жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« дё»иҰҒи®Іи§ЈдәҶвҖңжҖҺд№Ҳз”Ё Python еӯҰд№ Google зҡ„иҮӘ然иҜӯиЁҖ APIвҖқпјҢж–Үдёӯзҡ„и®Іи§ЈеҶ…е®№з®ҖеҚ•жё…жҷ°пјҢжҳ“дәҺеӯҰд№ дёҺзҗҶи§ЈпјҢдёӢйқўиҜ·еӨ§е®¶и·ҹзқҖе°Ҹзј–зҡ„жҖқи·Ҝж…ўж…ўж·ұе…ҘпјҢдёҖиө·жқҘз ”з©¶е’ҢеӯҰд№ вҖңжҖҺд№Ҳз”Ё Python еӯҰд№ Google зҡ„иҮӘ然иҜӯиЁҖ APIвҖқеҗ§пјҒ
дҪңдёәдёҖеҗҚжҠҖжңҜжҖ§зҡ„жҗңзҙўеј•ж“ҺдјҳеҢ–дәәе‘ҳпјҢжҲ‘дёҖзӣҙеңЁеҜ»жүҫд»Ҙж–°йў–зҡ„ж–№ејҸдҪҝз”Ёж•°жҚ®зҡ„ж–№жі•пјҢд»ҘжӣҙеҘҪең°дәҶи§Ј Google еҰӮдҪ•еҜ№зҪ‘з«ҷиҝӣиЎҢжҺ’еҗҚгҖӮжҲ‘жңҖиҝ‘з ”з©¶дәҶ Google зҡ„ иҮӘ然иҜӯиЁҖ API иғҪеҗҰжӣҙеҘҪең°жҸӯзӨә Google жҳҜеҰӮдҪ•еҲҶзұ»зҪ‘з«ҷеҶ…е®№зҡ„гҖӮ
е°Ҫз®Ўжңү ејҖжәҗ NLP е·Ҙе…·пјҢдҪҶжҲ‘жғіжҺўзҙўи°·жӯҢзҡ„е·Ҙе…·пјҢеүҚжҸҗжҳҜе®ғеҸҜиғҪеңЁе…¶д»–дә§е“ҒдёӯдҪҝз”ЁеҗҢж ·зҡ„жҠҖжңҜпјҢжҜ”еҰӮжҗңзҙўгҖӮжң¬ж–Үд»Ӣз»ҚдәҶ Google зҡ„иҮӘ然иҜӯиЁҖ APIпјҢ并жҺўз©¶дәҶеёёи§Ғзҡ„иҮӘ然иҜӯиЁҖеӨ„зҗҶпјҲNLPпјүд»»еҠЎпјҢд»ҘеҸҠеҰӮдҪ•дҪҝз”Ёе®ғ们жқҘдёәзҪ‘з«ҷеҶ…е®№еҲӣе»әжҸҗдҫӣдҝЎжҒҜгҖӮ
йҰ–е…ҲпјҢдәҶи§Ј Google иҮӘ然иҜӯиЁҖ API иҝ”еӣһзҡ„ж•°жҚ®зұ»еһӢйқһеёёйҮҚиҰҒгҖӮ
е®һдҪ“жҳҜеҸҜд»ҘдёҺзү©зҗҶдё–з•Ңдёӯзҡ„жҹҗдәӣдәӢзү©иҒ”зі»еңЁдёҖиө·зҡ„ж–Үжң¬зҹӯиҜӯгҖӮе‘ҪеҗҚе®һдҪ“иҜҶеҲ«пјҲNERпјүжҳҜ NLP зҡ„йҡҫзӮ№пјҢеӣ дёәе·Ҙе…·йҖҡеёёйңҖиҰҒжҹҘзңӢе…ій”®еӯ—зҡ„е®Ңж•ҙдёҠдёӢж–ҮжүҚиғҪзҗҶи§Је…¶з”Ёжі•гҖӮдҫӢеҰӮпјҢеҗҢеҪўејӮд№үеӯ—жӢјеҶҷзӣёеҗҢпјҢдҪҶжҳҜе…·жңүеӨҡз§Қеҗ«д№үгҖӮеҸҘеӯҗдёӯзҡ„ вҖңleadвҖқ жҳҜжҢҮдёҖз§ҚйҮ‘еұһпјҡвҖңй“…вҖқпјҲеҗҚиҜҚпјүпјҢдҪҝжҹҗдәә移еҠЁпјҡвҖңзүөйўҶвҖқпјҲеҠЁиҜҚпјүпјҢиҝҳеҸҜиғҪжҳҜеү§жң¬дёӯзҡ„дё»иҰҒи§’иүІпјҲд№ҹжҳҜеҗҚиҜҚпјүпјҹGoogle жңү 12 з§ҚдёҚеҗҢзұ»еһӢзҡ„е®һдҪ“пјҢиҝҳжңү第 13 дёӘеҗҚдёә вҖңUNKNOWNвҖқпјҲжңӘзҹҘпјүзҡ„з»ҹз§°зұ»еҲ«гҖӮдёҖдәӣе®һдҪ“дёҺз»ҙеҹәзҷҫ科зҡ„ж–Үз« зӣёе…іпјҢиҝҷиЎЁжҳҺ зҹҘиҜҶеӣҫи°ұ еҜ№ж•°жҚ®зҡ„еҪұе“ҚгҖӮжҜҸдёӘе®һдҪ“йғҪдјҡиҝ”еӣһдёҖдёӘжҳҫи‘—жҖ§еҲҶж•°пјҢеҚіе…¶дёҺжүҖжҸҗдҫӣж–Үжң¬зҡ„ж•ҙдҪ“зӣёе…іжҖ§гҖӮ
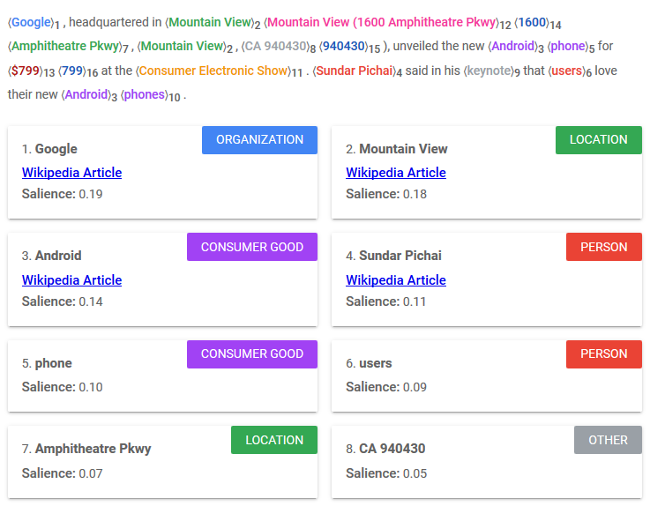
е®һдҪ“
жғ…ж„ҹпјҢеҚіеҜ№жҹҗдәӢзҡ„зңӢжі•жҲ–жҖҒеәҰпјҢжҳҜеңЁж–Ү件е’ҢеҸҘеӯҗеұӮйқўд»ҘеҸҠж–Ү件дёӯеҸ‘зҺ°зҡ„еҚ•дёӘе®һдҪ“дёҠиҝӣиЎҢиЎЎйҮҸгҖӮжғ…ж„ҹзҡ„еҫ—еҲҶиҢғеӣҙд»Һ -1.0пјҲж¶ҲжһҒпјүеҲ° 1.0пјҲз§ҜжһҒпјүгҖӮе№…еәҰд»ЈиЎЁжғ…ж„ҹзҡ„йқһеҪ’дёҖеҢ–ејәеәҰпјӣе®ғзҡ„иҢғеӣҙжҳҜ 0.0 еҲ°ж— з©·еӨ§гҖӮ

