жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жң¬зҜҮеҶ…е®№д»Ӣз»ҚдәҶвҖңPythonеҶ…зҪ®ж•°жҚ®з»“жһ„еҲ—иЎЁдёҺе…ғз»„зҡ„иҜҰз»Ҷд»Ӣз»ҚвҖқзҡ„жңүе…ізҹҘиҜҶпјҢеңЁе®һйҷ…жЎҲдҫӢзҡ„ж“ҚдҪңиҝҮзЁӢдёӯпјҢдёҚе°‘дәәйғҪдјҡйҒҮеҲ°иҝҷж ·зҡ„еӣ°еўғпјҢжҺҘдёӢжқҘе°ұи®©е°Ҹзј–еёҰйўҶеӨ§е®¶еӯҰд№ дёҖдёӢеҰӮдҪ•еӨ„зҗҶиҝҷдәӣжғ…еҶөеҗ§пјҒеёҢжңӣеӨ§е®¶д»”з»Ҷйҳ…иҜ»пјҢиғҪеӨҹеӯҰжңүжүҖжҲҗпјҒ
1. еәҸеҲ—
2. еҲ—иЎЁ
2.1 еҲ—иЎЁзҡ„зү№жҖ§
2.1.1 еҲ—иЎЁзҡ„иҝһжҺҘж“ҚдҪңз¬Ұе’ҢйҮҚеӨҚж“ҚдҪңз¬Ұ
2.1.3 еҲ—иЎЁзҡ„зҙўеј•
2.1.4 еҲ—иЎЁзҡ„еҲҮзүҮ
2.1.5 еҲ—иЎЁзҡ„еҫӘзҺҜпјҲforпјү
2.2 еҲ—иЎЁзҡ„еҹәжң¬ж“ҚдҪңпјҲеўһеҲ ж”№жҹҘпјү
2.2.1 еҲ—иЎЁзҡ„еўһеҠ
2.2.2 еҲ—иЎЁзҡ„дҝ®ж”№
2.2.3 жҹҘзңӢ
2.2.4 еҲ—иЎЁзҡ„еҲ йҷӨ
2.2.5 е…¶д»–ж“ҚдҪң
3. е…ғз»„
3.1 е…ғз»„зҡ„еҲӣе»ә
3.2 е…ғз»„зҡ„зү№жҖ§
3.3 е…ғз»„зҡ„е‘ҪеҗҚ
4. ж·ұжӢ·иҙқе’Ңжө…жӢ·иҙқ
4.1 еҖјзҡ„еј•з”Ё
4.2 жө…жӢ·иҙқ
4.3 ж·ұжӢ·иҙқ
5. is е’Ң ==зҡ„еҜ№жҜ”
жҖ»з»“
еәҸеҲ—пјҡжҲҗе‘ҳжңүеәҸжҺ’еҲ—пјҢеҸҜд»ҘйҖҡиҝҮдёӢж ҮеҒҸ移йҮҸи®ҝй—®еҲ°е®ғзҡ„дёҖдёӘжҲ–иҖ…еҮ дёӘжҲҗе‘ҳпјҢиҝҷзұ»зұ»еһӢз»ҹз§°дёәеәҸеҲ—гҖӮ
еәҸеҲ—ж•°жҚ®еҢ…жӢ¬пјҡеӯ—з¬ҰдёІгҖҒеҲ—иЎЁе’Ңе…ғз»„зұ»еһӢгҖӮ
зү№зӮ№пјҡйғҪж”ҜжҢҒзҙўеј•е’ҢеҲҮзүҮж“ҚдҪңз¬ҰпјӣжҲҗе‘ҳе…ізі»ж“ҚдҪңз¬Ұ(in,not in)пјӣиҝһжҺҘз¬Ұ(+)&йҮҚеӨҚж“ҚдҪңз¬Ұ(*)
ж•°з»„arrayпјҡеӯҳеӮЁеҗҢз§Қж•°жҚ®зұ»еһӢзҡ„ж•°жҚ®з»“жһ„гҖӮ[1,2,3],[1.1,2.2,3.1]
еҲ—иЎЁlistпјҡжү“дәҶжҝҖзҙ зҡ„ж•°з»„пјҢеҸҜд»ҘеӯҳеӮЁдёҚеҗҢж•°жҚ®зұ»еһӢзҡ„ж•°жҚ®з»“жһ„гҖӮ[1,2.2,вҖҳhello']
еҲ—иЎЁзҡ„еҲӣе»әпјҡ
li = [] #з©әжү©еҲ—иЎЁ print(li, type(li)) li1 = [1] #еҸӘжңүдёҖдёӘе…ғзҙ зҡ„еҲ—иЎЁ print(li1, type(li1))
print([1,2] + [2,3]) #[1,2,2,3] print([1,2] *3) #[1,2,1,2,1,2]
