жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жң¬зҜҮеҶ…е®№д»Ӣз»ҚдәҶвҖңLoki зҡ„дҪңз”ЁжҳҜд»Җд№ҲвҖқзҡ„жңүе…ізҹҘиҜҶпјҢеңЁе®һйҷ…жЎҲдҫӢзҡ„ж“ҚдҪңиҝҮзЁӢдёӯпјҢдёҚе°‘дәәйғҪдјҡйҒҮеҲ°иҝҷж ·зҡ„еӣ°еўғпјҢжҺҘдёӢжқҘе°ұи®©е°Ҹзј–еёҰйўҶеӨ§е®¶еӯҰд№ дёҖдёӢеҰӮдҪ•еӨ„зҗҶиҝҷдәӣжғ…еҶөеҗ§пјҒеёҢжңӣеӨ§е®¶д»”з»Ҷйҳ…иҜ»пјҢиғҪеӨҹеӯҰжңүжүҖжҲҗпјҒ
еүҚйқўжҲ‘们д»Ӣз»ҚдәҶ Loki зҡ„дёҖдәӣеҹәжң¬дҪҝз”Ёй…ҚзҪ®пјҢдҪҶжҳҜеҜ№ Loki иҝҳжҳҜдәҶи§ЈдёҚеӨҹж·ұе…ҘпјҢе®ҳж–№ж–ҮжЎЈеҶҷеҫ—иҫғдёәеҮҢд№ұпјҢиҖҢдё”жІЎжңүи·ҹдёҠж–°зүҲжң¬пјҢдёәдәҶиғҪеӨҹеҜ№ Loki жңүдёҖдёӘжӣҙж·ұе…Ҙзҡ„и®ӨиҜҶпјҢеҒҡеҲ°жңүзҡ„ж”ҫзҹўпјҢиҝҷйҮҢйқўжҲ‘们е°қиҜ•еҜ№ Loki зҡ„жәҗз ҒиҝӣиЎҢдёҖдәӣз®ҖеҚ•зҡ„еҲҶжһҗпјҢз”ұдәҺжңүеҫҲеӨҡжЁЎеқ—е’Ңе®һзҺ°з»ҶиҠӮпјҢиҝҷйҮҢжҲ‘们主иҰҒжҳҜеҜ№ж ёеҝғеҠҹиғҪиҝӣиЎҢеҲҶжһҗпјҢеёҢжңӣеҜ№еӨ§е®¶жңүжүҖеё®еҠ©гҖӮжң¬ж–ҮйҰ–е…ҲеҜ№ж—Ҙеҝ—зҡ„еҶҷе…ҘиҝҮзЁӢиҝӣиЎҢз®ҖеҚ•еҲҶжһҗгҖӮ
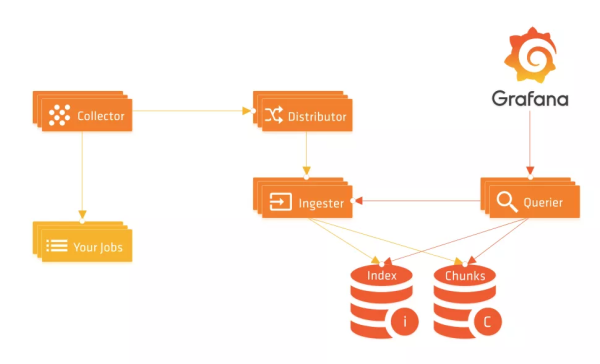
Promtail йҖҡиҝҮ Loki зҡ„ Push API жҺҘеҸЈжҺЁйҖҒж—Ҙеҝ—ж•°жҚ®пјҢиҜҘжҺҘеҸЈеңЁеҲқе§ӢеҢ– Distributor зҡ„ж—¶еҖҷиҝӣиЎҢеҲқе§ӢеҢ–пјҢеңЁжҺ§еҲ¶еҷЁеҹәзЎҖдёҠеҢ…иЈ…дәҶдёӨдёӘдёӯй—ҙ件пјҢе…¶дёӯзҡ„ HTTPAuthMiddleware е°ұжҳҜиҺ·еҸ–з§ҹжҲ· IDпјҢеҰӮжһңејҖеҗҜдәҶи®ӨиҜҒй…ҚзҪ®пјҢеҲҷд»Һ X-Scope-OrgID иҝҷдёӘиҜ·жұӮ Header еӨҙйҮҢйқўиҺ·еҸ–пјҢеҰӮжһңжІЎжңүй…ҚзҪ®еҲҷз”Ёй»ҳи®Өзҡ„ fake д»ЈжӣҝгҖӮ
// pkg/loki/modules.go func (t *Loki) initDistributor() (services.Service, error) { ...... if t.cfg.Target != All { logproto.RegisterPusherServer(t.Server.GRPC, t.distributor) } pushHandler := middleware.Merge( serverutil.RecoveryHTTPMiddleware, t.HTTPAuthMiddleware, ).Wrap(http.HandlerFunc(t.distributor.PushHandler)) t.Server.HTTP.Handle("/api/prom/push", pushHandler) t.Server.HTTP.Handle("/loki/api/v1/push", pushHandler) return t.distributor, nil }Push API еӨ„зҗҶеҷЁе®һзҺ°еҰӮдёӢжүҖзӨәпјҢйҰ–е…ҲйҖҡиҝҮ ParseRequest еҮҪж•°е°Ҷ Http иҜ·жұӮиҪ¬жҚўжҲҗ logproto.PushRequestпјҢ然еҗҺзӣҙжҺҘи°ғз”Ё Distributor дёӢйқўзҡ„ Push еҮҪж•°жқҘжҺЁйҖҒж—Ҙеҝ—ж•°жҚ®пјҡ
// pkg/distributor/http.go // PushHandler д»Һ HTTP body дёӯиҜ»еҸ–дёҖдёӘ snappy еҺӢзј©зҡ„ proto func (d *Distributor) PushHandler(w http.ResponseWriter, r *http.Request) { logger := util_log.WithContext(r.Context(), util_log.Logger) userID, _ := user.ExtractOrgID(r.Context()) req, err := ParseRequest(logger, userID, r) ...... _, err = d.Push(r.Context(), req) ...... } func ParseRequest(logger gokit.Logger, userID string, r *http.Request) (*logproto.PushRequest, error) { var body lokiutil.SizeReader contentEncoding := r.Header.Get(contentEnc) switch contentEncoding { case "": body = lokiutil.NewSizeReader(r.Body) case "snappy": body = lokiutil.NewSizeReader(r.Body) case "gzip": gzipReader, err := gzip.NewReader(r.Body) if err != nil { return nil, err } defer gzipReader.Close() body = lokiutil.NewSizeReader(gzipReader) default: return nil, fmt.Errorf("Content-Encoding %q not supported", contentEncoding) } contentType := r.Header.Get(contentType) var req logproto.PushRequest ...... switch contentType { case applicationJSON: var err error if loghttp.GetVersion(r.RequestURI) == loghttp.VersionV1 { err = unmarshal.DecodePushRequest(body, &req) } else { err = unmarshal_legacy.DecodePushRequest(body, &req) } if err != nil { return nil, err } default: // When no content-type header is set or when it is set to // `application/x-protobuf`: expect snappy compression. if err := util.ParseProtoReader(r.Context(), body, int(r.ContentLength), math.MaxInt32, &req, util.RawSnappy); err != nil { return nil, err } } return &req, nil }йҰ–е…ҲжҲ‘们е…ҲдәҶи§ЈдёӢ PushRequest зҡ„з»“жһ„пјҢPushRequest е°ұжҳҜдёҖдёӘ Stream йӣҶеҗҲпјҡ
