жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жң¬зҜҮеҶ…е®№д»Ӣз»ҚдәҶвҖңmysqlеҹәзЎҖзҹҘиҜҶжұҮжҖ»вҖқзҡ„жңүе…ізҹҘиҜҶпјҢеңЁе®һйҷ…жЎҲдҫӢзҡ„ж“ҚдҪңиҝҮзЁӢдёӯпјҢдёҚе°‘дәәйғҪдјҡйҒҮеҲ°иҝҷж ·зҡ„еӣ°еўғпјҢжҺҘдёӢжқҘе°ұи®©е°Ҹзј–еёҰйўҶеӨ§е®¶еӯҰд№ дёҖдёӢеҰӮдҪ•еӨ„зҗҶиҝҷдәӣжғ…еҶөеҗ§пјҒеёҢжңӣеӨ§е®¶д»”з»Ҷйҳ…иҜ»пјҢиғҪеӨҹеӯҰжңүжүҖжҲҗпјҒ
select жҹҘиҜўз»“жһң еҰӮ: [еӯҰеҸ·,е№іеқҮжҲҗз»©пјҡз»„еҮҪж•°avg(жҲҗз»©)]
from д»Һе“Әеј иЎЁдёӯжҹҘжүҫж•°жҚ® еҰӮ:[ж¶үеҸҠеҲ°жҲҗз»©пјҡжҲҗз»©иЎЁscore]
where жҹҘиҜўжқЎд»¶ еҰӮ:[b.иҜҫзЁӢеҸ·='0003' and b.жҲҗз»©>80]
group by еҲҶз»„ еҰӮ:[жҜҸдёӘеӯҰз”ҹзҡ„е№іеқҮпјҡжҢүеӯҰеҸ·еҲҶз»„](oracle,SQL serverдёӯеҮәзҺ°еңЁselect еӯҗеҸҘеҗҺзҡ„йқһеҲҶз»„еҮҪж•°пјҢеҝ…йЎ»еҮәзҺ°еңЁgroup byеӯҗеҸҘеҗҺеҮәзҺ°),MySQLдёӯеҸҜд»ҘдёҚз”Ё
having еҜ№еҲҶз»„з»“жһңжҢҮе®ҡжқЎд»¶ еҰӮ:[еӨ§дәҺ60еҲҶ]
order by еҜ№жҹҘиҜўз»“жһңжҺ’еәҸ еҰӮ:[еўһеәҸ: жҲҗз»© ASC / йҷҚеәҸ: жҲҗз»© DESC];
limit дҪҝз”ЁlimtеӯҗеҸҘиҝ”еӣһtopNпјҲеҜ№еә”иҝҷдёӘй—®йўҳиҝ”еӣһзҡ„жҲҗз»©еүҚдёӨеҗҚпјүеҰӮ:[ limit 2 ==>д»Һ0зҙўеј•ејҖе§ӢиҜ»еҸ–2дёӘ]limit==>д»Һ0зҙўеј•ејҖе§Ӣ [0,N-1]
в‘ select * from table limit 2,1; //еҗ«д№үжҳҜи·іиҝҮ2жқЎеҸ–еҮә1жқЎж•°жҚ®пјҢlimitеҗҺйқўжҳҜд»Һ第2жқЎејҖе§ӢиҜ»пјҢиҜ»еҸ–1жқЎдҝЎжҒҜпјҢеҚіиҜ»еҸ–第3жқЎж•°жҚ® в‘Ў select * from table limit 2 offset 1; //еҗ«д№үжҳҜд»Һ第1жқЎпјҲдёҚеҢ…жӢ¬пјүж•°жҚ®ејҖе§ӢеҸ–еҮә2жқЎж•°жҚ®пјҢlimitеҗҺйқўи·ҹзҡ„жҳҜ2жқЎж•°жҚ®пјҢoffsetеҗҺйқўжҳҜд»Һ第1жқЎејҖе§ӢиҜ»еҸ–пјҢеҚіиҜ»еҸ–第2,3жқЎ
з»„еҮҪж•°: еҺ»йҮҚ distinct() з»ҹи®ЎжҖ»ж•°sum() и®Ўз®—дёӘж•°count() е№іеқҮж•°avg() жңҖеӨ§еҖјmax() жңҖе°Ҹж•°min()
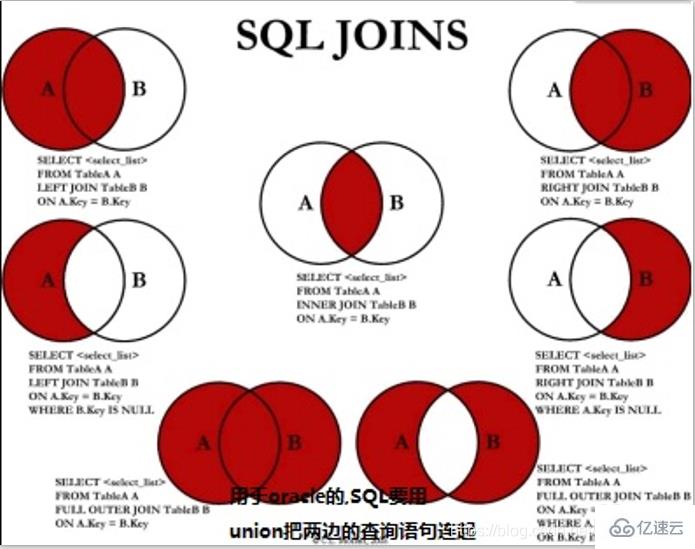
еӨҡиЎЁиҝһжҺҘ: еҶ…иҝһжҺҘ(зңҒз•Ҙй»ҳи®Өinner) join ...on..е·ҰиҝһжҺҘleft join tableName as b on a.key ==b.keyеҸіиҝһжҺҘright join иҝһжҺҘunion(ж— йҮҚеӨҚ(иҝҮж»ӨеҺ»йҮҚ))е’Ңunion all(жңүйҮҚеӨҚ[дёҚиҝҮж»ӨеҺ»йҮҚ])
union 并йӣҶ
union all(жңүйҮҚеӨҚ)
oracle(SQL server)ж•°жҚ®еә“
intersect дәӨйӣҶ
minus(except) зӣёеҮҸ(е·®йӣҶ)
oracle
дёҖгҖҒж•°жҚ®еә“еҜ№иұЎпјҡ иЎЁ(table) и§Ҷеӣҫ(view) еәҸеҲ—(sequence) зҙўеј•(index) еҗҢд№үиҜҚ(synonym)
1. и§Ҷеӣҫ: еӯҳеӮЁиө·жқҘзҡ„ select иҜӯеҸҘ
create view emp_vw as select employee_id, last_name, salary from employees where department_id = 90; select * from emp_vw;
еҸҜд»ҘеҜ№з®ҖеҚ•и§ҶеӣҫиҝӣиЎҢ DML ж“ҚдҪң
update emp_vw set last_name = 'HelloKitty' where employee_id = 100; select * from employees where employee_id = 100;
1). еӨҚжқӮи§Ҷеӣҫ
create view emp_vw2 as select department_id, avg(salary) avg_sal from employees group by department_id; select * from emp_vw2;
еӨҚжқӮи§ҶеӣҫдёҚиғҪиҝӣиЎҢ DML ж“ҚдҪң
update emp_vw2 set avg_sal = 10000 where department_id = 100;
2. еәҸеҲ—пјҡз”ЁдәҺз”ҹжҲҗдёҖз»„жңү规еҫӢзҡ„ж•°еҖјгҖӮпјҲйҖҡеёёз”ЁдәҺдёәдё»й”®и®ҫзҪ®еҖјпјү
create sequence emp_seq1 start with 1 increment by 1 maxvalue 10000 minvalue 1 cycle nocache; select emp_seq1.currval from dual; select emp_seq1.nextval from dual;
й—®йўҳпјҡиЈӮзјқ . еҺҹеӣ пјҡ
еҪ“еӨҡдёӘиЎЁе…ұз”ЁеҗҢдёҖдёӘеәҸеҲ—ж—¶гҖӮ
rollback
еҸ‘з”ҹејӮеёё
create table emp1( id number(10), name varchar2(30) ); insert into emp1 values(emp_seq1.nextval, 'еј дёү'); select * from emp1;
3. зҙўеј•пјҡжҸҗй«ҳжҹҘиҜўж•ҲзҺҮ
иҮӘеҠЁеҲӣе»әпјҡOracle дјҡдёәе…·жңүе”ҜдёҖзәҰжқҹ(е”ҜдёҖзәҰжқҹпјҢдё»й”®зәҰжқҹ)зҡ„еҲ—пјҢиҮӘеҠЁеҲӣе»әзҙўеј•
create table emp2( id number(10) primary key, name varchar2(30) )
жүӢеҠЁеҲӣе»ә
create index emp_idx on emp2(name); create index emp_idx2 on emp2(id, name);
4. еҗҢд№үиҜҚ
create synonym d1 for departments; select * from d1;
5. иЎЁпјҡ
DDL пјҡж•°жҚ®е®ҡд№үиҜӯиЁҖ create table .../ drop table ... / rename ... to..../ truncate table.../alter table ...
DML : ж•°жҚ®ж“ҚзәөиҜӯиЁҖ
insert into ... values ... update ... set ... where ... delete from ... where ...
гҖҗйҮҚиҰҒгҖ‘
select ... з»„еҮҪж•°(MIN()/MAX()/SUM()/AVG()/COUNT())
from ...join ... on ... е·ҰеӨ–иҝһжҺҘпјҡleft join ... on ... еҸіеӨ–иҝһжҺҘ: right join ... on ...
where ...