жғ…ж„ҹ
иҜӯжі•и§ЈжһҗеҢ…еҗ«дәҶеӨ§еӨҡж•°еңЁиҫғеҘҪзҡ„еә“дёӯеёёи§Ғзҡ„ NLP жҙ»еҠЁпјҢдҫӢеҰӮ иҜҚеҪўжј”еҸҳгҖҒиҜҚжҖ§ж Үи®° е’Ң дҫқиө–ж ‘и§ЈжһҗгҖӮNLP дё»иҰҒеӨ„зҗҶеё®еҠ©жңәеҷЁзҗҶи§Јж–Үжң¬е’Ңе…ій”®еӯ—д№Ӣй—ҙзҡ„е…ізі»гҖӮиҜӯжі•и§ЈжһҗжҳҜеӨ§еӨҡж•°иҜӯиЁҖеӨ„зҗҶжҲ–зҗҶи§Јд»»еҠЎзҡ„еҹәзЎҖйғЁеҲҶгҖӮ

иҜӯжі•
еҲҶзұ»жҳҜе°Ҷж•ҙдёӘз»ҷе®ҡеҶ…е®№еҲҶй…Қз»ҷзү№е®ҡиЎҢдёҡжҲ–дё»йўҳзұ»еҲ«пјҢе…¶зҪ®дҝЎеәҰеҫ—еҲҶд»Һ 0.0 еҲ° 1.0гҖӮиҝҷдәӣеҲҶзұ»дјјд№ҺдёҺе…¶д»– Google е·Ҙе…·дҪҝз”Ёзҡ„еҸ—дј—зҫӨдҪ“е’ҢзҪ‘з«ҷзұ»еҲ«зӣёеҗҢпјҢеҰӮ AdWordsгҖӮ
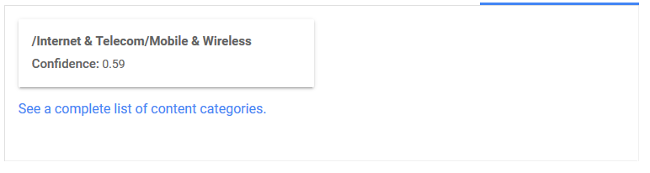
еҲҶзұ»
зҺ°еңЁпјҢжҲ‘е°ҶжҸҗеҸ–дёҖдәӣзӨәдҫӢж•°жҚ®иҝӣиЎҢеӨ„зҗҶгҖӮжҲ‘дҪҝз”Ё Google зҡ„ жҗңзҙўжҺ§еҲ¶еҸ° API 收йӣҶдәҶдёҖдәӣжҗңзҙўжҹҘиҜўеҸҠе…¶зӣёеә”зҡ„зҪ‘еқҖгҖӮGoogle жҗңзҙўжҺ§еҲ¶еҸ°жҳҜдёҖдёӘжҠҘе‘Ҡдәә们дҪҝз”Ё Google Search жҹҘжүҫзҪ‘з«ҷйЎөйқўзҡ„жңҜиҜӯзҡ„е·Ҙе…·гҖӮиҝҷдёӘ ејҖжәҗзҡ„ Jupyter 笔记жң¬ еҸҜд»Ҙи®©дҪ жҸҗеҸ–жңүе…ізҪ‘з«ҷзҡ„зұ»дјјж•°жҚ®гҖӮеңЁжӯӨзӨәдҫӢдёӯпјҢжҲ‘еңЁ 2019 е№ҙ 1 жңҲ 1 ж—ҘиҮі 6 жңҲ 1 ж—Ҙжңҹй—ҙз”ҹжҲҗзҡ„дёҖдёӘзҪ‘з«ҷпјҲжҲ‘жІЎжңүжҸҗеҸҠеҗҚеӯ—пјүдёҠжҸҗеҸ–дәҶ Google жҗңзҙўжҺ§еҲ¶еҸ°ж•°жҚ®пјҢ并е°Ҷе…¶йҷҗеҲ¶дёәиҮіе°‘иҺ·еҫ—дёҖж¬ЎзӮ№еҮ»пјҲиҖҢдёҚеҸӘжҳҜжӣқе…үпјүзҡ„жҹҘиҜўгҖӮ
иҜҘж•°жҚ®йӣҶеҢ…еҗ« 2969 дёӘйЎөйқўе’ҢеңЁ Google Search зҡ„з»“жһңдёӯжҳҫзӨәдәҶиҜҘзҪ‘з«ҷзҪ‘йЎөзҡ„ 7144 жқЎжҹҘиҜўзҡ„дҝЎжҒҜгҖӮдёӢиЎЁжҳҫзӨәпјҢз»қеӨ§еӨҡж•°йЎөйқўиҺ·еҫ—зҡ„зӮ№еҮ»еҫҲе°‘пјҢеӣ дёәиҜҘзҪ‘з«ҷдҫ§йҮҚдәҺжүҖи°“зҡ„й•ҝе°ҫпјҲи¶Ҡзү№ж®ҠйҖҡеёёе°ұжӣҙй•ҝе°ҫпјүиҖҢдёҚжҳҜзҹӯе°ҫпјҲйқһеёёз¬јз»ҹпјҢжҗңзҙўйҮҸжӣҙеӨ§пјүжҗңзҙўжҹҘиҜўгҖӮ

жүҖжңүйЎөйқўзҡ„зӮ№еҮ»ж¬Ўж•°жҹұзҠ¶еӣҫ
дёәдәҶеҮҸе°‘ж•°жҚ®йӣҶзҡ„еӨ§е°Ҹ并仅иҺ·еҫ—ж•ҲжһңжңҖеҘҪзҡ„йЎөйқўпјҢжҲ‘е°Ҷж•°жҚ®йӣҶйҷҗеҲ¶дёәеңЁжӯӨжңҹй—ҙиҮіе°‘иҺ·еҫ— 20 ж¬Ўжӣқе…үзҡ„йЎөйқўгҖӮиҝҷжҳҜзІҫзӮјж•°жҚ®йӣҶзҡ„жҢүйЎөзӮ№еҮ»зҡ„жҹұзҠ¶еӣҫпјҢе…¶дёӯеҢ…жӢ¬ 723 дёӘйЎөйқўпјҡ
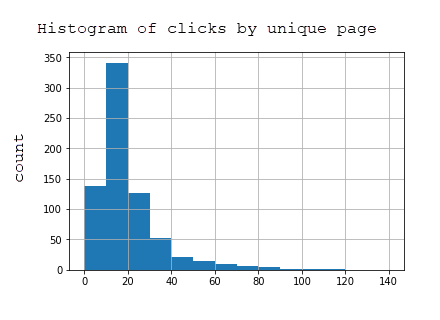
йғЁеҲҶзҪ‘йЎөзҡ„зӮ№еҮ»ж¬Ўж•°жҹұзҠ¶еӣҫ
иҰҒжөӢиҜ• APIпјҢеңЁ Python дёӯеҲӣе»әдёҖдёӘеҲ©з”Ё google-cloud-language еә“зҡ„е°Ҹи„ҡжң¬гҖӮд»ҘдёӢд»Јз ҒеҹәдәҺ Python 3.5+гҖӮ