print(1 in [1,2,3]) #True """#иҝ”еӣһзҡ„ж•°жҚ®зұ»еһӢдёәboolеһӢ еёғе°”зұ»еһӢпјҡ True: 1 False: 0 """ print(1 in ["a", True, [1,2]]) #з”ұдәҺжӯӨеӨ„жңүTrueжүҖд»Ҙдјҡй»ҳи®Өи®Өдёә1еұһдәҺиҜҘеҲ—иЎЁ print(1 in ["a", False, [1,2]]) #False
ж №жҚ®зҙўеј•жқҘиҝ”еӣһзҙўеј•еҲ°зҡ„еҖјпјӣ
li = [1,2,3,[1,2,3]] print(li[0]) #иҝ”еӣһж•°еҖј1 print(li[-1]) #иҝ”еӣһеҖ’数第дёҖдёӘеҖј[1, 2, 3] li1 = [1,2,3,[1,"b",3]] print(li1[-1]) #иҝ”еӣһеҖ’数第дёҖдёӘеҖј[1, 'b', 3] print(li1[-1][0]) #иҝ”еӣһеҖ’数第дёҖдёӘе…ғзҙ дёӯзҡ„第дёҖдёӘе…ғеҖј 1 print(li1[3][-1]) #иҝ”еӣһ第еӣӣдёӘе…ғзҙ дёӯзҡ„еҖ’数第дёҖдёӘеҖј 3
li = ['172','25','254','100'] print(li[:2]) #жӢҝеҮәеҲ—иЎЁдёӯзҡ„еүҚдёӨдёӘе…ғзҙ ['172', '25'] print(li[1:]) #жӢҝеҮәеҲ—иЎЁдёӯзҡ„第дәҢдёӘеҲ°жңҖеҗҺдёҖдёӘе…ғзҙ ['25', '254', '100'] print(li[::-1]) #е°ҶеҲ—иЎЁеҸҚиҪ¬['100', '254', '25', '172']
еҰӮе·ІзҹҘдёҖдёӘеҲ—иЎЁдҝЎжҒҜдёә [вҖҳ172',вҖҳ25',вҖҳ254',вҖҳ100']пјҢзҺ°еңЁйңҖиҰҒиҫ“еҮә'100-254-25вҖңпјӣ
print('-'.join(li[3:0:-1])) #иЎЁзӨәд»Һ第еӣӣдёӘе…ғзҙ ејҖе§ӢпјҢеҖ’еәҸдҫқж¬ЎжӢҝеҮә然еҗҺеҶҚжӢјжҺҘиө·жқҘ
print('-'.join(li[:0:-1])) #иЎЁзӨәд»ҺжңҖеҗҺдёҖдёӘе…ғзҙ ејҖе§ӢпјҢеҖ’еәҸдҫқж¬ЎжӢҝеҮә然еҗҺеҶҚжӢјжҺҘиө·жқҘ
print('-'.join(li[1:][::-1])) #иЎЁзӨәд»Һ第дәҢдёӘе…ғзҙ ејҖе§ӢпјҢе…ЁйғЁжӢҝеҮәд№ӢеҗҺеңЁеҖ’еәҸжӢјжҺҘnames = ['е°Ҹеј ','еј е“Ҙ','еј еёҲ']
for name in names:
print(f"zxkзҡ„еҲ«еҗҚжҳҜ:{name}")
иҝҪеҠ
иҝҪеҠ й»ҳи®ӨжҳҜеңЁеҲ—иЎЁзҡ„жңҖеҗҺж·»еҠ пјӣ
li = [1,2,3] li.append(4) print(li) #[1, 2, 3, 4]
еңЁеҲ—иЎЁејҖеӨҙж·»еҠ
li = [1,2,3] li.insert(0,'cat') print(li) #['cat', 1, 2, 3] li = [1,2,3] li.insert(2,'cat') print(li) #еңЁзҙўеј•2еүҚйқўж·»еҠ cat[1, 2, 'cat', 3]
дёҖж¬ЎиҝҪеҠ еӨҡдёӘе…ғзҙ
li = [1,2,3] #ж·»еҠ 4,5,6, li.append([4,5,6]) print(li) #[1, 2, 3, [4, 5, 6]] li.extend([4,5,6]) print(li) #[1, 2, 3, 4, 5, 6]