group by ... (oracle,SQL serverдёӯеҮәзҺ°еңЁselect еӯҗеҸҘеҗҺзҡ„йқһеҲҶз»„еҮҪж•°пјҢеҝ…йЎ»еҮәзҺ°еңЁ group byеӯҗеҸҘеҗҺ)
having ... з”ЁдәҺиҝҮж»Ө з»„еҮҪж•°
order by ... asc еҚҮеәҸпјҢ desc йҷҚеәҸ
limit (0,4) йҷҗеҲ¶NжқЎж•°жҚ® еҰӮ: topNж•°жҚ®
union 并йӣҶ
union all(жңүйҮҚеӨҚ)
intersect дәӨйӣҶ
minus зӣёеҮҸ
DCL : ж•°жҚ®жҺ§еҲ¶иҜӯиЁҖ commit : жҸҗдәӨ / rollback : еӣһж»ҡ / жҺҲжқғgrant...to... /revoke
зҙўеј•
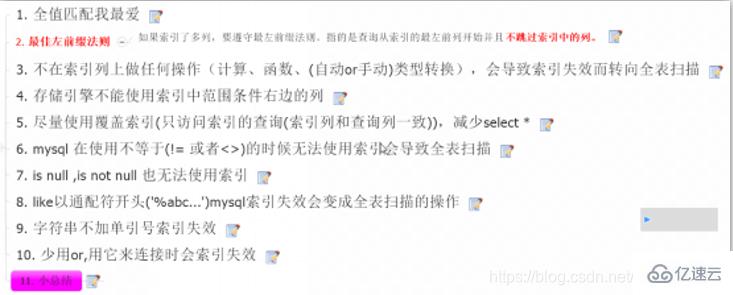

дҪ•ж—¶еҲӣе»әзҙўеј•:


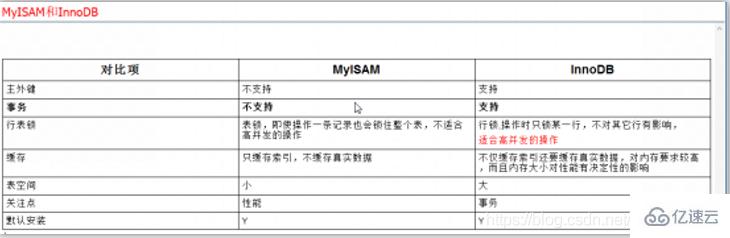

дёҖгҖҒ
select employee_id, last_name, salary, department_id from employees where department_id in (70, 80) --> 70:1 80:34
union 并йӣҶ
union all(жңүйҮҚеӨҚйғЁеҲҶ)
intersect дәӨйӣҶ
minus зӣёеҮҸ
select employee_id, last_name, salary, department_id from employees where department_id in (80, 90) --> 90:4 80:34
й—®йўҳпјҡжҹҘиҜўе·Ҙиө„еӨ§дәҺ149еҸ·е‘ҳе·Ҙе·Ҙиө„зҡ„е‘ҳе·Ҙзҡ„дҝЎжҒҜ
select * from employees where salary > ( select salary from employees where employee_id = 149 )
й—®йўҳпјҡжҹҘиҜўдёҺ141еҸ·жҲ–174еҸ·е‘ҳе·Ҙзҡ„manager_idе’Ңdepartment_idзӣёеҗҢзҡ„е…¶д»–е‘ҳе·Ҙзҡ„
employee_id, manager_id, department_id select employee_id, manager_id, department_id from employees where manager_id in ( select manager_id from employees where employee_id in(141, 174) ) and department_id in ( select department_id from employees where employee_id in(141, 174) ) and employee_id not in (141, 174); select employee_id, manager_id, department_id from employees where (manager_id, department_id) in ( select manager_id, department_id from employees where employee_id in (141, 174) ) and employee_id not in(141, 174);
1. from еӯҗеҸҘдёӯдҪҝз”ЁеӯҗжҹҘиҜў
select max(avg(salary)) from employees group by department_id; select max(avg_sal) from ( select avg(salary) avg_sal from employees group by department_id ) e
й—®йўҳпјҡиҝ”еӣһжҜ”жң¬йғЁй—Ёе№іеқҮе·Ҙиө„й«ҳзҡ„е‘ҳе·Ҙзҡ„last_name, department_id, salaryеҸҠе№іеқҮе·Ҙиө„
select last_name, department_id, salary, (select avg(salary) from employees where department_id = e1.department_id) from employees e1 where salary > ( select avg(salary) from employees e2 where e1.department_id = e2.department_id ) select last_name, e1.department_id, salary, avg_sal from employees e1, ( select department_id, avg(salary) avg_sal from employees group by department_id ) e2 where e1.department_id = e2.department_id and e1.salary > e2.avg_sal;
case...when ... then... when ... then ... else ... end
жҹҘиҜўпјҡиӢҘйғЁй—Ёдёә10 жҹҘзңӢе·Ҙиө„зҡ„ 1.1 еҖҚпјҢйғЁй—ЁеҸ·дёә 20 е·Ҙиө„зҡ„1.2еҖҚпјҢе…¶дҪҷ 1.3 еҖҚ
select employee_id, last_name, salary, case department_id when 10 then salary * 1.1 when 20 then salary * 1.2 else salary * 1.3 end "new_salary" from employees; select employee_id, last_name, salary, decode(department_id, 10, salary * 1.1, 20, salary * 1.2, salary * 1.3) "new_salary" from employees;
й—®йўҳпјҡжҳҫејҸе‘ҳе·Ҙзҡ„employee_id,last_nameе’ҢlocationгҖӮе…¶дёӯпјҢиӢҘе‘ҳе·Ҙdepartment_idдёҺlocation_idдёә1800зҡ„department_idзӣёеҗҢпјҢеҲҷlocationдёәвҖҷCanadaвҖҷ,е…¶дҪҷеҲҷдёәвҖҷUSAвҖҷгҖӮ
select employee_id, last_name, case department_id when ( select department_id from departments where location_id = 1800 ) then 'Canada' else 'USA' end "location" from employees;
й—®йўҳпјҡжҹҘиҜўе‘ҳе·Ҙзҡ„employee_id,last_name,иҰҒжұӮжҢүз…§е‘ҳе·Ҙзҡ„department_nameжҺ’еәҸ
select employee_id, last_name from employees e1 order by ( select department_name from departments d1 where e1.department_id = d1.department_id )
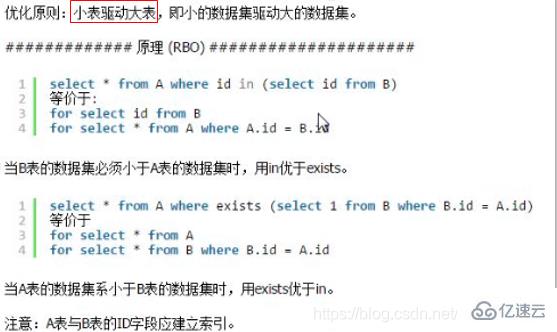
SQL дјҳеҢ–пјҡиғҪдҪҝз”Ё EXISTS е°ұдёҚиҰҒдҪҝз”Ё IN
й—®йўҳпјҡжҹҘиҜўе…¬еҸёз®ЎзҗҶиҖ…зҡ„employee_id,last_name,job_id,department_idдҝЎжҒҜ
select employee_id, last_name, job_id, department_id from employees where employee_id in ( select manager_id from employees ) select employee_id, last_name, job_id, department_id from employees e1 where exists ( select 'x' from employees e2 where e1.employee_id = e2.manager_id )
