您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章给大家分享的是有关spring data jpa开启批量插入、批量更新的示例分析的内容。小编觉得挺实用的,因此分享给大家做个参考,一起跟随小编过来看看吧。
ORM框架,最早我用的是jdbcTemplate,后来用了Mybatis,唯独没有用过JPA(Hibernate)系的,过去觉得Hibernate太重量级了,后来随着springboot和spring data jpa出来之后,让我觉得好像还不错,再加上谷歌趋势。。。
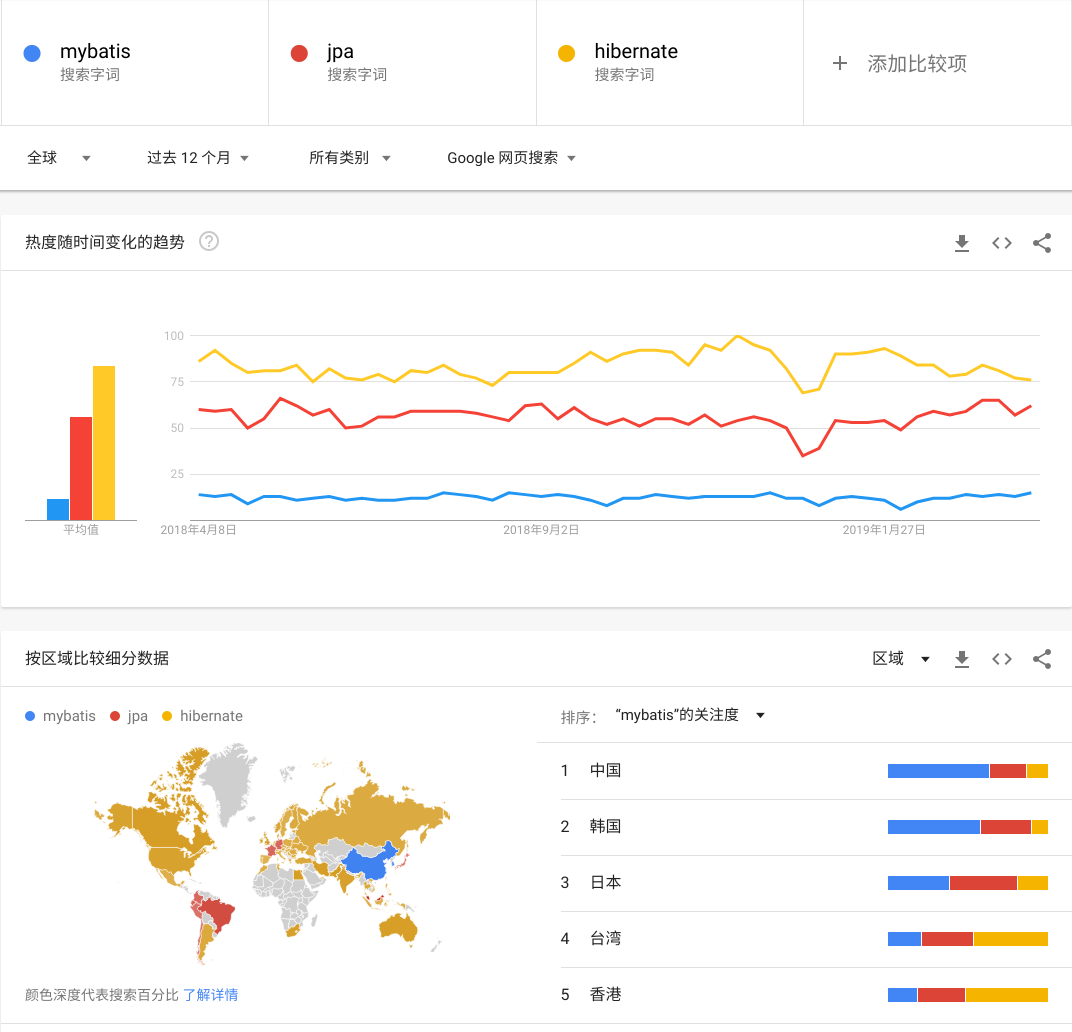
只有中日韩在大规模用Mybatis(我严重怀疑是中国的外包),所以就很奇怪,虽然说中国的IT技术在慢慢抬头了,但是这社会IT发展的主导目前看来还是美国、欧洲,这里JPA、Hibernate是绝对的主流,那么我觉得学习并以JPA为主开发是我接下来个人项目的选择。
那么经过几天简单的摸索,发现JPA可以说是非常的好用,尤其DDD设计思想简直完美符合现在springboot、微服务的设计理念(仅代表个人看法)。
不过呢,在使用过程中就会遇到一个问题,我之前写的爬虫插入效率非常低,一方面是因为我服务器上Mysql表现的极差,详情请看:
[评测]低配环境下,PostgresQL和Mysql读写性能简单对比(欢迎大家提出Mysql优化意见)
另外一方面,JPA的批量插入源码:
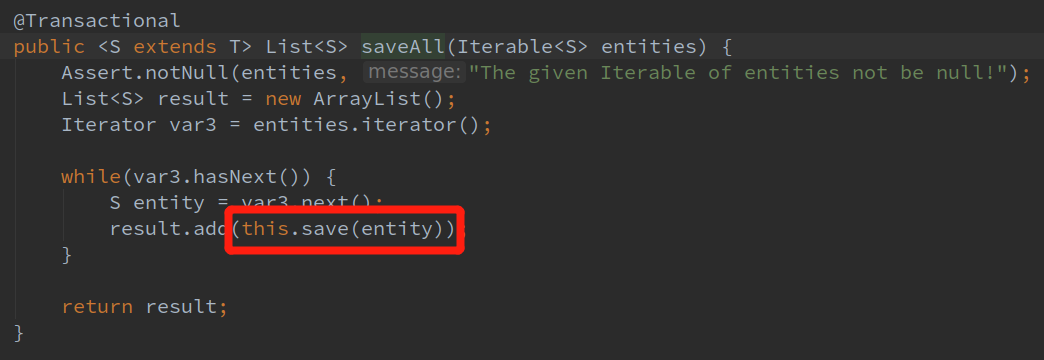
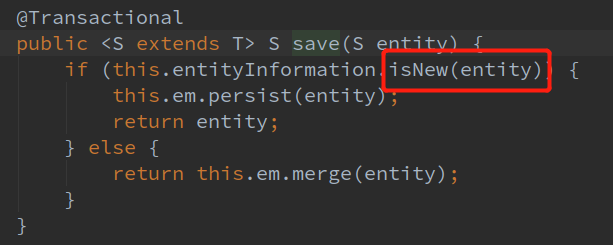
这saveAll明明就是循环调用save方法了啊,我们写个简单的测试插入数据方法试一下:
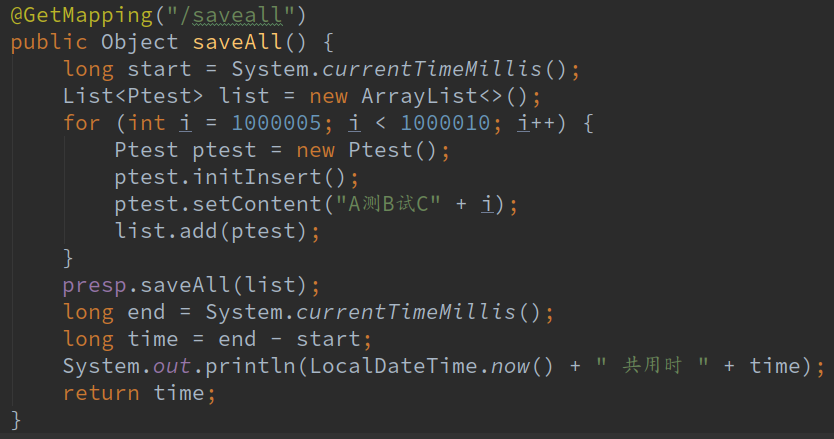
我们打开了Hibernate显示sql日志,看一下输出结果:
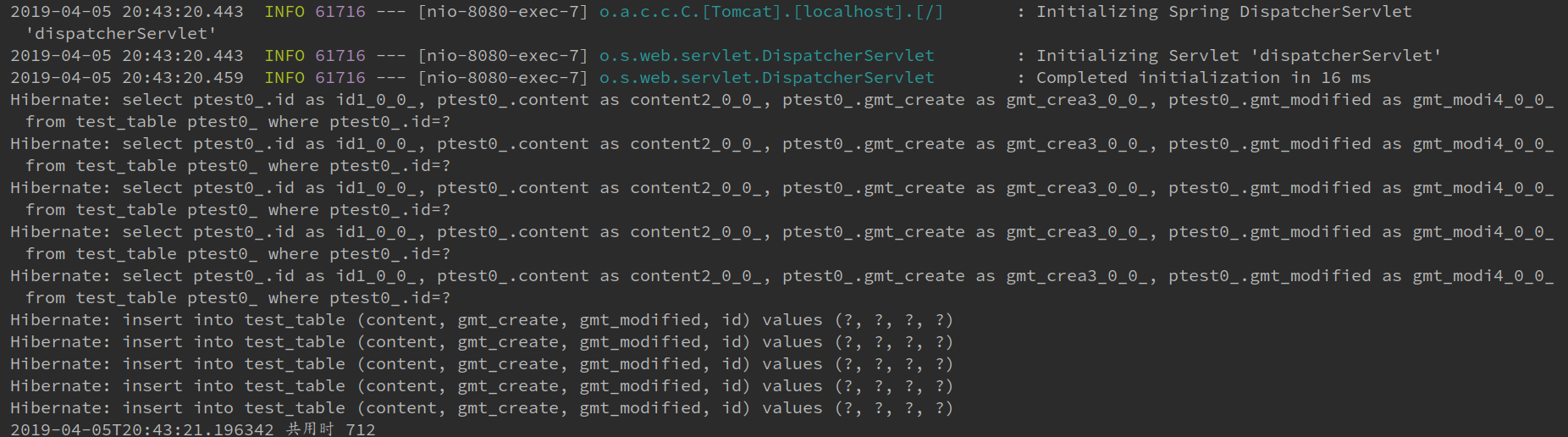
看日志,JPA是先把所有的数据全查出来了,如果数据库有就更新,没有就新增。我们再看一下阿里的监控,如果没有配可以按照这个文章里面的方法配
springboot2.0配置连接池(hikari、druid)
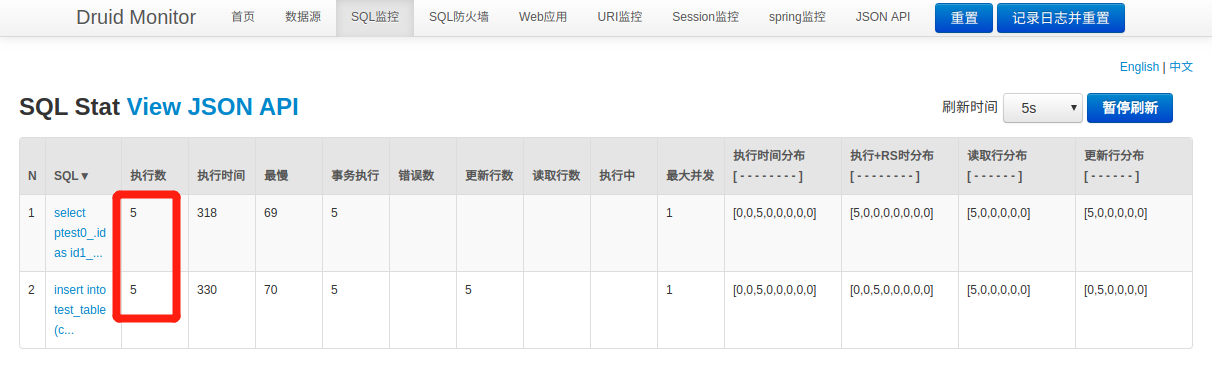
我插了5条数据,结果执行了10次sql,这特么。。。我不太能理解,可能是我太菜了?我跑脚本至少了成千上万条数据往库里插,这种写法得给我辣鸡数据库写死。
并且这样效率也太低了吧,查询不会用in?insert不会拼sql?并且很多场景我自己能控制是插入还是新增,我根本不需要你给我校验一次,我只想安安静静的插数据,那么有没有办法呢?有的。
在配置文件里加入:
spring.jpa.properties.hibernate.jdbc.batch_size=500 spring.jpa.properties.hibernate.jdbc.batch_versioned_data=true spring.jpa.properties.hibernate.order_inserts=true spring.jpa.properties.hibernate.order_updates =true