йҖҡиҝҮзҙўеј•е’ҢеҲҮзүҮйҮҚж–°иөӢеҖјзҡ„ж–№ејҸеҺ»дҝ®ж”№пјӣ
li = [1,2,3] li[0] = 'cat' print(li) #['cat', 2, 3] li[-1] = 'westos' print(li) #['cat', 2, 'westos'] li = [1,2,3] li[:2] = ['cat','westos'] #иЎЁзӨәд»Һ第дёҖдёӘејҖе§Ӣдҝ®ж”№дёӨдёӘ['cat', 'westos', 3] print(li)
йҖҡиҝҮзҙўеј•е’ҢеҲҮзүҮжҹҘзңӢе…ғзҙ пјҢжҹҘзңӢзҙўеј•еҖје’ҢеҮәзҺ°ж¬Ўж•°пјӣ
li = [1,2,3,4,3,2,3] print(li.count(1)) #жҹҘзңӢж•°еӯ—1еҮәзҺ°зҡ„ж¬Ўж•° print(li.index(3)) #жҹҘзңӢе…ғзҙ еҜ№еә”зҡ„зҙўеј•
ж №жҚ®зҙўеј•еҲ йҷӨ
li = [1,2,3]
#print(li.pop(1)) #е°Ҷзј©зҙўеј•зҡ„第дёҖдёӘеҲ йҷӨпјҢ[1, 3]
delete_num = li.pop(-1)
print(li)
print("еҲ йҷӨзҡ„е…ғзҙ жҳҜпјҡ",delete_num) #еҲ йҷӨзҡ„е…ғзҙ жҳҜпјҡ 3ж №жҚ®valueеҖјеҲ йҷӨ
li = [1,2,3] li.remove(3) print(li) #[1, 2]
е…ЁйғЁжё…з©ә
li =[1,2,3] li.clear() print(li) #[]
йҷӨдәҶдёҠйқўзҡ„д№ӢеӨ–иҝҳжңүеҸҚиҪ¬пјҢжҺ’еәҸпјҢеӨҚеҲ¶зӯүж“ҚдҪңпјӣ
li =[5,4,13,20] li.reverse() print(li) #еҸҚиҪ¬ [20, 13, 4, 5] li.sort() print(li) #д»Һе°ҸеҲ°еӨ§жҺ’еәҸ[4, 5, 13, 20] #sortй»ҳи®Өд»Һе°ҸеҲ°еӨ§пјҢеҰӮжһңжғіиҰҒд»ҺеӨ§еҲ°е°ҸпјҢйңҖиҰҒз”ЁreverseжқҘеҸҚиҪ¬ li.sort(reverse=True) print(li) #д»ҺеӨ§еҲ°е°ҸжҺ’еәҸ[20, 13, 5, 4] li1 = li.copy() print(id(li),id(li1)) #еӨҚеҲ¶еүҚеҗҺдёӨдёӘеҲ—иЎЁзҡ„IDдёҚдёҖж · 2097933779264 2097933779648 print(li,li1) #[20, 13, 5, 4] [20, 13, 5, 4]
е…ғз»„tupleпјҡеёҰдәҶзҙ§з®Қе’’зҡ„еҲ—иЎЁпјҢе’ҢеҲ—иЎЁзҡ„е”ҜдёҖеҢәеҲ«жҳҜдёҚиғҪеўһеҲ ж”№гҖӮ
е…ғз»„дёӯеҸӘжңүдёҖдёӘе…ғзҙ ж—¶дёҖе®ҡиҰҒж·»еҠ йҖ—еҸ·пјҢдёҚ然дјҡе°Ҷе…¶иҜ•еҒҡеҜ№еә”зҡ„дҝЎжҒҜпјҢ
t1 = () #з©әе…ғз»„ print(t1,type(t1)) t2 = (1) #еҸӘжңүеҚ•дёӘе…ғзҙ ж—¶дёҚжҳҜе…ғз»„пјҢеҪ“иҰҒжҳҜе…ғз»„жҳҜиҰҒеҠ йҖ—еҸ· print(t2,type(t2)) #1 <class 'int'> t3 = (1,2.2,True,[1,2,3,]) print(t3,type(t3)) ##(1, 2.2, True, [1, 2, 3]) <class 'tuple'>
