您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
本篇内容主要讲解“CSS中的选择器是什么”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“CSS中的选择器是什么”吧!
我们先了解一下选择器的语法,然后深入了解背后相关的特性。
简单选择器
星号 —— *
通用选择器,可以选择任何的元素
类型选择器|type selector —— div svg|a
也叫做 type selector, 也就是说它选择的是元素中的 tagName (标签名) 属性
tagName 也是我们平常最常用的的选择器
但是因为 HTML 也是有命名空间的,它主要有三个:HTML、SVG、MathML
如果我们想选 SVG 或者 MathML 里面特定的元素,我们就必须要用到单竖线 | ,CSS选择器里面单竖线是一个命名空间的分隔符,而HTML 里面命名空间分隔符是 冒号 : 。然后前面说到的命名空间是需要 @namespace 来声明的,他们是配合使用的,但是这个命名空间的使用不是很频繁,它的存在只是为了一个完备性考虑,HTML 和 SVG当中唯一一个重叠的元素名就只有一个 a
所以我们可以认为,类型选择器就是一个简单的文本字符串即可
类选择器|class selector —— .class-name
以 . 开头的选择器就是 class 选择器,也是最经典之一
它会选择一个 class,我们也可以用空格做分隔符来制定多个 class 的
这个 .class 只要匹配中其中一个就可以了
ID 选择器|id selector —— #id
以 # 开头加上 ID 名选中一个 ID
这个是严格匹配的
ID 里面是可以加减号或者是其他符号的
属性选择器|attribute selector —— [attr=value]
它包括了 class 属性选择器和 id 选择器
这个选择器的完整语法就是 attr=value,等于前面是属性名,后面是属性值
这里面的等号前面可以加 ~ 就表示像 class 一样,可以支持拿空格分隔的值的序列:attr~=value
如果在等号前面加单竖线,表示这个属性以这个值开头即可:attr|=value
如果我们对优先级没有特殊要求的话,我们理论上是可以用属性选择器来代替 class 选择器和 id 选择器的
伪类 —— :hover
以 : 开头的,它主要是一些属性的特殊状态
这个跟我们写的 HTML 没有关系,多半来自于交互和效果
一些伪类选择器是带有函数的伪类选择器,这些我们都是可以去使用伪类来解决的
伪元素选择器 —— ::before
一般来说是以 :: 双冒号开头的
实际上是支持使用单冒号的,但是我们提倡双冒号这个写法
因为我们可以一眼就看出这个是伪元素选择器,和伪类区分开来
伪元素属于选中一些原本不存在的元素
如果我们不选择它们,这个地方就不存在这个元素了,选择后就会多了一个元素
复合选择器
<简单选择器><简单选择器><简单选择器>
* 或则 div 必须写在最前面
首先复合选择器是以多个简单选择器构成的,只要把简单选择器挨着写就变成一个复合选择器了。它的语义就是我们选中的元素必须同时 match 几个简单选择器,形成了 “与” 的关系。
复杂选择器
复合选择器中间用连接符就可以变成复杂选择器了,复杂选择器是针对一个元素的结构来进行选择的。
<复合选择器> <复合选择器> —— 子孙选择器,单个元素必须要有空格左边的一个父级节点或者祖先节点
<复合选择器> “>” <复合选择器> —— 父子选择器,必须是元素直接的上级父元素
<复合选择器> “~” <复合选择器> —— 邻接关系选择器
<复合选择器> “+” <复合选择器> —— 邻接关系选择器
<复合选择器> “||” <复合选择器> —— 双竖线是 Selector Level 4 才有的,当我们做表格的时候可以选中每一个列
在之前的 《实战中学习浏览器工作原理》中也接触过选择器的优先级的概念了。这里我们深入了解一下选择器优先级的概念。
简单选择器计数
我们从一个案例出发,选择器优先级是对一个选择器里面包含的所有简单选择器进行计数。所以选择器列表不被视为一个完整的选择器(也就是逗号分隔的选择器),因为选择器列表中间是以逗号分隔开的复杂选择器来进行简单选择器计数的。
例子:
#id div.a#id
这个里面包含了两个 ID 选择器,一个类型选择器和一个 class 选择器
根据一个 specificity 数组的计数 [inline-style个数,ID 选择器个数,class 选择器个数,tagName 选择器个数]
我们这个例子就会得出 specificity = [0, 2, 1, 1]
在选择器的标准里面,有一个这样的描述,我们会采用一个 N 进制来表示选择器优先级
所以 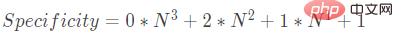
我们只需要取一个大的 N,算出来就是选择器的优先级了
比如说我们用
N=1000000,那么 S=2000001000001,这个就是这个例子中选择器的 specificity 优先级了
像 IE 的老版本 IE6,因为为了节省内存 N 取值不够大,取了一个 255 为 N 的值,所以就发生了非常好玩的事情,比如说到值我们 256 个 class 就相当于一个 ID。后来我们大部分的浏览器都选择了 65536,基本上就再也没有发生过超过额度的事情了。因为标准里面只说采用一个比较大的值就可以,但是我们要考虑内存暂用的问题,所以我们会取一个 16 进制上比较整的数,一般来说都是 256 的整次幂(因为 256 是刚好是一个字节)。
伪类其实是一类非常多的内容的简单选择器。
链接/行为
:any-link —— 可以匹配任何的超链接
:link —— 还没有访问过的超链接
:link :visited —— 匹配所有被访问过的超链接
:hover —— 用户鼠标放在元素上之后的状态,之前是只能对超链接生效,但是现在是可以在很多元素中使用了
