жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жң¬зҜҮеҶ…е®№д»Ӣз»ҚдәҶвҖңеҲҶеёғејҸдәӢеҠЎзҡ„еҗ«д№үвҖқзҡ„жңүе…ізҹҘиҜҶпјҢеңЁе®һйҷ…жЎҲдҫӢзҡ„ж“ҚдҪңиҝҮзЁӢдёӯпјҢдёҚе°‘дәәйғҪдјҡйҒҮеҲ°иҝҷж ·зҡ„еӣ°еўғпјҢжҺҘдёӢжқҘе°ұи®©е°Ҹзј–еёҰйўҶеӨ§е®¶еӯҰд№ дёҖдёӢеҰӮдҪ•еӨ„зҗҶиҝҷдәӣжғ…еҶөеҗ§пјҒеёҢжңӣеӨ§е®¶д»”з»Ҷйҳ…иҜ»пјҢиғҪеӨҹеӯҰжңүжүҖжҲҗпјҒ
дәӢеҠЎе…¶е®һеӨ§е®¶еә”иҜҘдёҚйҷҢз”ҹпјҢе°Өе…¶жҳҜеҜ№дәҺзЁӢеәҸе‘ҳжқҘиҜҙпјҢеҰӮжһңдҪ иҝһдәӢеҠЎйғҪжІЎеҗ¬иҜҙиҝҮпјҢжІЎе…ізі»пјҢеӣ дёәдҪ йҒҮеҲ°дәҶиҒӘжҳҺе’ҢжүҚжҷәдәҺдёҖдҪ“зҡ„жҲ‘пјҢдәӢеҠЎе…¶е®һе°ұжҳҜдёәдәҶеӨ„зҗҶеӨҡз§Қж··еҗҲж“ҚдҪңпјҢж¶үеҸҠеҲ°еӨҡж–№йқўдёҡеҠЎзҡ„жғ…жҷҜ
йҮҚзӮ№жҳҜдәӢеҠЎеә”з”Ёзҡ„еңәжҷҜе°ұжҳҜдёәдәҶи§ЈеҶіеӨҡз§ҚдәӢеҠЎеҝ…йЎ»иҰҒд№ҲеҗҢж—¶е®ҢжҲҗпјҢиҰҒд№ҲеҗҢж—¶дёҚиғҪе®ҢжҲҗзҡ„еңәжҷҜпјҢд№ҹе°ұжҳҜеҒҡеҲ°зңҹжӯЈж„Ҹд№үдёҠзҡ„"еҗҢз”ҹе…ұжӯ»"
дёҘж јж„Ҹд№үдёҠжқҘиҜҙдәӢеҠЎе…¶е®һе…·жңүеҺҹеӯҗжҖ§гҖҒдёҖиҮҙжҖ§гҖҒйҡ”зҰ»жҖ§е’ҢжҢҒд№…жҖ§еӣӣз§Қзү№жҖ§пјҢд№ҹе°ұжҳҜеӨ§е®¶иҖҒз”ҹеёёи°Ҳзҡ„ACID
еҺҹеӯҗжҖ§(Atomicity)пјҢеҸҜд»ҘзҗҶи§ЈдёәдёҖдёӘдәӢеҠЎеҶ…зҡ„жүҖжңүж“ҚдҪңиҰҒд№ҲйғҪжү§иЎҢпјҢиҰҒд№ҲйғҪдёҚжү§иЎҢ
дёҖиҮҙжҖ§(Consistency)пјҢеҸҜд»ҘзҗҶи§Јдёәж•°жҚ®жҳҜж»Ўи¶іе®Ңж•ҙжҖ§зәҰжқҹзҡ„пјҢд№ҹе°ұжҳҜдёҚдјҡеӯҳеңЁдёӯй—ҙзҠ¶жҖҒзҡ„ж•°жҚ®пјҢжҜ”еҰӮдҪ иҙҰдёҠжңү400пјҢжҲ‘иҙҰдёҠжңү100пјҢдҪ з»ҷжҲ‘жү“200еқ—пјҢжӯӨж—¶дҪ иҙҰдёҠзҡ„й’ұеә”иҜҘжҳҜ200пјҢжҲ‘иҙҰдёҠзҡ„й’ұеә”иҜҘжҳҜ300пјҢдёҚдјҡеӯҳеңЁжҲ‘иҙҰдёҠй’ұеҠ дәҶпјҢдҪ иҙҰдёҠй’ұжІЎжүЈзҡ„дёӯй—ҙзҠ¶жҖҒ
йҡ”зҰ»жҖ§(Isolation)пјҢжҢҮзҡ„жҳҜеӨҡдёӘдәӢеҠЎе№¶еҸ‘жү§иЎҢзҡ„ж—¶еҖҷдёҚдјҡдә’зӣёе№Іжү°пјҢеҚідёҖдёӘдәӢеҠЎеҶ…йғЁзҡ„ж•°жҚ®еҜ№дәҺе…¶д»–дәӢеҠЎжқҘиҜҙжҳҜйҡ”зҰ»зҡ„
жҢҒд№…жҖ§(Durability)пјҢжҢҮзҡ„жҳҜдёҖдёӘдәӢеҠЎе®ҢжҲҗдәҶд№ӢеҗҺж•°жҚ®е°ұиў«ж°ёиҝңдҝқеӯҳдёӢжқҘпјҢд№ӢеҗҺзҡ„е…¶д»–ж“ҚдҪңжҲ–ж•…йҡңйғҪдёҚдјҡеҜ№дәӢеҠЎзҡ„з»“жһңдә§з”ҹеҪұе“Қ
дёҘж јж„Ҹд№үдёҠжқҘиҜҙдәӢеҠЎе…¶е®һе…·жңүеҺҹеӯҗжҖ§гҖҒдёҖиҮҙжҖ§гҖҒйҡ”зҰ»жҖ§е’ҢжҢҒд№…жҖ§еӣӣз§Қзү№жҖ§пјҢд№ҹе°ұжҳҜеӨ§е®¶иҖҒз”ҹеёёи°Ҳзҡ„ACID
е…¶е®һеңЁжҲ‘们еҚ°иұЎдёӯпјҢеә”иҜҘеҜ№иҝҷдёӘдәӢеҠЎеҶҚзҶҹжӮүдёҚиҝҮдәҶпјҢеӨ§е®¶йғҪзҹҘйҒ“дәӢеҠЎе°ұжҳҜдёәдәҶдҪҝеҫ—дёҖдәӣж•°жҚ®еә“еұӮйқўзҡ„жӣҙж–°ж“ҚдҪңиҰҒд№Ҳе…ЁйғЁжҲҗеҠҹпјҢиҰҒд№Ҳе…ЁйғЁеӨұиҙҘгҖӮ
дёҚзҹҘйҒ“еӨ§е®¶еӯҰиҝҮRedisжІЎжңүпјҢеҰӮжһңеӯҰиҝҮRedisзҡ„е…¶е®һеҸҜиғҪдјҡжңүз–‘й—®пјҢеӣ дёәRedisзҡ„дәӢеҠЎдёҚиғҪдҝқиҜҒжүҖжңүж“ҚдҪңиҰҒд№ҲйғҪжү§иЎҢпјҢиҰҒд№ҲйғҪдёҚжү§иЎҢпјҢдҪҶжҳҜд№ҹеҸ«еҒҡдәӢеҠЎгҖӮRedisе…¶е®һеңЁе®ҳзҪ‘е°ұе·Із»ҸиҜҙжҳҺзҷҪдәҶпјҢе®ҳзҪ‘дёӯе‘ҠиҜүеӨ§е®¶дәӢеҠЎдёӯзҡ„жҹҗдёӘе‘Ҫд»ӨеӨұиҙҘдәҶпјҢд№ӢеҗҺзҡ„е‘Ҫд»ӨиҝҳжҳҜдјҡиў«еӨ„зҗҶпјҢRedisдёҚдјҡеҒңжӯўжү§иЎҢе‘Ҫд»ӨпјҢд№ҹе°ұжҳҜж„Ҹе‘ізқҖдёҚдјҡеӣһж»ҡ
他们з»ҷеҮәзҡ„еӣһзҡ„е°ұжҳҜйҰ–е…ҲеҰӮжһңе‘Ҫд»ӨеҮәй”ҷйӮЈе°ұжҳҜиҜӯжі•зҡ„й”ҷиҜҜпјҢжҳҜеұһдәҺдёӘдәәзҡ„зј–зЁӢй”ҷиҜҜпјҢиҖҢдё”иҝҷз§Қжғ…еҶөеә”иҜҘиў«жЈҖжөӢеҮәжқҘпјҢиҖҢдёҚжҳҜеңЁз”ҹдә§зҺҜеўғеҮәзҺ°пјҢдәҺжҳҜд№ҺRedisдёәдәҶйҖҹеәҰжӣҙеҝ«дёҚж”ҜжҢҒеӣһж»ҡж“ҚдҪң