йҰ–е…ҲпјҢжҝҖжҙ»дёҖдёӘж–°зҡ„иҷҡжӢҹзҺҜеўғ并е®үиЈ…еә“гҖӮз”ЁзҺҜеўғзҡ„е”ҜдёҖеҗҚз§°жӣҝжҚў <your-env> гҖӮ
virtualenv <your-env>source <your-env>/bin/activatepip install --upgrade google-cloud-languagepip install --upgrade requests
иҜҘи„ҡжң¬д»Һ URL жҸҗеҸ– HTMLпјҢ并е°Ҷ HTML жҸҗдҫӣз»ҷиҮӘ然иҜӯиЁҖ APIгҖӮиҝ”еӣһдёҖдёӘеҢ…еҗ« sentimentгҖҒ entities е’Ң categories зҡ„еӯ—е…ёпјҢе…¶дёӯиҝҷдәӣй”®зҡ„еҖјйғҪжҳҜеҲ—иЎЁгҖӮжҲ‘дҪҝз”Ё Jupyter 笔记жң¬иҝҗиЎҢжӯӨд»Јз ҒпјҢеӣ дёәдҪҝз”ЁеҗҢдёҖеҶ…ж ёжіЁйҮҠе’ҢйҮҚиҜ•д»Јз ҒжӣҙеҠ е®№жҳ“гҖӮ
# Import needed librariesimport requestsimport json from google.cloud import languagefrom google.oauth3 import service_accountfrom google.cloud.language import enumsfrom google.cloud.language import types # Build language API client (requires service account key)client = language.LanguageServiceClient.from_service_account_json('services.json') # Define functionsdef pull_googlenlp(client, url, invalid_types = ['OTHER'], **data): html = load_text_from_url(url, **data) if not html: return None document = types.Document( content=html, type=language.enums.Document.Type.HTML ) features = {'extract_syntax': True, 'extract_entities': True, 'extract_document_sentiment': True, 'extract_entity_sentiment': True, 'classify_text': False } response = client.annotate_text(document=document, features=features) sentiment = response.document_sentiment entities = response.entities response = client.classify_text(document) categories = response.categories def get_type(type): return client.enums.Entity.Type(entity.type).name result = {} result['sentiment'] = [] result['entities'] = [] result['categories'] = [] if sentiment: result['sentiment'] = [{ 'magnitude': sentiment.magnitude, 'score':sentiment.score }] for entity in entities: if get_type(entity.type) not in invalid_types: result['entities'].append({'name': entity.name, 'type': get_type(entity.type), 'salience': entity.salience, 'wikipedia_url': entity.metadata.get('wikipedia_url', '-') }) for category in categories: result['categories'].append({'name':category.name, 'confidence': category.confidence}) return result def load_text_from_url(url, **data): timeout = data.get('timeout', 20) results = [] try: print("Extracting text from: {}".format(url)) response = requests.get(url, timeout=timeout) text = response.text status = response.status_code if status == 200 and len(text) > 0: return text return None except Exception as e: print('Problem with url: {0}.'.format(url)) return NoneиҰҒи®ҝй—®иҜҘ APIпјҢиҜ·жҢүз…§ Google зҡ„ еҝ«йҖҹе…Ҙй—ЁиҜҙжҳҺ еңЁ Google дә‘дё»жҺ§еҸ°дёӯеҲӣе»әдёҖдёӘйЎ№зӣ®пјҢеҗҜз”ЁиҜҘ API 并дёӢиҪҪжңҚеҠЎеёҗжҲ·еҜҶй’ҘгҖӮд№ӢеҗҺпјҢдҪ еә”иҜҘжӢҘжңүдёҖдёӘзұ»дјјдәҺд»ҘдёӢеҶ…е®№зҡ„ JSON ж–Ү件пјҡ

services.json ж–Ү件
е‘ҪеҗҚдёә services.jsonпјҢ并дёҠдј еҲ°йЎ№зӣ®ж–Ү件еӨ№гҖӮ
然еҗҺпјҢдҪ еҸҜд»ҘйҖҡиҝҮиҝҗиЎҢд»ҘдёӢзЁӢеәҸжқҘжҸҗеҸ–д»»дҪ• URLпјҲдҫӢеҰӮ Opensource.comпјүзҡ„ API ж•°жҚ®пјҡ
url = "https://opensource.com/article/19/6/how-ssh-running-container"pull_googlenlp(client,url)
еҰӮжһңи®ҫзҪ®жӯЈзЎ®пјҢдҪ е°ҶзңӢеҲ°д»ҘдёӢиҫ“еҮәпјҡ

жӢүеҸ– API ж•°жҚ®зҡ„иҫ“еҮә
дёәдәҶдҪҝе…Ҙй—ЁжӣҙеҠ е®№жҳ“пјҢжҲ‘еҲӣе»әдәҶдёҖдёӘ Jupyter 笔记жң¬пјҢдҪ еҸҜд»ҘдёӢиҪҪ并дҪҝз”Ёе®ғжқҘжөӢиҜ•жҸҗеҸ–зҪ‘йЎөзҡ„е®һдҪ“гҖҒзұ»еҲ«е’Ңжғ…ж„ҹгҖӮжҲ‘жӣҙе–ңж¬ўдҪҝз”Ё JupyterLabпјҢе®ғжҳҜ Jupyter 笔记жң¬зҡ„жү©еұ•пјҢе…¶дёӯеҢ…жӢ¬ж–Ү件жҹҘзңӢеҷЁе’Ңе…¶д»–еўһејәзҡ„з”ЁжҲ·дҪ“йӘҢеҠҹиғҪгҖӮеҰӮжһңдҪ дёҚзҶҹжӮүиҝҷдәӣе·Ҙе…·пјҢжҲ‘и®ӨдёәеҲ©з”Ё Anaconda жҳҜејҖе§ӢдҪҝз”Ё Python е’Ң Jupyter зҡ„жңҖз®ҖеҚ•йҖ”еҫ„гҖӮе®ғдҪҝе®үиЈ…е’Ңи®ҫзҪ® Python д»ҘеҸҠеёёз”Ёеә“еҸҳеҫ—йқһеёёе®№жҳ“пјҢе°Өе…¶жҳҜеңЁ Windows дёҠгҖӮ
дҪҝз”ЁиҝҷдәӣеҮҪж•°пјҢеҸҜжҠ“еҸ–з»ҷе®ҡйЎөйқўзҡ„ HTML 并е°Ҷе…¶дј йҖ’з»ҷиҮӘ然иҜӯиЁҖ APIпјҢжҲ‘еҸҜд»ҘеҜ№ 723 дёӘ URL иҝӣиЎҢдёҖдәӣеҲҶжһҗгҖӮйҰ–е…ҲпјҢжҲ‘е°ҶйҖҡиҝҮжҹҘзңӢжүҖжңүйЎөйқўдёӯиҝ”еӣһзҡ„йЎ¶зә§еҲҶзұ»зҡ„ж•°йҮҸжқҘжҹҘзңӢдёҺзҪ‘з«ҷзӣёе…ізҡ„еҲҶзұ»гҖӮ
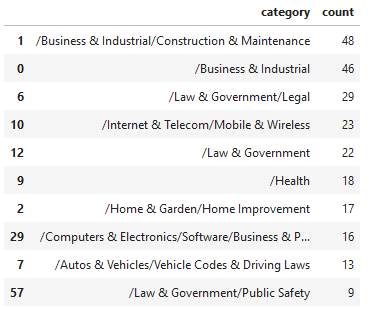
жқҘиҮӘзӨәдҫӢз«ҷзӮ№зҡ„еҲҶзұ»ж•°жҚ®
иҝҷдјјд№ҺжҳҜиҜҘзү№е®ҡз«ҷзӮ№зҡ„е…ій”®дё»йўҳзҡ„зӣёеҪ“еҮҶзЎ®зҡ„д»ЈиЎЁгҖӮйҖҡиҝҮжҹҘзңӢдёҖдёӘж•ҲжһңжңҖеҘҪзҡ„йЎөйқўиҝӣиЎҢжҺ’еҗҚзҡ„еҚ•дёӘжҹҘиҜўпјҢжҲ‘еҸҜд»ҘжҜ”иҫғеҗҢдёҖжҹҘиҜўеңЁ Google жҗңзҙўз»“жһңдёӯзҡ„е…¶д»–жҺ’еҗҚйЎөйқўгҖӮ