:active —— 之前也是只对超链接生效的,点击之后当前的链接就会生效
:focus —— 就是焦点在这个元素中的状态,一般用于 input 标签,其实任何可以获得焦点的元素都可以使用
:target —— 链接到当前的目标,这个不是给超链接用的,是给锚点的 a 标签使用的,就是当前的 HASH指向了当前的 a 标签的话就会激活 target 伪类
一旦使用了
:link或者:visited之后,我们就再也无法对这个元素的文字颜色之外的属性进行更改。为什么要这样设计呢?因为一旦我们使用了 layout 相关的属性,比如说我们给:visited的尺寸加大一点,它就会影响排班。这样我们就可以通过 JavaScript 的 API 去获取这个链接是否被访问过了。但是如果我们能获得链接是否被访问过了,那么我们就可以知道用户访问过那些网站了,这个对于浏览器的安全性来说是一个致命打击。所以这里也提醒一下大家,不要以为做一些表现性的东西于安全没有任何关系,其实安全性是一个综合的考量。CSS 它也能造成安全漏洞的。
树结构
:empty —— 这个元素是否有子元素
:nth-child() —— 是父元素的第几个儿子(child)
:nth-last-child() —— 于 nth-child 一样,只不过从后往前数
:first-child :last-child :only-child
:nth-child是一个非常复杂的伪类,里面支持一种语法,比如说可以在括号里面写奇偶event或者odd,也可以写4N+1、3N-1,这个就会分别匹配到整数的形态。因为这个是一个比较复杂的选择器,我们就不要在里面写过于复杂的表达式了,只用它来处理一下奇偶,逢3个多1个,逢4个多1个等等这种表达式。
其实
empty、nth-last-child、last-child、only-child这两个选择器,是破坏了我们之前在 《实现中学习浏览器原理》中的说到的 CSS 计算的时机问题。我们可以想象一下,当我们在开始标签计算的时候,肯定不知道它有没有子标签。empty影响不是特别大,但是last-child的这个关系其实还是影响蛮大的。所以浏览在实现这些的时候是做了特别处理的,要么就是浏览器实现的不是特别好,要么就是浏览器要耗费更大的性能来得以实现。所以建议大家尽量避免大量使用这些。
逻辑型
:not 伪类 —— 主流浏览器只支持简单选择器的序列(复合选择器)我们是没有办法在里面写复杂选择器的语法的
:where :has —— 在 CSS Level 4 加入了这两个非常强大了逻辑型伪类
这里还是像温馨建议一下大家,不建议大家把选择器写的过于复杂,我们很多时候都可以多加一点 class 去解决的。如果我们的选择器写的过于复杂,某种程度上意味着 HTML 结构写的不合理。我们不光是为了给浏览器工程省麻烦,也不光是为了性能,而是为了我们自身的代码结构考虑,所以我们不应该出现过于复杂的选择器。
一共分为 4 种
::before
::after
::first-line
::first-letter
::before 和 ::after 是在元素的内容的前和后,插入一个伪元素。一旦应用了 before 和 after 的属性,declaration(声明)里面就可以写一个叫做 content 的属性(一般元素是没有办法写 content 的属性的)。content 的属性就像一个真正的 DOM 元素一样,可以去生成盒,可以参与后续的排版和渲染了。所以我们可以给他声明 border、background等这样的属性。
可以理解为:伪元素向界面上添加了一个不存在的元素。
::first-line 和 ::first-letter 的机制就不一样了。这两个其实原本就存在 content 之中。他们顾名思义就是 选中“第一行” 和选中 “第一个字母”。它们 不是一个不存在的元素,是把一部分的文本括了起来让我们可以对它进行一些处理。
before 和 after
在我们概念里,我们可以认为带有 before 伪元素的选择器,会给他实际选中的元素的内容前面增加了一个元素,我们只需要通过他的 content 属性为它添加文本内容即可。(这里我们也可以给伪元素赋予 content: '' 为空的)所以我们可以任何的给 before 和 after 指定 display 属性,和不同元素一样比较自由的。
我们在实现一些组建的时候,也会常常使用这种不污染 DOM 树,但是能实际创造视觉效果的方式来给页面添加一些修饰性的内容。
<div> <::before/> content content content content content content content content content content content content content content content content <::after/> </div>
first-letter 和 first-line
first-letter 相当于我们有一个元素把内容里面的第一个字母给括了起来。这个 first-letter 我们是可以任意声明各种不同的属性的,但是我们是无法改变它的 content 的。我们应该都看到过报纸上的第一个字母会比较大,然后会游离出来的效果,这个在 CSS 里面我们就可以用 ::first-letter的伪元素选择器了。使用这个来实现相比用 JavaScript 来实现就会更加稳定和代码更加优雅一些。
<div> <::first-letter>c</::first-letter>ontent content content content content content content content content content content content content content content content </div>
first-line 是针对排版之后的 line,其实跟我们源码里面的 first line 没有任何的关系的。假如说我们的浏览器提供的渲染的宽度不同,first-line 在两个环境里面它最终括住的元素数量就不一样多了。所以我们用这个选择器的时候需要去根据需求的情况使用,很有可能在我们开发机器上和用户的机器上渲染出来的效果是不一样的!
