您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章主要介绍了Python中csv模块怎么用,具有一定借鉴价值,感兴趣的朋友可以参考下,希望大家阅读完这篇文章之后大有收获,下面让小编带着大家一起了解一下。
CSV (Comma Separated Values) ,即逗号分隔值(也称字符分隔值,因为分隔符可以不是逗号),是一种常用的文本
格式,用以存储表格数据,包括数字或者字符。很多程序在处理数据时都会碰到csv这种格式的文件,它的使用是比
较广泛的(Kaggle上一些题目提供的数据就是csv格式),csv虽然使用广泛,但却没有通用的标准,所以在处理csv
格式时常常会碰到麻烦,幸好python内置了csv模块。下面简单介绍csv模块中最常用的一些函数。
reader(csvfile, dialect='excel', **fmtparams)
参数说明:
csvfile,必须是支持迭代(Iterator)的对象,可以是文件(file)对象或者列表(list)对象,如果是文件对
象,打开时需要加"b"标志参数。
dialect,编码风格,默认为excel的风格,也就是用逗号(,)分隔,dialect 方式也支持自定义,通过调用register_dialect方法来注册,下文会提到。
fmtparam,格式化参数,用来覆盖之前dialect对象指定的编码风格。
import csv
with open('test.csv','rb') as myFile:
lines=csv.reader(myFile)
for line in lines:
print line'test.csv'是文件名,‘rb'中的r表示“读”模式,因为是文件对象,所以加‘b'。open()返回了一个文件对象
myFile,reader(myFile)只传入了第一个参数,另外两个参数采用缺省值,即以excel风格读入。reader()返回一个
reader对象lines,lines是一个list,当调用它的方法lines.next()时,会返回一个string。上面程序的效果是将csv
文件中的文本按行打印,每一行的元素都是以逗号分隔符','分隔得来。
在我的test.csv文件中,存储的数据如图:
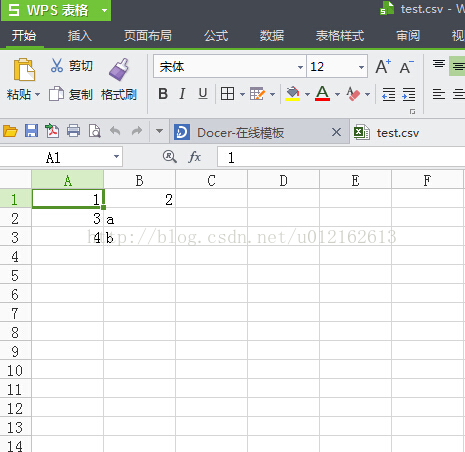
程序输出:
['1', '2']
['3', 'a']
['4', 'b']
补充:reader对象还提供一些方法:line_num、dialect、next()
writer(csvfile, dialect='excel', **fmtparams)
参数的意义同上,这里不赘述,直接上例程:
with open('t.csv','wb') as myFile:
myWriter=csv.writer(myFile)
myWriter.writerow([7,'g'])
myWriter.writerow([8,'h'])
myList=[[1,2,3],[4,5,6]]
myWriter.writerows(myList)'w'表示写模式。
首先open()函数打开当前路径下的名字为't.csv'的文件,如果不存在这个文件,则创建它,返回myFile文件对象。
csv.writer(myFile)返回writer对象myWriter。
writerow()方法是一行一行写入,writerows方法是一次写入多行。
注意:如果文件't.csv'事先存在,调用writer函数会先清空原文件中的文本,再执行writerow/writerows方法。
补充:除了writerow、writerows,writer对象还提供了其他一些方法:writeheader、dialect
register_dialect(name, [dialect, ]**fmtparams)
这个函数是用来自定义dialect的。
参数说明:
name,你所自定义的dialect的名字,比如默认的是'excel',你可以定义成'mydialect'
[dialect, ]**fmtparams,dialect格式参数,有delimiter(分隔符,默认的就是逗号)、quotechar、
quoting等等,可以参考Dialects and Formatting Parameters
csv.register_dialect('mydialect',delimiter='|', quoting=csv.QUOTE_ALL)上面一行程序自定义了一个命名为mydialect的dialect,参数只设置了delimiter和quoting这两个,其他的仍然采用
默认值,其中以'|'为分隔符。接下来我们就可以像使用'excel'一样来使用'mydialect'了。我们来看看效果:
在我test.csv中存储如下数据:
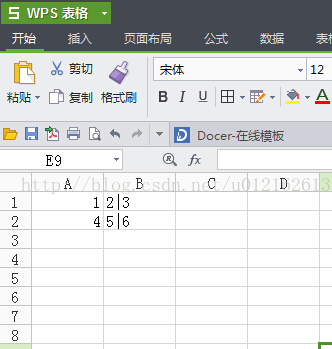
以'mydialect'风格打印:
with open('test.csv','rb') as myFile:
lines=csv.reader(myFile,'mydialect')
print lines.line_num
for line in lines:
print line输出:
['1,2', '3']
['4,5', '6']
可以看到,现在是以'|'为分隔符,1和2合成了一个字符串(因为1和2之间的分隔符是逗号,而mydialect风格的分隔
符是'|'),3单独一个字符串。
对于writer()函数,同样可以传入mydialect作为参数,这里不赘述。
unregister_dialect(name)
这个函数用于注销自定义的dialect
此外,csv模块还提供get_dialect(name)、list_dialects()、field_size_limit([new_limit])等函数,这些都比较
简单,可以自己试试。比如list_dialects()函数会列出当前csv模块里所有的dialect:
print csv.list_dialects()
输出:
['excel-tab', 'excel', 'mydialect']
'mydialect'是自定义的,'excel-tab', 'excel'都是自带的dialect,其中'excel-tab'跟'excel'差不多,
只不过它以tab为分隔符。
csv模块还定义了
一些类:DictReader、DictWriter、Dialect等,DictReader和DictWriter类似于reader和writer。
一些常量:QUOTE_ALL、QUOTE_MINIMAL、.QUOTE_NONNUMERIC等,这些常量可以作为Dialects and Formatting Parameters的值。
先写到这,其他的以后用到再更新。
感谢你能够认真阅读完这篇文章,希望小编分享的“Python中csv模块怎么用”这篇文章对大家有帮助,同时也希望大家多多支持亿速云,关注亿速云行业资讯频道,更多相关知识等着你来学习!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。