з”ұдәҺе…ғз»„жҳҜеёҰдәҶзҙ§з®Қе’’зҡ„еҲ—иЎЁпјҢжүҖд»ҘжІЎжңүеўһеҲ ж”№зҡ„зү№жҖ§пјӣ
1. иҝһжҺҘз¬Ұе’ҢйҮҚеӨҚж“ҚдҪңз¬Ұ print((1,2,3)+(3,)) #(1, 2, 3, 3) print((1,2,3) *2) #(1, 2, 3, 1, 2, 3) 2. жҲҗе‘ҳж“ҚдҪңз¬Ұ print(1 in (1,2,3)) #True 3. еҲҮзүҮе’Ңзҙўеј• t = (1,2,3) print(t[0]) #1 print(t[-1]) #3 print(t[:2]) #(1, 2) print(t[1:]) #(2, 3) print(t[::-1]) #(3, 2, 1)
жҹҘзңӢпјҡйҖҡиҝҮзҙўеј•е’ҢеҲҮзүҮжҹҘзңӢе…ғзҙ пјҢжҹҘзңӢзҙўеј•еҖје’ҢеҮәзҺ°ж¬Ўж•°пјӣ
t = (1,4,5,2,3,4) print(t.count(4)) #з»ҹи®Ў4еҮәзҺ°зҡ„ж¬Ўж•°пјҢиҝ”еӣһеҖјдёә2 print(t.index(2)) #жҹҘзңӢе…ғзҙ 2 зҡ„пјҢиҝ”еӣһзҡ„зҙўеј•еҖјдёә3
TupleиҝҳжңүдёҖдёӘе…„ејҹпјҢеҸ«namedtupleгҖӮиҷҪ然йғҪжҳҜtupleпјҢдҪҶжҳҜеҠҹиғҪжӣҙдёәејәеӨ§гҖӮ collections.namedtuple(typename, field_names) typenameпјҡзұ»еҗҚз§° field_names: е…ғз»„дёӯе…ғзҙ зҡ„еҗҚз§°
е®һдҫӢеҢ–е‘ҪеҗҚе…ғз»„
# import datetime
# today = datetime.date.today()
# print(today)
tuple = ('name','age','city') #жҷ®йҖҡзҡ„е…ғз»„ж јејҸпјҢеҪ“йңҖиҰҒеҸ–еҮәж—¶пјҢйңҖиҰҒдёҖдёӘдёҖдёӘеҸ–еҮәдҝЎжҒҜ
print(tuple[0],tuple[1],tuple[2]) # name age cityеҸҜд»Ҙд»ҺcollectionsжЁЎеқ—дёӯеҜје…Ҙnamedtupleе·Ҙе…·:
from collections import namedtuple
#1.еҲӣе»әе‘ҪеҗҚе…ғз»„еҜ№иұЎUser
User = namedtuple('User',('name','age','city'))
#2.з»ҷе‘ҪеҗҚе…ғз»„дј еҖј
user1 = User("zxk",24,"иҘҝе®ү")
#3.жү“еҚ°е‘ҪеҗҚе…ғз»„
print(user1) #User(name='zxk', age=24, city='иҘҝе®ү')
# 4. иҺ·еҸ–е‘ҪеҗҚе…ғз»„жҢҮе®ҡзҡ„дҝЎжҒҜ
print(user1.name) #zxk
print(user1.age) #24
print(user1.city) #иҘҝе®ү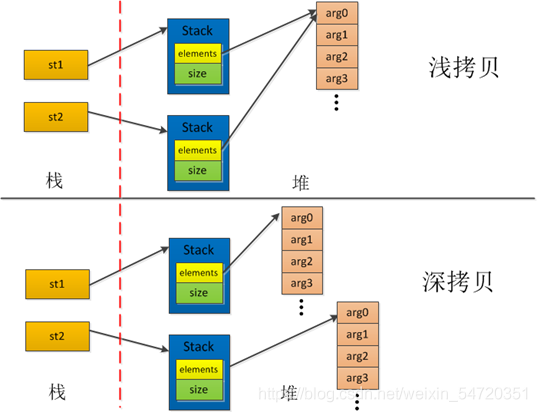
й—®йўҳ: ж·ұжӢ·иҙқе’Ңжө…жӢ·иҙқзҡ„еҢәеҲ«? pythonдёӯеҰӮдҪ•жӢ·иҙқдёҖдёӘеҜ№иұЎ?
