层面进行操作呢?这是本节将要介绍的内容:
1.首先使用IDEA创建一个maven工程: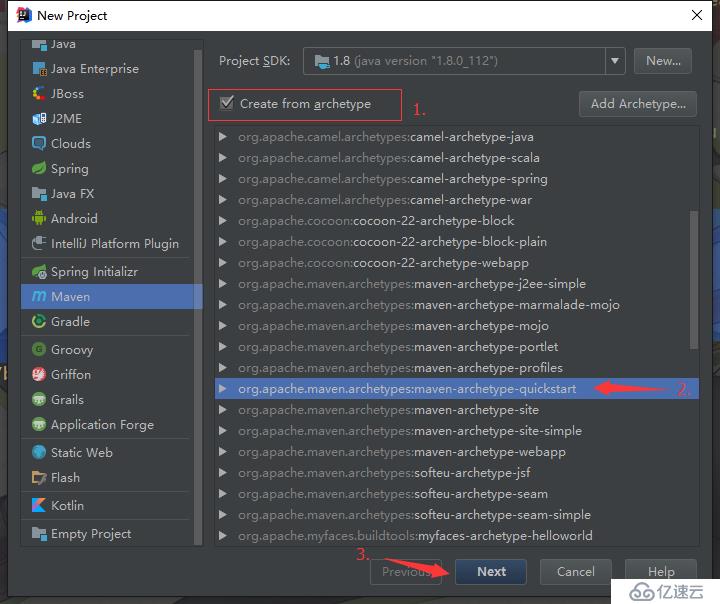
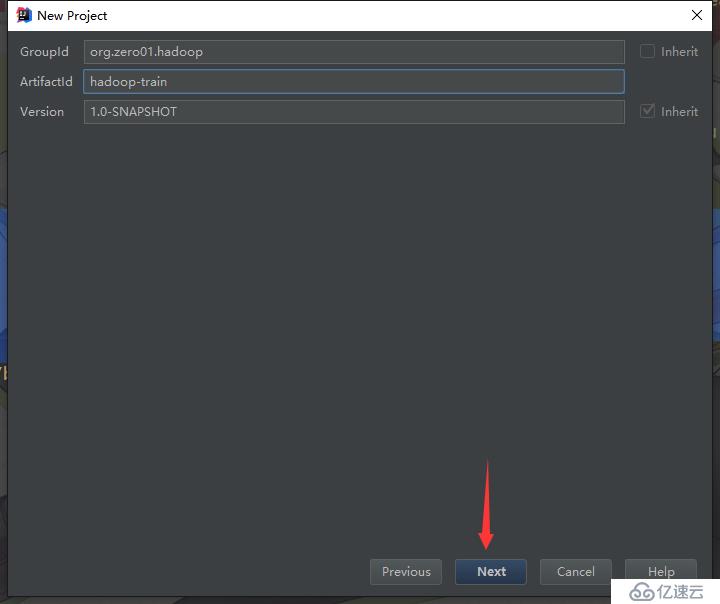
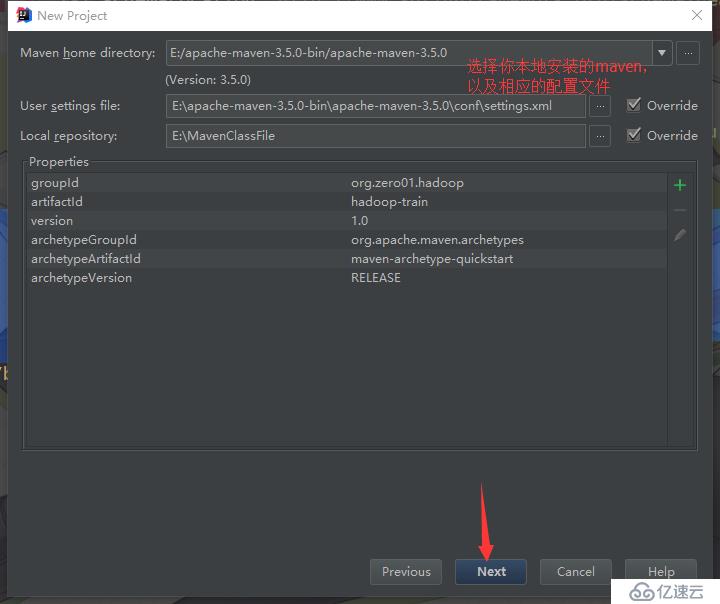
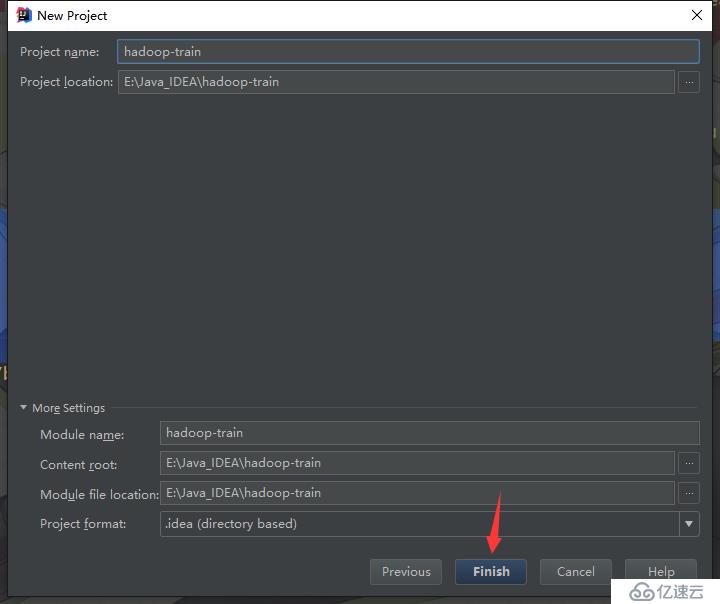
maven默认是不支持cdh的仓库的,需要在pom.xml中配置cdh的仓库,如下:
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>注意:如果你maven的settings.xml文件中,将mirrorOf的值配置成了*的话,那么就需要将其修改为*,!cloudera或central,因为*表示覆盖所有仓库地址会导致maven无法从cloudera的仓库下载依赖包,而*,!cloudera 表示不覆盖id为cloudera的仓库,关于这个问题可以自行了解一下。具体配置如下示例:
<mirror>
<id>alimaven</id>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<mirrorOf>*,!cloudera</mirrorOf>
</mirror>最后添加相关的依赖项:
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<hadoop.version>2.6.0-cdh6.7.0</hadoop.version>
</properties>
<dependencies>
<!-- hadoop依赖 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!-- 单元测试依赖 -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.10</version>
<scope>test</scope>
</dependency>
</dependencies>搭建完工程环境后,我们就可以调用Hadoop的API来操作HDFS文件系统了,下面我们来写一个测试用例,在HDFS文件系统上创建一个目录:
package org.zero01.hadoop.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.net.URI;
/**
* @program: hadoop-train
* @description: Hadoop HDFS Java API 操作
* @author: 01
* @create: 2018-03-25 13:59
**/
public class HDFSAPP {
// HDFS文件系统服务器的地址以及端口
public static final String HDFS_PATH = "hdfs://192.168.77.130:8020";
// HDFS文件系统的操作对象
FileSystem fileSystem = null;
// 配置对象
Configuration configuration = null;
/**
* 创建HDFS目录
*/
@Test
public void mkdir()throws Exception{
// 需要传递一个Path对象
fileSystem.mkdirs(new Path("/hdfsapi/test"));
}
// 准备资源
@Before
public void setUp() throws Exception {
configuration = new Configuration();
// 第一参数是服务器的URI,第二个参数是配置对象,第三个参数是文件系统的用户名
fileSystem = FileSystem.get(new URI(HDFS_PATH), configuration, "root");
System.out.println("HDFSAPP.setUp");
}
// 释放资源
@After
public void tearDown() throws Exception {
configuration = null;
fileSystem = null;
System.out.println("HDFSAPP.tearDown");
}
}运行结果:
可以看到是运行成功的,然后到服务器上,查看文件是否多了我们创建的目录:
[root@localhost ~]# hdfs dfs -ls /
Found 3 items
-rw-r--r-- 1 root supergroup 311585484 2018-03-24 23:15 /hadoop-2.6.0-cdh6.7.0.tar.gz
drwxr-xr-x - root supergroup 0 2018-03-25 22:17 /hdfsapi
-rw-r--r-- 1 root supergroup 49 2018-03-24 23:10 /hello.txt