// pkg/logproto/logproto.pb.go type PushRequest struct { Streams []Stream `protobuf:"bytes,1,rep,name=streams,proto3,customtype=Stream" json:"streams"` } // pkg/logproto/types.go // Stream жөҒеҢ…еҗ«дёҖдёӘе”ҜдёҖзҡ„ж ҮзӯҫйӣҶпјҢдҪңдёәдёҖдёӘеӯ—з¬ҰдёІпјҢ然еҗҺиҝҳеҢ…еҗ«дёҖз»„ж—Ҙеҝ—жқЎзӣ® type Stream struct { Labels string `protobuf:"bytes,1,opt,name=labels,proto3" json:"labels"` Entries []Entry `protobuf:"bytes,2,rep,name=entries,proto3,customtype=EntryAdapter" json:"entries"` } // Entry жҳҜдёҖдёӘеёҰжңүж—¶й—ҙжҲізҡ„ж—Ҙеҝ—жқЎзӣ® type Entry struct { Timestamp time.Time `protobuf:"bytes,1,opt,name=timestamp,proto3,stdtime" json:"ts"` Line string `protobuf:"bytes,2,opt,name=line,proto3" json:"line"` } 

然еҗҺжҹҘзңӢ Distributor дёӢзҡ„ Push еҮҪж•°е®һзҺ°пјҡ
// pkg/distributor/distributor.go // Push ж—Ҙеҝ—жөҒйӣҶеҗҲ func (d *Distributor) Push(ctx context.Context, req *logproto.PushRequest) (*logproto.PushResponse, error) { // иҺ·еҸ–з§ҹжҲ·ID userID, err := user.ExtractOrgID(ctx) ...... // йҰ–е…ҲжҠҠиҜ·жұӮе№ій“әжҲҗдёҖдёӘж ·жң¬зҡ„еҲ—иЎЁ streams := make([]streamTracker, 0, len(req.Streams)) keys := make([]uint32, 0, len(req.Streams)) var validationErr error validatedSamplesSize := 0 validatedSamplesCount := 0 validationContext := d.validator.getValidationContextFor(userID) for _, stream := range req.Streams { // и§Јжһҗж—Ҙеҝ—жөҒж Үзӯҫ stream.Labels, err = d.parseStreamLabels(validationContext, stream.Labels, &stream) ...... n := 0 for _, entry := range stream.Entries { // ж ЎйӘҢдёҖдёӘж—Ҙеҝ—Entryе®һдҪ“ if err := d.validator.ValidateEntry(validationContext, stream.Labels, entry); err != nil { validationErr = err continue } stream.Entries[n] = entry n++ // ж ЎйӘҢжҲҗеҠҹзҡ„ж ·жң¬еӨ§е°Ҹе’ҢдёӘж•° validatedSamplesSize += len(entry.Line) validatedSamplesCount++ } // еҺ»жҺүж ЎйӘҢеӨұиҙҘзҡ„е®һдҪ“ stream.Entries = stream.Entries[:n] if len(stream.Entries) == 0 { continue } // дёәеҪ“еүҚж—Ҙеҝ—жөҒз”ҹжҲҗз”ЁдәҺhashжҚўзҡ„tokenеҖј keys = append(keys, util.TokenFor(userID, stream.Labels)) streams = append(streams, streamTracker{ stream: stream, }) } if len(streams) == 0 { return &logproto.PushResponse{}, validationErr } now := time.Now() // жҜҸдёӘз§ҹжҲ·жңүдёҖдёӘйҷҗйҖҹеҷЁпјҢеҲӨж–ӯеҸҜд»ҘжӯЈеёёдј иҫ“зҡ„ж—Ҙеҝ—еӨ§е°ҸжҳҜеҗҰеә”иҜҘиў«йҷҗеҲ¶ if !d.ingestionRateLimiter.AllowN(now, userID, validatedSamplesSize) { // иҝ”еӣһ429иЎЁжҳҺе®ўжҲ·з«Ҝиў«йҷҗйҖҹдәҶ ...... return nil, httpgrpc.Errorf(http.StatusTooManyRequests, validation.RateLimitedErrorMsg, int(d.ingestionRateLimiter.Limit(now, userID)), validatedSamplesCount, validatedSamplesSize) } const maxExpectedReplicationSet = 5 // typical replication factor 3 plus one for inactive plus one for luck var descs [maxExpectedReplicationSet]ring.InstanceDesc