иөӢеҖјпјҡ еҲӣе»әдәҶеҜ№иұЎзҡ„дёҖдёӘж–°зҡ„еј•з”ЁпјҢдҝ®ж”№е…¶дёӯд»»ж„ҸдёҖдёӘеҸҳйҮҸйғҪдјҡеҪұе“ҚеҲ°еҸҰдёҖдёӘгҖӮ(=)
жө…жӢ·иҙқпјҡ еҜ№еҸҰеӨ–дёҖдёӘеҸҳйҮҸзҡ„еҶ…еӯҳең°еқҖзҡ„жӢ·иҙқпјҢиҝҷдёӨдёӘеҸҳйҮҸжҢҮеҗ‘еҗҢдёҖдёӘеҶ…еӯҳең°еқҖзҡ„еҸҳйҮҸеҖјгҖӮ(li.copy(), copy.copy())
е…¬з”ЁдёҖдёӘеҖјпјӣ
иҝҷдёӨдёӘеҸҳйҮҸзҡ„еҶ…еӯҳең°еқҖдёҖж ·пјӣ
еҜ№е…¶дёӯдёҖдёӘеҸҳйҮҸзҡ„еҖјж”№еҸҳпјҢеҸҰеӨ–дёҖдёӘеҸҳйҮҸзҡ„еҖјд№ҹдјҡж”№еҸҳпјӣ
ж·ұжӢ·иҙқпјҡ дёҖдёӘеҸҳйҮҸеҜ№еҸҰеӨ–дёҖдёӘеҸҳйҮҸзҡ„еҖјжӢ·иҙқгҖӮ(copy.deepcopy())
дёӨдёӘеҸҳйҮҸзҡ„еҶ…еӯҳең°еқҖдёҚеҗҢпјӣ
дёӨдёӘеҸҳйҮҸеҗ„жңүиҮӘе·ұзҡ„еҖјпјҢдё”дә’дёҚеҪұе“Қпјӣ
еҜ№е…¶д»»ж„ҸдёҖдёӘеҸҳйҮҸзҡ„еҖјзҡ„ж”№еҸҳдёҚдјҡеҪұе“ҚеҸҰеӨ–дёҖдёӘпјӣ
nums1 = [1,2,3] nums2 = nums1 nums1.append(4) print(nums2) # [1, 2, 3, 4]
еӣ дёәnum1е’Ңnum2жҢҮеҗ‘еҗҢдёҖдёӘеҶ…еӯҳз©әй—ҙпјҢжүҖд»ҘеҪ“nums1ж·»еҠ еҖјж—¶пјҢзӣёеҪ“дәҺnums2д№ҹж·»еҠ дәҶеҖјгҖӮ
n1 = [1,2,3] n2 = n1.copy() #n1.copyе’Ңn1[:]йғҪеҸҜд»Ҙе®һзҺ°жӢ·иҙқгҖӮ print(id(n1),id(n2)) #2708901331648 2708901331264 n1.append(4) print(n2) #n1е’Ңn2зҡ„еҶ…еӯҳең°еқҖдёҚеҗҢпјҢдҝ®ж”№е№¶дёҚдә’зӣёеҪұе“Қ [1, 2, 3]
еҠ зІ—ж ·ејҸ
жңүеҲ—иЎЁеөҢеҘ—ж—¶пјҢжҲ–иҖ…иҜҙеҲ—иЎЁдёӯеҢ…еҗ«еҸҜеҸҳж•°жҚ®зұ»еһӢж—¶пјҢдёҖе®ҡиҰҒйҖүжӢ©ж·ұжӢ·иҙқ.