[root@localhost ~]# hdfs dfs -ls /hdfsapi
Found 1 items
drwxr-xr-x - root supergroup 0 2018-03-25 22:17 /hdfsapi/test
[root@localhost ~]# 如上,代表我们的目录创建成功了。
我们再来增加一个方法,测试创建文件,并写入一些内容到文件中:
/**
* 创建文件
*/
@Test
public void create() throws Exception {
// 创建文件
FSDataOutputStream outputStream = fileSystem.create(new Path("/hdfsapi/test/a.txt"));
// 写入一些内容到文件中
outputStream.write("hello hadoop".getBytes());
outputStream.flush();
outputStream.close();
}执行成功后,同样的到服务器上,查看是否有我们创建的文件,并且文件的内容是否是我们写入的内容:
[root@localhost ~]# hdfs dfs -ls /hdfsapi/test
Found 1 items
-rw-r--r-- 3 root supergroup 12 2018-03-25 22:25 /hdfsapi/test/a.txt
[root@localhost ~]# hdfs dfs -text /hdfsapi/test/a.txt
hello hadoop
[root@localhost ~]# 每次操作完都得去服务器上查看,很麻烦,其实我们也可以直接在代码中读取文件系统中某个文件的内容,如下示例:
/**
* 查看HDFS里某个文件的内容
*/
@Test
public void cat() throws Exception {
// 读取文件
FSDataInputStream in = fileSystem.open(new Path("/hdfsapi/test/a.txt"));
// 将文件内容输出到控制台上,第三个参数表示输出多少字节的内容
IOUtils.copyBytes(in, System.out, 1024);
in.close();
}现在创建目录、文件以及读取文件内容都知道如何操作了,或许我们还需要知道如何重命名文件,如下示例:
/**
* 重命名文件
*/
@Test
public void rename() throws Exception {
Path oldPath = new Path("/hdfsapi/test/a.txt");
Path newPath = new Path("/hdfsapi/test/b.txt");
// 第一个参数是原文件的名称,第二个则是新的名称
fileSystem.rename(oldPath, newPath);
}增、查、改我们都已经知道如何操作了,就差最后一个删除的操作了,如下示例:
/**
* 删除文件
* @throws Exception
*/
@Test
public void delete()throws Exception{
// 第二个参数指定是否要递归删除,false=否,true=是
fileSystem.delete(new Path("/hdfsapi/test/mysql_cluster.iso"), false);
}对文件的增、删、查、改都介绍完了,下面我们来看看如何上传本地文件到HDFS文件系统中,我这里有一个local.txt文件,文件内容如下:
This is a local file
编写测试代码如下:
/**
* 上传本地文件到HDFS
*/
@Test
public void copyFromLocalFile() throws Exception {
Path localPath = new Path("E:/local.txt");
Path hdfsPath = new Path("/hdfsapi/test/");
// 第一个参数是本地文件的路径,第二个则是HDFS的路径
fileSystem.copyFromLocalFile(localPath, hdfsPath);
}执行以上的方法成功后,我们到HDFS上,看看是否拷贝成功:
[root@localhost ~]# hdfs dfs -ls /hdfsapi/test/
Found 2 items
-rw-r--r-- 3 root supergroup 12 2018-03-25 22:33 /hdfsapi/test/b.txt
-rw-r--r-- 3 root supergroup 20 2018-03-25 22:45 /hdfsapi/test/local.txt
[root@localhost ~]# hdfs dfs -text /hdfsapi/test/local.txt
This is a local file
[root@localhost ~]# 以上演示了上传一个小的文件,但是如果我需要上传一个比较大的文件,并且还希望有个进度条的话,就得使用以下这个种方式了:
/**
* 上传大体积的本地文件到HDFS,并显示进度条
*/
@Test
public void copyFromLocalFileWithProgress() throws Exception {
InputStream in = new BufferedInputStream(new FileInputStream(new File("E:/Linux Install/mysql_cluster.iso")));
FSDataOutputStream outputStream = fileSystem.create(new Path("/hdfsapi/test/mysql_cluster.iso"), new Progressable() {
public void progress() {
// 进度条的输出
System.out.print(".");
}
});
IOUtils.copyBytes(in, outputStream, 4096);
in.close();
outputStream.close();
}同样的,执行以上的方法成功后,我们到HDFS上,看看是否上传成功:
[root@localhost ~]# hdfs dfs -ls -h /hdfsapi/test/
Found 3 items
-rw-r--r-- 3 root supergroup 12 2018-03-25 22:33 /hdfsapi/test/b.txt
-rw-r--r-- 3 root supergroup 20 2018-03-25 22:45 /hdfsapi/test/local.txt
-rw-r--r-- 3 root supergroup 812.8 M 2018-03-25 23:01 /hdfsapi/test/mysql_cluster.iso
[root@localhost ~]#既然有上传文件自然就有下载文件,而且上传文件的方式有两种。所以下载文件的方式也有两种,如下示例:
/**
* 下载HDFS文件1
*
*/
@Test
public void copyToLocalFile1() throws Exception {
Path localPath = new Path("E:/b.txt");
Path hdfsPath = new Path("/hdfsapi/test/b.txt");
fileSystem.copyToLocalFile(hdfsPath, localPath);
}
/**
* 下载HDFS文件2
*
*/
@Test
public void copyToLocalFile2() throws Exception {
FSDataInputStream in = fileSystem.open(new Path("/hdfsapi/test/b.txt"));
OutputStream outputStream = new FileOutputStream(new File("E:/b.txt"));
IOUtils.copyBytes(in, outputStream, 1024);
in.close();
outputStream.close();
}下面我们来演示一下如何列出某个目录下的所有文件,示例:
/**
* 查看某个目录下所有的文件
*
* @throws Exception
*/
@Test
public void listFiles() throws Exception {
FileStatus[] fileStatuses = fileSystem.listStatus(new Path("/hdfsapi/test/"));
for (FileStatus fileStatus : fileStatuses) {
System.out.println("这是一个:" + (fileStatus.isDirectory() ? "文件夹" : "文件"));
System.out.println("副本系数:" + fileStatus.getReplication());
System.out.println("大小:" + fileStatus.getLen());
System.out.println("路径:" + fileStatus.getPath() + "\n");
}
}控制台打印结果如下:
这是一个:文件
副本系数:3
大小:12
路径:hdfs://192.168.77.130:8020/hdfsapi/test/b.txt
这是一个:文件
副本系数:3
大小:20
路径:hdfs://192.168.77.130:8020/hdfsapi/test/local.txt
这是一个:文件
副本系数:3
大小:852279296
路径:hdfs://192.168.77.130:8020/hdfsapi/test/mysql_cluster.iso注意,从控制台打印结果中,我们可以看到一个问题:我们之前已经在hdfs-site.xml中设置了副本系数为1,为什么此时查询文件看到的系数是3呢?