й—®йўҳпјҡжҹҘиҜўdepartmentsиЎЁдёӯпјҢдёҚеӯҳеңЁдәҺemployeesиЎЁдёӯзҡ„йғЁй—Ёзҡ„department_idе’Ңdepartment_name
select department_id, department_name from departments d1 where not exists ( select 'x' from employees e1 where e1.department_id = d1.department_id )
жӣҙж”№ 108 е‘ҳе·Ҙзҡ„дҝЎжҒҜ: дҪҝе…¶е·Ҙиө„еҸҳдёәжүҖеңЁйғЁй—Ёдёӯзҡ„жңҖй«ҳе·Ҙиө„, job еҸҳдёәе…¬еҸёдёӯе№іеқҮе·Ҙиө„жңҖдҪҺзҡ„ job
update employees e1 set salary = ( select max(salary) from employees e2 where e1.department_id = e2.department_id ), job_id = ( select job_id from employees group by job_id having avg(salary) = ( select min(avg(salary)) from employees group by job_id ) ) where employee_id = 108;
56. еҲ йҷӨ 108 еҸ·е‘ҳе·ҘжүҖеңЁйғЁй—Ёдёӯе·Ҙиө„жңҖдҪҺзҡ„йӮЈдёӘе‘ҳе·Ҙ.
delete from employees e1 where salary = ( select min(salary) from employees where department_id = ( select department_id from employees where employee_id = 108 ) ) select * from employees where employee_id = 108; select * from employees where department_id = 100 order by salary; rollback;
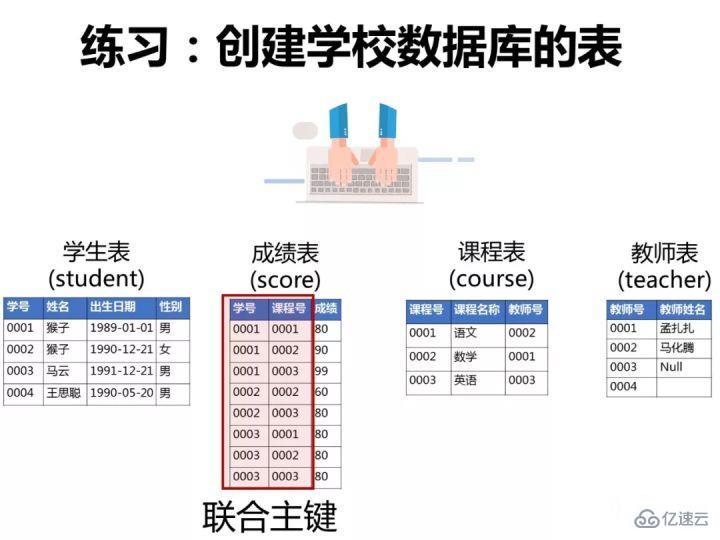
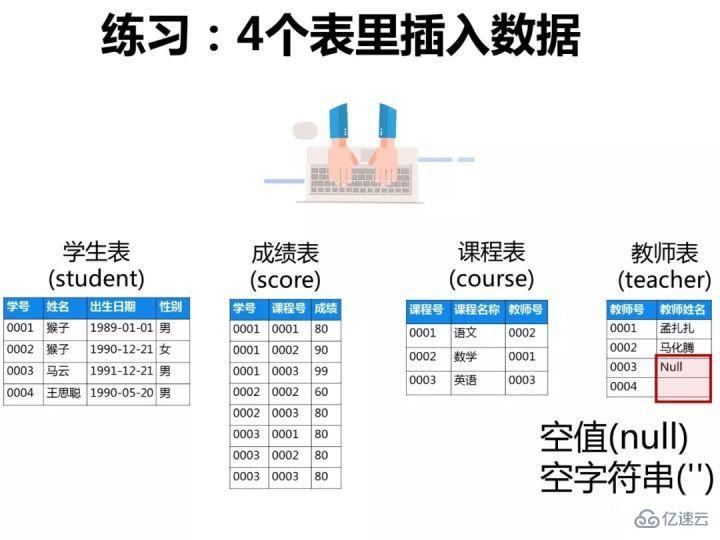
е·ІзҹҘжңүеҰӮдёӢ4еј иЎЁпјҡ
еӯҰз”ҹиЎЁпјҡstudent(еӯҰеҸ·,еӯҰз”ҹ姓еҗҚ,еҮәз”ҹе№ҙжңҲ,жҖ§еҲ«)
жҲҗз»©иЎЁпјҡscore(еӯҰеҸ·,иҜҫзЁӢеҸ·,жҲҗз»©)
иҜҫзЁӢиЎЁпјҡcourse(иҜҫзЁӢеҸ·,иҜҫзЁӢеҗҚз§°,ж•ҷеёҲеҸ·)
ж•ҷеёҲиЎЁпјҡteacher(ж•ҷеёҲеҸ·,ж•ҷеёҲ姓еҗҚ)
ж №жҚ®д»ҘдёҠдҝЎжҒҜжҢүз…§дёӢйқўиҰҒжұӮеҶҷеҮәеҜ№еә”зҡ„SQLиҜӯеҸҘгҖӮ
psпјҡиҝҷдәӣйўҳиҖғеҜҹSQLзҡ„зј–еҶҷиғҪеҠӣпјҢеҜ№дәҺиҝҷзұ»еһӢзҡ„йўҳзӣ®пјҢйңҖиҰҒдҪ е…ҲжҠҠ4еј иЎЁд№Ӣй—ҙзҡ„е…іиҒ”е…ізі»жҗһжё…жҘҡдәҶпјҢжңҖеҘҪзҡ„еҠһжі•жҳҜиҮӘе·ұеңЁиҚүзЁҝзәёдёҠз”»еҮәе…іиҒ”еӣҫпјҢ然еҗҺеҶҚзј–еҶҷеҜ№еә”зҡ„SQLиҜӯеҸҘе°ұжҜ”иҫғе®№жҳ“дәҶгҖӮдёӢеӣҫжҳҜжҲ‘з”»зҡ„иҝҷ4еј иЎЁзҡ„е…ізі»еӣҫпјҢеҸҜд»ҘзңӢеҮәе®ғ们д№Ӣй—ҙжҳҜйҖҡиҝҮе“ӘдәӣеӨ–й”®е…іиҒ”иө·жқҘзҡ„пјҡ
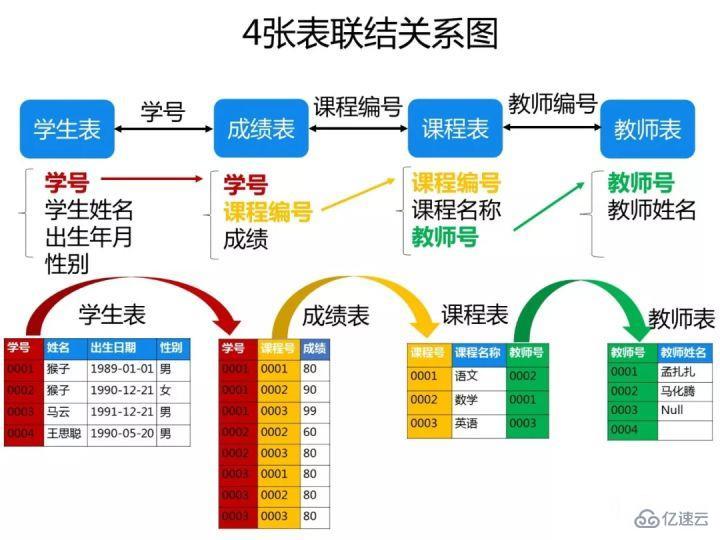
дёҖгҖҒеҲӣе»әж•°жҚ®еә“е’ҢиЎЁ
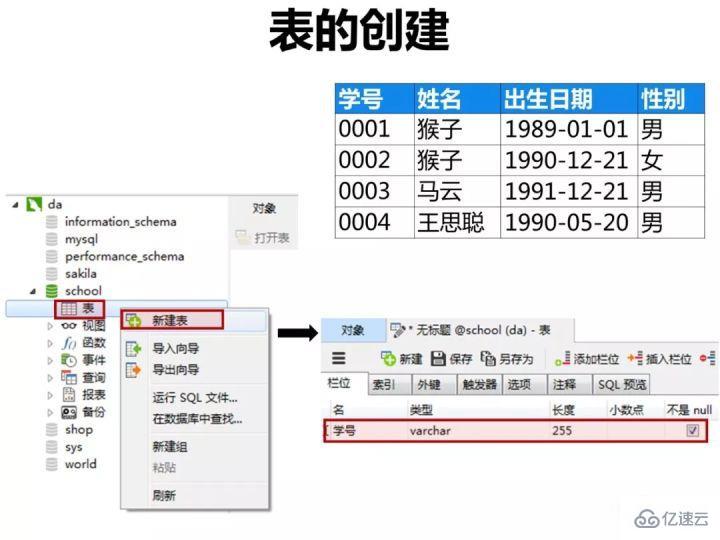
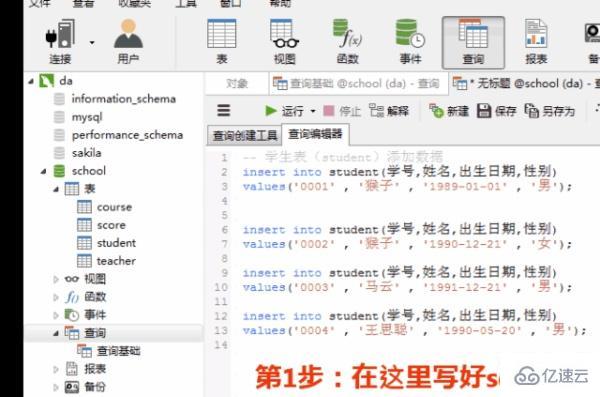
дёәдәҶжј”зӨәйўҳзӣ®зҡ„иҝҗиЎҢиҝҮзЁӢпјҢжҲ‘们е…ҲжҢүдёӢйқўиҜӯеҸҘеңЁе®ўжҲ·з«ҜnavicatдёӯеҲӣе»әж•°жҚ®еә“е’ҢиЎЁгҖӮ
пјҲеҰӮдҪ•дҪ иҝҳдёҚжҮӮд»Җд№ҲжҳҜж•°жҚ®еә“пјҢд»Җд№ҲжҳҜе®ўжҲ·з«ҜnavicatпјҢеҸҜд»Ҙе…ҲеӯҰд№ иҝҷдёӘпјҡ
1.еҲӣе»әиЎЁ
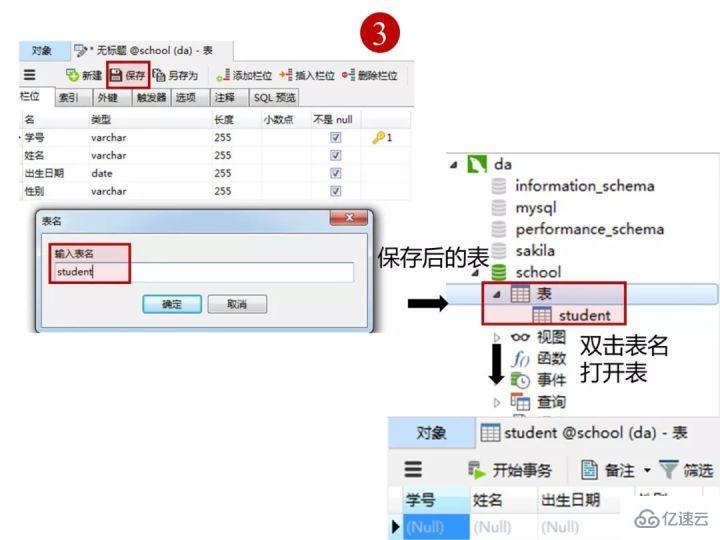
1пјүеҲӣе»әеӯҰз”ҹиЎЁпјҲstudentпјү
жҢүдёӢеӣҫеңЁе®ўжҲ·з«ҜnavicatйҮҢеҲӣе»әеӯҰз”ҹиЎЁ
еӯҰз”ҹиЎЁзҡ„вҖңеӯҰеҸ·вҖқеҲ—и®ҫзҪ®дёәдё»й”®зәҰжқҹпјҢдёӢеӣҫжҳҜжҜҸдёҖеҲ—и®ҫзҪ®зҡ„ж•°жҚ®зұ»еһӢе’ҢзәҰжқҹ
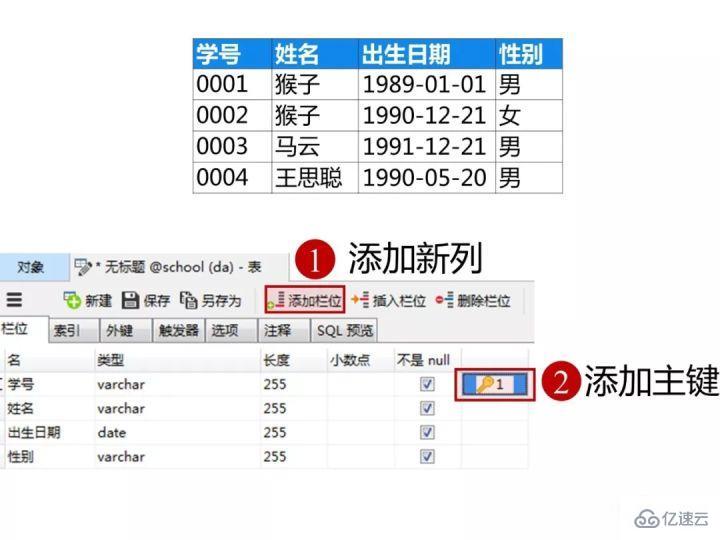
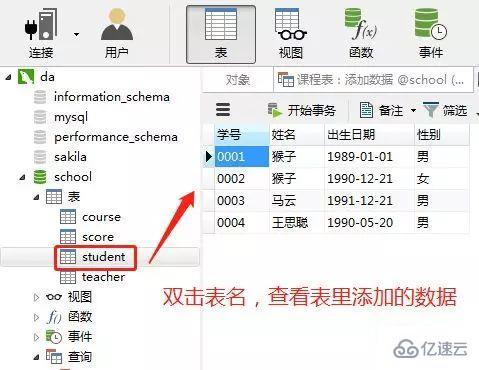
еҲӣе»әе®ҢиЎЁпјҢзӮ№еҮ»вҖңдҝқеӯҳвҖқ
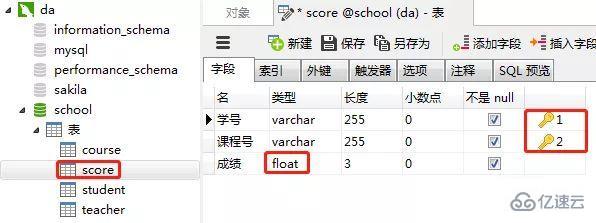
2пјүеҲӣе»әжҲҗз»©иЎЁпјҲscoreпјү
еҗҢж ·зҡ„жӯҘйӘӨпјҢеҲӣе»ә"жҲҗз»©иЎЁвҖңгҖӮвҖңиҜҫзЁӢиЎЁзҡ„вҖңеӯҰеҸ·вҖқе’ҢвҖңиҜҫзЁӢеҸ·вҖқдёҖиө·и®ҫзҪ®дёәдё»й”®зәҰжқҹпјҲиҒ”еҗҲдё»й”®пјүпјҢвҖңжҲҗз»©вҖқиҝҷдёҖеҲ—и®ҫзҪ®дёәж•°еҖјзұ»еһӢпјҲfloatпјҢжө®зӮ№ж•°еҖјпјү
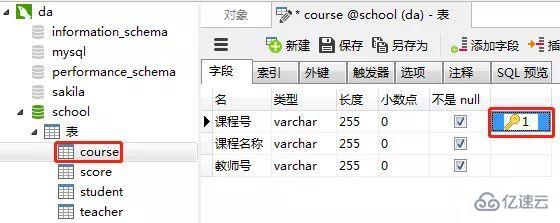
3пјүеҲӣе»әиҜҫзЁӢиЎЁпјҲcourseпјү
иҜҫзЁӢиЎЁзҡ„вҖңиҜҫзЁӢеҸ·вҖқи®ҫзҪ®дёәдё»й”®зәҰжқҹ
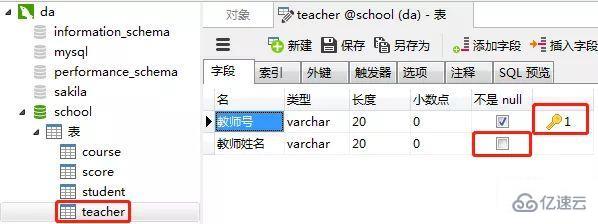
4пјүж•ҷеёҲиЎЁпјҲteacherпјү
ж•ҷеёҲиЎЁзҡ„вҖңж•ҷеёҲеҸ·вҖқеҲ—и®ҫзҪ®дёәдё»й”®зәҰжқҹпјҢ
ж•ҷеёҲ姓еҗҚиҝҷдёҖеҲ—и®ҫзҪ®зәҰжқҹдёәвҖңnullвҖқпјҲзәўжЎҶзҡ„ең°ж–№дёҚеӢҫйҖүпјүпјҢиЎЁзӨәиҝҷдёҖеҲ—е…Ғи®ёеҢ…еҗ«з©әеҖјпјҲnullпјү
2.еҗ‘иЎЁдёӯж·»еҠ ж•°жҚ®
1пјүеҗ‘еӯҰз”ҹиЎЁйҮҢж·»еҠ ж•°жҚ®
ж·»еҠ ж•°жҚ®зҡ„sql
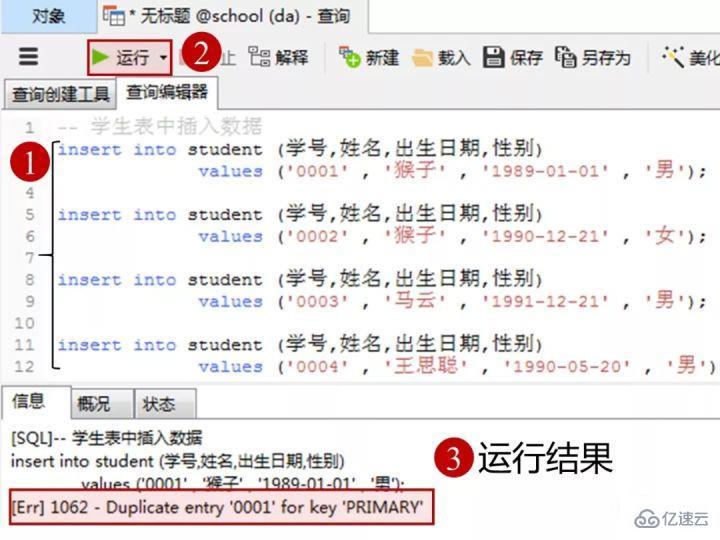
insert into student(еӯҰеҸ·,姓еҗҚ,еҮәз”ҹж—Ҙжңҹ,жҖ§еҲ«)
values('0001' , 'зҢҙеӯҗ' , '1989-01-01' , 'з”·');
insert into student(еӯҰеҸ·,姓еҗҚ,еҮәз”ҹж—Ҙжңҹ,жҖ§еҲ«)
values('0002' , 'зҢҙеӯҗ' , '1990-12-21' , 'еҘі');
insert into student(еӯҰеҸ·,姓еҗҚ,еҮәз”ҹж—Ҙжңҹ,жҖ§еҲ«)
values('0003' , '马дә‘' , '1991-12-21' , 'з”·');
insert into student(еӯҰеҸ·,姓еҗҚ,еҮәз”ҹж—Ҙжңҹ,жҖ§еҲ«)