ж„ҹи§үеҫҲжңүйҒ“зҗҶзҡ„ж ·еӯҗпјҢдҪҶжҳҜеҸҲжңүзӮ№дёҚеҜ№еҠІ
еҘҪдәҶпјҢиҝҷдёӢеӨ§е®¶йғҪзҹҘйҒ“дәӢеҠЎжҳҜе•ҘдәҶпјҢйӮЈд№ҲжҲ‘们дёҖиө·жқҘзңӢзңӢеҲҶеёғејҸдәӢеҠЎеҗ§
еҲҡжүҚиҜҙзҡ„дәӢеҠЎйғҪжҳҜеұһдәҺеҚ•дҪ“зЁӢеәҸдёӯпјҢеҚ•жңәдёӯиҝҷж ·жҳҜжІЎй—®йўҳзҡ„пјҢйҖҡиҝҮжҷ®йҖҡзҡ„дәӢеҠЎж“ҚдҪңе°ұеҸҜд»ҘжқҘи§ЈеҶі;еҪ“жҲ‘们зҡ„зі»з»ҹйҖҗжёҗеҸҳеӨ§пјҢж—ҘзӣҠеҸҳејәзҡ„еҗҢж—¶пјҢ并еҸ‘йҮҸе’Ңзі»з»ҹйғҪйҡҸд№ӢиҖҢеўһеҠ пјҢеҪ“ж¶үеҸҠеҲ°еӨҡдёӘзі»з»ҹд№Ӣй—ҙзҡ„й…ҚеҗҲжқҘе®ҢжҲҗдёҖдёӘдәӢеҠЎзҡ„ж—¶еҖҷпјҢиҝҷе°ұжҜ”иҫғйҡҫеҠһдәҶпјҢеӣ дёәж— жі•зӣҙжҺҘйҖҡиҝҮдёҖдёӘзі»з»ҹзҡ„ж•°жҚ®еә“жқҘе®ҢжҲҗ
еҒҮи®ҫзҺ°еңЁжңүи®ўеҚ•зі»з»ҹгҖҒжүЈж¬ҫзі»з»ҹгҖҒз§ҜеҲҶзі»з»ҹпјҢиҝҷжҳҜеұһдәҺдёүдёӘзі»з»ҹпјҢд№ҹе°ұжҳҜеҲҶеҲ«еңЁдёҚеҗҢзҡ„ж•°жҚ®еә“дёӯпјҢдҪҶжҳҜжҲ‘йңҖиҰҒдҝқиҜҒдёүдёӘзі»з»ҹдёӯзҡ„жңҚеҠЎиҰҒд№Ҳе…ЁйғЁжҲҗеҠҹгҖҒиҰҒд№Ҳе…ЁйғЁеӨұиҙҘпјҢе…¶е®һеғҸиҝҷз§Қи®ҫи®ЎеҲ°еӨҡдёӘеә“гҖҒеӨҡдёӘзі»з»ҹд№Ӣй—ҙзҡ„дәӢеҠЎж“ҚдҪңпјҢд№ҹе°ұжҳҜеҲҶеёғејҸдәӢеҠЎдәҶ
еҲҶеёғејҸдәӢеҠЎе…¶е®һиҜҙз®ҖеҚ•д№ҹз®ҖеҚ•пјҢе…¶е®һе°ұжҳҜжңүеӨҡдёӘжң¬ең°дәӢеҠЎз»„еҗҲиҖҢжҲҗпјҢеҜ№дәҺеҲҶеёғејҸдәӢеҠЎиҖҢиЁҖеҮ д№Һж»Ўи¶ідёҚдәҶACIDпјҢе…¶е®һеҜ№дәҺеҚ•жңәдәӢеҠЎеӨ§еӨҡжҳҜжғ…еҶөдёӢд№ҹжҳҜж— жі•е…ЁйғЁж»Ўи¶іACIDзҡ„пјҢеҗҰеҲҷе“ӘйҮҢжқҘзҡ„еӣӣз§Қйҡ”зҰ»зә§еҲ«?жүҖд»ҘжӣҙеҲ«иҜҙеҲҶеёғеңЁдёҚеҗҢж•°жҚ®еә“гҖҒдёҚеҗҢзі»з»ҹд№Ӣй—ҙзҡ„еҲҶеёғејҸдәӢеҠЎдәҶ
еҲҶеёғејҸдәӢеҠЎеӨ§иҮҙеҸҜд»ҘеҲҶдёәе…ӯз§ҚпјҢдҪҶжҳҜе…¶е®һиҝҷе…ӯз§ҚеҸҲеҸҜд»ҘжҢүз…§дёүз§ҚжҖқжғіжқҘеҲҶзұ»пјҢжҺҘдёӢжқҘдёҖиө·зңӢзңӢеҗ§
2PCе’Ң3PCжҳҜдёҖз§ҚејәдёҖиҮҙжҖ§дәӢеҠЎпјҢдёҚиҝҮиҝҳжҳҜжңүж•°жҚ®зҡ„дёҚдёҖиҮҙгҖҒйҳ»еЎһзӯүйЈҺйҷ©пјҢиҖҢдё”еҸӘиғҪеә”з”ЁеңЁж•°жҚ®еә“еұӮйқў;иҖҢTCCжҳҜдёҖз§ҚиЎҘеҒҝжҖ§дәӢеҠЎзҡ„жҖқжғіпјҢйҖӮз”Ёзҡ„иҢғеӣҙеә”иҜҘжҳҜжҜ”иҫғе№ҝпјҢдёҚиҝҮиҝҷз§ҚиЎҘеҒҝжҖ§жңәеҲ¶дёҖиҲ¬еҜ№дёҡеҠЎзҡ„дҫөе…ҘжҖ§жҜ”иҫғеӨ§пјҢжҜҸдёҖдёӘж“ҚдҪңйғҪйңҖиҰҒе®һзҺ°еҜ№еә”зҡ„дёүз§Қж–№жі•;иҝҳжңүдёҖз§ҚжҖқжғіе°ұжҳҜеҠӘеҠӣе®һзҺ°жңҖз»ҲдёҖиҮҙжҖ§дәӢеҠЎпјҢжңүжң¬ең°ж¶ҲжҒҜгҖҒдәӢеҠЎж¶ҲжҒҜгҖҒе’ҢжңҖеӨ§еҠӘеҠӣйҖҡзҹҘиҝҷдёүз§Қж–№жі•пјҢйғҪжҳҜе®һзҺ°жңҖз»ҲдёҖиҮҙжҖ§дәӢеҠЎпјҢеӣ жӯӨйҖӮз”ЁдәҺдәҺдёҖдәӣеҜ№дәҺж—¶й—ҙдёҚж•Ҹж„ҹзҡ„дёҡеҠЎ
еӨ§иҮҙдәҶи§ЈдәҶиҝҷдёүзұ»пјҢжҺҘдёӢжқҘжқҘз»Ҷз»ҶеӯҰд№ жҜҸдёҖз§Қеҗ§
2PCдәҢйҳ¶ж®өжҸҗдәӨпјҡеҮҶеӨҮйҳ¶ж®өгҖҒжҸҗдәӨйҳ¶ж®ө
2PCпјҢеҸҲеҸ«еҒҡдәҢйҳ¶ж®өжҸҗдәӨпјҢдәҢйҳ¶ж®өжҢҮзҡ„жҳҜеҮҶеӨҮйҳ¶ж®өе’ҢжҸҗдәӨдёӨдёӘйҳ¶ж®ө
дәҢйҳ¶ж®өжҸҗдәӨеұһдәҺдёҖз§ҚејәдёҖиҮҙжҖ§зҡ„и®ҫи®ЎпјҢ2PCеј•е…ҘдёҖдёӘдәӢеҠЎеҚҸи°ғиҖ…зҡ„и§’иүІжқҘеҚҸи°ғз®ЎзҗҶеҗ„еҸӮдёҺиҖ…зҡ„жҸҗдәӨе’Ңеӣһж»ҡжңәеҲ¶пјҢжҲ‘们жқҘзңӢдёӢе…·дҪ“жөҒзЁӢ
еҮҶеӨҮйҳ¶ж®өеҚҸи°ғиҖ…дјҡеҗ‘еҗ„дёӘеҸӮдёҺиҖ…еҸ‘йҖҒеҮҶеӨҮзҡ„е‘Ҫд»ӨпјҢиҝҷдёӘеҮҶеӨҮе…¶е®һе°ұжҳҜеҮҶеӨҮзҺҜеўғпјҢеҸҜд»ҘзҗҶи§ЈжҲҗжҸҗдәӨд№ӢеүҚзҡ„еҮҶеӨҮе·ҘдҪң
еҗҢжӯҘзҡ„зӯүеҫ…жүҖжңүзҡ„иө„жәҗзҡ„е“Қеә”д№ӢеҗҺпјҢе°ұеҲ°дәҶдёҮдәӢдҝұеӨҮпјҢеҸӘж¬ жҸҗдәӨзҡ„зҠ¶жҖҒдәҶ