URL 1 |йЎ¶зә§зұ»еҲ«пјҡ/жі•еҫӢе’Ңж”ҝеәң/дёҺжі•еҫӢзӣёе…ізҡ„пјҲ0.5099999904632568пјүе…ұ 1 дёӘзұ»еҲ«гҖӮ
жңӘиҝ”еӣһд»»дҪ•зұ»еҲ«гҖӮ
URL 3 |йЎ¶зә§зұ»еҲ«пјҡ/дә’иҒ”зҪ‘дёҺз”өдҝЎ/移еҠЁдёҺж— зәҝпјҲ0.6100000143051147пјүе…ұ 1 дёӘзұ»еҲ«гҖӮ
URL 4 |йЎ¶зә§зұ»еҲ«пјҡ/и®Ўз®—жңәдёҺз”өеӯҗдә§е“Ғ/иҪҜ件пјҲ0.5799999833106995пјүе…ұжңү 2 дёӘзұ»еҲ«гҖӮ
URL 5 |йЎ¶зә§зұ»еҲ«пјҡ/дә’иҒ”зҪ‘дёҺз”өдҝЎ/移еҠЁдёҺж— зәҝ/移еҠЁеә”з”ЁзЁӢеәҸе’Ңйҷ„件пјҲ0.75пјүе…ұжңү 1 дёӘзұ»еҲ«гҖӮ
жңӘиҝ”еӣһд»»дҪ•зұ»еҲ«гҖӮ
URL 7 |йЎ¶зә§зұ»еҲ«пјҡ/и®Ўз®—жңәдёҺз”өеӯҗ/иҪҜ件/е•ҶдёҡдёҺз”ҹдә§еҠӣиҪҜ件пјҲ0.7099999785423279пјүе…ұ 2 дёӘзұ»еҲ«гҖӮ
URL 8 |йЎ¶зә§зұ»еҲ«пјҡ/жі•еҫӢе’Ңж”ҝеәң/дёҺжі•еҫӢзӣёе…ізҡ„пјҲ0.8999999761581421пјүе…ұ 3 дёӘзұ»еҲ«гҖӮ
URL 9 |йЎ¶зә§зұ»еҲ«пјҡ/еҸӮиҖғ/дёҖиҲ¬еҸӮиҖғ/зұ»еһӢжҢҮеҚ—е’ҢжЁЎжқҝпјҲ0.6399999856948853пјүе…ұжңү 1 дёӘзұ»еҲ«гҖӮ
жңӘиҝ”еӣһд»»дҪ•зұ»еҲ«гҖӮ
дёҠж–№жӢ¬еҸ·дёӯзҡ„ж•°еӯ—иЎЁзӨә Google еҜ№йЎөйқўеҶ…е®№дёҺиҜҘеҲҶзұ»зӣёе…ізҡ„зҪ®дҝЎеәҰгҖӮеҜ№дәҺзӣёеҗҢеҲҶзұ»пјҢ第八дёӘз»“жһңжҜ”第дёҖдёӘз»“жһңе…·жңүжӣҙй«ҳзҡ„зҪ®дҝЎеәҰпјҢеӣ жӯӨпјҢиҝҷдјјд№ҺдёҚжҳҜе®ҡд№үжҺ’еҗҚзӣёе…іжҖ§зҡ„зҒөдё№еҰҷиҚҜгҖӮжӯӨеӨ–пјҢеҲҶзұ»еӨӘе®ҪжіӣеҜјиҮҙж— жі•ж»Ўи¶ізү№е®ҡжҗңзҙўдё»йўҳзҡ„йңҖиҰҒгҖӮ
йҖҡиҝҮжҺ’еҗҚжҹҘзңӢе№іеқҮзҪ®дҝЎеәҰпјҢиҝҷдёӨдёӘжҢҮж Үд№Ӣй—ҙдјјд№ҺжІЎжңүзӣёе…іжҖ§пјҢиҮіе°‘еҜ№дәҺжӯӨж•°жҚ®йӣҶиҖҢиЁҖеҰӮжӯӨпјҡ
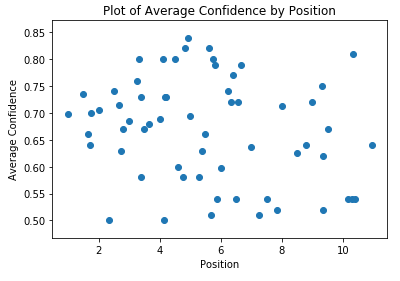
е№іеқҮзҪ®дҝЎеәҰжҺ’еҗҚеҲҶеёғеӣҫ
иҝҷдёӨз§Қж–№жі•еҜ№зҪ‘з«ҷиҝӣиЎҢ规模审жҹҘжҳҜжңүж„Ҹд№үзҡ„пјҢд»ҘзЎ®дҝқеҶ…е®№зұ»еҲ«жҳ“дәҺзҗҶи§ЈпјҢе№¶дё”ж ·жқҝжҲ–й”Җе”®еҶ…е®№дёҚдјҡдҪҝдҪ зҡ„йЎөйқўдёҺдҪ зҡ„дё»иҰҒдё“дёҡзҹҘиҜҶйўҶеҹҹж— е…ігҖӮжғідёҖжғіпјҢеҰӮжһңдҪ еҮәе”®е·Ҙдёҡз”Ёе“ҒпјҢдҪҶжҳҜдҪ зҡ„йЎөйқўиҝ”еӣһ вҖңMarketingпјҲй”Җе”®пјүвҖқ дҪңдёәдё»иҰҒеҲҶзұ»гҖӮдјјд№ҺжІЎжңүдёҖдёӘејәзғҲзҡ„иҝ№иұЎиЎЁжҳҺпјҢеҲҶзұ»зӣёе…іжҖ§дёҺдҪ зҡ„жҺ’еҗҚжңүд»Җд№Ҳе…ізі»пјҢиҮіе°‘еңЁйЎөйқўзә§еҲ«еҰӮжӯӨгҖӮ