еҸҜеҸҳж•°жҚ®зұ»еһӢпјҲеҸҜеўһеҲ ж”№зҡ„пјүпјҡеҲ—иЎЁпјҲlistпјү
дёҚеҸҜеҸҳж•°жҚ®зұ»еһӢпјҡж•°еҖјпјҢеӯ—з¬ҰдёІпјҲstrпјүпјҢе…ғз»„пјҲtupleпјү namedtupleпјӣеҸҳйҮҸжҢҮеҗ‘еҶ…еӯҳз©әй—ҙзҡ„еҖјдёҚдјҡж”№еҸҳгҖӮ
n1 = [1,2,[1,2]] n2 = n1.copy() #n1е’Ңn2зҡ„еҶ…еӯҳең°еқҖпјҡзҡ„зЎ®жӢ·иҙқдәҶ #2859072423168 2859072422336 print(id(n1),id(n2)) #n1[-1]е’Ңn2[-1]зҡ„еҶ…еӯҳең°еқҖпјҡ #жңҖеҗҺдёҖдёӘе…ғзҙ зҡ„ең°еқҖпјҡ2859072425664 2859072425664 print(id(n1[-1]),id(n2[-1])) n1[-1].append(4) print(n1) #[1, 2, [1, 2, 4]] print(n2) #[1, 2, [1, 2, 4]]
ж·ұжӢ·иҙқе’Ңжө…жӢ·иҙқжңҖж №жң¬зҡ„еҢәеҲ«еңЁдәҺжҳҜеҗҰзңҹжӯЈиҺ·еҸ–дёҖдёӘеҜ№иұЎзҡ„еӨҚеҲ¶е®һдҪ“пјҢиҖҢдёҚжҳҜеј•з”ЁгҖӮ
еҒҮи®ҫBеӨҚеҲ¶дәҶAпјҢеңЁдҝ®ж”№Aзҡ„ж—¶еҖҷпјҢзңӢBжҳҜеҗҰеҸ‘з”ҹеҸҳеҢ–пјҡ
еҰӮжһңBи·ҹзқҖд№ҹеҸҳдәҶпјҢиҜҙжҳҺжҳҜжө…жӢ·иҙқпјҢжӢҝдәәжүӢзҹӯпјҒпјҲдҝ®ж”№е ҶеҶ…еӯҳдёӯзҡ„еҗҢдёҖдёӘеҖјпјү
еҰӮжһңBжІЎжңүж”№еҸҳпјҢиҜҙжҳҺжҳҜж·ұжӢ·иҙқпјҢиҮӘйЈҹе…¶еҠӣпјҒпјҲдҝ®ж”№е ҶеҶ…еӯҳдёӯзҡ„дёҚеҗҢзҡ„еҖјпјү
еҰӮдҪ•е®һзҺ°ж·ұжӢ·иҙқ copy.deepcopy
import copy n1 = [1,2,[1,2]] n2 = copy.deepcopy(n1) #n1е’Ңn2зҡ„еҶ…еӯҳең°еқҖпјҡзҡ„зЎ®жӢ·иҙқдәҶ print(id(n1),id(n2)) #2894603422016 2894603421056 #n1[-1]е’Ңn2[-1]зҡ„еҶ…еӯҳең°еқҖпјҡ print(id(n1[-1]),id(n2[-1])) #жңҖеҗҺдёҖдёӘе…ғзҙ зҡ„ең°еқҖпјҡ2894603422272 2894603419776 n1[-1].append(4) #n1 = [1, 2, [1, 2, 4]] print(n2) #n2 = [1, 2, [1, 2]]
еңЁ python иҜӯиЁҖдёӯ пјҡ
==пјҡеҲӨж–ӯзұ»еһӢе’ҢеҖјжҳҜеҗҰзӣёзӯү
is: зұ»еһӢе’ҢеҖјжҳҜеҗҰзӣёзӯүпјҢеҶ…еӯҳең°еқҖжҳҜеҗҰзӣёзӯү
== isе’Ң==дёӨз§Қиҝҗз®—з¬ҰеңЁеә”з”ЁдёҠзҡ„жң¬иҙЁеҢәеҲ«жҳҜпјҡ
1). PythonдёӯеҜ№иұЎзҡ„дёүдёӘеҹәжң¬иҰҒзҙ пјҢеҲҶеҲ«жҳҜпјҡid(иә«д»Ҫж ҮиҜҶ)гҖҒtype(ж•°жҚ®зұ»еһӢ)е’Ңvalue(еҖј)гҖӮ
2). isе’Ң==йғҪжҳҜеҜ№еҜ№иұЎиҝӣиЎҢжҜ”иҫғеҲӨж–ӯдҪңз”Ёзҡ„пјҢдҪҶеҜ№еҜ№иұЎжҜ”иҫғеҲӨж–ӯзҡ„еҶ…容并дёҚзӣёеҗҢгҖӮ