其实这是因为这几个文件都是我们在本地通过Java API上传上去的,在本地我们并没有设置副本系数,所以这时就会使用Hadoop的默认副本系数:3。
如果我们是在服务器上,通过hdfs命令put上去的,那么才会采用我们在配置文件中设置的副本系数。不信的话,可以在代码中将路径修改为根目录,这时控制台输出如下:
这是一个:文件
副本系数:1
大小:311585484
路径:hdfs://192.168.77.130:8020/hadoop-2.6.0-cdh6.7.0.tar.gz
这是一个:文件夹
副本系数:0
大小:0
路径:hdfs://192.168.77.130:8020/hdfsapi
这是一个:文件
副本系数:1
大小:49
路径:hdfs://192.168.77.130:8020/hello.txt根目录下的文件都是我们之前通过hdfs命令put上去,所以这些文件的副本系数才是我们在配置文件中设置的副本系数。
关于HDFS写数据流程,我在网络上找到一篇描述非常简洁易懂的漫画形式讲解HDFS的原理,作者不详。比一般PPT要通俗易懂很多,是难得的学习资料,特此摘录到本文中。
1、三个部分: 客户端、NameNode(可理解为主控和文件索引类似linux的inode)、DataNode(存放实际数据的存server)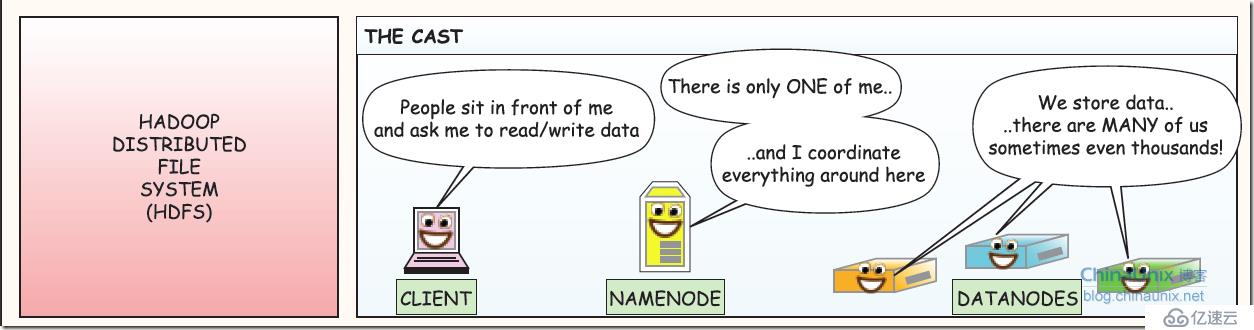
2、HDFS写数据过程: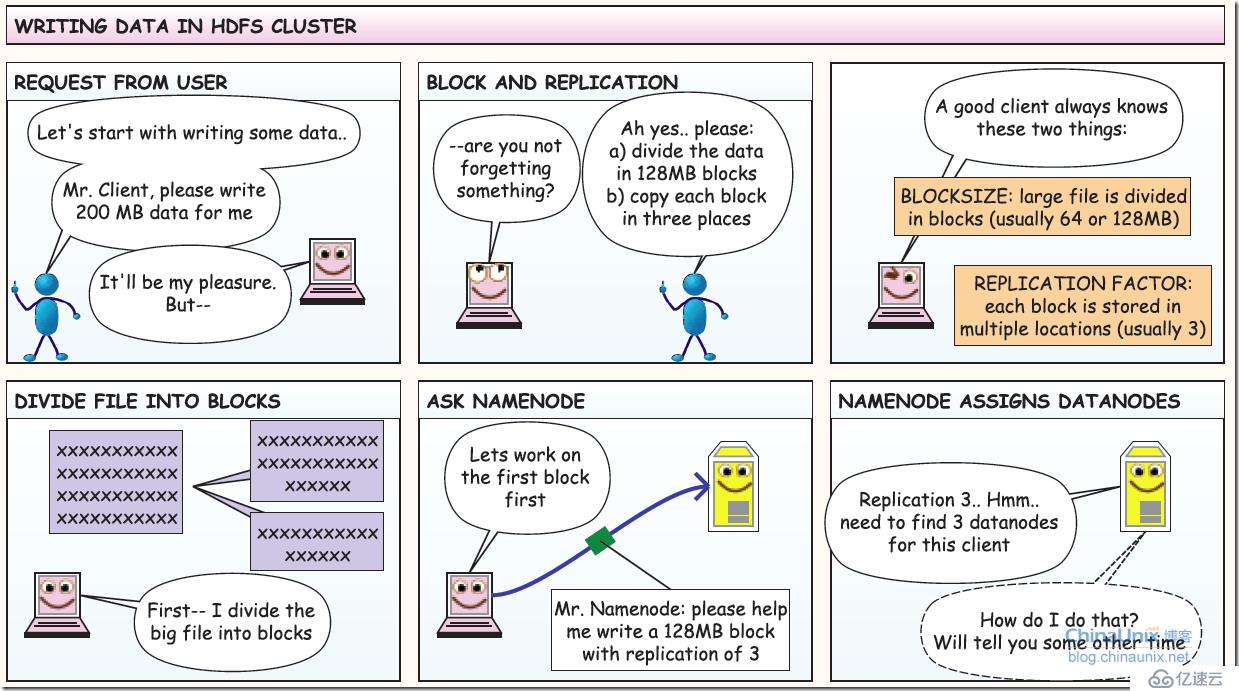

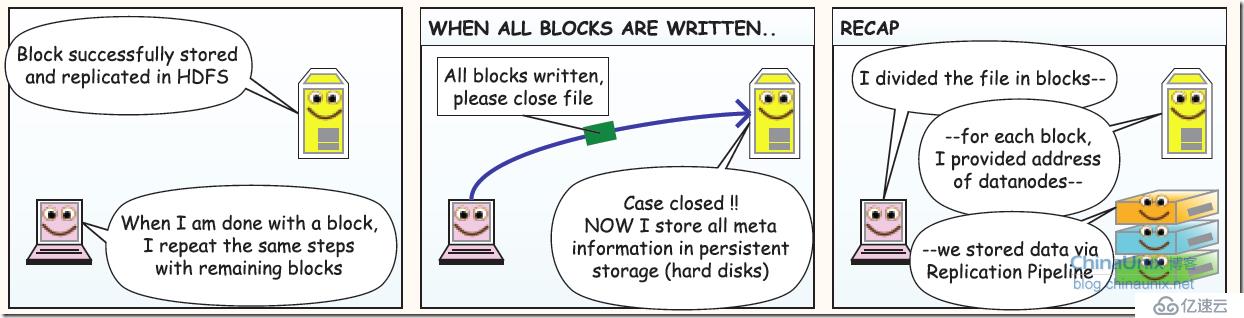