values('0004' , 'зҺӢжҖқиҒӘ' , '1990-05-20' , 'з”·');еңЁе®ўжҲ·з«ҜnavicatйҮҢзҡ„ж“ҚдҪң
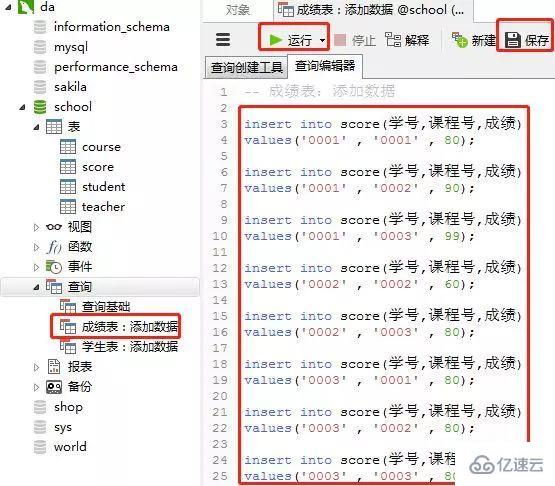
2пјүжҲҗз»©иЎЁпјҲscoreпјү
ж·»еҠ ж•°жҚ®зҡ„sql
insert into score(еӯҰеҸ·,иҜҫзЁӢеҸ·,жҲҗз»©)
values('0001' , '0001' , 80);
insert into score(еӯҰеҸ·,иҜҫзЁӢеҸ·,жҲҗз»©)
values('0001' , '0002' , 90);
insert into score(еӯҰеҸ·,иҜҫзЁӢеҸ·,жҲҗз»©)
values('0001' , '0003' , 99);
insert into score(еӯҰеҸ·,иҜҫзЁӢеҸ·,жҲҗз»©)
values('0002' , '0002' , 60);
insert into score(еӯҰеҸ·,иҜҫзЁӢеҸ·,жҲҗз»©)
values('0002' , '0003' , 80);
insert into score(еӯҰеҸ·,иҜҫзЁӢеҸ·,жҲҗз»©)
values('0003' , '0001' , 80);
insert into score(еӯҰеҸ·,иҜҫзЁӢеҸ·,жҲҗз»©)
values('0003' , '0002' , 80);
insert into score(еӯҰеҸ·,иҜҫзЁӢеҸ·,жҲҗз»©)
values('0003' , '0003' , 80);е®ўжҲ·з«ҜnavicatйҮҢзҡ„ж“ҚдҪң
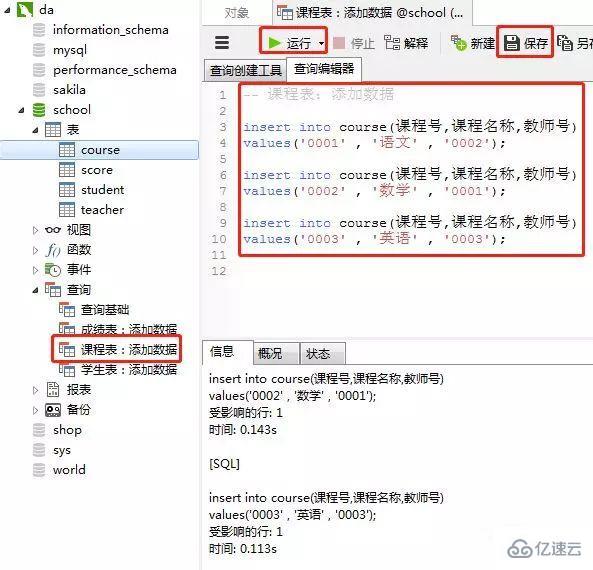
3пјүиҜҫзЁӢиЎЁ
ж·»еҠ ж•°жҚ®зҡ„sql
insert into course(иҜҫзЁӢеҸ·,иҜҫзЁӢеҗҚз§°,ж•ҷеёҲеҸ·)
values('0001' , 'иҜӯж–Ү' , '0002');
insert into course(иҜҫзЁӢеҸ·,иҜҫзЁӢеҗҚз§°,ж•ҷеёҲеҸ·)
values('0002' , 'ж•°еӯҰ' , '0001');
insert into course(иҜҫзЁӢеҸ·,иҜҫзЁӢеҗҚз§°,ж•ҷеёҲеҸ·)
values('0003' , 'иӢұиҜӯ' , '0003');е®ўжҲ·з«ҜnavicatйҮҢзҡ„ж“ҚдҪң
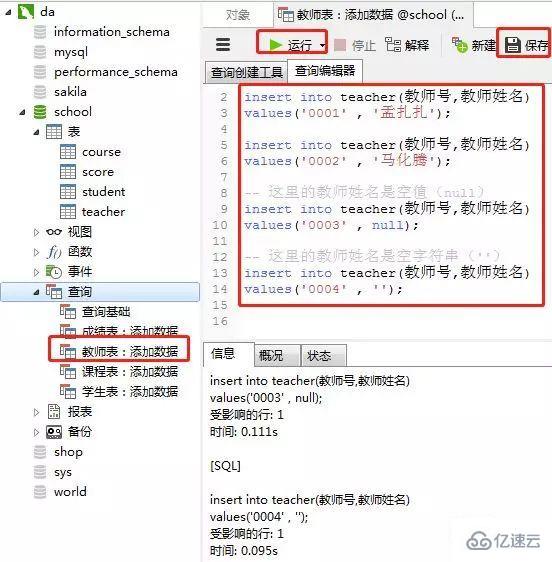
4пјүж•ҷеёҲиЎЁйҮҢж·»еҠ ж•°жҚ®
ж·»еҠ ж•°жҚ®зҡ„sql
-- ж•ҷеёҲиЎЁпјҡж·»еҠ ж•°жҚ®
insert into teacher(ж•ҷеёҲеҸ·,ж•ҷеёҲ姓еҗҚ)
values('0001' , 'еӯҹжүҺжүҺ');
insert into teacher(ж•ҷеёҲеҸ·,ж•ҷеёҲ姓еҗҚ)
values('0002' , '马еҢ–и…ҫ');
-- иҝҷйҮҢзҡ„ж•ҷеёҲ姓еҗҚжҳҜз©әеҖјпјҲnullпјү
insert into teacher(ж•ҷеёҲеҸ·,ж•ҷеёҲ姓еҗҚ)
values('0003' , null);
-- иҝҷйҮҢзҡ„ж•ҷеёҲ姓еҗҚжҳҜз©әеӯ—з¬ҰдёІпјҲ''пјү
insert into teacher(ж•ҷеёҲеҸ·,ж•ҷеёҲ姓еҗҚ)
values('0004' , '');е®ўжҲ·з«ҜnavicatйҮҢж“ҚдҪң
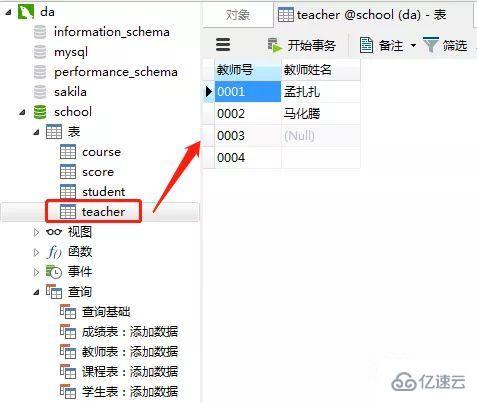
ж·»еҠ з»“жһң
дёәдәҶж–№дҫҝеӯҰд№ пјҢжҲ‘е°Ҷ50йҒ“йқўиҜ•йўҳиҝӣиЎҢдәҶеҲҶзұ»
жҹҘиҜўе§“вҖңзҢҙвҖқзҡ„еӯҰз”ҹеҗҚеҚ•

жҹҘиҜўе§“вҖңеӯҹвҖқиҖҒеёҲзҡ„дёӘж•°
select count(ж•ҷеёҲеҸ·) from teacher where ж•ҷеёҲ姓еҗҚ like 'еӯҹ%';

йқўиҜ•йўҳпјҡжҹҘиҜўиҜҫзЁӢзј–еҸ·дёәвҖң0002вҖқзҡ„жҖ»жҲҗз»©
/* еҲҶжһҗжҖқи·Ҝ select жҹҘиҜўз»“жһң [жҖ»жҲҗз»©:жұҮжҖ»еҮҪж•°sum] from д»Һе“Әеј иЎЁдёӯжҹҘжүҫж•°жҚ®[жҲҗз»©иЎЁscore] where жҹҘиҜўжқЎд»¶ [иҜҫзЁӢеҸ·жҳҜ0002] */ select sum(жҲҗз»©) from score where иҜҫзЁӢеҸ· = '0002';
жҹҘиҜўйҖүдәҶиҜҫзЁӢзҡ„еӯҰз”ҹдәәж•°
/* иҝҷдёӘйўҳзӣ®зҝ»иҜ‘жҲҗеӨ§зҷҪиҜқе°ұжҳҜпјҡжҹҘиҜўжңүеӨҡе°‘дәәйҖүдәҶиҜҫзЁӢ select еӯҰеҸ·пјҢжҲҗз»©иЎЁйҮҢеӯҰеҸ·жңүйҮҚеӨҚеҖјйңҖиҰҒеҺ»жҺү from д»ҺиҜҫзЁӢиЎЁжҹҘжүҫscore; */ select count(distinct еӯҰеҸ·) as еӯҰз”ҹдәәж•° from score;
жҹҘиҜўеҗ„科жҲҗз»©жңҖй«ҳе’ҢжңҖдҪҺзҡ„еҲҶпјҢ д»ҘеҰӮдёӢзҡ„еҪўејҸжҳҫзӨәпјҡиҜҫзЁӢеҸ·пјҢжңҖй«ҳеҲҶпјҢжңҖдҪҺеҲҶ
/* еҲҶжһҗжҖқи·Ҝ select жҹҘиҜўз»“жһң [иҜҫзЁӢIDпјҡжҳҜиҜҫзЁӢеҸ·зҡ„еҲ«еҗҚ,жңҖй«ҳеҲҶпјҡmax(жҲҗз»©) ,жңҖдҪҺеҲҶпјҡmin(жҲҗз»©)] from д»Һе“Әеј иЎЁдёӯжҹҘжүҫж•°жҚ® [жҲҗз»©иЎЁscore] where жҹҘиҜўжқЎд»¶ [жІЎжңү] group by еҲҶз»„ [еҗ„科жҲҗз»©пјҡд№ҹе°ұжҳҜжҜҸй—ЁиҜҫзЁӢзҡ„жҲҗз»©пјҢйңҖиҰҒжҢүиҜҫзЁӢеҸ·еҲҶз»„]; */ select иҜҫзЁӢеҸ·,max(жҲҗз»©) as жңҖй«ҳеҲҶ,min(жҲҗз»©) as жңҖдҪҺеҲҶ from score group by иҜҫзЁӢеҸ·;
жҹҘиҜўжҜҸй—ЁиҜҫзЁӢиў«йҖүдҝ®зҡ„еӯҰз”ҹж•°
/* еҲҶжһҗжҖқи·Ҝ select жҹҘиҜўз»“жһң [иҜҫзЁӢеҸ·пјҢйҖүдҝ®иҜҘиҜҫзЁӢзҡ„еӯҰз”ҹж•°пјҡжұҮжҖ»еҮҪж•°count] from д»Һе“Әеј иЎЁдёӯжҹҘжүҫж•°жҚ® [жҲҗз»©иЎЁscore] where жҹҘиҜўжқЎд»¶ [жІЎжңү] group by еҲҶз»„ [жҜҸй—ЁиҜҫзЁӢпјҡжҢүиҜҫзЁӢеҸ·еҲҶз»„]; */ select иҜҫзЁӢеҸ·, count(еӯҰеҸ·) from score group by иҜҫзЁӢеҸ·;
жҹҘиҜўз”·з”ҹгҖҒеҘіз”ҹдәәж•°
/* еҲҶжһҗжҖқи·Ҝ select жҹҘиҜўз»“жһң [жҖ§еҲ«пјҢеҜ№еә”жҖ§еҲ«зҡ„дәәж•°пјҡжұҮжҖ»еҮҪж•°count] from д»Һе“Әеј иЎЁдёӯжҹҘжүҫж•°жҚ® [жҖ§еҲ«еңЁеӯҰз”ҹиЎЁдёӯпјҢжүҖд»ҘжҹҘжүҫзҡ„жҳҜеӯҰз”ҹиЎЁstudent] where жҹҘиҜўжқЎд»¶ [жІЎжңү] group by еҲҶз»„ [з”·з”ҹгҖҒеҘіз”ҹдәәж•°пјҡжҢүжҖ§еҲ«еҲҶз»„] having еҜ№еҲҶз»„з»“жһңжҢҮе®ҡжқЎд»¶ [жІЎжңү] order by еҜ№жҹҘиҜўз»“жһңжҺ’еәҸ[жІЎжңү]; */ select жҖ§еҲ«,count(*) from student group by жҖ§еҲ«;

жҹҘиҜўе№іеқҮжҲҗз»©еӨ§дәҺ60еҲҶеӯҰз”ҹзҡ„еӯҰеҸ·е’Ңе№іеқҮжҲҗз»©