samplesByIngester := map[string][]*streamTracker{} ingesterDescs := map[string]ring.InstanceDesc{} for i, key := range keys { // ReplicationSet жҸҸиҝ°дәҶдёҖдёӘжҢҮе®ҡзҡ„й”®дёҺе“Әдәӣ Ingesters иҝӣиЎҢеҜ№иҜқпјҢд»ҘеҸҠеҸҜд»Ҙе®№еҝҚеӨҡе°‘дёӘй”ҷиҜҜ // ж №жҚ® label hash еҲ° hash зҺҜдёҠиҺ·еҸ–еҜ№еә”зҡ„ ingester иҠӮзӮ№пјҢдёҖдёӘиҠӮзӮ№еҸҜиғҪжңүеӨҡдёӘеҜ№зӯүзҡ„ ingester еүҜжң¬жқҘеҒҡ HA replicationSet, err := d.ingestersRing.Get(key, ring.Write, descs[:0], nil, nil) ...... // жңҖе°ҸжҲҗеҠҹзҡ„е®һдҫӢж ‘ streams[i].minSuccess = len(replicationSet.Ingesters) - replicationSet.MaxErrors // еҸҜе®№еҝҚзҡ„жңҖеӨ§ж•…йҡңе®һдҫӢж•° streams[i].maxFailures = replicationSet.MaxErrors // е°Ҷ Stream жҢүеҜ№еә”зҡ„ ingester иҝӣиЎҢеҲҶз»„ for _, ingester := range replicationSet.Ingesters { // й…ҚзҪ®жҜҸдёӘ ingester еүҜжң¬еҜ№еә”зҡ„ж—Ҙеҝ—жөҒж•°жҚ® samplesByIngester[ingester.Addr] = append(samplesByIngester[ingester.Addr], &streams[i]) ingesterDescs[ingester.Addr] = ingester } } tracker := pushTracker{ done: make(chan struct{}), err: make(chan error), } tracker.samplesPending.Store(int32(len(streams))) // еҫӘзҺҜIngesters for ingester, samples := range samplesByIngester { // и®©ingester并иЎҢеӨ„зҗҶйҖҡиҝҮhashзҺҜеҜ№еә”зҡ„ж—Ҙеҝ—жөҒеҲ—иЎЁ go func(ingester ring.InstanceDesc, samples []*streamTracker) { ...... // е°Ҷж—Ҙеҝ—жөҒж ·жң¬ж•°жҚ®дёӢеҸ‘з»ҷеҜ№еә”зҡ„ ingester иҠӮзӮ№ d.sendSamples(localCtx, ingester, samples, &tracker) }(ingesterDescs[ingester], samples) } ...... }Push еҮҪж•°зҡ„ж ёеҝғе°ұжҳҜж №жҚ®ж—Ҙеҝ—жөҒзҡ„ж ҮзӯҫжқҘи®Ўз®—дёҖдёӘ Token еҖјпјҢж №жҚ®иҝҷдёӘ Token еҖјеҺ»е“ҲеёҢзҺҜдёҠиҺ·еҸ–еҜ№еә”зҡ„еӨ„зҗҶж—Ҙеҝ—зҡ„ Ingester е®һдҫӢпјҢ然еҗҺ并иЎҢйҖҡиҝҮ Ingester еӨ„зҗҶж—Ҙеҝ—жөҒж•°жҚ®пјҢйҖҡиҝҮ sendSamples еҮҪж•°дёәеҚ•дёӘ ingester еҺ»еҸ‘йҖҒж—Ҙеҝ—ж ·жң¬ж•°жҚ®пјҡ
// pkg/distributor/distributor.go func (d *Distributor) sendSamples(ctx context.Context, ingester ring.InstanceDesc, streamTrackers []*streamTracker, pushTracker *pushTracker) { err := d.sendSamplesErr(ctx, ingester, streamTrackers) ...... } func (d *Distributor) sendSamplesErr(ctx context.Context, ingester ring.InstanceDesc, streams []*streamTracker) error { // ж №жҚ® ingester ең°еқҖиҺ·еҸ– client c, err := d.pool.GetClientFor(ingester.Addr) ...... // йҮҚж–°жһ„йҖ PushRequest req := &logproto.PushRequest{ Streams: make([]logproto.Stream, len(streams)), } for i, s := range streams { req.Streams[i] = s.stream } // йҖҡиҝҮ Ingester е®ўжҲ·з«ҜиҜ·жұӮж•°жҚ® _, err = c.(logproto.PusherClient).Push(ctx, req) ...... }Ingester е®ўжҲ·з«Ҝдёӯзҡ„ Push еҮҪж•°е®һйҷ…дёҠе°ұжҳҜдёҖдёӘ gRPC жңҚеҠЎзҡ„е®ўжҲ·з«Ҝпјҡ
// pkg/ingester/ingester.go // Push е®һзҺ° logproto.Pusher. func (i *Ingester) Push(ctx context.Context, req *logproto.PushRequest) (*logproto.PushResponse, error) { // иҺ·еҸ–з§ҹжҲ·ID instanceID, err := user.ExtractOrgID(ctx) ...... // ж №жҚ®з§ҹжҲ·IDиҺ·еҸ– instance еҜ№иұЎ instance := i.getOrCreateInstance(instanceID) // зӣҙжҺҘи°ғз”Ё instance еҜ№иұЎ Push ж•°жҚ® err = instance.Push(ctx, req) return &logproto.PushResponse{}, err }instance дёӢзҡ„ Push еҮҪж•°пјҡ