3、读取数据过程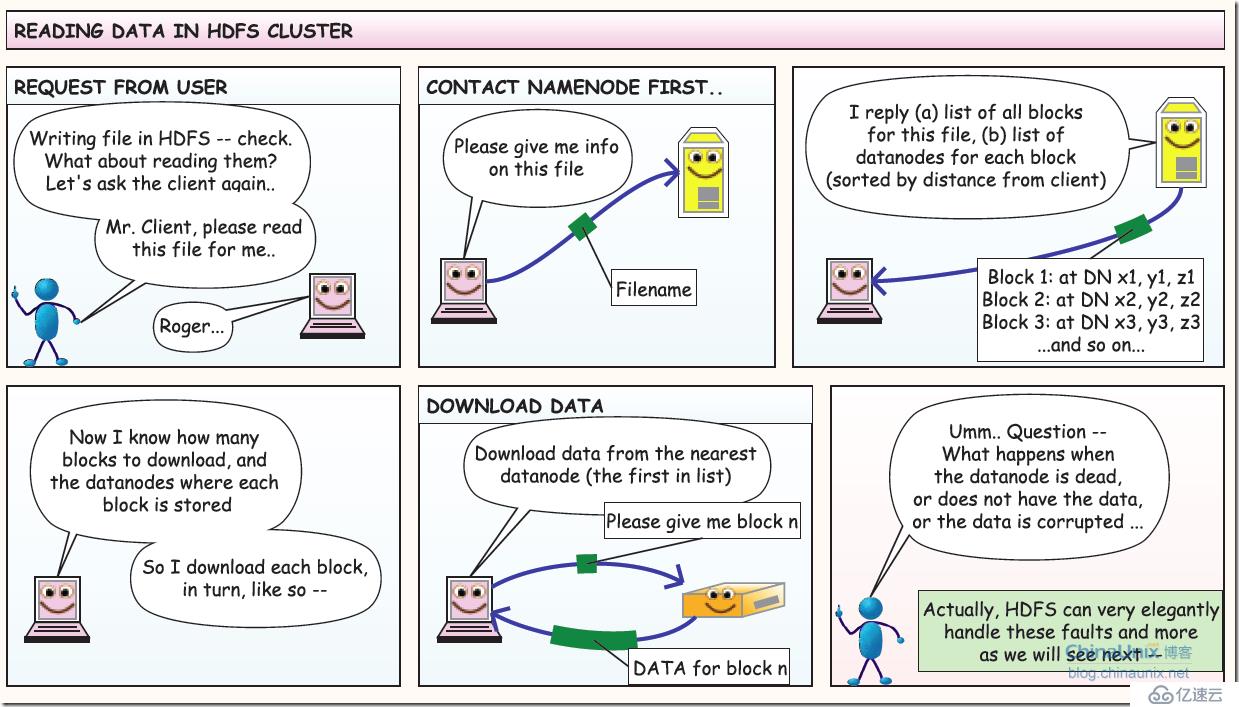
4、容错:第一部分:故障类型及其检测方法(nodeserver 故障,和网络故障,和脏数据问题)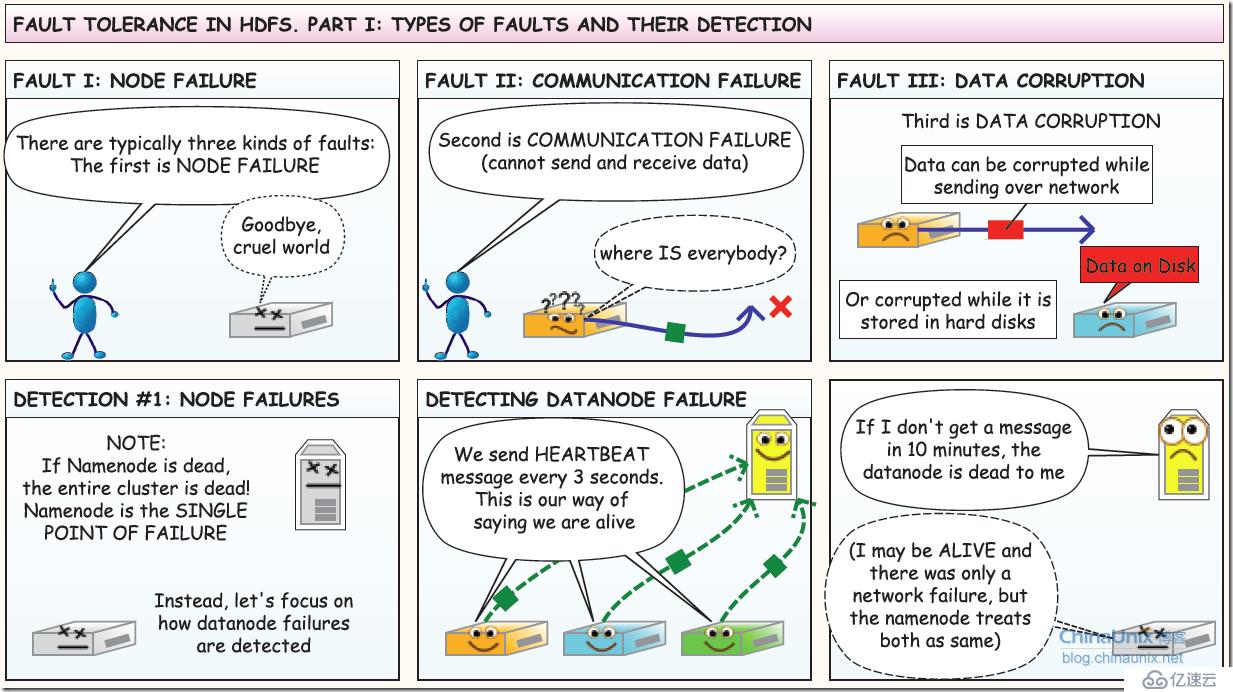
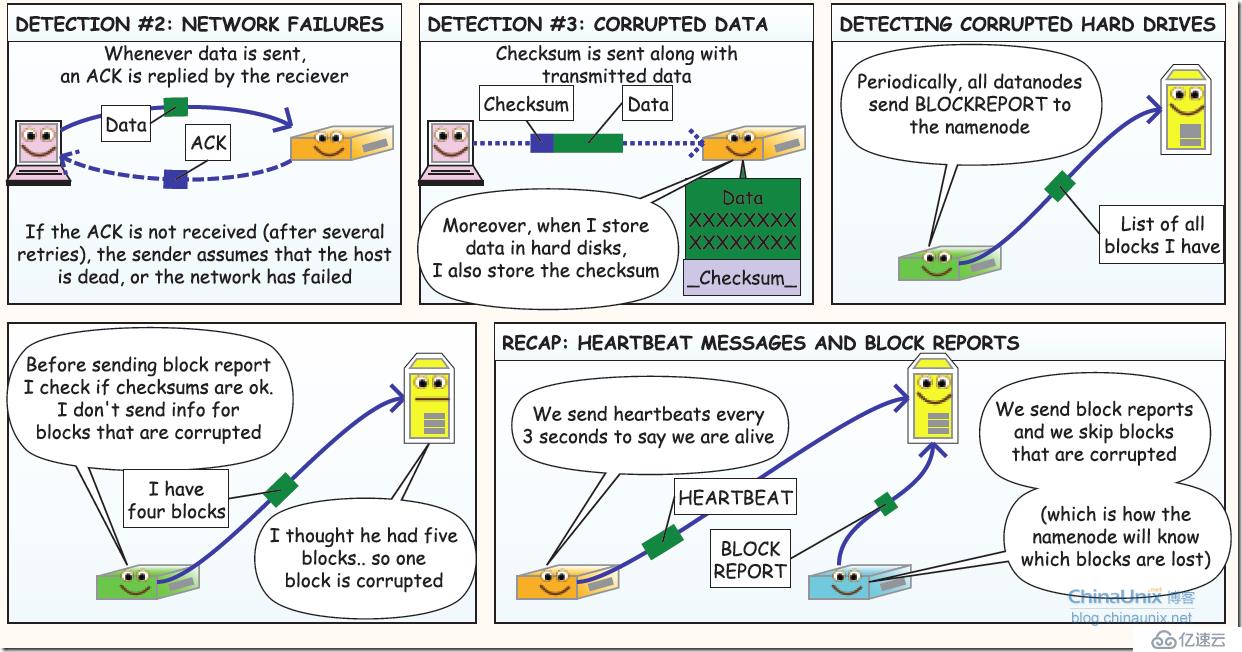
5、容错第二部分:读写容错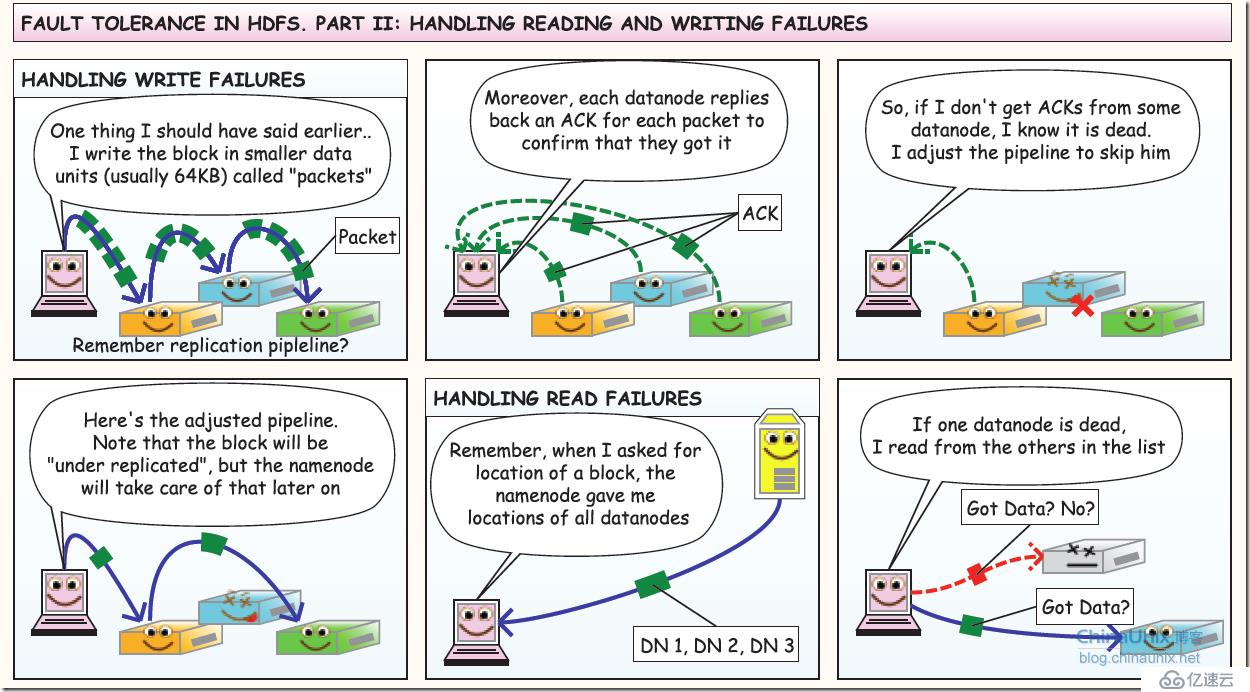