жҸҗдәӨйҳ¶ж®өпјҢжҸҗдәӨйҳ¶ж®ө并дёҚдёҖе®ҡжҳҜжҸҗдәӨдәӢеҠЎпјҢд№ҹжңүеҸҜиғҪжҳҜеӣһж»ҡдәӢеҠЎпјҢеҰӮжһң第дёҖйҳ¶ж®өйғҪеҮҶеӨҮжҲҗеҠҹпјҢеҲҷ第дәҢйҳ¶ж®өзҡ„жҸҗдәӨе°ұжҳҜжҸҗдәӨдәӢеҠЎ;еҗҢзҗҶеҰӮжһң第дёҖйҳ¶ж®өжңӘе…ЁйғЁеҮҶеӨҮжҲҗеҠҹпјҢеҲҷ第дәҢйҳ¶ж®өжҸҗдәӨзҡ„е°ұжҳҜеӣһж»ҡдәӢеҠЎдәҶгҖӮеҒҮи®ҫ第дёҖйҳ¶ж®өйғҪеҮҶеӨҮжҲҗеҠҹпјҢеҲҷеҚҸи°ғиҖ…еҗ‘жүҖжңүеҸӮдёҺиҖ…еҸ‘йҖҒжҸҗдәӨе‘Ҫд»ӨпјҢ然еҗҺжҺҘдёӢжқҘзӯүеҫ…жүҖжңүеҸӮдёҺиҖ…йғҪжҲҗеҠҹд№ӢеҗҺпјҢиҝ”еӣһдәӢеҠЎжү§иЎҢжҲҗеҠҹ
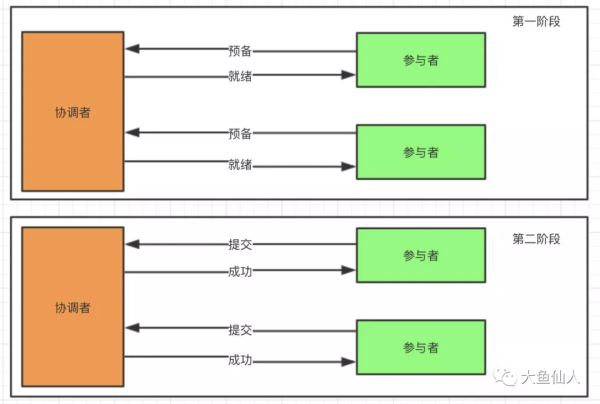
еҒҮи®ҫ第дёҖйҳ¶ж®өжңүйғЁеҲҶеҸӮдёҺиҖ…иҝ”еӣһеӨұиҙҘзҡ„иҜқпјҢйӮЈд№ҲеҚҸи°ғиҖ…еҲҷдјҡеҗ‘жүҖжңүеҸӮдёҺиҖ…йғҪеҸ‘йҖҒеӣһж»ҡдәӢеҠЎзҡ„иҜ·жұӮпјҢеҚізұ»дјјдёҠеӣҫпјҢеҗ‘е…ЁйғЁеҸӮдёҺиҖ…еҸ‘йҖҒеӣһж»ҡдәӢеҠЎ
иҜҙеҲ°иҝҷйҮҢе…¶е®һжңүдәӣе°Ҹдјҷдјҙе·Із»ҸејҖе§Ӣжңүз–‘й—®дәҶпјҢжҲ‘зҹҘйҒ“дәҶ第дёҖйҳ¶ж®өжңүеӨұиҙҘзҡ„еҰӮдҪ•еӨ„зҗҶдәҶпјҢдҪҶжҳҜеҰӮжһң第дәҢйҳ¶ж®өеҮәзҺ°еӨұиҙҘдәҶе’Ӣж•ҙе‘ў
е…¶е®һиҝҷйҮҢеҲҶдәҶдёӨз§Қжғ…еҶөпјҢеҲҶеҲ«жҳҜ第дәҢйҳ¶ж®өжү§иЎҢзҡ„жҳҜжҸҗдәӨйҳ¶ж®өгҖҒ第дәҢйҳ¶ж®өжү§иЎҢзҡ„жҳҜеӣһж»ҡж“ҚдҪңпјҢиҝҷдёӨз§Қжғ…еҶөзҡ„еӨ„зҗҶж–№ејҸе…¶е®һжҳҜдёҖж ·зҡ„пјҢйғҪжҳҜеұһдәҺдёҚж–ӯең°йҮҚиҜ•пјҢзӣҙеҲ°йҮҚиҜ•жҲҗеҠҹ;еҜ№дәҺжҸҗдәӨжқҘиҜҙпјҢеҸҜд»Ҙж №жҚ®дёҡеҠЎеңәжҷҜпјҢжү§иЎҢдёҖе®ҡж¬Ўж•°зҡ„йҮҚиҜ•д№ӢеҗҺпјҢе°қиҜ•еӣһж»ҡ;дҪҶжҳҜеҜ№дәҺеӣһж»ҡж“ҚдҪңпјҢжҖ»дёҚиғҪжү§иЎҢжҲҗеҠҹж“ҚдҪңеҗ§
жүҖд»ҘпјҢеҰӮжһң第дәҢйҳ¶ж®өжҳҜеӣһж»ҡж“ҚдҪңжңүеӨұиҙҘпјҢеҪ“еӨұиҙҘж¬Ўж•°иҫҫеҲ°дёҖе®ҡж¬Ўж•°зҡ„ж—¶еҖҷпјҢжңҖеҘҪзҡ„ж–№жі•е°ұжҳҜдәәе·Ҙд»Ӣе…ҘдәҶ
жҸҗдәӨжөҒзЁӢеӨ§иҮҙд№ҹеҲҶжһҗзҡ„е·®дёҚеӨҡдәҶпјҢжҺҘдёӢжқҘдёҖиө·зңӢзңӢз»ҶиҠӮйғЁеҲҶпјҢ2PCеҸҜд»ҘзңӢжҲҗеҗҢжӯҘйҳ»еЎһеҚҸи®®пјҢеҗҢжӯҘйҳ»еЎһзҡ„зӯүеҫ…жүҖжңүеҸӮдёҺиҖ…зҡ„第дёҖйҳ¶ж®өйғҪжңүе“Қеә”д№ӢеҗҺпјҢжүҚдјҡиҝӣиЎҢ第дәҢйҳ¶ж®өзҡ„ж“ҚдҪң;еҜ№дәҺJavaеҹәзЎҖеҫҲзҶҹжӮүзҡ„е°ҸдјҷдјҙжҳҜдёҚжҳҜеҫҲеҝ«жғіиө·жқҘJava并еҸ‘еҢ…дёӯзҡ„дёҖдёӘе·Ҙе…·зұ»CountDownLatchпјҢд»ҘеҸҠеҠҹиғҪзұ»дјјзҡ„CyclicBarrierпјҢеҝҳи®°зҡ„иө¶зҙ§еӣһеҝҶдёӢ
е…¶е®һ2PCдёӯеҜ№дәҺиҝҷйҮҢзҡ„еҗҢжӯҘйҳ»еЎһжҳҜжңүи¶…ж—¶жңәеҲ¶зҡ„пјҢеҚҸи°ғиҖ…зӯүеҫ…еҸӮдёҺиҖ…зҡ„е“Қеә”и¶…ж—¶зҡ„жғ…еҶөдёӢпјҢдјҡй»ҳи®ӨеӨұиҙҘпјҢ然еҗҺеҚҸи°ғиҖ…зӣҙжҺҘеҗ‘жүҖжңүеҸӮдёҺиҖ…еҸ‘иө·еӣһж»ҡзҡ„е‘Ҫд»ӨпјҢзҹҘйҒ“иҝҷж¬ЎдәӢеҠЎеӨұиҙҘ
дёҠйқўиҝҷдәӣйғҪжҳҜеҹәдәҺеҸӮдёҺиҖ…зҡ„и§’еәҰжқҘиҖғиҷ‘зҡ„пјҢйӮЈеҰӮжһңеҚҸи°ғиҖ…еҮәй—®йўҳдәҶе‘ў
еҚҸи°ғиҖ…еҰӮжһңжҳҜеҚ•зӮ№зҡ„пјҢеҮәзҺ°ж•…йҡңд№ӢеҗҺпјҢеҸҜиғҪдјҡеҮәзҺ°дёҖдәӣзі»з»ҹзҡ„й—®йўҳпјҢжҲ‘们д»ҺжөҒзЁӢзҡ„и§’еәҰеҲҶжһҗдёӢпјҡ
еҮҶеӨҮйҳ¶ж®өе‘Ҫд»ӨжңӘеҸ‘еҮәпјҢеҚҸи°ғиҖ…ж•…йҡңпјҢдәӢеҠЎиҝҳжІЎејҖе§ӢпјҢй—®йўҳдёҚеӨ§;