жҲ‘дёҚдјҡеңЁжғ…ж„ҹдёҠиҠұеҫҲеӨҡж—¶й—ҙгҖӮеңЁжүҖжңүд»Һ API иҝ”еӣһжғ…ж„ҹзҡ„йЎөйқўдёӯпјҢе®ғ们еҲҶдёәдёӨдёӘеҢәй—ҙпјҡ0.1 е’Ң 0.2пјҢиҝҷеҮ д№ҺжҳҜдёӯз«Ӣзҡ„жғ…ж„ҹгҖӮж №жҚ®зӣҙж–№еӣҫпјҢеҫҲе®№жҳ“зңӢеҮәжғ…ж„ҹжІЎжңүеӨӘеӨ§д»·еҖјгҖӮеҜ№дәҺж–°й—»жҲ–иҲҶи®әзҪ‘з«ҷиҖҢиЁҖпјҢжөӢйҮҸзү№е®ҡйЎөйқўзҡ„жғ…ж„ҹеҲ°дёӯдҪҚж•°жҺ’еҗҚд№Ӣй—ҙзҡ„зӣёе…іжҖ§е°ҶжҳҜдёҖдёӘжӣҙеҠ жңүи¶Јзҡ„жҢҮж ҮгҖӮ

зӢ¬зү№йЎөйқўзҡ„жғ…ж„ҹжҹұзҠ¶еӣҫ
еңЁжҲ‘зңӢжқҘпјҢе®һдҪ“жҳҜ API дёӯжңҖжңүи¶Јзҡ„йғЁеҲҶгҖӮиҝҷжҳҜеңЁжүҖжңүйЎөйқўдёӯжҢүжҳҫи‘—жҖ§пјҲжҲ–дёҺйЎөйқўзҡ„зӣёе…іжҖ§пјүйҖүжӢ©зҡ„йЎ¶зә§е®һдҪ“гҖӮиҜ·жіЁж„ҸпјҢеҜ№дәҺзӣёеҗҢзҡ„жңҜиҜӯпјҲй”Җе”®жё…еҚ•пјүпјҢGoogle дјҡжҺЁж–ӯеҮәдёҚеҗҢзҡ„зұ»еһӢпјҢеҸҜиғҪжҳҜй”ҷиҜҜзҡ„гҖӮиҝҷжҳҜз”ұдәҺиҝҷдәӣжңҜиҜӯеҮәзҺ°еңЁеҶ…е®№дёӯзҡ„дёҚеҗҢдёҠдёӢж–Үдёӯеј•иө·зҡ„гҖӮ
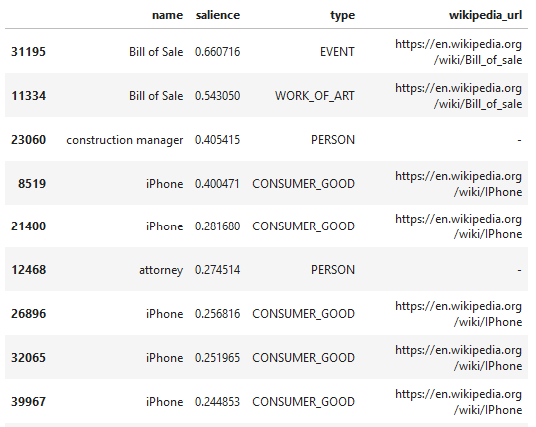
зӨәдҫӢзҪ‘з«ҷзҡ„йЎ¶зә§е®һдҪ“
然еҗҺпјҢжҲ‘еҲҶеҲ«жҹҘзңӢдәҶжҜҸдёӘе®һдҪ“зұ»еһӢпјҢ并дёҖиө·жҹҘзңӢдәҶиҜҘе®һдҪ“зҡ„жҳҫи‘—жҖ§дёҺйЎөйқўзҡ„жңҖдҪіжҺ’еҗҚдҪҚзҪ®д№Ӣй—ҙжҳҜеҗҰеӯҳеңЁд»»дҪ•е…іиҒ”гҖӮеҜ№дәҺжҜҸз§Қзұ»еһӢпјҢжҲ‘еҢ№й…ҚдәҶдёҺиҜҘзұ»еһӢеҢ№й…Қзҡ„йЎ¶зә§е®һдҪ“зҡ„жҳҫи‘—жҖ§пјҲдёҺйЎөйқўзҡ„ж•ҙдҪ“зӣёе…іжҖ§пјүпјҢжҢүжҳҫи‘—жҖ§жҺ’еәҸпјҲйҷҚеәҸпјүгҖӮ
жңүдәӣе®һдҪ“зұ»еһӢеңЁжүҖжңүзӨәдҫӢдёӯиҝ”еӣһзҡ„жҳҫи‘—жҖ§дёәйӣ¶пјҢеӣ жӯӨжҲ‘д»ҺдёӢйқўзҡ„еӣҫиЎЁдёӯзңҒз•ҘдәҶиҝҷдәӣз»“жһңгҖӮ
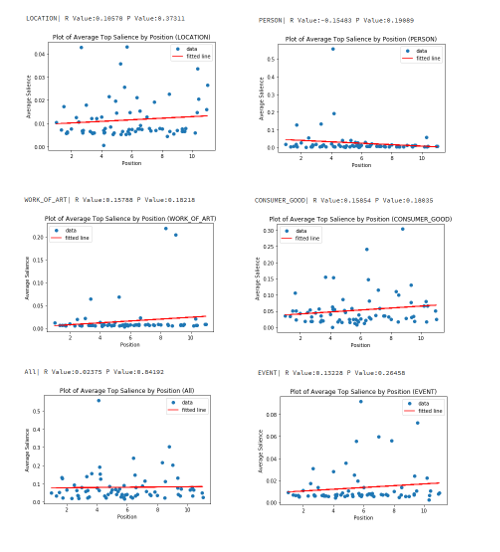
жҳҫи‘—жҖ§дёҺжңҖдҪіжҺ’еҗҚдҪҚзҪ®зҡ„зӣёе…іжҖ§
вҖңConsumer GoodпјҲж¶Ҳиҙ№жҖ§е•Ҷе“ҒпјүвҖқ е®һдҪ“зұ»еһӢе…·жңүжңҖй«ҳзҡ„жӯЈзӣёе…іжҖ§пјҢзҡ®е°”жЈ®зӣёе…іеәҰдёә 0.15854пјҢе°Ҫз®Ўз”ұдәҺиҫғдҪҺзј–еҸ·зҡ„жҺ’еҗҚжӣҙеҘҪпјҢжүҖд»Ҙ вҖңPersonвҖқ е®һдҪ“зҡ„з»“жһңжңҖеҘҪпјҢзӣёе…іеәҰдёә -0.15483гҖӮиҝҷжҳҜдёҖдёӘйқһеёёе°Ҹзҡ„ж ·жң¬йӣҶпјҢе°Өе…¶жҳҜеҜ№дәҺеҚ•дёӘе®һдҪ“зұ»еһӢпјҢжҲ‘дёҚиғҪеҜ№ж•°жҚ®еҒҡеӨӘеӨҡзҡ„еҲӨж–ӯгҖӮжҲ‘жІЎжңүеҸ‘зҺ°д»»дҪ•е…·жңүејәзӣёе…іжҖ§зҡ„еҖјпјҢдҪҶжҳҜ вҖңPersonвҖқ е®һдҪ“жңҖжңүж„Ҹд№үгҖӮзҪ‘з«ҷйҖҡеёёйғҪжңүе…ідәҺе…¶йҰ–еёӯжү§иЎҢе®ҳе’Ңе…¶д»–дё»иҰҒйӣҮе‘ҳзҡ„йЎөйқўпјҢиҝҷдәӣйЎөйқўеҫҲеҸҜиғҪеңЁиҝҷдәӣжҹҘиҜўзҡ„жҗңзҙўз»“жһңж–№йқўеҒҡеҫ—еҘҪгҖӮ
继з»ӯпјҢеҪ“д»Һж•ҙдҪ“дёҠзңӢз«ҷзӮ№пјҢж №жҚ®е®һдҪ“еҗҚз§°е’Ңе®һдҪ“зұ»еһӢпјҢеҮәзҺ°дәҶд»ҘдёӢдё»йўҳгҖӮ
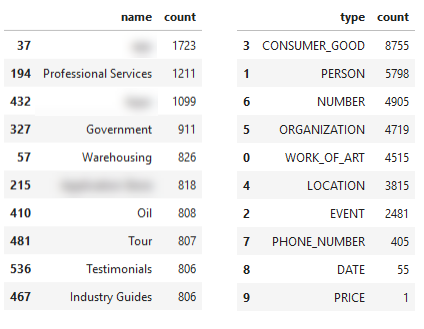
еҹәдәҺе®һдҪ“еҗҚз§°е’Ңе®һдҪ“зұ»еһӢзҡ„дё»йўҳ