6、容错第三部分:dataNode 失效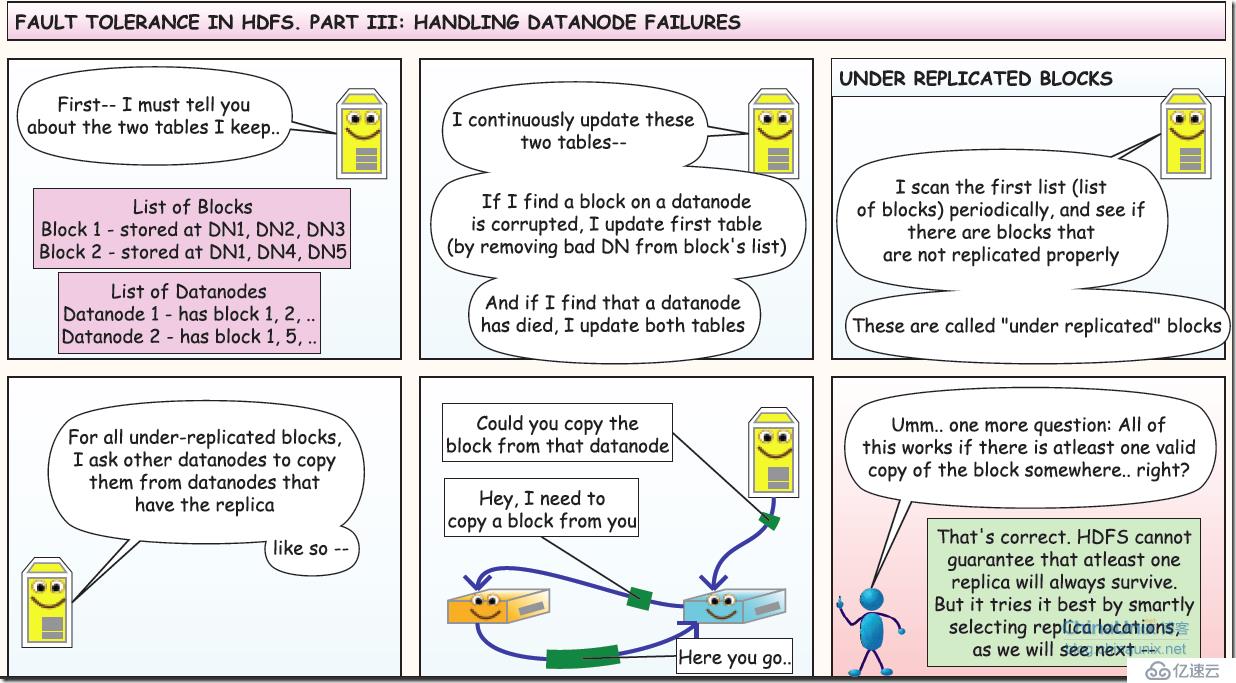
7、备份规则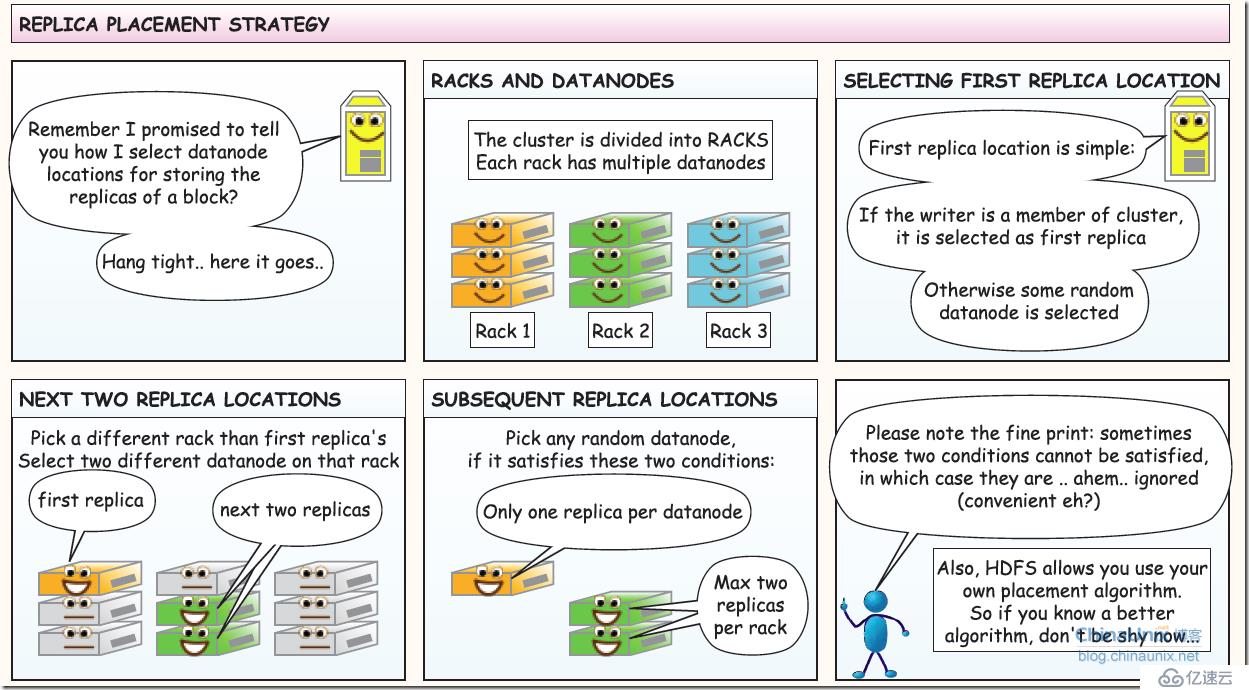
8、结束语
关于这个漫画还有一个中文版的,地址如下:
https://www.cnblogs.com/raphael5200/p/5497218.html
HDFS优点:
HDFS缺点:
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。