еҮҶеӨҮйҳ¶ж®өе‘Ҫд»ӨеҸ‘еҮәдәҶпјҢеҚҸи°ғиҖ…ж•…йҡңпјҢдәӢеҠЎејҖе§ӢдәҶпјҢж— и®әеҸӮдёҺиҖ…йғҪжҳҜжҲҗеҠҹиҝҳжҳҜеӨұиҙҘпјҢжңҖз»Ҳжғ…еҶөйғҪеҫҲзіҹзі•пјҢеӣ дёәеҸӮдёҺиҖ…ж— жі•зӯүеҲ°дёӢдёҖжӯҘзҡ„жҢҮд»ӨдәҶпјҢд№ҹе°ұжҳҜеҚЎзўҹдәҶпјҢдёҚд»…дәӢеҠЎж— жі•жү§иЎҢпјҢиҝҳдјҡй”Ғе®ҡдёҖдәӣе…¬з”Ёиө„жәҗиҖҢйҳ»еЎһе…¶е®ғзі»з»ҹ;еҮҶеӨҮйҳ¶ж®өе‘Ҫд»ӨеҸ‘еҮәпјҢе…ЁйғЁжҲҗеҠҹпјҢ第дәҢйҳ¶ж®өжү§иЎҢжҸҗдәӨйҳ¶ж®өе‘Ҫд»ӨеҸ‘еҮәпјҢиҝҷз§Қжғ…еҶөд№ҹжҳҜдёҚиЎҢзҡ„пјҢеӣ дёәд№ҹеҸҜиғҪеӣ дёәеҲҶеҢәе’ҢзҪ‘з»ңйҳ»еЎһпјҢжҹҗдәӣеҸӮдёҺиҖ…жңӘ收еҲ°жҸҗдәӨе‘Ҫд»ӨпјҢзҗҶжғіжғ…еҶөдёӢеҰӮжһңеҸӮдёҺиҖ…дёҖж¬ЎжҖ§е…ЁйғЁж”¶еҲ°жҸҗдәӨе‘Ҫд»ӨпјҢдҪҶжҳҜеҸӮдёҺиҖ…жңүеҸҜиғҪжҸҗдәӨеӨұиҙҘпјҢиҝҷж ·иҝҳжҳҜйңҖиҰҒйҮҚиҜ•пјҢжӯӨж—¶еҚҸи°ғиҖ…жҢӮдәҶпјҢд№ҹжҳҜдёҚиЎҢ
еҮҶеӨҮйҳ¶ж®өе‘Ҫд»ӨеҸ‘еҮәпјҢйғЁеҲҶеӨұиҙҘпјҢ第дәҢйҳ¶ж®өеӣһж»ҡе‘Ҫд»ӨеҸ‘еҮәпјҢе…¶е®һе’ҢдёҠйқўжғ…еҶөзұ»дјјпјҢд№ҹжҳҜдјҡеҮәзҺ°еҗ„ејҸеҗ„ж ·зҡ„й—®йўҳ
既然еҚ•зӮ№еҚҸи°ғиҖ…дёҚиЎҢпјҢйӮЈе°ұжқҘдёӘеӨҡдёӘзҡ„еҗ§пјҢйҖҡиҝҮйҖүдёҫжңәеҲ¶еҶҚйҖүдёҖдёӘж–°еҚҸи°ғиҖ…
еҰӮжһңйғҪеӨ„дәҺ第дёҖйҳ¶ж®өпјҢе…¶е®һйғҪиҝҳеҘҪпјҢдәӢеҠЎиҝҳжІЎжҸҗдәӨпјҢзӣҙжҺҘйғҪдјҡж»ҡе°ұеҘҪдәҶ;еҰӮжһңеӨ„дәҺ第дәҢйҳ¶ж®өпјҢеҒҮи®ҫеҸӮдёҺиҖ…йғҪжІЎжҢӮпјҢжӯӨж—¶ж–°еҚҸи°ғиҖ…еҸҜд»Ҙеҗ‘жүҖжңүеҸӮдёҺиҖ…жқҘиҝӣдёҖжӯҘзЎ®и®Ө他们иҮӘиә«зҡ„жғ…еҶөжқҘжҺЁж–ӯдёӢдёҖжӯҘиҜҘеҰӮдҪ•ж“ҚдҪңпјҢеҰӮжһңдёӘеҲ«еҸӮдёҺиҖ…жҢӮдәҶпјҢе°ұжҜ”иҫғе°ҙе°¬дәҶгҖӮжҜ”еҰӮеҚҸи°ғиҖ…еҸ‘йҖҒдәҶеӣһж»ҡзҡ„е‘Ҫд»ӨпјҢжӯӨ时第дёҖдёӘеҸӮдёҺиҖ…收еҲ°дәҶ并жү§иЎҢдәҶпјҢ然еҗҺеҚҸи°ғиҖ…е’Ң第дёҖдёӘеҸӮдёҺиҖ…йғҪжҢӮжҺүдәҶпјҢжӯӨж—¶е…¶е®ғеҸӮдёҺиҖ…йғҪ没收еҲ°иҜ·жұӮпјҢ然еҗҺж–°еҚҸи°ғиҖ…жқҘдәҶпјҢе®ғиҜўй—®дәҶе…¶е®ғзҡ„еҸӮдёҺиҖ…йғҪеӣһзӯ”OKпјҢдҪҶжҳҜе®ғдёҚзҹҘйҒ“е…¶дёӯ第дёҖдёӘеҸӮдёҺиҖ…жҢӮдәҶпјҢжӯӨж—¶иҰҒжҳҜжҢүз…§е…ЁйғЁOKжқҘеӨ„зҗҶпјҢзӣҙжҺҘеҸ‘йҖҒжҸҗдәӨе‘Ҫд»ӨпјҢе°ұзіҹзі•дәҶпјҢиҝҷдёҚжҳҜжҲ‘们жғіиҰҒзҡ„з»“жһң
е…¶е®һиҷҪ然2PCеҚҸи®®дёҠжІЎиҜҙпјҢдҪҶжҳҜеңЁе®һзҺ°зҡ„ж—¶еҖҷжҲ‘们йңҖиҰҒзҒөжҙ»зҡ„и®©еҚҸи°ғиҖ…е°ҶиҮӘе·ұеҸ‘иҝҮзҡ„иҜ·жұӮеңЁе“Әдәӣең°ж–№йғҪи®°дёҖдёӢпјҢд№ҹе°ұзұ»дјјдәҺж—Ҙеҝ—и®°еҪ•пјҢиҝҷж ·ж–°зҡ„еҚҸи°ғиҖ…жқҘзҡ„ж—¶еҖҷе°ұдёҚгҖҒзҹҘйҒ“жӯӨж—¶иҜҘдёҚиҜҘеҸ‘дәҶ
еҚідҪҝеҚҸи°ғиҖ…зҹҘйҒ“иҮӘе·ұеә”иҜҘеҸ‘жҸҗдәӨиҝҳжҳҜеӣһж»ҡиҜ·жұӮпјҢдҪҶжҳҜеңЁеҸӮдёҺиҖ…д№ҹдёҖиө·жҢӮдәҶзҡ„жғ…еҶөдёӢд№ҹжҳҜжІЎз”Ёзҡ„пјҢеӣ дёәеҚҸи°ғиҖ…ж— жі•зҹҘйҒ“еҸӮдёҺиҖ…еңЁжҢӮд№ӢеүҚжңүжІЎжңүжҸҗдәӨдәӢеҠЎпјҢе…¶е®һиҝҷйҮҢжңҖйқ и°ұзҡ„ж–№жі•пјҢе°ұжҳҜеҜ№жҜҸдёҖжӯҘйғҪиҝӣиЎҢзӣёеә”зҡ„ж—Ҙеҝ—и®°еҪ•пјҢйҮҚиҰҒзҡ„жӯҘйӘӨжңҖеҘҪиҝҳжҳҜејәз»‘е®ҡж—Ҙеҝ—и®°еҪ•зҡ„пјҢеҗҰеҲҷж“ҚдҪңжҲҗеҠҹдәҶпјҢж—Ҙеҝ—и®°еҪ•еӨұиҙҘйӮЈд№ҹеҫҲзіҹзі•пјҢжҖ»д№Ӣе°ұжҳҜиҰҒиҖғиҷ‘еҗ„з§ҚжһҒз«Ҝзҡ„жғ…еҶөпјҢе°ҪжңҖеӨ§еҠӘеҠӣеҺ»еҒҡеҲ°жҜҸдёӘз»ҶиҠӮйғҪиҖғиҷ‘еҲ°
2PCжҳҜдёҖз§Қе°ҪйҮҸдҝқиҜҒејәдёҖиҮҙжҖ§зҡ„еҲҶеёғејҸдәӢеҠЎпјҢеӣ дёәе®ғжҳҜеҗҢжӯҘйҳ»еЎһзҡ„пјҢиҖҢеҗҢжӯҘйҳ»еЎһе°ұж„Ҹе‘ізқҖеңЁжҹҗдәӣжғ…еҶөдёӢдјҡеҮәзҺ°й”Ғе®ҡиө„жәҗзҡ„жғ…еҶөпјҢиҖҢдё”еҚ•зӮ№дёҖж—ҰеҮәзҺ°ж•…йҡңпјҢе°ұдјҡйҖ жҲҗиө„жәҗй”Ғе®ҡзҡ„жғ…еҶө
д»ҘдёӢд»Јз ҒеҸ–иҮӘ <<Distributed System: Principles and Paradigms>>