жҲ‘жЁЎзіҠдәҶеҮ дёӘзңӢиө·жқҘиҝҮдәҺе…·дҪ“зҡ„з»“жһңпјҢд»ҘжҺ©зӣ–зҪ‘з«ҷзҡ„иә«д»ҪгҖӮд»Һдё»йўҳдёҠи®ІпјҢеҗҚз§°дҝЎжҒҜжҳҜеңЁдҪ пјҲжҲ–з«һдәүеҜ№жүӢпјүзҡ„зҪ‘з«ҷдёҠеұҖйғЁжҹҘзңӢе…¶ж ёеҝғдё»йўҳзҡ„дёҖз§ҚеҘҪж–№жі•гҖӮиҝҷж ·еҒҡд»…еҹәдәҺзӨәдҫӢзҪ‘з«ҷзҡ„жҺ’еҗҚзҪ‘еқҖпјҢиҖҢдёҚжҳҜеҹәдәҺжүҖжңүзҪ‘з«ҷзҡ„еҸҜиғҪзҪ‘еқҖпјҲеӣ дёә Search Console ж•°жҚ®д»…и®°еҪ• Google дёӯеұ•зӨәзҡ„йЎөйқўпјүпјҢдҪҶжҳҜз»“жһңдјҡеҫҲжңүи¶ЈпјҢе°Өе…¶жҳҜеҪ“дҪ дҪҝз”ЁеғҸ Ahrefs д№Ӣзұ»зҡ„е·Ҙе…·жҸҗеҸ–дёҖдёӘзҪ‘з«ҷзҡ„дё»иҰҒжҺ’еҗҚ URLпјҢиҜҘе·Ҙе…·дјҡи·ҹиёӘи®ёеӨҡжҹҘиҜўд»ҘеҸҠиҝҷдәӣжҹҘиҜўзҡ„ Google жҗңзҙўз»“жһңгҖӮ
е®һдҪ“ж•°жҚ®дёӯеҸҰдёҖдёӘжңүи¶Јзҡ„йғЁеҲҶжҳҜж Үи®°дёә вҖңCONSUMER_GOODвҖқ зҡ„е®һдҪ“еҖҫеҗ‘дәҺ вҖңзңӢиө·жқҘвҖқ еғҸжҲ‘еңЁзңӢеҲ° вҖңзҹҘиҜҶз»“жһңвҖқзҡ„з»“жһңпјҢеҚійЎөйқўеҸідҫ§зҡ„ Google жҗңзҙўз»“жһңгҖӮ
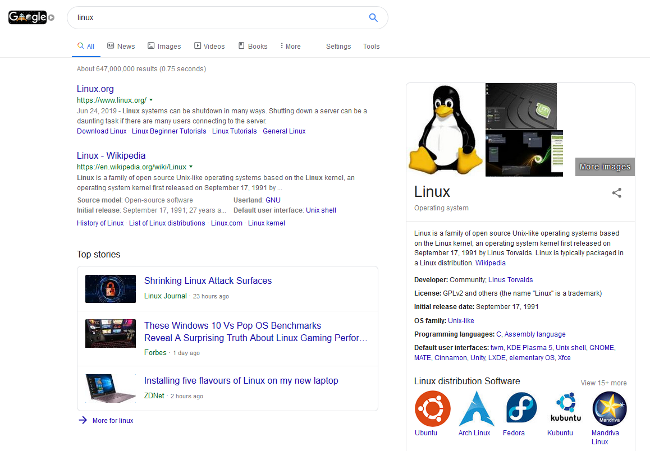
Google жҗңзҙўз»“жһң
еңЁжҲ‘们зҡ„ж•°жҚ®йӣҶдёӯе…·жңүдёүдёӘжҲ–дёүдёӘд»ҘдёҠе…ій”®еӯ—зҡ„ вҖңConsumer GoodпјҲж¶Ҳиҙ№жҖ§е•Ҷе“ҒпјүвҖқ е®һдҪ“еҗҚз§°дёӯпјҢжңү 5.8пј… зҡ„зҹҘиҜҶз»“жһңдёҺ Google еҜ№иҜҘе®һдҪ“е‘ҪеҗҚзҡ„з»“жһңзӣёеҗҢгҖӮиҝҷж„Ҹе‘ізқҖпјҢеҰӮжһңдҪ еңЁ Google дёӯжҗңзҙўжңҜиҜӯжҲ–зҹӯиҜӯпјҢеҲҷеҸідҫ§зҡ„жЎҶпјҲдҫӢеҰӮпјҢдёҠйқўжҳҫзӨә Linux зҡ„зҹҘиҜҶз»“жһңпјүе°ҶжҳҫзӨәеңЁжҗңзҙўз»“жһңйЎөйқўдёӯгҖӮз”ұдәҺ Google дјҡ вҖңжҢ‘йҖүвҖқ д»ЈиЎЁе®һдҪ“зҡ„зӨәдҫӢзҪ‘йЎөпјҢеӣ жӯӨиҝҷжҳҜдёҖдёӘеҫҲеҘҪзҡ„жңәдјҡпјҢеҸҜд»ҘеңЁжҗңзҙўз»“жһңдёӯиҜҶеҲ«еҮәе…·жңүе”ҜдёҖзү№еҫҒзҡ„жңәдјҡгҖӮеҗҢж ·жңүи¶Јзҡ„жҳҜпјҢ5.8пј… зҡ„еңЁ Google дёӯжҳҫзӨәиҝҷдәӣзҹҘиҜҶз»“жһңеҗҚз§°дёӯпјҢжІЎжңүдёҖдёӘе®һдҪ“зҡ„з»ҙеҹәзҷҫ科 URL д»ҺиҮӘ然иҜӯиЁҖ API дёӯиҝ”еӣһгҖӮиҝҷеҫҲжңүи¶ЈпјҢеҖјеҫ—иҝӣиЎҢйўқеӨ–зҡ„еҲҶжһҗгҖӮиҝҷе°ҶжҳҜйқһеёёжңүз”Ёзҡ„пјҢзү№еҲ«жҳҜеҜ№дәҺдј з»ҹзҡ„е…ЁзҗғжҺ’еҗҚи·ҹиёӘе·Ҙе…·пјҲеҰӮ Ahrefsпјүж•°жҚ®еә“дёӯжІЎжңүзҡ„жӣҙж·ұеҘҘзҡ„дё»йўҳгҖӮ
еҰӮеүҚжүҖиҝ°пјҢзҹҘиҜҶз»“жһңеҜ№дәҺйӮЈдәӣеёҢжңӣиҮӘе·ұзҡ„еҶ…е®№еңЁ Google дёӯ被收еҪ•зҡ„зҪ‘з«ҷжүҖжңүиҖ…жқҘиҜҙжҳҜйқһеёёйҮҚиҰҒзҡ„пјҢеӣ дёәе®ғ们еңЁжЎҢйқўжҗңзҙўдёӯеҠ ејәй«ҳдә®жҳҫзӨәгҖӮеҒҮи®ҫпјҢе®ғ们д№ҹеҫҲеҸҜиғҪдёҺ Google Discover зҡ„зҹҘиҜҶеә“дё»йўҳдҝқжҢҒдёҖиҮҙпјҢиҝҷжҳҜдёҖж¬ҫйҖӮз”ЁдәҺ Android е’Ң iOS зҡ„дә§е“ҒпјҢе®ғиҜ•еӣҫж №жҚ®з”ЁжҲ·ж„ҹе…ҙи¶ЈдҪҶжІЎжңүжҳҺзЎ®жҗңзҙўзҡ„дё»йўҳдёәз”ЁжҲ·жө®зҺ°еҶ…е®№гҖӮ