// pkg/ingester/instance.go func (i *instance) Push(ctx context.Context, req *logproto.PushRequest) error { record := recordPool.GetRecord() record.UserID = i.instanceID defer recordPool.PutRecord(record) i.streamsMtx.Lock() defer i.streamsMtx.Unlock() var appendErr error for _, s := range req.Streams { // иҺ·еҸ–дёҖдёӘ stream еҜ№иұЎ stream, err := i.getOrCreateStream(s, false, record) if err != nil { appendErr = err continue } // зңҹжӯЈз”ЁдәҺж•°жҚ®еӨ„зҗҶзҡ„жҳҜ stream еҜ№иұЎдёӯзҡ„ Push еҮҪж•° if _, err := stream.Push(ctx, s.Entries, record); err != nil { appendErr = err continue } } ...... return appendErr } func (i *instance) getOrCreateStream(pushReqStream logproto.Stream, lock bool, record *WALRecord) (*stream, error) { if lock { i.streamsMtx.Lock() defer i.streamsMtx.Unlock() } // еҰӮжһң streams дёӯеҢ…еҗ«еҪ“еүҚж ҮзӯҫеҲ—иЎЁеҜ№еә”зҡ„ stream еҜ№иұЎпјҢеҲҷзӣҙжҺҘиҝ”еӣһ stream, ok := i.streams[pushReqStream.Labels] if ok { return stream, nil } // record еҸӘеңЁйҮҚж”ҫ WAL ж—¶дёә nil // жҲ‘们дёҚеёҢжңӣеңЁйҮҚж”ҫ WAL еҗҺдёўжҺүж•°жҚ® // дёә instance йҷҚдҪҺ stream жөҒйҷҗеҲ¶ var err error if record != nil { // йҷҗжөҒеҷЁеҲӨж–ӯ // AssertMaxStreamsPerUser зЎ®дҝқдёҺеҪ“еүҚиҫ“е…Ҙзҡ„жөҒж•°йҮҸжІЎжңүиҫҫеҲ°йҷҗеҲ¶ err = i.limiter.AssertMaxStreamsPerUser(i.instanceID, len(i.streams)) } ...... // и§Јжһҗж—Ҙеҝ—жөҒж ҮзӯҫйӣҶ labels, err := logql.ParseLabels(pushReqStream.Labels) ...... // иҺ·еҸ–еҜ№еә”ж ҮзӯҫйӣҶзҡ„жҢҮзә№ fp := i.getHashForLabels(labels) // йҮҚж–°е®һдҫӢеҢ–дёҖдёӘ stream еҜ№иұЎпјҢиҝҷйҮҢиҝҳдјҡз»ҙжҠӨж—Ҙеҝ—жөҒзҡ„еҖ’жҺ’зҙўеј• sortedLabels := i.index.Add(client.FromLabelsToLabelAdapters(labels), fp) stream = newStream(i.cfg, fp, sortedLabels, i.metrics) // е°Ҷstreamи®ҫзҪ®еҲ°streamsдёӯеҺ» i.streams[pushReqStream.Labels] = stream i.streamsByFP[fp] = stream // еҪ“йҮҚж”ҫ wal зҡ„ж—¶еҖҷ record жҳҜ nil (жҲ‘们дёҚеёҢжңӣеңЁйҮҚж”ҫж—¶йҮҚеҶҷ wal entries). if record != nil { record.Series = append(record.Series, tsdb_record.RefSeries{ Ref: uint64(fp), Labels: sortedLabels, }) } else { // еҰӮжһң record дёә nilпјҢиҝҷе°ұжҳҜдёҖдёӘ WAL жҒўеӨҚ i.metrics.recoveredStreamsTotal.Inc() } ...... i.addTailersToNewStream(stream) return stream, nil }иҝҷдёӘйҮҢйқўж¶үеҸҠеҲ° WAL иҝҷдёҖеқ—зҡ„и®ҫи®ЎпјҢжҜ”иҫғеӨҚжқӮпјҢжҲ‘们еҸҜд»Ҙе…ҲзңӢ stream дёӢйқўзҡ„ Push еҮҪж•°е®һзҺ°пјҢдё»иҰҒе°ұжҳҜе°Ҷ收еҲ°зҡ„ []Entry е…Ҳ Append еҲ°еҶ…еӯҳдёӯзҡ„ Chunk жөҒ([]chunkDesc) дёӯпјҡ
// pkg/ingester/stream.go func (s *stream) Push(ctx context.Context, entries []logproto.Entry, record *WALRecord) (int, error) { s.chunkMtx.Lock() defer s.chunkMtx.Unlock() var bytesAdded int prevNumChunks := len(s.chunks) var lastChunkTimestamp time.Time // еҰӮжһңд№ӢеүҚзҡ„ chunks еҲ—иЎЁдёәз©әпјҢеҲҷеҲӣе»әдёҖдёӘж–°зҡ„ chunk if prevNumChunks == 0 { s.chunks = append(s.chunks, chunkDesc{ chunk: s.NewChunk(), }) chunksCreatedTotal.Inc() } else { // иҺ·еҸ–жңҖж–°дёҖдёӘchunkзҡ„ж—Ҙеҝ—ж—¶й—ҙжҲі _, lastChunkTimestamp = s.chunks[len(s.chunks)-1].chunk.Bounds() } var storedEntries []logproto.Entry failedEntriesWithError := []entryWithError{} for i := range entries { // еҰӮжһңиҝҷдёӘж—Ҙеҝ—жқЎзӣ®дёҺжҲ‘们жңҖеҗҺ append зҡ„дёҖиЎҢзҡ„ж—¶й—ҙжҲіе’ҢеҶ…е®№зӣёеҢ№й…ҚпјҢеҲҷеҝҪз•Ҙе®ғ if entries[i].Timestamp.Equal(s.lastLine.ts) && entries[i].Line == s.lastLine.content { continue } // жңҖж–°зҡ„дёҖдёӘ chunk chunk := &s.chunks[len(s.chunks)-1] // еҰӮжһңеҪ“еүҚchunkе·Із»Ҹе…ій—ӯ жҲ–иҖ… е·Із»ҸиҫҫеҲ°и®ҫзҪ®зҡ„жңҖеӨ§ Chunk еӨ§е°Ҹ if chunk.closed || !chunk.chunk.SpaceFor(&entries[i]) || s.cutChunkForSynchronization(entries[i].Timestamp, lastChunkTimestamp, chunk, s.cfg.SyncPeriod, s.cfg.SyncMinUtilization) { // еҰӮжһң chunk жІЎжңүжӣҙеӨҡзҡ„з©әй—ҙпјҢеҲҷи°ғз”Ё Close жқҘд»ҘзЎ®дҝқ head block дёӯзҡ„ж•°жҚ®йғҪиў«еҲҮеүІе’ҢеҺӢзј©гҖӮ err := chunk.chunk.Close() ...... chunk.closed = true ...... // Append дёҖдёӘж–°зҡ„ Chunk s.chunks = append(s.chunks, chunkDesc{ chunk: s.NewChunk(), }) chunk = &s.chunks[len(s.chunks)-1] lastChunkTimestamp = time.Time{} } // еҫҖ chunk йҮҢйқў Append ж—Ҙеҝ—ж•°жҚ® if err := chunk.chunk.Append(&entries[i]); err != nil { failedEntriesWithError = append(failedEntriesWithError, entryWithError{&entries[i], err}) } else { // еӯҳеӮЁж·»еҠ еҲ° chunk дёӯзҡ„ж—Ҙеҝ—ж•°жҚ® storedEntries = append(storedEntries, entries[i]) // й…ҚзҪ®жңҖеҗҺж—Ҙеҝ—иЎҢзҡ„ж•°жҚ® lastChunkTimestamp = entries[i].Timestamp s.lastLine.ts = lastChunkTimestamp s.lastLine.content = entries[i].Line // зҙҜи®ЎеӨ§е°Ҹ bytesAdded += len(entries[i].Line) } chunk.lastUpdated = time.Now() } if len(storedEntries) != 0 { // еҪ“йҮҚж”ҫ wal зҡ„ж—¶еҖҷ record е°Ҷдёә nilпјҲжҲ‘们дёҚеёҢжңӣеңЁйҮҚж”ҫзҡ„ж—¶еҖҷйҮҚеҶҷwalж—Ҙеҝ—жқЎзӣ®пјү if record != nil { record.AddEntries(uint64(s.fp), storedEntries...) } // еҗҺз»ӯжҳҜз”ЁдёҺtailж—Ҙеҝ—зҡ„еӨ„зҗҶ ...... } ...... // еҰӮжһңж–°еўһдәҶchunks if len(s.chunks) != prevNumChunks { memoryChunks.Add(float64(len(s.chunks) - prevNumChunks)) } return bytesAdded, nil }Chunk е…¶е®һе°ұжҳҜеӨҡжқЎж—Ҙеҝ—жһ„жҲҗзҡ„еҺӢзј©еҢ…пјҢе°Ҷж—Ҙеҝ—еҺӢжҲҗ Chunk зҡ„еҸҜд»ҘзӣҙжҺҘеӯҳе…ҘеҜ№иұЎеӯҳеӮЁпјҢ дёҖдёӘ Chunk еҲ°иҫҫжҢҮе®ҡеӨ§е°Ҹд№ӢеүҚдјҡдёҚж–ӯ Append ж–°зҡ„ж—Ҙеҝ—еҲ°йҮҢйқўпјҢиҖҢеңЁиҫҫеҲ°еӨ§е°Ҹд№ӢеҗҺ, Chunk е°ұдјҡе…ій—ӯзӯүеҫ…жҢҒд№…еҢ–(ејәеҲ¶жҢҒд№…еҢ–д№ҹдјҡе…ій—ӯ Chunk, жҜ”еҰӮе…ій—ӯ ingester е®һдҫӢж—¶е°ұдјҡе…ій—ӯжүҖжңүзҡ„ Chunk 并жҢҒд№…еҢ–)гҖӮChunk зҡ„еӨ§е°ҸжҺ§еҲ¶еҫҲйҮҚиҰҒпјҡ
еҒҮеҰӮ Chunk е®№йҮҸиҝҮе°Ҹ: йҰ–е…ҲжҳҜеҜјиҮҙеҺӢзј©ж•ҲзҺҮдёҚй«ҳпјҢеҗҢж—¶д№ҹдјҡеўһеҠ ж•ҙдҪ“зҡ„ Chunk ж•°йҮҸ, еҜјиҮҙеҖ’жҺ’зҙўеј•иҝҮеӨ§пјҢжңҖеҗҺ, еҜ№иұЎеӯҳеӮЁзҡ„ж“ҚдҪңж¬Ўж•°д№ҹдјҡеҸҳеӨҡ, еёҰжқҘйўқеӨ–зҡ„жҖ§иғҪејҖй”Җ
еҒҮеҰӮ Chunk иҝҮеӨ§: дёҖдёӘ Chunk зҡ„ open ж—¶й—ҙдјҡжӣҙй•ҝ, еҚ з”ЁйўқеӨ–зҡ„еҶ…еӯҳз©әй—ҙ, еҗҢж—¶, д№ҹеўһеҠ дәҶдёўж•°жҚ®зҡ„йЈҺйҷ©пјҢChunk иҝҮеӨ§д№ҹдјҡеҜјиҮҙжҹҘиҜўиҜ»ж”ҫеӨ§
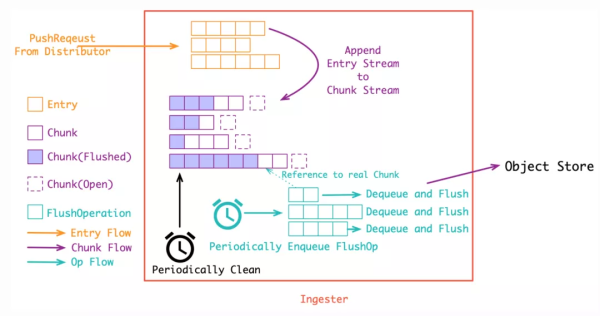
еңЁе°Ҷж—Ҙеҝ—жөҒиҝҪеҠ еҲ° Chunk дёӯиҝҮеҗҺпјҢеңЁ Ingester еҲқе§ӢеҢ–ж—¶дјҡеҗҜеҠЁдёӨдёӘеҫӘзҺҜеҺ»еӨ„зҗҶ Chunk ж•°жҚ®пјҢеҲҶеҲ«д»Һ chunks ж•°жҚ®еҸ–еҮәеӯҳе…Ҙдјҳе…Ҳзә§йҳҹеҲ—пјҢеҸҰеӨ–дёҖдёӘеҫӘзҺҜе®ҡжңҹжЈҖжҹҘд»ҺеҶ…еӯҳдёӯеҲ йҷӨе·Із»ҸжҢҒд№…еҢ–иҝҮеҗҺзҡ„ж•°жҚ®гҖӮ
йҰ–е…ҲжҳҜ Ingester дёӯе®ҡд№үдәҶдёҖдёӘ flushQueues еұһжҖ§пјҢжҳҜдёҖдёӘдјҳе…Ҳзә§йҳҹеҲ—ж•°з»„пјҢиҜҘйҳҹеҲ—дёӯеӯҳж”ҫзҡ„жҳҜ flushOpпјҡ