еҚҸи°ғиҖ…: write START_2PC to local log; //ејҖе§ӢдәӢеҠЎ multicast VOTE_REQUEST to all participants; //е№ҝж’ӯйҖҡзҹҘеҸӮдёҺиҖ…жҠ•зҘЁ while not all votes have been collected { wait for any incoming vote; if timeout { //еҚҸи°ғиҖ…и¶…ж—¶ write GLOBAL_ABORT to local log; //еҶҷж—Ҙеҝ— multicast GLOBAL_ABORT to all participants; //йҖҡзҹҘдәӢеҠЎдёӯж–ӯ exit; } record vote; } //еҰӮжһңжүҖжңүеҸӮдёҺиҖ…йғҪok if all participants sent VOTE_COMMIT and coordinator votes COMMIT { write GLOBAL_COMMIT to local log; multicast GLOBAL_COMMIT to all participants; } else { write GLOBAL_ABORT to local log; multicast GLOBAL_ABORT to all participants; } еҸӮдёҺиҖ…: write INIT to local log; //еҶҷж—Ҙеҝ— wait for VOTE_REQUEST from coordinator; if timeout { //зӯүеҫ…и¶…ж—¶ write VOTE_ABORT to local log; exit; } if participant votes COMMIT { write VOTE_COMMIT to local log; //и®°еҪ•иҮӘе·ұзҡ„еҶізӯ– send VOTE_COMMIT to coordinator; wait for DECISION from coordinator; if timeout { multicast DECISION_REQUEST to other participants; //и¶…ж—¶йҖҡзҹҘ wait until DECISION is received; /* remain blocked*/ write DECISION to local log; } if DECISION == GLOBAL_COMMIT write GLOBAL_COMMIT to local log; else if DECISION == GLOBAL_ABORT write GLOBAL_ABORT to local log; } else { write VOTE_ABORT to local log; send VOTE_ABORT to coordinator; } жҜҸдёӘеҸӮдёҺиҖ…з»ҙжҠӨдёҖдёӘзәҝзЁӢеӨ„зҗҶе…¶е®ғеҸӮдёҺиҖ…зҡ„DECISION_REQUESTиҜ·жұӮпјҡ while true { wait until any incoming DECISION_REQUEST is received; read most recently recorded STATE from the local log; if STATE == GLOBAL_COMMIT send GLOBAL_COMMIT to requesting participant; else if STATE == INIT or STATE == GLOBAL_ABORT; send GLOBAL_ABORT to requesting participant; else skip; /* participant remains blocked */ }3PCдёүйҳ¶ж®өжҸҗдәӨпјҡеҮҶеӨҮйҳ¶ж®өгҖҒйў„жҸҗдәӨйҳ¶ж®өгҖҒжҸҗдәӨйҳ¶ж®ө
3PCе…¶е®һе°ұжҳҜ2PCзҡ„еҚҮзә§зүҲпјҢзӣёжҜ”дәҺ2PCпјҢеҸӮдёҺиҖ…д№ҹеј•е…ҘдәҶи¶…ж—¶жңәеҲ¶пјҢ并且иҝҳж–°еўһдәҶдёҖдёӘйҳ¶ж®өдҪҝеҫ—еҸӮдёҺиҖ…еҸҜд»ҘеҲ©з”ЁиҝҷдёҖйҳ¶ж®өжқҘз»ҹдёҖеҗ„иҮӘзҡ„зҠ¶жҖҒ
3PCеҲҶдёәдёүдёӘйҳ¶ж®өпјҡеҮҶеӨҮйҳ¶ж®өгҖҒйў„жҸҗдәӨйҳ¶ж®өгҖҒжҸҗдәӨйҳ¶ж®өгҖӮзңӢиө·жқҘжӣҙеғҸжҳҜжҠҠ2PCдёӯзҡ„жҸҗдәӨйҳ¶ж®өеҲҶдёәдәҶйў„жҸҗдәӨе’ҢжҸҗдәӨзҡ„дёӨдёӘйҳ¶ж®өпјҢ дҪҶжҳҜиҝҷйҮҢзҡ„еҮҶеӨҮйҳ¶ж®өе…¶е®һе°ұжҳҜиҜўй—®еҸӮдёҺиҖ…зҡ„иҮӘиә«зҠ¶еҶөпјҢе°ұжҳҜй—®дҪ зҺ°еңЁзҡ„зҠ¶еҶөеҰӮдҪ•пјҢиҙҹиҪҪжҳҜдёҚжҳҜи¶…иҪҪпјҢиҝҳеҸҜд»ҘеҶҚжҺҘеҸ—ж–°зҡ„д»»еҠЎеҗ—
иҖҢйў„жҸҗдәӨйҳ¶ж®өе…¶е®һе°ұжҳҜзұ»дјјдәҺ2PCзҡ„еҮҶеӨҮйҳ¶ж®өпјҢе°ұжҳҜйҷӨдәҶдәӢеҠЎзҡ„жҸҗдәӨиҜҘеҒҡзҡ„йғҪеҒҡдәҶпјҢе°ұжҳҜд№ӢеүҚзҡ„еҮҶеӨҮе·ҘдҪңпјҢдҪҶжҳҜеңЁ3PCдёӯеҸ«еҒҡйў„жҸҗдәӨйҳ¶ж®ө
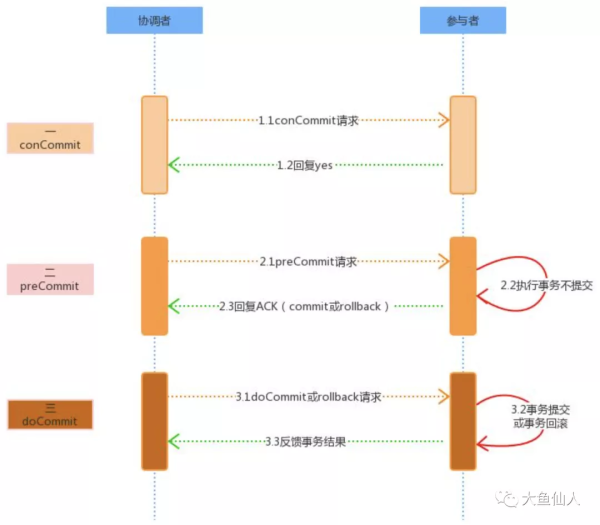