<div> <::first-line>content content content content content</::first-line> content content content content content content content content content content content content </div>
这两个选择器其实可用的属性也是有区别的:
first-line 可用属性
font 系列
color 系列
background 系列
word-spacing
letter-spacing
text-decoration
text-transform
line-height
first-letter 可用属性
font 系列
color 系列
background 系列
text-decoration
text-transform
letter-spacing
word-spacing
line-height
float
vertical-align
盒模型系列:margin, padding, border
编写一个 match 函数。它接受两个参数,第一个参数是一个选择器字符串性质,第二个是一个 HTML 元素。这个元素你可以认为它一定会在一棵 DOM 树里面。通过选择器和 DOM 元素来判断,当前的元素是否能够匹配到我们的选择器。(不能使用任何内置的浏览器的函数,仅通过 DOM 的 parent 和 children 这些 API,来判断一个元素是否能够跟一个选择器相匹配。)以下是一个调用的例子。
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Match Example —— by 三钻</title>
</head>
<body>
<div>
<b>
<div class="class classA" id="id">content</div>
</b>
</div>
</body>
<script language="javascript">
/**
* 匹配选择器
*/
function matchSelectors(selector, element) {
// 先匹配当前元素是否匹配
let tagSelector = selector.match(/^[\w]+/gm);
let idSelectors = selector.match(/(?<=#)([\w\d\-\_]+)/gm);
let classSelectors = selector.match(/(?<=\.)([\w\d\-\_]+)/gm);
/**
* 实现复合选择器,实现支持空格的 Class 选择器
* --------------------------------
*/
// 检查 tag name 是否匹配
if (tagSelector !== null) {
if (element.tagName.toLowerCase() !== tagSelector[0]) return false;
}
// 检测 id 是否匹配
if (idSelectors !== null) {
let attr = element.attributes['id'].value;
if (attr) {
for (let selector of idSelectors) {
if (attr.split(' ').indexOf(selector) === -1) return false;
}
}
}
// 检测 class 是否匹配
if (classSelectors !== null) {
let attr = element.attributes['class'].value;
if (attr) {
for (let selector of classSelectors) {
if (attr.split(' ').indexOf(selector) === -1) return false;
}
}
}
return true;
}
/**
* 匹配元素
*/
function match(selector, element) {
if (!selector || !element.attributes) return false;
let selectors = selector.split(' ').reverse();
if (!matchSelectors(selectors[0], element)) return false;
let curElement = element;
let matched = 1;
// 递归寻找父级元素匹配
while (curElement.parentElement !== null && matched < selectors.length) {
curElement = curElement.parentElement;
if (matchSelectors(selectors[matched], curElement)) matched++;
}
// 所有选择器匹配上为 匹配成功,否则是失败
if (matched !== selectors.length) return false;
return true;
}
let matchResult = match('div #id.class', document.getElementById('id'));
console.log('Match example by 三钻');
console.log('matchResult', matchResult);
</script>
</html>到此,相信大家对“CSS中的选择器是什么”有了更深的了解,不妨来实际操作一番吧!这里是亿速云网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。