// pkg/ingester/ingester.go type Ingester struct { services.Service ...... // жҜҸдёӘ flush зәҝзЁӢдёҖдёӘйҳҹеҲ—пјҢжҢҮзә№з”ЁжқҘйҖүжӢ©йҳҹеҲ— flushQueues []*util.PriorityQueue // дјҳе…Ҳзә§йҳҹеҲ—ж•°з»„ flushQueuesDone sync.WaitGroup ...... } // pkg/ingester/flush.go // дјҳе…Ҳзә§йҳҹеҲ—дёӯеӯҳж”ҫзҡ„ж•°жҚ® type flushOp struct { from model.Time userID string fp model.Fingerprint immediate bool }еңЁеҲқе§ӢеҢ– Ingester зҡ„ж—¶еҖҷдјҡж №жҚ®дј йҖ’зҡ„ ConcurrentFlushes еҸӮж•°жқҘе®һдҫӢеҢ– flushQueuesзҡ„еӨ§е°Ҹпјҡ
// pkg/ingester/ingester.go func New(cfg Config, clientConfig client.Config, store ChunkStore, limits *validation.Overrides, configs *runtime.TenantConfigs, registerer prometheus.Registerer) (*Ingester, error) { ...... i := &Ingester{ ...... flushQueues: make([]*util.PriorityQueue, cfg.ConcurrentFlushes), ...... } ...... i.Service = services.NewBasicService(i.starting, i.running, i.stopping) return i, nil }然еҗҺйҖҡиҝҮ services.NewBasicService е®һдҫӢеҢ– Service зҡ„ж—¶еҖҷжҢҮе®ҡдәҶжңҚеҠЎзҡ„ StartingгҖҒRunningгҖҒStopping 3 дёӘзҠ¶жҖҒпјҢеңЁе…¶дёӯзҡ„ staring зҠ¶жҖҒеҮҪж•°дёӯдјҡеҗҜеҠЁеҚҸзЁӢеҺ»ж¶Ҳиҙ№дјҳе…Ҳзә§йҳҹеҲ—дёӯзҡ„ж•°жҚ®
// pkg/ingester/ingester.go func (i *Ingester) starting(ctx context.Context) error { // todoпјҢеҰӮжһңејҖеҗҜдәҶ WAL зҡ„еӨ„зҗҶ ...... // еҲқе§ӢеҢ– flushQueues i.InitFlushQueues() ...... // еҗҜеҠЁеҫӘзҺҜжЈҖжҹҘchunkж•°жҚ® i.loopDone.Add(1) go i.loop() return nil }еҲқе§ӢеҢ– flushQueues е®һзҺ°еҰӮдёӢжүҖзӨәпјҢе…¶дёӯ flushQueuesDone жҳҜдёҖдёӘ WaitGroupпјҢж №жҚ®й…ҚзҪ®зҡ„并еҸ‘ж•°йҮҸ并еҸ‘жү§иЎҢ flushLoop ж“ҚдҪңпјҡ
// pkg/ingester/flush.go func (i *Ingester) InitFlushQueues() { i.flushQueuesDone.Add(i.cfg.ConcurrentFlushes) for j := 0; j < i.cfg.ConcurrentFlushes; j++ { // дёәжҜҸдёӘеҚҸзЁӢжһ„йҖ дёҖдёӘдјҳе…Ҳзә§йҳҹеҲ— i.flushQueues[j] = util.NewPriorityQueue(flushQueueLength) go i.flushLoop(j) } }жҜҸдёҖдёӘдјҳе…Ҳзә§йҳҹеҲ—еҫӘзҺҜж¶Ҳиҙ№ж•°жҚ®пјҡ
// pkg/ingester/flush.go func (i *Ingester) flushLoop(j int) { ...... for { // д»ҺйҳҹеҲ—дёӯж №жҚ®дјҳе…Ҳзә§еҸ–еҮәж•°жҚ® o := i.flushQueues[j].Dequeue() if o == nil { return } op := o.(*flushOp) // жү§иЎҢзңҹжӯЈзҡ„еҲ·ж–°з”ЁжҲ·еәҸеҲ—ж•°жҚ® err := i.flushUserSeries(op.userID, op.fp, op.immediate) ...... // еҰӮжһңйҖҖеҮәж—¶еҲ·ж–°еӨұиҙҘдәҶпјҢжҠҠеӨұиҙҘзҡ„ж“ҚдҪңж”ҫеӣһеҲ°йҳҹеҲ—дёӯеҺ»гҖӮ if op.immediate && err != nil { op.from = op.from.Add(flushBackoff) i.flushQueues[j].Enqueue(op) } } }еҲ·ж–°з”ЁжҲ·зҡ„еәҸеҲ—ж“ҚдҪңпјҢд№ҹе°ұжҳҜиҰҒдҝқеӯҳеҲ°еӯҳеӮЁдёӯеҺ»пјҡ
// pkg/ingester/flush.go // ж №жҚ®з”ЁжҲ·IDеҲ·ж–°з”ЁжҲ·ж—Ҙеҝ—еәҸеҲ— func (i *Ingester) flushUserSeries(userID string, fp model.Fingerprint, immediate bool) error { instance, ok := i.getInstanceByID(userID) ...... // ж №жҚ®instanceе’ҢfpжҢҮзә№ж•°жҚ®иҺ·еҸ–йңҖиҰҒеҲ·ж–°зҡ„chunks chunks, labels, chunkMtx := i.collectChunksToFlush(instance, fp, immediate) ...... // жү§иЎҢзңҹжӯЈзҡ„еҲ·ж–° chunks ж“ҚдҪң err := i.flushChunks(ctx, fp, labels, chunks, chunkMtx) ...... } // 收йӣҶйңҖиҰҒеҲ·ж–°зҡ„ chunks func (i *Ingester) collectChunksToFlush(instance *instance, fp model.Fingerprint, immediate bool) ([]*chunkDesc, labels.Labels, *sync.RWMutex) { instance.streamsMtx.Lock() // ж №жҚ®жҢҮзә№ж•°жҚ®иҺ·еҸ– stream stream, ok := instance.streamsByFP[fp] instance.streamsMtx.Unlock() if !ok { return nil, nil, nil } var result []*chunkDesc stream.chunkMtx.Lock() defer stream.chunkMtx.Unlock() // еҫӘзҺҜжүҖжңүchunks for j := range stream.chunks { // еҲӨж–ӯжҳҜеҗҰеә”иҜҘеҲ·ж–°еҪ“еүҚchunk shouldFlush, reason := i.shouldFlushChunk(&stream.chunks[j]) if immediate || shouldFlush { // зЎ®дҝқдёҚеҶҚеҜ№иҜҘеқ—иҝӣиЎҢеҶҷж“ҚдҪңпјҲеҰӮжһңжІЎжңүе…ій—ӯпјҢеҲҷи®ҫзҪ®дёәе…ій—ӯзҠ¶жҖҒпјү if !stream.chunks[j].closed { stream.chunks[j].closed = true } // еҰӮжһңиҜҘ chunk иҝҳжІЎжңүиў«жҲҗеҠҹеҲ·ж–°пјҢеҲҷеҲ·ж–°иҝҷдёӘеқ— if stream.chunks[j].flushed.IsZero() { result = append(result, &stream.chunks[j]) ...... } } } return result, stream.labels, &stream.chunkMtx }дёӢйқўжҳҜеҲӨж–ӯдёҖдёӘе…·дҪ“зҡ„ chunk жҳҜеҗҰеә”иҜҘиў«еҲ·ж–°зҡ„йҖ»иҫ‘пјҡ
// pkg/ingester/flush.go func (i *Ingester) shouldFlushChunk(chunk *chunkDesc) (bool, string) { // chunkе…ій—ӯдәҶд№ҹеә”иҜҘеҲ·ж–°дәҶ if chunk.closed { if chunk.synced { return true, flushReasonSynced } return true, flushReasonFull } // chunkжңҖеҗҺжӣҙж–°зҡ„ж—¶й—ҙи¶…иҝҮдәҶй…ҚзҪ®зҡ„ chunk з©әй—Іж—¶й—ҙ MaxChunkIdle if time.Since(chunk.lastUpdated) > i.cfg.MaxChunkIdle { return true, flushReasonIdle } // chunkзҡ„иҫ№з•Ңж—¶й—ҙж“ҚиҝҮдәҶй…ҚзҪ®зҡ„ chunk жңҖеӨ§ж—¶й—ҙ MaxChunkAge if from, to := chunk.chunk.Bounds(); to.Sub(from) > i.cfg.MaxChunkAge { return true, flushReasonMaxAge } return false, "" }зңҹжӯЈе°Ҷ chunks ж•°жҚ®еҲ·ж–°дҝқеӯҳеҲ°еӯҳеӮЁдёӯжҳҜ flushChunks еҮҪж•°е®һзҺ°зҡ„пјҡ
// pkg/ingester/flush.go func (i *Ingester) flushChunks(ctx context.Context, fp model.Fingerprint, labelPairs labels.Labels, cs []*chunkDesc, chunkMtx sync.Locker) error { ...... wireChunks := make([]chunk.Chunk, len(cs)) // дёӢйқўзҡ„еҢҝеҗҚеҮҪж•°з”ЁдәҺз”ҹжҲҗдҝқеӯҳеҲ°еӯҳеӮЁдёӯзҡ„chunkж•°жҚ® err = func() error { chunkMtx.Lock() defer chunkMtx.Unlock() for j, c := range cs { if err := c.chunk.Close(); err != nil { return err } firstTime, lastTime := loki_util.RoundToMilliseconds(c.chunk.Bounds()) ch := chunk.NewChunk( userID, fp, metric, chunkenc.NewFacade(c.chunk, i.cfg.BlockSize, i.cfg.TargetChunkSize), firstTime, lastTime, ) chunkSize := c.chunk.BytesSize() + 4*1024 // size + 4kB should be enough room for cortex header start := time.Now() if err := ch.EncodeTo(bytes.NewBuffer(make([]byte, 0, chunkSize))); err != nil { return err } wireChunks[j] = ch } return nil }() // йҖҡиҝҮ store жҺҘеҸЈдҝқеӯҳ chunk ж•°жҚ® if err := i.store.Put(ctx, wireChunks); err != nil { return err } ...... chunkMtx.Lock() defer chunkMtx.Unlock() for i, wc := range wireChunks { // flush жҲҗеҠҹпјҢеҶҷе…ҘеҲ·ж–°ж—¶й—ҙ cs[i].flushed = time.Now() // дёӢжҳҜдёҖдәӣзӣ‘жҺ§ж•°жҚ®жӣҙж–° ...... } return nil }chunk ж•°жҚ®иў«еҶҷе…ҘеҲ°еӯҳеӮЁеҗҺпјҢиҝҳжңүжңүдёҖдёӘеҚҸзЁӢдјҡеҺ»е®ҡж—¶жё…зҗҶжң¬ең°зҡ„иҝҷдәӣ chunk ж•°жҚ®пјҢеңЁдёҠйқўзҡ„ Ingester зҡ„ staring еҮҪж•°дёӯжңҖеҗҺжңүдёҖдёӘ go i.loop()пјҢеңЁиҝҷдёӘ loop() еҮҪж•°дёӯдјҡжҜҸйҡ” FlushCheckPeriod(й»ҳи®Ө 30sпјҢеҸҜд»ҘйҖҡиҝҮ --ingester.flush-check-period иҝӣиЎҢй…ҚзҪ®)ж—¶й—ҙе°ұдјҡеҺ»еҺ»и°ғз”Ё sweepUsers еҮҪж•°иҝӣиЎҢеһғеңҫеӣһ收пјҡ
// pkg/ingester/ingester.go func (i *Ingester) loop() { defer i.loopDone.Done() flushTicker := time.NewTicker(i.cfg.FlushCheckPeriod) defer flushTicker.Stop() for { select { case <-flushTicker.C: i.sweepUsers(false, true) case <-i.loopQuit: return } } }sweepUsers еҮҪж•°з”ЁдәҺжү§иЎҢе°Ҷж—Ҙеҝ—жөҒж•°жҚ®еҠ е…ҘеҲ°дјҳе…Ҳзә§йҳҹеҲ—дёӯпјҢ并еҜ№жІЎжңүеәҸеҲ—зҡ„з”ЁжҲ·иҝӣиЎҢеһғеңҫеӣһ收пјҡ