3PCжҳҜйҰ–е…ҲеҮҶеӨҮйҳ¶ж®ө并дёҚдјҡзӣҙжҺҘжү§иЎҢдәӢеҠЎпјҢиҖҢжҳҜе…ҲеҺ»иҜўй—®жӯӨж—¶зҡ„еҸӮдёҺиҖ…жҳҜеҗҰжңүжқЎд»¶еҸҜд»Ҙжү§иЎҢиҝҷдёӘдәӢеҠЎпјҢеӣ жӯӨдёҚдјҡзӣҙжҺҘй”ҒдҪҸиө„жәҗпјҢиҖҢйў„жҸҗдәӨйҳ¶ж®өзҡ„еј•е…ҘеҲҷжҳҜдёәдәҶиө·еҲ°дәҶдёҖдёӘз»ҹзҠ¶жҖҒзҡ„дҪңз”ЁпјҢеңЁйў„еӨ„зҗҶйҳ¶ж®өиЎЁйқўжүҖжңүеҸӮдёҺиҖ…йғҪе·Із»Ҹеӣһеә”дәҶ
е…¶е®һиҝҷд№ҹеӨҡеј•е…ҘдәҶдёҖдёӘйҳ¶ж®өпјҢеӣ жӯӨжҖ§иғҪдјҡе·®дёҖдәӣпјҢиҖҢдё”з»қеӨ§йғЁеҲҶзҡ„жғ…еҶөдёӢиө„жәҗд№ҹйғҪжҳҜжІЎй—®йўҳзҡ„пјҢд№ҹе°ұжҳҜеҸҜз”Ёзҡ„пјҢиҝҷж ·зӯүдәҺжҜҸж¬ЎжҳҺзҹҘеҸҜз”ЁдҪҶжҳҜиҝҳжҳҜеҫ—иҜўй—®дёҖж¬Ў
еҪ“然пјҢиҝҷе…¶дёӯе“ӘдёҖдёӘйҳ¶ж®өзҡ„еҸӮдёҺиҖ…иҝ”еӣһеӨұиҙҘйғҪдјҡе®ЈеёғдәӢеҠЎеӨұиҙҘпјҢиҝҷдёӘ2PCд№ҹжҳҜдёҖж ·зҡ„пјҢеҪ“然еҲ°жңҖеҗҺзҡ„жҸҗдәӨйҳ¶ж®өе’Ң2PCдёҖж ·йғҪжҳҜеҸӘиҰҒжҳҜжҸҗдәӨиҜ·жұӮд№ҹе°ұеҸӘиғҪйҖҡиҝҮдёҚж–ӯзҡ„йҮҚиҜ•е’Ҝ
жҲ‘们дёҠйқўиҜҙиҝҮ2PCжҳҜеҗҢжӯҘйҳ»еЎһзҡ„пјҢеҚҸи°ғиҖ…жҢӮеңЁдәҶжҸҗдәӨиҜ·жұӮиҝҳжңӘеҸ‘еҮәеҺ»зҡ„ж—¶еҖҷжҳҜжңҖе°ҙе°¬зҡ„пјҢжүҖжңүеҸӮдёҺиҖ…йғҪе·Із»Ҹй”Ғе®ҡдәҶиө„жәҗ并且йҳ»еЎһзҡ„зӯүеҫ…зқҖпјҢдәҺжҳҜеј•е…ҘдәҶи¶…ж—¶жңәеҲ¶пјҢеҸӮдёҺиҖ…еҲҷдёҚз”ЁзӣҙжҺҘе№Іе№Ізҡ„зӯүзқҖдәҶпјҢеҰӮжһңжҳҜзӯүеҫ…жҸҗдәӨе‘Ҫд»Өи¶…ж—¶пјҢйӮЈд№ҲеҸӮдёҺиҖ…е°ұдјҡжҸҗдәӨдәӢеҠЎдәҶпјҢеӣ дёәеҲ°дәҶиҝҷдёҖйҳ¶ж®өеӨ§жҰӮзҺҮйғҪжҳҜжҸҗдәӨзҡ„пјҢеҰӮжһңжҳҜзӯүеҫ…йў„жҸҗдәӨи¶…ж—¶пјҢжҺҘдёӢжқҘд№ҹжІЎе•ҘеҪұе“Қ
иҝҷйҮҢе…¶е®һжңүдёҖдёӘй—®йўҳпјҢ然еҗҺи¶…ж—¶жңәеҲ¶дјҡеёҰжқҘж•°жҚ®дёҚдёҖиҮҙзҡ„й—®йўҳпјҢе°ұжҳҜеңЁзӯүеҫ…жҸҗдәӨе‘Ҫд»Өзҡ„ж—¶еҖҷи¶…ж—¶пјҢйӮЈд№ҲеҸӮдёҺиҖ…иҮӘеҠЁжҸҗдәӨдәӢеҠЎдәҶпјҢдҪҶжҳҜе‘ўпјҢд№ҹеҸҜиғҪжү§иЎҢзҡ„жҳҜеӣһж»ҡжңәеҲ¶пјҢиҝҷж ·дёҖжқҘж•°жҚ®дҫҝеҮәзҺ°дәҶдёҚдёҖиҮҙдәҶ
3PCзҡ„еј•е…ҘжҳҜдёәдәҶи§ЈеҶіжҸҗдәӨйҳ¶ж®ө2PCеҚҸи°ғиҖ…е’Ңе…¶дёӯзҡ„йғЁеҲҶеҸӮдёҺиҖ…йғҪжҢӮдәҶзҡ„жғ…еҶөдёӢпјҢ然еҗҺд№ӢеҗҺзҡ„ж–°йҖүдёҫзҡ„еҚҸи°ғиҖ…дёҚзҹҘйҒ“еҪ“еүҚеә”иҜҘжҳҜиҜҘжҸҗдәӨиҝҳжҳҜеӣһж»ҡзҡ„й—®йўҳпјҢж–°еҚҸи°ғиҖ…жқҘзҡ„ж—¶еҖҷеҸ‘зҺ°жңүдёҖдёӘеҸӮдёҺиҖ…еӨ„дәҺйў„жҸҗдәӨжҲ–иҖ…жҸҗдәӨйҳ¶ж®өпјҢйӮЈд№ҲиЎЁжҳҺжүҖд»ҘеҸӮдёҺиҖ…йғҪе·Із»Ҹз»ҸиҝҮзЎ®и®ӨдәҶпјҢжүҖд»ҘжӯӨж—¶жү§иЎҢзҡ„е°ұжҳҜжҸҗдәӨе‘Ҫд»ӨдәҶ
3PCе°ұжҳҜйҖҡиҝҮеј•е…Ҙйў„жҸҗдәӨйҳ¶ж®өжқҘжҳҜзҡ„еҸӮдёҺиҖ…д№Ӣй—ҙзҡ„зҠ¶жҖҒеҫ—еҲ°зңҹжӯЈзҡ„з»ҹдёҖпјҢд№ҹе°ұжҳҜз•ҷдәҶдёҖдёӘйҳ¶ж®өи®©еӨ§е®¶йғҪеҗҢжӯҘпјҢдҪҶжҳҜиҝҷд№ҹжҳҜеҸӘиғҪи®©еҚҸи°ғиҖ…зҹҘйҒ“еҰӮдҪ•еҒҡпјҢ并дёҚиғҪдҝқиҜҒиҝҷж ·еҒҡдёҖе®ҡжҳҜеҜ№зҡ„пјҢиҝҷе…¶е®һе’ҢдёҠйқўзҡ„2PCзҡ„еҲҶжһҗдёҖзӣҙпјҢеӣ дёәжҢӮдәҶзҡ„еҸӮдёҺиҖ…еҲ°еә•жңүжІЎжңүжү§иЎҢдәӢеҠЎжҳҜж— жі•ж–ӯе®ҡзҡ„пјҢжүҖд»ҘиҜҙе‘ўпјҢ3PCйҖҡиҝҮйў„жҸҗдәӨйҳ¶ж®өеҸҜд»ҘеҮҸе°‘ж•…йҡңж—¶еҖҷзҡ„еӨҚжқӮжҖ§пјҢдҪҶжҳҜ并дёҚиғҪдҝқиҜҒж•°жҚ®зңҹжӯЈзҡ„дёҖиҮҙпјҢеӨ„зҗҶжҢӮдәҶзҡ„йӮЈдёӘеҸӮдёҺиҖ…д№ҹжҒўеӨҚдәҶ
дёҖеҸҘиҜқжҖ»з»“пјҡ3PCзӣёжҜ”дәҺ2PCеҒҡдәҶдёҖе®ҡзҡ„еҸӮдёҺиҖ…и¶…ж—¶жңәеҲ¶зҡ„ж”№иҝӣпјҢ并且еўһеҠ дәҶйў„жҸҗдәӨйҳ¶ж®өпјҢеҸҜд»ҘдҪҝж•…йҡңжҒўеӨҚд№ӢеҗҺзҡ„еҚҸи°ғиҖ…зҡ„еҶізӯ–еӨҚжқӮеәҰйҷҚдҪҺпјҢдҪҶж•ҙдҪ“зҡ„дәӨдә’иҝҮзЁӢдјҡеҸҳеҫ—жӣҙй•ҝпјҢжҖ§иғҪдјҡжңүжүҖдёӢйҷҚпјҢиҖҢдё”иҝҳдјҡеҮәзҺ°ж•°жҚ®дёҚдёҖиҮҙзҡ„жғ…еҶө
TCCпјҡTry-Confirm-Cancel