这个batch size建议设置成你数据库每秒最大写入数/2 ,没有理由只是我自己感觉这样好一点。。。
自己在repository里面定义两个接口 batchSave,batchUpdate并实现:
@Override
@Transactional
public <S extends T> Iterable<S> batchSave(Iterable<S> var1) {
Iterator<S> iterator = var1.iterator();
int index = 0;
while (iterator.hasNext()){
em.persist(iterator.next());
index++;
if (index % BATCH_SIZE == 0){
em.flush();
em.clear();
}
}
if (index % BATCH_SIZE != 0){
em.flush();
em.clear();
}
return var1;
}@Override
public <S extends T> Iterable<S> batchUpdate(Iterable<S> var1) {
Iterator<S> iterator = var1.iterator();
int index = 0;
while (iterator.hasNext()){
em.merge(iterator.next());
index++;
if (index % BATCH_SIZE == 0){
em.flush();
em.clear();
}
}
if (index % BATCH_SIZE != 0){
em.flush();
em.clear();
}
return var1;
}然后对批量插入的入口稍作改动,改成刚刚自己实现的调用batchSave的方法
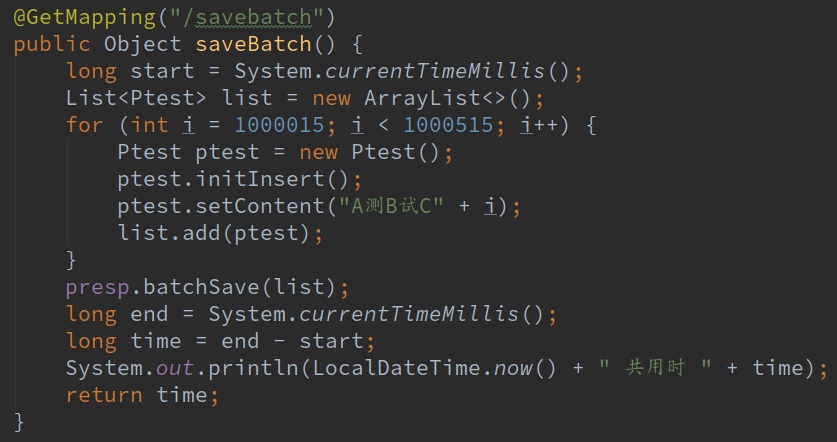
我们运行一下看看结果:
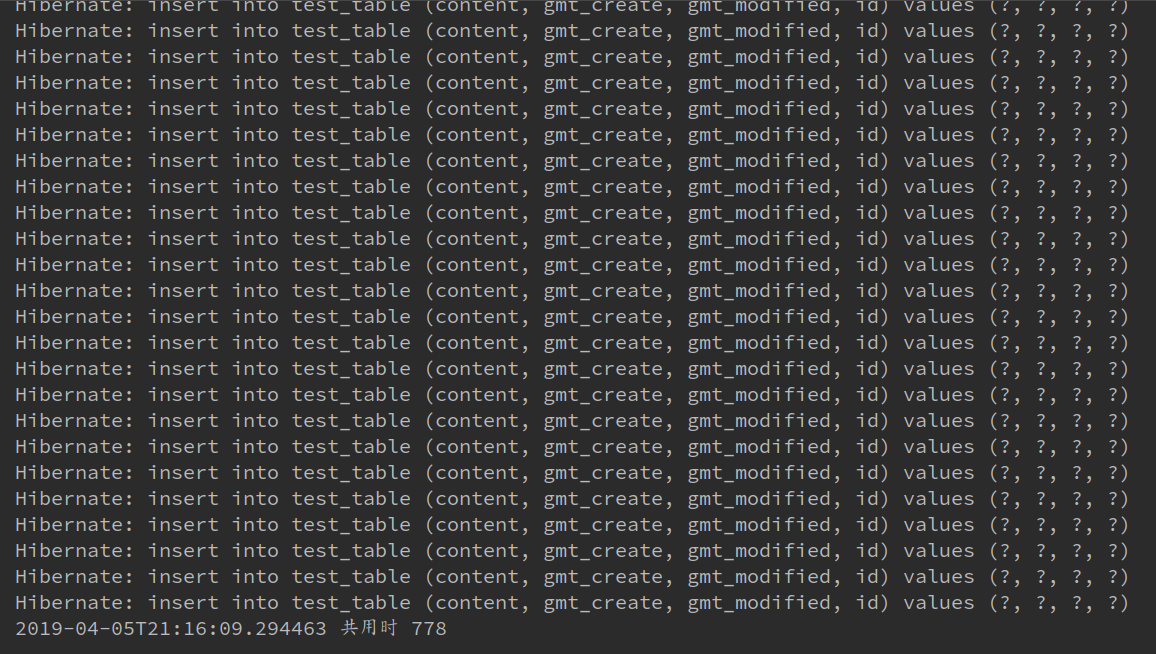
这次500条用了778毫秒,跟之前5条712相差不多,但是我们大家看到了,控制台打印了500条插入语句。。。这个导致我一度以为批量插入失败了,按理说看时间是成功了呀,所以后来配置了阿里的监控一看:

放心了,是Hibernate自己日志打印有问题,所以后来我给Hibernate日志打印关掉了,专心用阿里的druid
感谢各位的阅读!关于“spring data jpa开启批量插入、批量更新的示例分析”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,让大家可以学到更多知识,如果觉得文章不错,可以把它分享出去让更多的人看到吧!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。