жң¬ж–Үд»Ӣз»ҚдәҶ Google зҡ„иҮӘ然иҜӯиЁҖ APIпјҢеҲҶдә«дәҶдёҖдәӣд»Јз ҒпјҢе№¶з ”з©¶дәҶжӯӨ API еҜ№зҪ‘з«ҷжүҖжңүиҖ…еҸҜиғҪжңүз”Ёзҡ„ж–№ејҸгҖӮе…ій”®иҰҒзӮ№жҳҜпјҡ
еӯҰд№ дҪҝз”Ё Python е’Ң Jupyter 笔记жң¬еҸҜд»ҘдёәдҪ зҡ„ж•°жҚ®ж”¶йӣҶд»»еҠЎжү“ејҖеҲ°дёҖдёӘз”ұд»Өдәәйҡҫд»ҘзҪ®дҝЎзҡ„иҒӘжҳҺе’ҢжңүжүҚеҚҺзҡ„дәәе»әз«Ӣзҡ„дёҚеҸҜжҖқи®®зҡ„ API е’ҢејҖжәҗйЎ№зӣ®пјҲеҰӮ Pandas е’Ң NumPyпјүзҡ„дё–з•ҢгҖӮ
Python е…Ғи®ёжҲ‘дёәдәҶдёҖдёӘзү№е®ҡзӣ®зҡ„еҝ«йҖҹжҸҗеҸ–е’ҢжөӢиҜ•жңүе…і API еҖјзҡ„еҒҮи®ҫгҖӮ
йҖҡиҝҮ Google зҡ„еҲҶзұ» API дј йҖ’зҪ‘з«ҷйЎөйқўеҸҜиғҪжҳҜдёҖйЎ№еҫҲеҘҪзҡ„жЈҖжҹҘпјҢд»ҘзЎ®дҝқе…¶еҶ…е®№еҲҶи§ЈжҲҗжӯЈзЎ®зҡ„дё»йўҳеҲҶзұ»гҖӮеҜ№дәҺз«һдәүеҜ№жүӢзҡ„зҪ‘з«ҷжү§иЎҢжӯӨж“ҚдҪңиҝҳеҸҜд»ҘжҸҗдҫӣжңүе…іеңЁдҪ•еӨ„иҝӣиЎҢи°ғж•ҙжҲ–еҲӣе»әеҶ…е®№зҡ„жҢҮеҜјгҖӮ
еҜ№дәҺзӨәдҫӢзҪ‘з«ҷпјҢGoogle зҡ„жғ…ж„ҹиҜ„еҲҶдјјд№Һ并дёҚжҳҜдёҖдёӘжңүи¶Јзҡ„жҢҮж ҮпјҢдҪҶжҳҜеҜ№дәҺж–°й—»жҲ–еҹәдәҺж„Ҹи§Ғзҡ„зҪ‘з«ҷпјҢе®ғеҸҜиғҪжҳҜдёҖдёӘжңүи¶Јзҡ„жҢҮж ҮгҖӮ
Google еҸ‘зҺ°зҡ„е®һдҪ“д»Һж•ҙдҪ“дёҠжҸҗдҫӣдәҶжӣҙз»ҶеҢ–зҡ„зҪ‘з«ҷзҡ„дё»йўҳзә§еҲ«и§ҶеӣҫпјҢ并且еғҸеҲҶзұ»дёҖж ·пјҢеңЁз«һдәүжҖ§еҶ…е®№еҲҶжһҗдёӯдҪҝз”Ёе°Ҷйқһеёёжңүи¶ЈгҖӮ
е®һдҪ“еҸҜд»Ҙеё®еҠ©е®ҡд№үжңәдјҡпјҢдҪҝдҪ зҡ„еҶ…е®№еҸҜд»ҘдёҺжҗңзҙўз»“жһңжҲ– Google Discover з»“жһңдёӯзҡ„ Google зҹҘиҜҶеқ—дҝқжҢҒдёҖиҮҙгҖӮжҲ‘们е°Ҷ 5.8пј… зҡ„з»“жһңи®ҫзҪ®дёәжӣҙй•ҝзҡ„пјҲеӯ—и®Ўж•°пјүвҖңConsumer GoodsпјҲж¶Ҳиҙ№е•Ҷе“ҒпјүвҖқ е®һдҪ“пјҢжҳҫзӨәиҝҷдәӣз»“жһңпјҢеҜ№дәҺжҹҗдәӣзҪ‘з«ҷжқҘиҜҙпјҢеҸҜиғҪжңүжңәдјҡжӣҙеҘҪең°дјҳеҢ–иҝҷдәӣе®һдҪ“зҡ„йЎөйқўжҳҫи‘—жҖ§еҲҶж•°пјҢд»ҺиҖҢжңүжӣҙеҘҪзҡ„жңәдјҡеңЁ Google жҗңзҙўз»“жһңжҲ– Google Discovers е»әи®®дёӯжҠ“дҪҸиҝҷдёӘйҮҚиҰҒдҪңз”Ёзҡ„дҪҚзҪ®гҖӮ
ж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҢд»ҘдёҠе°ұжҳҜвҖңжҖҺд№Ҳз”Ё Python еӯҰд№ Google зҡ„иҮӘ然иҜӯиЁҖ APIвҖқзҡ„еҶ…е®№дәҶпјҢз»ҸиҝҮжң¬ж–Үзҡ„еӯҰд№ еҗҺпјҢзӣёдҝЎеӨ§е®¶еҜ№жҖҺд№Ҳз”Ё Python еӯҰд№ Google зҡ„иҮӘ然иҜӯиЁҖ APIиҝҷдёҖй—®йўҳжңүдәҶжӣҙж·ұеҲ»зҡ„дҪ“дјҡпјҢе…·дҪ“дҪҝз”Ёжғ…еҶөиҝҳйңҖиҰҒеӨ§е®¶е®һи·өйӘҢиҜҒгҖӮиҝҷйҮҢжҳҜдәҝйҖҹдә‘пјҢе°Ҹзј–е°ҶдёәеӨ§е®¶жҺЁйҖҒжӣҙеӨҡзӣёе…ізҹҘиҜҶзӮ№зҡ„ж–Үз« пјҢж¬ўиҝҺе…іжіЁпјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