TCCеұһдәҺдёҡеҠЎеұӮйқўзҡ„еҲҶеёғејҸдәӢеҠЎпјҢеҲҶеёғејҸдәӢеҠЎдёҚд»…д»…еҢ…еҗ«ж•°жҚ®еә“еұӮйқўзҡ„ж“ҚдҪңпјҢиҝҳеҢ…жӢ¬дёҡеҠЎеұӮйқўзҡ„ж“ҚдҪңпјҢиҝҷж—¶еҖҷTCCе°ұиҰҒжҺ’дёҠз”ЁеңәдәҶ
TCCжҢҮзҡ„е°ұжҳҜTryгҖҒConfirmгҖҒCancelдёүдёӘжӯҘйӘӨпјҢTryжҢҮзҡ„жҳҜйў„з•ҷпјҢжҢҮзҡ„жҳҜиө„жәҗзҡ„йў„з•ҷе’Ңй”Ғе®ҡ;ConfirmжҢҮзҡ„е°ұжҳҜзЎ®и®Өж“ҚдҪңпјҢиҝҷдёҖжӯҘе…¶е®һе°ұжҳҜеұһдәҺзңҹжӯЈзҡ„жү§иЎҢдәҶпјҢзңҹжӯЈзҡ„ж¶ҲиҖ—иө„жәҗжқҘиҝӣиЎҢзӣёеә”зҡ„дёҡеҠЎжҸҗдәӨж“ҚдҪң;CancelжҢҮзҡ„жҳҜж’Өй”Җж“ҚдҪңпјҢеҸҜд»ҘзҗҶи§ЈдёәжҠҠйў„з•ҷйҳ¶ж®өзҡ„еҠЁдҪңй”ҖжҜҒдәҶпјҢе°ұжҳҜдёҖдёӘеӣһж»ҡж“ҚдҪң
д»ҺжҖқжғідёҠжқҘзңӢпјҢе…¶е®һжҳҜе’Ң2PCгҖҒ3PCжҳҜзұ»дјјзҡ„пјҢйғҪжҳҜе…ҲиҜ•жҺўжҖ§зҡ„жү§иЎҢпјҢе…ҲиҜ•жҺўжҖ§зҡ„й”Ғе®ҡиө„жәҗпјҢеҰӮжһңжҜҸдёҖдёӘеҸӮдёҺиҖ…йғҪжІЎй—®йўҳдәҶпјҢе°ұеҸҜд»Ҙжү§иЎҢзңҹжӯЈзҡ„ж“ҚдҪңдәҶпјҢжҸҗдәӨжҲ–иҖ…еӣһж»ҡ
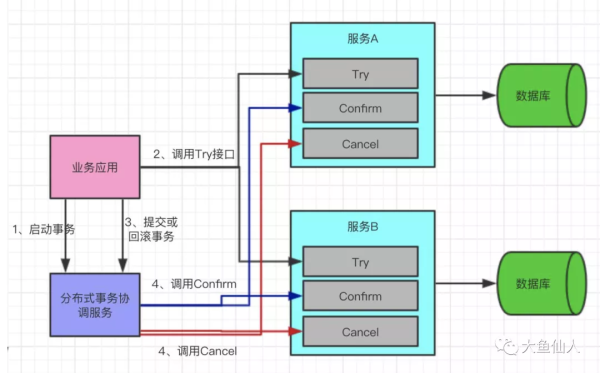
дёҫдёӘдҫӢеӯҗпјҡдёҖдёӘдәӢеҠЎиҰҒжү§иЎҢAгҖҒBгҖҒCдёүдёӘж“ҚдҪңпјҢйӮЈд№Ҳе…ҲеҜ№дёүдёӘж“ҚдҪңжү§иЎҢйў„з•ҷеҠЁдҪңпјҢеҰӮжһңжүҖжңүйғҪйў„з•ҷжҲҗеҠҹдәҶйӮЈд№Ҳе°ұжү§иЎҢзЎ®и®ӨжҸҗдәӨж“ҚдҪңпјҢеҰӮжһңе…¶дёӯиҮіе°‘жңүдёҖдёӘйў„з•ҷеӨұиҙҘпјҢйӮЈе°ұйғҪжү§иЎҢж’Өй”Җзҡ„еҠЁдҪң
TCCжЁЎеһӢе…¶дёӯиҝҳжңүдёҖдёӘдәӢеҠЎз®ЎзҗҶиҖ…зҡ„и§’иүІпјҢз”ЁжқҘи®°еҪ•TCCжңүе…ізҡ„е…ЁеұҖдәӢеҠЎж“ҚдҪңзҡ„зҠ¶жҖҒпјҢ并且еҮҶеӨҮжҸҗдәӨжҲ–иҖ…еӣһж»ҡдәӢеҠЎпјҢе…¶е®һиҝҷдёӘжҳҜжҜ”иҫғе®№жҳ“зҗҶи§Јзҡ„пјҢйҡҫзӮ№еңЁдәҺдёҡеҠЎдёҠзҡ„е®ҡд№ү
жҖҺд№ҲиҜҙе‘ўпјҢTCCиҝҷз§ҚжҳҜеҜ№дёҡеҠЎзҡ„дҫөе…ҘиҫғеӨ§е’ҢдёҡеҠЎзҙ§иҖҰеҗҲпјҢйңҖиҰҒж №жҚ®зӣёеә”зҡ„зү№е®ҡзҡ„дёҡеҠЎеңәжҷҜе’ҢдёҡеҠЎйҖ»иҫ‘жқҘи®ҫе®ҡзҡ„е“Қеә”ж“ҚдҪңпјҢе…¶е®һиҝҳжңүдёҖзӮ№йңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҢж’Өй”Җе’ҢзЎ®и®Өзҡ„ж“ҚдҪңзҡ„жү§иЎҢзҡ„е°ұжҳҜйңҖиҰҒйҮҚиҜ•пјҢе°ұжҳҜйңҖиҰҒдҝқиҜҒж“ҚдҪңзҡ„е№ӮзӯүжҖ§
TCCзӣёеҜ№жқҘиҜҙпјҢйҖӮз”Ёзҡ„иҢғеӣҙеә”иҜҘжҳҜжӣҙе№ҝзҡ„пјҢдҪҶжҳҜиҝҷдёӘжҳҜжңүдёҖдёӘзјәзӮ№зҡ„пјҢе°ұжҳҜиҝҷдёӘе’ҢдёҡеҠЎжҳҜиҖҰеҗҲзҡ„пјҢйңҖиҰҒеӨ§йҮҸзҡ„ејҖеҸ‘пјҢеӣ дёәйғҪжҳҜеңЁдёҡеҠЎдёҠзҡ„е®һзҺ°пјҢзӯүеҗҢдәҺжҜҸдёӘеңәжҷҜйғҪйңҖиҰҒдёүдёӘж–№жі•жқҘе®һзҺ°пјҢе°ұжҳҜеөҢе…ҘдёҡеҠЎпјҢжүҖд»ҘTCCжҳҜеҸҜд»Ҙи·ЁдёҡеҠЎзі»з»ҹгҖҒи·Ёж•°жҚ®еә“жқҘе®һзҺ°дәӢеҠЎ
жң¬ең°ж¶ҲжҒҜиЎЁ
жң¬ең°ж¶ҲжҒҜиЎЁпјҢе°ұжҳҜеҲ©з”ЁдәҶеҗ„дёӘзі»з»ҹзҡ„жң¬ең°дәӢеҠЎжқҘе®һзҺ°еҲҶеёғејҸдәӢеҠЎпјҢиҝҷдёӘе‘ўпјҢе…¶е®һеҫҲз®ҖеҚ•зҡ„йҒ“зҗҶпјҢе…¶е®һе°ұжҳҜдјҡжңүдёҖеј еӯҳж”ҫжң¬ең°ж¶ҲжҒҜзҡ„иЎЁпјҢдёҖиҲ¬йғҪжҳҜж”ҫеңЁж•°жҚ®еә“дёӯпјҢ然еҗҺеңЁжү§иЎҢдёҡеҠЎзҡ„ж—¶еҖҷпјҢеҝ…йЎ»жҠҠдёҡеҠЎзҡ„зңҹжӯЈзҡ„жү§иЎҢж“ҚдҪңе’Ңзӣёеә”зҡ„иҝҷдёӘж“ҚдҪңзҡ„ж¶ҲжҒҜж”ҫе…ҘеҲ°ж¶ҲжҒҜиЎЁдёӯиҝҷдёӘж“ҚдҪңпјҢеӯҳж”ҫеҲ°еҗҢдёҖдёӘдәӢеҠЎдёӯпјҢе°ұжҳҜеҸӘиҰҒж“ҚдҪңжҲҗеҠҹдәҶпјҢе°ұеҝ…йЎ»дҝқиҜҒиҜҘж¶ҲжҒҜд№ҹжҲҗеҠҹзҡ„ж”ҫе…ҘеҲ°жң¬ең°зҡ„ж¶ҲжҒҜиЎЁдёӯдәҶ