// pkg/ingester/flush.go // sweepUsers е®ҡжңҹжү§иЎҢ flush ж“ҚдҪңпјҢ并еҜ№жІЎжңүеәҸеҲ—зҡ„з”ЁжҲ·иҝӣиЎҢеһғеңҫеӣһ收 func (i *Ingester) sweepUsers(immediate, mayRemoveStreams bool) { instances := i.getInstances() for _, instance := range instances { i.sweepInstance(instance, immediate, mayRemoveStreams) } } func (i *Ingester) sweepInstance(instance *instance, immediate, mayRemoveStreams bool) { instance.streamsMtx.Lock() defer instance.streamsMtx.Unlock() for _, stream := range instance.streams { i.sweepStream(instance, stream, immediate) i.removeFlushedChunks(instance, stream, mayRemoveStreams) } } // must hold streamsMtx func (i *Ingester) sweepStream(instance *instance, stream *stream, immediate bool) { stream.chunkMtx.RLock() defer stream.chunkMtx.RUnlock() if len(stream.chunks) == 0 { return } // жңҖж–°зҡ„chunk lastChunk := stream.chunks[len(stream.chunks)-1] // еҲӨж–ӯжҳҜеҗҰеә”иҜҘиў«flush shouldFlush, _ := i.shouldFlushChunk(&lastChunk) // еҰӮжһңеҸӘжңүдёҖдёӘchunk并且дёҚжҳҜејәеҲ¶жҢҒд№…еҢ–еҲҮжңҖж–°зҡ„chunkиҝҳдёҚеә”иҜҘиў«flushпјҢеҲҷзӣҙжҺҘиҝ”еӣһ if len(stream.chunks) == 1 && !immediate && !shouldFlush { return } // ж №жҚ®жҢҮзә№иҺ·еҸ–з”ЁдёҺеӨ„зҗҶзҡ„дјҳе…Ҳзә§йҳҹеҲ—зҙўеј• flushQueueIndex := int(uint64(stream.fp) % uint64(i.cfg.ConcurrentFlushes)) firstTime, _ := stream.chunks[0].chunk.Bounds() // еҠ е…ҘеҲ°дјҳе…Ҳзә§йҳҹеҲ—дёӯеҺ» i.flushQueues[flushQueueIndex].Enqueue(&flushOp{ model.TimeFromUnixNano(firstTime.UnixNano()), instance.instanceID, stream.fp, immediate, }) } // 移йҷӨе·Із»ҸflushиҝҮеҗҺзҡ„chunksж•°жҚ® func (i *Ingester) removeFlushedChunks(instance *instance, stream *stream, mayRemoveStream bool) { now := time.Now() stream.chunkMtx.Lock() defer stream.chunkMtx.Unlock() prevNumChunks := len(stream.chunks) var subtracted int for len(stream.chunks) > 0 { // еҰӮжһңchunkиҝҳжІЎжңүиў«еҲ·ж–°еҲ°еӯҳеӮЁ жҲ–иҖ… chunkиў«еҲ·ж–°еҲ°еӯҳеӮЁеҲ°зҺ°еңЁзҡ„ж—¶й—ҙиҝҳжІЎж“ҚиҝҮ RetainPeriodпјҲй»ҳи®Ө15еҲҶй’ҹпјҢеҸҜд»ҘйҖҡиҝҮ--ingester.chunks-retain-period иҝӣиЎҢй…ҚзҪ®пјүеҲҷеҝҪз•Ҙ if stream.chunks[0].flushed.IsZero() || now.Sub(stream.chunks[0].flushed) < i.cfg.RetainPeriod { break } subtracted += stream.chunks[0].chunk.UncompressedSize() // еҲ йҷӨеј•з”ЁпјҢд»ҘдҫҝиҜҘеқ—еҸҜд»Ҙиў«еһғеңҫеӣһ收иө·жқҘ stream.chunks[0].chunk = nil // 移йҷӨchunk stream.chunks = stream.chunks[1:] } ...... // еҰӮжһңstreamдёӯзҡ„жүҖжңүchunkйғҪиў«жё…з©әдәҶпјҢеҲҷжё…з©әиҜҘ stream зҡ„зӣёе…іж•°жҚ® if mayRemoveStream && len(stream.chunks) == 0 { delete(instance.streamsByFP, stream.fp) delete(instance.streams, stream.labelsString) instance.index.Delete(stream.labels, stream.fp) ...... } }е…ідәҺеӯҳеӮЁжҲ–иҖ…жҹҘиҜўзӯүжЁЎеқ—зҡ„е®һзҺ°еңЁеҗҺж–ҮеҶҚ继з»ӯжҺўзҙўпјҢеҢ…жӢ¬ WAL зҡ„е®һзҺ°д№ҹиҫғдёәеӨҚжқӮгҖӮ
вҖңLoki зҡ„дҪңз”ЁжҳҜд»Җд№ҲвҖқзҡ„еҶ…е®№е°ұд»Ӣз»ҚеҲ°иҝҷйҮҢдәҶпјҢж„ҹи°ўеӨ§е®¶зҡ„йҳ…иҜ»гҖӮеҰӮжһңжғідәҶи§ЈжӣҙеӨҡиЎҢдёҡзӣёе…ізҡ„зҹҘиҜҶеҸҜд»Ҙе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–е°ҶдёәеӨ§е®¶иҫ“еҮәжӣҙеӨҡй«ҳиҙЁйҮҸзҡ„е®һз”Ёж–Үз« пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