/* йўҳзӣ®зҝ»иҜ‘жҲҗеӨ§зҷҪиҜқпјҡ е№іеқҮжҲҗз»©пјҡеұ•ејҖжқҘиҜҙе°ұжҳҜи®Ўз®—жҜҸдёӘеӯҰз”ҹзҡ„е№іеқҮжҲҗз»© иҝҷйҮҢж¶үеҸҠеҲ°вҖңжҜҸдёӘвҖқе°ұжҳҜиҰҒеҲҶз»„дәҶ е№іеқҮжҲҗз»©еӨ§дәҺ60еҲҶпјҢе°ұжҳҜеҜ№еҲҶз»„з»“жһңжҢҮе®ҡжқЎд»¶ еҲҶжһҗжҖқи·Ҝ select жҹҘиҜўз»“жһң [еӯҰеҸ·пјҢе№іеқҮжҲҗз»©пјҡжұҮжҖ»еҮҪж•°avg(жҲҗз»©)] from д»Һе“Әеј иЎЁдёӯжҹҘжүҫж•°жҚ® [жҲҗз»©еңЁжҲҗз»©иЎЁдёӯпјҢжүҖд»ҘжҹҘжүҫзҡ„жҳҜжҲҗз»©иЎЁscore] where жҹҘиҜўжқЎд»¶ [жІЎжңү] group by еҲҶз»„ [е№іеқҮжҲҗз»©пјҡе…ҲжҢүеӯҰеҸ·еҲҶз»„пјҢеҶҚи®Ўз®—е№іеқҮжҲҗз»©] having еҜ№еҲҶз»„з»“жһңжҢҮе®ҡжқЎд»¶ [е№іеқҮжҲҗз»©еӨ§дәҺ60еҲҶ] */ select еӯҰеҸ·, avg(жҲҗз»©) from score group by еӯҰеҸ· having avg(жҲҗз»©)>60;
жҹҘиҜўиҮіе°‘йҖүдҝ®дёӨй—ЁиҜҫзЁӢзҡ„еӯҰз”ҹеӯҰеҸ·
/* зҝ»иҜ‘жҲҗеӨ§зҷҪиҜқпјҡ 第1жӯҘпјҢйңҖиҰҒе…Ҳи®Ўз®—еҮәжҜҸдёӘеӯҰз”ҹйҖүдҝ®зҡ„иҜҫзЁӢж•°жҚ®пјҢйңҖиҰҒжҢүеӯҰеҸ·еҲҶз»„ 第2жӯҘпјҢиҮіе°‘йҖүдҝ®дёӨй—ЁиҜҫзЁӢпјҡд№ҹе°ұжҳҜжҜҸдёӘеӯҰз”ҹйҖүдҝ®иҜҫзЁӢж•°зӣ®>=2пјҢеҜ№еҲҶз»„з»“жһңжҢҮе®ҡжқЎд»¶ еҲҶжһҗжҖқи·Ҝ select жҹҘиҜўз»“жһң [еӯҰеҸ·,жҜҸдёӘеӯҰз”ҹйҖүдҝ®иҜҫзЁӢж•°зӣ®пјҡжұҮжҖ»еҮҪж•°count] from д»Һе“Әеј иЎЁдёӯжҹҘжүҫж•°жҚ® [иҜҫзЁӢзҡ„еӯҰз”ҹеӯҰеҸ·пјҡиҜҫзЁӢиЎЁscore] where жҹҘиҜўжқЎд»¶ [иҮіе°‘йҖүдҝ®дёӨй—ЁиҜҫзЁӢпјҡйңҖиҰҒе…Ҳи®Ўз®—еҮәжҜҸдёӘеӯҰз”ҹйҖүдҝ®дәҶеӨҡе°‘й—ЁиҜҫпјҢйңҖиҰҒз”ЁеҲҶз»„пјҢжүҖд»ҘиҝҷйҮҢжІЎжңүwhereеӯҗеҸҘ] group by еҲҶз»„ [жҜҸдёӘеӯҰз”ҹйҖүдҝ®иҜҫзЁӢж•°зӣ®пјҡжҢүиҜҫзЁӢеҸ·еҲҶз»„пјҢ然еҗҺз”ЁжұҮжҖ»еҮҪж•°countи®Ўз®—еҮәйҖүдҝ®дәҶеӨҡе°‘й—ЁиҜҫ] having еҜ№еҲҶз»„з»“жһңжҢҮе®ҡжқЎд»¶ [иҮіе°‘йҖүдҝ®дёӨй—ЁиҜҫзЁӢпјҡжҜҸдёӘеӯҰз”ҹйҖүдҝ®иҜҫзЁӢж•°зӣ®>=2] */ select еӯҰеҸ·, count(иҜҫзЁӢеҸ·) as йҖүдҝ®иҜҫзЁӢж•°зӣ® from score group by еӯҰеҸ· having count(иҜҫзЁӢеҸ·)>=2;
жҹҘиҜўеҗҢеҗҚеҗҢжҖ§еӯҰз”ҹеҗҚеҚ•е№¶з»ҹи®ЎеҗҢеҗҚдәәж•°
/* зҝ»иҜ‘жҲҗеӨ§зҷҪиҜқпјҢй—®йўҳи§Јжһҗпјҡ 1пјүжҹҘжүҫеҮә姓еҗҚзӣёеҗҢзҡ„еӯҰз”ҹжңүи°ҒпјҢжҜҸдёӘ姓еҗҚзӣёеҗҢеӯҰз”ҹзҡ„дәәж•° жҹҘиҜўз»“жһңпјҡ姓еҗҚ,дәәж•° жқЎд»¶пјҡжҖҺд№Ҳ算姓еҗҚзӣёеҗҢпјҹжҢү姓еҗҚеҲҶз»„еҗҺдәәж•°еӨ§дәҺзӯүдәҺ2пјҢеӣ дёәеҗҢеҗҚзҡ„дәәж•°еӨ§дәҺзӯүдәҺ2 еҲҶжһҗжҖқи·Ҝ select жҹҘиҜўз»“жһң [姓еҗҚ,дәәж•°пјҡжұҮжҖ»еҮҪж•°count(*)] from д»Һе“Әеј иЎЁдёӯжҹҘжүҫж•°жҚ® [еӯҰз”ҹиЎЁstudent] where жҹҘиҜўжқЎд»¶ [жІЎжңү] group by еҲҶз»„ [姓еҗҚзӣёеҗҢпјҡжҢү姓еҗҚеҲҶз»„] having еҜ№еҲҶз»„з»“жһңжҢҮе®ҡжқЎд»¶ [姓еҗҚзӣёеҗҢпјҡcount(*)>=2] order by еҜ№жҹҘиҜўз»“жһңжҺ’еәҸ[жІЎжңү]; */ select 姓еҗҚ,count(*) as дәәж•° from student group by 姓еҗҚ having count(*)>=2;
жҹҘиҜўдёҚеҸҠж јзҡ„иҜҫзЁӢ并жҢүиҜҫзЁӢеҸ·д»ҺеӨ§еҲ°е°ҸжҺ’еҲ—
/* еҲҶжһҗжҖқи·Ҝ select жҹҘиҜўз»“жһң [иҜҫзЁӢеҸ·] from д»Һе“Әеј иЎЁдёӯжҹҘжүҫж•°жҚ® [жҲҗз»©иЎЁscore] where жҹҘиҜўжқЎд»¶ [дёҚеҸҠж јпјҡжҲҗз»© <60] group by еҲҶз»„ [жІЎжңү] having еҜ№еҲҶз»„з»“жһңжҢҮе®ҡжқЎд»¶ [жІЎжңү] order by еҜ№жҹҘиҜўз»“жһңжҺ’еәҸ[иҜҫзЁӢеҸ·д»ҺеӨ§еҲ°е°ҸжҺ’еҲ—пјҡйҷҚеәҸdesc]; */ select иҜҫзЁӢеҸ· from score where жҲҗз»©<60 order by иҜҫзЁӢеҸ· desc;
жҹҘиҜўжҜҸй—ЁиҜҫзЁӢзҡ„е№іеқҮжҲҗз»©пјҢз»“жһңжҢүе№іеқҮжҲҗз»©еҚҮеәҸжҺ’еәҸпјҢе№іеқҮжҲҗз»©зӣёеҗҢж—¶пјҢжҢүиҜҫзЁӢеҸ·йҷҚеәҸжҺ’еҲ—
/* еҲҶжһҗжҖқи·Ҝ select жҹҘиҜўз»“жһң [иҜҫзЁӢеҸ·,е№іеқҮжҲҗз»©пјҡжұҮжҖ»еҮҪж•°avg(жҲҗз»©)] from д»Һе“Әеј иЎЁдёӯжҹҘжүҫж•°жҚ® [жҲҗз»©иЎЁscore] where жҹҘиҜўжқЎд»¶ [жІЎжңү] group by еҲҶз»„ [жҜҸй—ЁиҜҫзЁӢпјҡжҢүиҜҫзЁӢеҸ·еҲҶз»„] having еҜ№еҲҶз»„з»“жһңжҢҮе®ҡжқЎд»¶ [жІЎжңү] order by еҜ№жҹҘиҜўз»“жһңжҺ’еәҸ[жҢүе№іеқҮжҲҗз»©еҚҮеәҸжҺ’еәҸ:ascпјҢе№іеқҮжҲҗз»©зӣёеҗҢж—¶пјҢжҢүиҜҫзЁӢеҸ·йҷҚеәҸжҺ’еҲ—:desc]; */ select иҜҫзЁӢеҸ·, avg(жҲҗз»©) as е№іеқҮжҲҗз»© from score group by иҜҫзЁӢеҸ· order by е№іеқҮжҲҗз»© asc,иҜҫзЁӢеҸ· desc;
жЈҖзҙўиҜҫзЁӢзј–еҸ·дёәвҖң0004вҖқдё”еҲҶж•°е°ҸдәҺ60зҡ„еӯҰз”ҹеӯҰеҸ·пјҢз»“жһңжҢүжҢүеҲҶж•°йҷҚеәҸжҺ’еҲ—
/* еҲҶжһҗжҖқи·Ҝ select жҹҘиҜўз»“жһң [] from д»Һе“Әеј иЎЁдёӯжҹҘжүҫж•°жҚ® [жҲҗз»©иЎЁscore] where жҹҘиҜўжқЎд»¶ [иҜҫзЁӢзј–еҸ·дёәвҖң04вҖқдё”еҲҶж•°е°ҸдәҺ60] group by еҲҶз»„ [жІЎжңү] having еҜ№еҲҶз»„з»“жһңжҢҮе®ҡжқЎд»¶ [] order by еҜ№жҹҘиҜўз»“жһңжҺ’еәҸ[жҹҘиҜўз»“жһңжҢүжҢүеҲҶж•°йҷҚеәҸжҺ’еҲ—]; */ select еӯҰеҸ· from score where иҜҫзЁӢеҸ·='04' and жҲҗз»© <60 order by жҲҗз»© desc;