жҺҘдёӢжқҘи°ғз”ЁдёӢдёҖдёӘж“ҚдҪңзҡ„ж—¶еҖҷпјҢеҰӮжһңдёӢдёҖдёӘж“ҚдҪңи°ғз”ЁжҲҗеҠҹдәҶпјҢе°ұеҸҜд»ҘзӣҙжҺҘжҠҠж¶ҲжҒҜзҡ„зҠ¶жҖҒж”№жҲҗе·ІжҲҗеҠҹпјҢи°ғз”ЁеӨұиҙҘд№ҹжІЎжңүе…ізі»пјҢжҲ‘们еҸҜд»ҘеҶҷдёҖдёӘе®ҡж—¶д»»еҠЎжқҘиҜ»еҸ–жң¬ең°зҡ„ж¶ҲжҒҜиЎЁпјҢ然еҗҺзӯӣйҖүеҮәжңӘжү§иЎҢжҲҗеҠҹзҡ„ж¶ҲжҒҜеҶҚи°ғз”ЁеҜ№еә”зҡ„жңҚеҠЎпјҢжңҚеҠЎжӣҙж–°жҲҗеҠҹдәҶпјҢеҶҚж”№еҸҳж¶ҲжҒҜзҡ„зҠ¶жҖҒ
е…¶е®һиҝҷйҮҢд№ҹжҳҜйңҖиҰҒйҮҚиҜ•жңәеҲ¶пјҢйҮҚиҜ•е°ұеҫ—дҝқиҜҒеҜ№еә”жңҚеҠЎзҡ„ж–№жі•жҳҜе№Ӯзӯүзҡ„пјҢиҖҢдё”дёҖиҲ¬йҮҚиҜ•д№ҹдјҡжңүжңҖеӨ§зҡ„ж¬Ўж•°пјҢи¶…иҝҮжңҖеӨ§ж¬Ўж•°зҡ„ж—¶еҖҷеҸҜд»Ҙдәәе·Ҙд»Ӣе…Ҙ
жң¬ең°ж¶ҲжҒҜиЎЁе®һзҺ°зҡ„жҳҜдёҡеҠЎзҡ„жңҖз»ҲдёҖиҮҙжҖ§пјҢйңҖиҰҒиғҪеӨҹе®№еҝҚж•°жҚ®жҡӮж—¶дёҚдёҖиҮҙзҡ„жғ…еҶө
ж¶ҲжҒҜдәӢеҠЎ
е…¶е®һж¶ҲжҒҜдәӢеҠЎпјҢжңҖе…ёеһӢзҡ„е°ұжҳҜеұһдәҺRocketMQдёӯзҡ„е®һзҺ°дәҶпјҢиҖҢдё”еә”з”Ёзҡ„еңәжҷҜд№ҹжҳҜжҜ”иҫғеӨҡзҡ„

RocketMQзҡ„жңәеҲ¶е°ұжҳҜе…Ҳз»ҷBrokerеҸ‘йҖҒдәӢеҠЎж¶ҲжҒҜпјҢд№ҹе°ұжҳҜеҚҠж¶ҲжҒҜпјҢеҚҠж¶ҲжҒҜжҢҮзҡ„жҳҜиҝҷдёӘж¶ҲжҒҜеҜ№ж¶Ҳиҙ№иҖ…жқҘиҜҙдёҚеҸҜи§ҒпјҢ然еҗҺеҸ‘йҖҒжҲҗеҠҹеҗҺпјҢеҸ‘йҖҒд№ӢеҗҺдјҡ继з»ӯжү§иЎҢжң¬ең°дәӢеҠЎ
第дәҢжӯҘе°ұжҳҜж №жҚ®жң¬ең°дәӢеҠЎзҡ„жү§иЎҢз»“жһңеҗ‘BrokerеҸ‘йҖҒCommitе’ҢRollbackе‘Ҫд»ӨпјҢеҰӮжһңдёҖзӣҙдёҚеҸ‘йҖҒпјҢRocketMQзҡ„еҸ‘йҖҒж–№дјҡжҸҗдҫӣдёҖдёӘеҸҚжҹҘдәӢеҠЎзҠ¶жҖҒзҡ„жҺҘеҸЈпјҢз”ЁжқҘеҸҚжҹҘзӣёеә”зҡ„дәӢеҠЎзҡ„з»“жһңеҲ°еә•жҳҜжҲҗеҠҹиҝҳжҳҜеӣһж»ҡ
е…¶е®һиҝҷд№ҹе°ұжҳҜдёӘи¶…ж—¶жңәеҲ¶пјҢеңЁдёҖж®өж—¶й—ҙеҶ…жІЎжңү收еҲ°д»»дҪ•зҡ„ж“ҚдҪңиҜ·жұӮпјҢйӮЈд№ҲBrokerе°ұдјҡйҖҡиҝҮзӣёеә”зҡ„з»“жһңжҹҘеҮәиҜҘдәӢеҠЎжҳҜеҗҰжҲҗеҠҹжү§иЎҢе‘ўпјҢжҳҜCommitиҝҳжҳҜRollback
еҰӮжһңжҳҜCommitпјҢеҲҷbrokerе°ұдјҡеҸ‘йҖҒиҝҷдёӘж¶ҲжҒҜеҲ°и®ўйҳ…ж–№пјҢ然еҗҺеҶҚеҒҡеҜ№еә”зҡ„ж“ҚдҪңпјҢеҒҡе®ҢдәҶд№ӢеҗҺе°ұеҸҜд»Ҙж¶Ҳиҙ№иҝҷдёӘж¶ҲжҒҜпјҢеҰӮжһңжҳҜRollbackеҲҷи®ўйҳ…ж–№еҚіж”¶дёҚеҲ°иҝҷдёӘж¶ҲжҒҜпјҢзӯүеҗҢдәҺдәӢеҠЎжІЎжңүжү§иЎҢиҝҮ
жңҖеӨ§еҠӘеҠӣйҖҡзҹҘ
е…¶е®һжңҖеӨ§еҠӘеҠӣйҖҡзҹҘжҲ‘дёӘдәәи®ӨдёәжҳҜдёҖз§ҚжҖқжғіпјҢеғҸдёҠйқўзҡ„жң¬ең°ж¶ҲжҒҜиЎЁгҖҒдәӢеҠЎж¶ҲжҒҜд№ҹжҳҜеұһдәҺжңҖеӨ§еҠӘеҠӣйҖҡзҹҘзұ»еһӢзҡ„
жң¬ең°ж¶ҲжҒҜиЎЁдјҡжңүеҗҺеҸ°д»»еҠЎе®ҡж—¶жҹҘзңӢжңӘе®ҢжҲҗзҡ„д»»еҠЎзҡ„ж¶ҲжҒҜпјҢ然еҗҺеҺ»и°ғз”ЁеҜ№еә”зҡ„жңҚеҠЎпјҢиҝӣиЎҢеӨҡж¬ЎйҮҚиҜ•пјҢеҪ“еӨҡж¬ЎеӨұиҙҘзҡ„ж—¶еҖҷе°ұйңҖиҰҒеј•е…Ҙдәәе·ҘпјҢиҝҷд№ҹжҳҜеұһдәҺжңҖеӨ§еҠӘеҠӣ
дәӢеҠЎж¶ҲжҒҜд№ҹжҳҜеұһдәҺзұ»дјјпјҢеҚҠж¶ҲжҒҜиў«Commitд№ӢеҗҺе°ұдјҡеҸ‘йҖҒеҲ°ж¶Ҳиҙ№з«ҜдәҶпјҢеҰӮжһңж¶Ҳиҙ№з«ҜдёҖзӣҙдёҚж¶Ҳиҙ№жҲ–иҖ…ж¶Ҳиҙ№дёҚдәҶеҲҷдјҡдёҖзӣҙйҮҚиҜ•пјҢеҰӮжһңйҮҚиҜ•ж¬Ўж•°иҫҫеҲ°дёҖе®ҡж•°йҮҸпјҢиҜҘж¶ҲжҒҜеҸҳеӣһиҝӣе…ҘеҲ°з§ҒдҝЎйҳҹеҲ—пјҢд№ҹжҳҜеұһдәҺе°ҪжңҖеӨ§еҠӘеҠӣйҖҡзҹҘеҗ§
иҝҷеә”иҜҘжҳҜеұһдәҺдёҖз§ҚжҖқжғіпјҢе°ҪжңҖеӨ§еҠӘеҠӣзҡ„иҫҫеҲ°дәӢеҠЎзҡ„жңҖз»ҲдёҖиҮҙпјҢйҖӮз”ЁдәҺеҜ№ж—¶й—ҙдёҚж•Ҹж„ҹзҡ„дёҡеҠЎеңәжҷҜ
вҖңеҲҶеёғејҸдәӢеҠЎзҡ„еҗ«д№үвҖқзҡ„еҶ…е®№е°ұд»Ӣз»ҚеҲ°иҝҷйҮҢдәҶпјҢж„ҹи°ўеӨ§е®¶зҡ„йҳ…иҜ»гҖӮеҰӮжһңжғідәҶи§ЈжӣҙеӨҡиЎҢдёҡзӣёе…ізҡ„зҹҘиҜҶеҸҜд»Ҙе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–е°ҶдёәеӨ§е®¶иҫ“еҮәжӣҙеӨҡй«ҳиҙЁйҮҸзҡ„е®һз”Ёж–Үз« пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