з»ҹи®ЎжҜҸй—ЁиҜҫзЁӢзҡ„еӯҰз”ҹйҖүдҝ®дәәж•°(и¶…иҝҮ2дәәзҡ„иҜҫзЁӢжүҚз»ҹи®Ў)
иҰҒжұӮиҫ“еҮәиҜҫзЁӢеҸ·е’ҢйҖүдҝ®дәәж•°пјҢжҹҘиҜўз»“жһңжҢүдәәж•°йҷҚеәҸжҺ’еәҸпјҢиӢҘдәәж•°зӣёеҗҢпјҢжҢүиҜҫзЁӢеҸ·еҚҮеәҸжҺ’еәҸ
/* еҲҶжһҗжҖқи·Ҝ select жҹҘиҜўз»“жһң [иҰҒжұӮиҫ“еҮәиҜҫзЁӢеҸ·е’ҢйҖүдҝ®дәәж•°] from д»Һе“Әеј иЎЁдёӯжҹҘжүҫж•°жҚ® [] where жҹҘиҜўжқЎд»¶ [] group by еҲҶз»„ [жҜҸй—ЁиҜҫзЁӢпјҡжҢүиҜҫзЁӢеҸ·еҲҶз»„] having еҜ№еҲҶз»„з»“жһңжҢҮе®ҡжқЎд»¶ [еӯҰз”ҹйҖүдҝ®дәәж•°(и¶…иҝҮ2дәәзҡ„иҜҫзЁӢжүҚз»ҹи®Ў)пјҡжҜҸй—ЁиҜҫзЁӢеӯҰз”ҹдәәж•°>2] order by еҜ№жҹҘиҜўз»“жһңжҺ’еәҸ[жҹҘиҜўз»“жһңжҢүдәәж•°йҷҚеәҸжҺ’еәҸпјҢиӢҘдәәж•°зӣёеҗҢпјҢжҢүиҜҫзЁӢеҸ·еҚҮеәҸжҺ’еәҸ]; */ select иҜҫзЁӢеҸ·, count(еӯҰеҸ·) as 'йҖүдҝ®дәәж•°' from score group by иҜҫзЁӢеҸ· having count(еӯҰеҸ·)>2 order by count(еӯҰеҸ·) desc,иҜҫзЁӢеҸ· asc;
жҹҘиҜўдёӨй—Ёд»ҘдёҠдёҚеҸҠж јиҜҫзЁӢзҡ„еҗҢеӯҰзҡ„еӯҰеҸ·еҸҠе…¶е№іеқҮжҲҗз»©
/* еҲҶжһҗжҖқи·Ҝ е…ҲеҲҶи§Јйўҳзӣ®пјҡ 1пјү[дёӨй—Ёд»ҘдёҠ][дёҚеҸҠж јиҜҫзЁӢ]йҷҗеҲ¶жқЎд»¶ 2пјү[еҗҢеӯҰзҡ„еӯҰеҸ·еҸҠе…¶е№іеқҮжҲҗз»©]пјҢд№ҹе°ұжҳҜжҜҸдёӘеӯҰз”ҹзҡ„е№іеқҮжҲҗз»©пјҢжҳҫзӨәеӯҰеҸ·пјҢе№іеқҮжҲҗз»© еҲҶжһҗиҝҮзЁӢпјҡ 第1жӯҘпјҡеҫ—еҲ°жҜҸдёӘеӯҰз”ҹзҡ„е№іеқҮжҲҗз»©пјҢжҳҫзӨәеӯҰеҸ·пјҢе№іеқҮжҲҗз»© 第2жӯҘпјҡеҶҚеҠ дёҠйҷҗеҲ¶жқЎд»¶пјҡ 1пјүдёҚеҸҠж јиҜҫзЁӢ 2пјүдёӨй—Ёд»ҘдёҠ[дёҚеҸҠж јиҜҫзЁӢ]пјҡиҜҫзЁӢж•°зӣ®>2 */ /* 第1жӯҘпјҡеҫ—еҲ°жҜҸдёӘеӯҰз”ҹзҡ„е№іеқҮжҲҗз»©пјҢжҳҫзӨәеӯҰеҸ·пјҢе№іеқҮжҲҗз»© select жҹҘиҜўз»“жһң [еӯҰеҸ·,е№іеқҮжҲҗз»©пјҡжұҮжҖ»еҮҪж•°avg(жҲҗз»©)] from д»Һе“Әеј иЎЁдёӯжҹҘжүҫж•°жҚ® [ж¶үеҸҠеҲ°жҲҗз»©пјҡжҲҗз»©иЎЁscore] where жҹҘиҜўжқЎд»¶ [жІЎжңү] group by еҲҶз»„ [жҜҸдёӘеӯҰз”ҹзҡ„е№іеқҮпјҡжҢүеӯҰеҸ·еҲҶз»„] having еҜ№еҲҶз»„з»“жһңжҢҮе®ҡжқЎд»¶ [жІЎжңү] order by еҜ№жҹҘиҜўз»“жһңжҺ’еәҸ[жІЎжңү]; */ select еӯҰеҸ·, avg(жҲҗз»©) as е№іеқҮжҲҗз»© from score group by еӯҰеҸ·; /* 第2жӯҘпјҡеҶҚеҠ дёҠйҷҗеҲ¶жқЎд»¶пјҡ 1пјүдёҚеҸҠж јиҜҫзЁӢ 2пјүдёӨй—Ёд»ҘдёҠ[дёҚеҸҠж јиҜҫзЁӢ] select жҹҘиҜўз»“жһң [еӯҰеҸ·,е№іеқҮжҲҗз»©пјҡжұҮжҖ»еҮҪж•°avg(жҲҗз»©)] from д»Һе“Әеј иЎЁдёӯжҹҘжүҫж•°жҚ® [ж¶үеҸҠеҲ°жҲҗз»©пјҡжҲҗз»©иЎЁscore] where жҹҘиҜўжқЎд»¶ [йҷҗеҲ¶жқЎд»¶пјҡдёҚеҸҠж јиҜҫзЁӢпјҢе№іеқҮжҲҗз»©<60] group by еҲҶз»„ [жҜҸдёӘеӯҰз”ҹзҡ„е№іеқҮпјҡжҢүеӯҰеҸ·еҲҶз»„] having еҜ№еҲҶз»„з»“жһңжҢҮе®ҡжқЎд»¶ [йҷҗеҲ¶жқЎд»¶пјҡиҜҫзЁӢж•°зӣ®>2,жұҮжҖ»еҮҪж•°count(иҜҫзЁӢеҸ·)>2] order by еҜ№жҹҘиҜўз»“жһңжҺ’еәҸ[жІЎжңү]; */ select еӯҰеҸ·, avg(жҲҗз»©) as е№іеқҮжҲҗз»© from score where жҲҗз»© <60 group by еӯҰеҸ· having count(иҜҫзЁӢеҸ·)>=2;
еҰӮжһңдёҠйқўйўҳзӣ®дёҚдјҡеҒҡпјҢеҸҜд»ҘеӨҚд№ иҝҷйғЁеҲҶж¶үеҸҠеҲ°зҡ„sqlзҹҘиҜҶпјҡ
жҹҘиҜўжүҖжңүиҜҫзЁӢжҲҗз»©е°ҸдәҺ60еҲҶеӯҰз”ҹзҡ„еӯҰеҸ·гҖҒ姓еҗҚ
гҖҗзҹҘиҜҶзӮ№гҖ‘еӯҗжҹҘиҜў
1.зҝ»иҜ‘жҲҗеӨ§зҷҪиҜқ
1пјүжҹҘиҜўз»“жһңпјҡеӯҰз”ҹеӯҰеҸ·пјҢ姓еҗҚ
2пјүжҹҘиҜўжқЎд»¶пјҡжүҖжңүиҜҫзЁӢжҲҗз»© < 60 зҡ„еӯҰз”ҹпјҢйңҖиҰҒд»ҺжҲҗз»©иЎЁйҮҢжҹҘжүҫпјҢз”ЁеҲ°еӯҗжҹҘиҜў
第1жӯҘпјҢеҶҷеӯҗжҹҘиҜўпјҲжүҖжңүиҜҫзЁӢжҲҗз»© < 60 зҡ„еӯҰз”ҹпјү
select жҹҘиҜўз»“жһң[еӯҰеҸ·]
from д»Һе“Әеј иЎЁдёӯжҹҘжүҫж•°жҚ®[жҲҗз»©иЎЁпјҡscore]
where жҹҘиҜўжқЎд»¶[жҲҗз»© < 60]
group by еҲҶз»„[жІЎжңү]
having еҜ№еҲҶз»„з»“жһңжҢҮе®ҡжқЎд»¶[жІЎжңү]
order by еҜ№жҹҘиҜўз»“жһңжҺ’еәҸ[жІЎжңү]
limit д»ҺжҹҘиҜўз»“жһңдёӯеҸ–еҮәжҢҮе®ҡиЎҢ[жІЎжңү];
select еӯҰеҸ· from score where жҲҗз»© < 60;
第2жӯҘпјҢжҹҘиҜўз»“жһңпјҡеӯҰз”ҹеӯҰеҸ·пјҢ姓еҗҚпјҢжқЎд»¶жҳҜеүҚйқў1жӯҘжҹҘеҲ°зҡ„еӯҰеҸ·
select жҹҘиҜўз»“жһң[еӯҰеҸ·,姓еҗҚ]
from д»Һе“Әеј иЎЁдёӯжҹҘжүҫж•°жҚ®[еӯҰз”ҹиЎЁ:student]
where жҹҘиҜўжқЎд»¶[з”ЁеҲ°иҝҗз®—з¬Ұin]
group by еҲҶз»„[жІЎжңү]
having еҜ№еҲҶз»„з»“жһңжҢҮе®ҡжқЎд»¶[жІЎжңү]
order by еҜ№жҹҘиҜўз»“жһңжҺ’еәҸ[жІЎжңү]
limit д»ҺжҹҘиҜўз»“жһңдёӯеҸ–еҮәжҢҮе®ҡиЎҢ[жІЎжңү];
select еӯҰеҸ·,姓еҗҚ from student where еӯҰеҸ· in ( select еӯҰеҸ· from score where жҲҗз»© < 60 );
жҹҘиҜўжІЎжңүеӯҰе…ЁжүҖжңүиҜҫзҡ„еӯҰз”ҹзҡ„еӯҰеҸ·гҖҒ姓еҗҚ|
/* жҹҘжүҫеҮәеӯҰеҸ·пјҢжқЎд»¶пјҡжІЎжңүеӯҰе…ЁжүҖжңүиҜҫпјҢд№ҹе°ұжҳҜиҜҘеӯҰз”ҹйҖүдҝ®зҡ„иҜҫзЁӢж•° < жҖ»зҡ„иҜҫзЁӢж•° гҖҗиҖғеҜҹзҹҘиҜҶзӮ№гҖ‘inпјҢеӯҗжҹҘиҜў */ select еӯҰеҸ·,姓еҗҚ from student where еӯҰеҸ· in( select еӯҰеҸ· from score group by еӯҰеҸ· having count(иҜҫзЁӢеҸ·) < (select count(иҜҫзЁӢеҸ·) from course) );
жҹҘиҜўеҮәеҸӘйҖүдҝ®дәҶдёӨй—ЁиҜҫзЁӢзҡ„е…ЁйғЁеӯҰз”ҹзҡ„еӯҰеҸ·е’Ң姓еҗҚ|
select еӯҰеҸ·,姓еҗҚ from student where еӯҰеҸ· in( select еӯҰеҸ· from score group by еӯҰеҸ· having count(иҜҫзЁӢеҸ·)=2 );
1990е№ҙеҮәз”ҹзҡ„еӯҰз”ҹеҗҚеҚ•
/* жҹҘжүҫ1990е№ҙеҮәз”ҹзҡ„еӯҰз”ҹеҗҚеҚ• еӯҰз”ҹиЎЁдёӯеҮәз”ҹж—ҘжңҹеҲ—зҡ„зұ»еһӢжҳҜdatetime */ select еӯҰеҸ·,姓еҗҚ from student where year(еҮәз”ҹж—Ҙжңҹ)=1990;
жҹҘиҜўеҗ„科жҲҗз»©еүҚдёӨеҗҚзҡ„и®°еҪ•
иҝҷзұ»й—®йўҳе…¶е®һе°ұжҳҜеёёи§Ғзҡ„пјҡеҲҶз»„еҸ–жҜҸз»„жңҖеӨ§еҖјгҖҒжңҖе°ҸеҖјпјҢжҜҸз»„жңҖеӨ§зҡ„NжқЎпјҲtop Nпјүи®°еҪ•гҖӮ
е·ҘдҪңдёӯдјҡз»ҸеёёйҒҮеҲ°иҝҷж ·зҡ„дёҡеҠЎй—®йўҳпјҡ
еҰӮдҪ•жүҫеҲ°жҜҸдёӘзұ»еҲ«дёӢз”ЁжҲ·жңҖе–ңж¬ўзҡ„дә§е“ҒжҳҜе“ӘдёӘпјҹ
еҰӮжһңжүҫеҲ°жҜҸдёӘзұ»еҲ«дёӢз”ЁжҲ·зӮ№еҮ»жңҖеӨҡзҡ„5дёӘе•Ҷе“ҒжҳҜд»Җд№Ҳпјҹ
иҝҷзұ»й—®йўҳе…¶е®һе°ұжҳҜеёёи§Ғзҡ„пјҡеҲҶз»„еҸ–жҜҸз»„жңҖеӨ§еҖјгҖҒжңҖе°ҸеҖјпјҢжҜҸз»„жңҖеӨ§зҡ„NжқЎпјҲtop Nпјүи®°еҪ•гҖӮ
йқўеҜ№иҜҘзұ»й—®йўҳпјҢеҰӮдҪ•и§ЈеҶіе‘ўпјҹ
дёӢйқўжҲ‘们йҖҡиҝҮжҲҗз»©иЎЁзҡ„дҫӢеӯҗжқҘз»ҷеҮәзӯ”жЎҲгҖӮ
жҲҗз»©иЎЁжҳҜеӯҰз”ҹзҡ„жҲҗз»©пјҢйҮҢйқўжңүеӯҰеҸ·пјҲеӯҰз”ҹзҡ„еӯҰеҸ·пјүпјҢиҜҫзЁӢеҸ·пјҲеӯҰз”ҹйҖүдҝ®иҜҫзЁӢзҡ„иҜҫзЁӢеҸ·пјүпјҢжҲҗз»©пјҲеӯҰз”ҹйҖүдҝ®иҜҘиҜҫзЁӢеҸ–еҫ—зҡ„жҲҗз»©пјү
еҲҶз»„еҸ–жҜҸз»„жңҖеӨ§еҖј
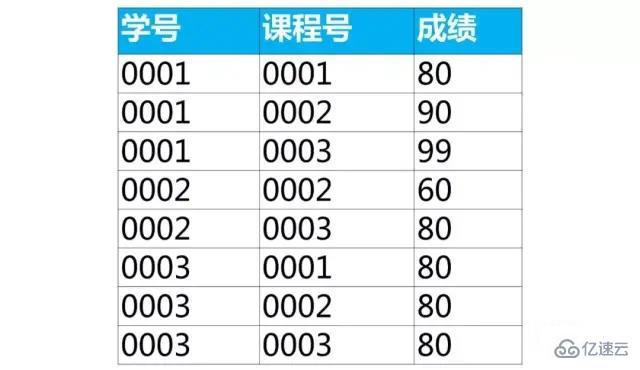
жЎҲдҫӢпјҡжҢүиҜҫзЁӢеҸ·еҲҶз»„еҸ–жҲҗз»©жңҖеӨ§еҖјжүҖеңЁиЎҢзҡ„ж•°жҚ®
жҲ‘们еҸҜд»ҘдҪҝз”ЁеҲҶз»„пјҲgroup byпјүе’ҢжұҮжҖ»еҮҪж•°еҫ—еҲ°жҜҸдёӘз»„йҮҢзҡ„дёҖдёӘеҖјпјҲжңҖеӨ§еҖјпјҢжңҖе°ҸеҖјпјҢе№іеқҮеҖјзӯүпјүгҖӮдҪҶжҳҜж— жі•еҫ—еҲ°жҲҗз»©жңҖеӨ§еҖјжүҖеңЁиЎҢзҡ„ж•°жҚ®гҖӮ
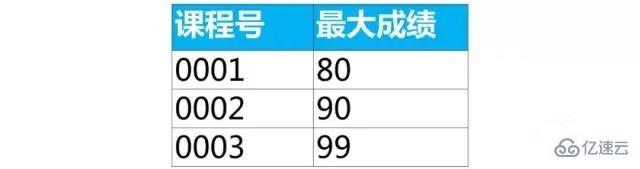
select иҜҫзЁӢеҸ·,max(жҲҗз»©) as жңҖеӨ§жҲҗз»© from score group by иҜҫзЁӢеҸ·;
жҲ‘们еҸҜд»ҘдҪҝз”Ёе…іиҒ”еӯҗжҹҘиҜўжқҘе®һзҺ°пјҡ
select * from score as a where жҲҗз»© = ( select max(жҲҗз»©) from score as b where b.иҜҫзЁӢеҸ· = a.иҜҫзЁӢеҸ·);
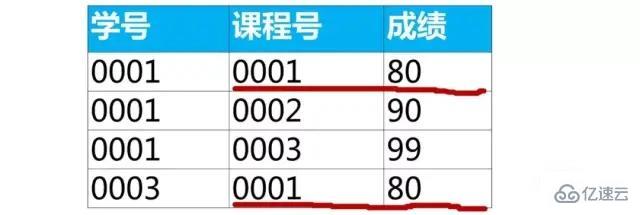
дёҠйқўжҹҘиҜўз»“жһңиҜҫзЁӢеҸ·вҖң0001вҖқжңү2иЎҢж•°жҚ®пјҢжҳҜеӣ дёәжңҖеӨ§жҲҗз»©80жңү2дёӘ
еҲҶз»„еҸ–жҜҸз»„жңҖе°ҸеҖј
жЎҲдҫӢпјҡжҢүиҜҫзЁӢеҸ·еҲҶз»„еҸ–жҲҗз»©жңҖе°ҸеҖјжүҖеңЁиЎҢзҡ„ж•°жҚ®
еҗҢж ·зҡ„дҪҝз”Ёе…іиҒ”еӯҗжҹҘиҜўжқҘе®һзҺ°
select * from score as a where жҲҗз»© = ( select min(жҲҗз»©) from score as b where b.иҜҫзЁӢеҸ· = a.иҜҫзЁӢеҸ·);
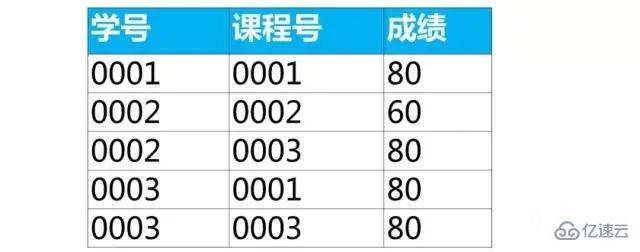
жҜҸз»„жңҖеӨ§зҡ„NжқЎи®°еҪ•
жЎҲдҫӢпјҡжҹҘиҜўеҗ„科жҲҗз»©еүҚдёӨеҗҚзҡ„и®°еҪ•
第1жӯҘпјҢжҹҘеҮәжңүе“Әдәӣз»„
жҲ‘们еҸҜд»ҘжҢүиҜҫзЁӢеҸ·еҲҶз»„пјҢжҹҘиҜўеҮәжңүе“Әдәӣз»„пјҢеҜ№еә”иҝҷдёӘй—®йўҳйҮҢе°ұжҳҜжңүе“ӘдәӣиҜҫзЁӢеҸ·
select иҜҫзЁӢеҸ·,max(жҲҗз»©) as жңҖеӨ§жҲҗз»© from score group by иҜҫзЁӢеҸ·;
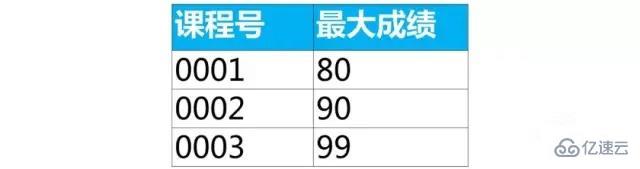
第2жӯҘпјҡе…ҲдҪҝз”Ёorder byеӯҗеҸҘжҢүжҲҗз»©йҷҚеәҸжҺ’еәҸпјҲdescпјүпјҢ然еҗҺдҪҝз”ЁlimtеӯҗеҸҘиҝ”еӣһtopNпјҲеҜ№еә”иҝҷдёӘй—®йўҳиҝ”еӣһзҡ„жҲҗз»©еүҚдёӨеҗҚпјү
-- иҜҫзЁӢеҸ·'0001' иҝҷдёҖз»„йҮҢжҲҗз»©еүҚ2еҗҚ select * from score where иҜҫзЁӢеҸ· = '0001' order by жҲҗз»© desc limit 2;
еҗҢж ·зҡ„пјҢеҸҜд»ҘеҶҷеҮәе…¶д»–з»„зҡ„пјҲе…¶д»–иҜҫзЁӢеҸ·пјүеҸ–еҮәжҲҗз»©еүҚ2еҗҚзҡ„sql
第3жӯҘпјҢдҪҝз”Ёunion all е°ҶжҜҸз»„йҖүеҮәзҡ„ж•°жҚ®еҗҲ并еҲ°дёҖиө·
-- е·ҰеҸіж»‘еҠЁеҸҜд»ҘеҸҜжӢҝеҲ°е…ЁйғЁsql (select * from score where иҜҫзЁӢеҸ· = '0001' order by жҲҗз»© desc limit 2) union all (select * from score where иҜҫзЁӢеҸ· = '0002' order by жҲҗз»© desc limit 2) union all (select * from score where иҜҫзЁӢеҸ· = '0003' order by жҲҗз»© desc limit 2);
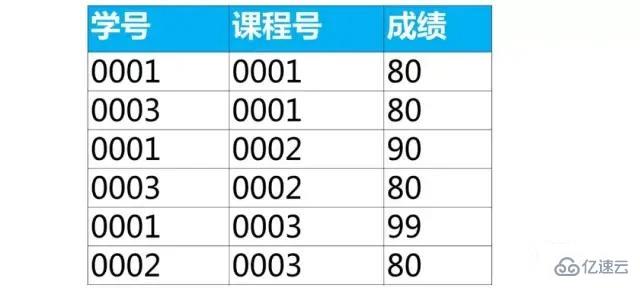
еүҚйқўжҲ‘们дҪҝз”Ёorder byеӯҗеҸҘжҢүжҹҗдёӘеҲ—йҷҚеәҸжҺ’еәҸпјҲdescпјүеҫ—еҲ°зҡ„жҳҜжҜҸз»„жңҖеӨ§зҡ„NдёӘи®°еҪ•гҖӮеҰӮжһңжғіиҰҒиҫҫеҲ°жҜҸз»„жңҖе°Ҹзҡ„NдёӘи®°еҪ•пјҢе°Ҷorder byеӯҗеҸҘжҢүжҹҗдёӘеҲ—еҚҮеәҸжҺ’еәҸпјҲascпјүеҚіеҸҜгҖӮ
жұӮtopNзҡ„й—®йўҳиҝҳеҸҜд»ҘдҪҝз”ЁиҮӘе®ҡд№үеҸҳйҮҸжқҘе®һзҺ°пјҢиҝҷдёӘеңЁеҗҺз»ӯеҶҚд»Ӣз»ҚгҖӮ
еҰӮжһңеҜ№еӨҡиЎЁеҗҲ并иҝҳдёҚдәҶи§Јзҡ„пјҢеҸҜд»ҘзңӢдёӢжҲ‘и®ІиҝҮзҡ„гҖҠд»Һйӣ¶еӯҰдјҡSQLгҖӢзҡ„вҖңеӨҡиЎЁжҹҘиҜўвҖқгҖӮ
жҖ»з»“
еёёи§ҒйқўиҜ•йўҳпјҡеҲҶз»„еҸ–жҜҸз»„жңҖеӨ§еҖјгҖҒжңҖе°ҸеҖјпјҢжҜҸз»„жңҖеӨ§зҡ„NжқЎпјҲtop Nпјүи®°еҪ•гҖӮ

жҹҘиҜўжүҖжңүеӯҰз”ҹзҡ„еӯҰеҸ·гҖҒ姓еҗҚгҖҒйҖүиҜҫж•°гҖҒжҖ»жҲҗз»©
selecta.еӯҰеҸ·,a.姓еҗҚ,count(b.иҜҫзЁӢеҸ·) as йҖүиҜҫж•°,sum(b.жҲҗз»©) as жҖ»жҲҗз»© from student as a left join score as b on a.еӯҰеҸ· = b.еӯҰеҸ· group by a.еӯҰеҸ·;
жҹҘиҜўе№іеқҮжҲҗз»©еӨ§дәҺ85зҡ„жүҖжңүеӯҰз”ҹзҡ„еӯҰеҸ·гҖҒ姓еҗҚе’Ңе№іеқҮжҲҗз»©
select a.еӯҰеҸ·,a.姓еҗҚ, avg(b.жҲҗз»©) as е№іеқҮжҲҗз»© from student as a left join score as b on a.еӯҰеҸ· = b.еӯҰеҸ· group by a.еӯҰеҸ· having avg(b.жҲҗз»©)>85;
жҹҘиҜўеӯҰз”ҹзҡ„йҖүиҜҫжғ…еҶөпјҡеӯҰеҸ·пјҢ姓еҗҚпјҢиҜҫзЁӢеҸ·пјҢиҜҫзЁӢеҗҚз§°
select a.еӯҰеҸ·, a.姓еҗҚ, c.иҜҫзЁӢеҸ·,c.иҜҫзЁӢеҗҚз§° from student a inner join score b on a.еӯҰеҸ·=b.еӯҰеҸ· inner join course c on b.иҜҫзЁӢеҸ·=c.иҜҫзЁӢеҸ·;
жҹҘиҜўеҮәжҜҸй—ЁиҜҫзЁӢзҡ„еҸҠж јдәәж•°е’ҢдёҚеҸҠж јдәәж•°
-- иҖғеҜҹcaseиЎЁиҫҫејҸ select иҜҫзЁӢеҸ·, sum(case when жҲҗз»©>=60 then 1 else 0 end) as еҸҠж јдәәж•°, sum(case when жҲҗз»© < 60 then 1 else 0 end) as дёҚеҸҠж јдәәж•° from score group by иҜҫзЁӢеҸ·;
дҪҝз”ЁеҲҶж®ө[100-85],[85-70],[70-60],[<60]жқҘз»ҹи®Ўеҗ„科жҲҗз»©пјҢеҲҶеҲ«з»ҹи®Ўпјҡеҗ„еҲҶж•°ж®өдәәж•°пјҢиҜҫзЁӢеҸ·е’ҢиҜҫзЁӢеҗҚз§°
-- иҖғеҜҹcaseиЎЁиҫҫејҸ select a.иҜҫзЁӢеҸ·,b.иҜҫзЁӢеҗҚз§°, sum(case when жҲҗз»© between 85 and 100 then 1 else 0 end) as '[100-85]', sum(case when жҲҗз»© >=70 and жҲҗз»©<85 then 1 else 0 end) as '[85-70]', sum(case when жҲҗз»©>=60 and жҲҗз»©<70 then 1 else 0 end) as '[70-60]', sum(case when жҲҗз»©<60 then 1 else 0 end) as '[<60]' from score as a right join course as b on a.иҜҫзЁӢеҸ·=b.иҜҫзЁӢеҸ· group by a.иҜҫзЁӢеҸ·,b.иҜҫзЁӢеҗҚз§°;
жҹҘиҜўиҜҫзЁӢзј–еҸ·дёә0003дё”иҜҫзЁӢжҲҗз»©еңЁ80еҲҶд»ҘдёҠзҡ„еӯҰз”ҹзҡ„еӯҰеҸ·е’Ң姓еҗҚ|
select a.еӯҰеҸ·,a.姓еҗҚ from student as a inner join score as b on a.еӯҰеҸ·=b.еӯҰеҸ· where b.иҜҫзЁӢеҸ·='0003' and b.жҲҗз»©>80;
дёӢйқўжҳҜеӯҰз”ҹзҡ„жҲҗз»©иЎЁпјҲиЎЁеҗҚscoreпјҢеҲ—еҗҚпјҡеӯҰеҸ·гҖҒиҜҫзЁӢеҸ·гҖҒжҲҗз»©пјү
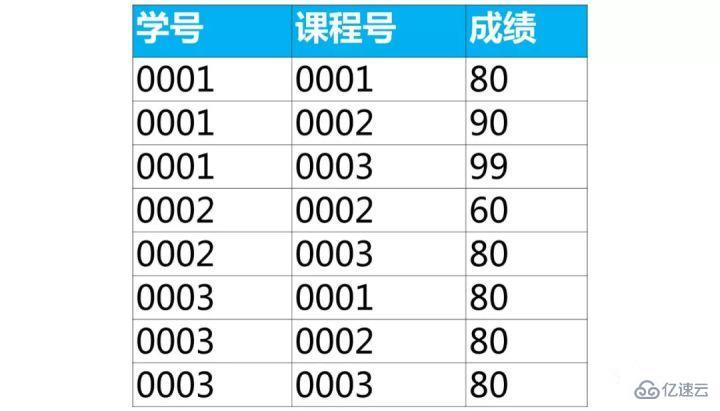
дҪҝз”Ёsqlе®һзҺ°е°ҶиҜҘиЎЁиЎҢиҪ¬еҲ—дёәдёӢйқўзҡ„иЎЁз»“жһ„
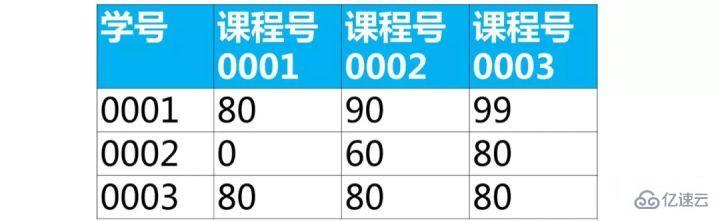
гҖҗйқўиҜ•йўҳгҖ‘дёӢйқўжҳҜеӯҰз”ҹзҡ„жҲҗз»©иЎЁпјҲиЎЁеҗҚscoreпјҢеҲ—еҗҚпјҡеӯҰеҸ·гҖҒиҜҫзЁӢеҸ·гҖҒжҲҗз»©пјү

дҪҝз”Ёsqlе®һзҺ°е°ҶиҜҘиЎЁиЎҢиҪ¬еҲ—дёәдёӢйқўзҡ„иЎЁз»“жһ„
гҖҗи§Јзӯ”гҖ‘
第1жӯҘпјҢдҪҝз”ЁеёёйҮҸеҲ—иҫ“еҮәзӣ®ж ҮиЎЁзҡ„з»“жһ„
еҸҜд»ҘзңӢеҲ°жҹҘиҜўз»“жһңе·Із»Ҹе’Ңзӣ®ж ҮиЎЁйқһеёёжҺҘиҝ‘дәҶ
select еӯҰеҸ·,'иҜҫзЁӢеҸ·0001','иҜҫзЁӢеҸ·0002','иҜҫзЁӢеҸ·0003' from score;
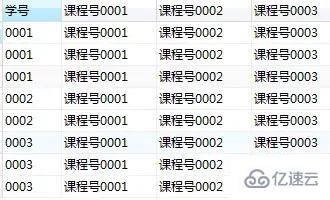
第2жӯҘпјҢдҪҝз”ЁcaseиЎЁиҫҫејҸпјҢжӣҝжҚўеёёйҮҸеҲ—дёәеҜ№еә”зҡ„жҲҗз»©
select еӯҰеҸ·, (case иҜҫзЁӢеҸ· when '0001' then жҲҗз»© else 0 end) as 'иҜҫзЁӢеҸ·0001', (case иҜҫзЁӢеҸ· when '0002' then жҲҗз»© else 0 end) as 'иҜҫзЁӢеҸ·0002', (case иҜҫзЁӢеҸ· when '0003' then жҲҗз»© else 0 end) as 'иҜҫзЁӢеҸ·0003' from score;
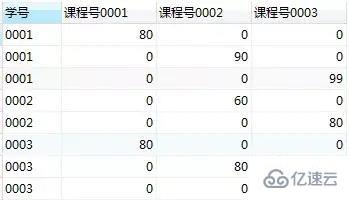
еңЁиҝҷдёӘжҹҘиҜўз»“жһңдёӯпјҢжҜҸдёҖиЎҢиЎЁзӨәдәҶжҹҗдёӘеӯҰз”ҹжҹҗдёҖй—ЁиҜҫзЁӢзҡ„жҲҗз»©гҖӮжҜ”еҰӮ第дёҖиЎҢжҳҜ'еӯҰеҸ·0001'йҖүдҝ®'иҜҫзЁӢеҸ·00001'зҡ„жҲҗз»©пјҢиҖҢе…¶д»–дёӨеҲ—зҡ„'иҜҫзЁӢеҸ·0002'е’Ң'иҜҫзЁӢеҸ·0003'жҲҗз»©дёә0гҖӮ
жҜҸдёӘеӯҰз”ҹйҖүдҝ®жҹҗй—ЁиҜҫзЁӢзҡ„жҲҗз»©еңЁдёӢеӣҫзҡ„жҜҸдёӘж–№еқ—еҶ…гҖӮжҲ‘们еҸҜд»ҘйҖҡиҝҮеҲҶз»„пјҢеҸ–еҮәжҜҸй—ЁиҜҫзЁӢзҡ„жҲҗз»©гҖӮ

第3е…іпјҢеҲҶз»„
еҲҶз»„пјҢ并дҪҝз”ЁжңҖеӨ§еҖјеҮҪж•°maxеҸ–еҮәдёҠеӣҫжҜҸдёӘж–№еқ—йҮҢзҡ„жңҖеӨ§еҖј
select еӯҰеҸ·, max(case иҜҫзЁӢеҸ· when '0001' then жҲҗз»© else 0 end) as 'иҜҫзЁӢеҸ·0001', max(case иҜҫзЁӢеҸ· when '0002' then жҲҗз»© else 0 end) as 'иҜҫзЁӢеҸ·0002', max(case иҜҫзЁӢеҸ· when '0003' then жҲҗз»© else 0 end) as 'иҜҫзЁӢеҸ·0003' from score group by еӯҰеҸ·;
иҝҷж ·жҲ‘们е°ұеҫ—еҲ°дәҶзӣ®ж ҮиЎЁпјҲиЎҢеҲ—дә’жҚўпјү
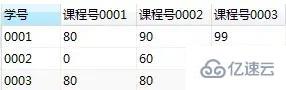
вҖңmysqlеҹәзЎҖзҹҘиҜҶжұҮжҖ»вҖқзҡ„еҶ…е®№е°ұд»Ӣз»ҚеҲ°иҝҷйҮҢдәҶпјҢж„ҹи°ўеӨ§е®¶зҡ„йҳ…иҜ»гҖӮеҰӮжһңжғідәҶи§ЈжӣҙеӨҡиЎҢдёҡзӣёе…ізҡ„зҹҘиҜҶеҸҜд»Ҙе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–е°ҶдёәеӨ§е®¶иҫ“еҮәжӣҙеӨҡй«ҳиҙЁйҮҸзҡ„е®һз”Ёж–Үз« пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