3). ==з”ЁжқҘжҜ”иҫғеҲӨж–ӯдёӨдёӘеҜ№иұЎзҡ„value(еҖј)жҳҜеҗҰзӣёзӯүпјӣ(typeе’Ңvalue)
isд№ҹиў«еҸ«еҒҡеҗҢдёҖжҖ§иҝҗз®—з¬ҰпјҢ дјҡеҲӨж–ӯidжҳҜеҗҰзӣёеҗҢ;(id, type е’Ңvalue)
print(1 == '1') #з”ұдәҺж•°жҚ®зұ»еһӢдёҚдёҖиҮҙFalse li = [1,2,3] li1 = li.copy() print(li == li1) #True #зұ»еһӢе’ҢеҖјзӣёзӯүпјҢдҪҶжҳҜеҶ…еӯҳең°еқҖдёҚзӣёзӯү print(id(li),id(li1)) print(li is li1) #False
еҝ«йҖҹжіЁйҮҠд»Јз Ғзҡ„еҝ«жҚ·й”®пјҡctrl+/
еҝ«йҖҹзј©иҝӣзҡ„еҝ«жҚ·й”®пјҡйҖүдёӯйңҖиҰҒзј©иҝӣзҡ„д»Јз Ғ+tab
еҝ«йҖҹеҸ–ж¶Ҳзј©иҝӣзҡ„еҝ«жҚ·й”®пјҡйҖүдёӯйңҖиҰҒзј©иҝӣзҡ„д»Јз Ғ пјҢжҢүshift+tab
з»ғд№ пјҡдә‘дё»жңәз®ЎзҗҶзі»з»ҹ
зј–еҶҷдёҖдёӘдә‘дё»жңәз®ЎзҗҶзі»з»ҹпјҡ
- еҲӣе»әдә‘дё»жңә(IP,hostname,IDC)
- жҗңзҙўдә‘дё»жңәпјҲйЎәеәҸжҹҘжүҫпјү
- еҲ йҷӨдә‘дё»жңә
-жҹҘзңӢжүҖжңүдә‘дё»жңәдҝЎжҒҜ
from collections import namedtuple
menu = """
дә‘дё»жңәз®ЎзҗҶзі»з»ҹ
1).ж·»еҠ дә‘дё»жңә
2).жҗңзҙўдә‘дё»жңә(IPжҗңзҙў)
3).еҲ йҷӨдә‘дё»жңә
4).дә‘дё»жңәеҲ—иЎЁ
5). йҖҖеҮәзі»з»ҹ
иҜ·иҫ“е…ҘжӮЁзҡ„йҖүжӢ©пјҡ"""
# 1. жүҖжңүдә‘дё»жңәдҝЎжҒҜеҰӮдҪ•еӯҳеӮЁпјҹйҖүжӢ©е“Әз§Қзұ»еһӢеӯҳеӮЁпјҹ йҖүжӢ©еҲ—иЎЁ
# 2. жҜҸдёӘдә‘дё»жңәдҝЎжҒҜиҜҘеҰӮдҪ•еӯҳеӮЁпјҹIP,hostname.IDC йҖүжӢ©е‘ҪеҗҚе…ғз»„
hosts = []
Host = namedtuple('Host',('ip','hostname','idc'))
while True:
choice = input(menu)
if choice == '1':
print("ж·»еҠ дә‘дё»жңә".center(50,"*"))
ip = input("ip:")
hostname = input("hostname:")
idc = input("idc(eg:ali,huawei...):")
host1 = Host(ip,hostname,idc)
hosts.append(host1)
print(f"ж·»еҠ {idc}зҡ„дә‘дё»жңәжҲҗеҠҹгҖӮIPең°еқҖдёә{ip}")
elif choice == '2':
#жҖҺд№ҲжҗңзҙўпјҡforеҫӘзҺҜ(for..else),еҲӨж–ӯпјҢbreak
print("жҗңзҙўдә‘дё»жңә".center(50,"*"))
for host in hosts:
ipv4 = input("please input ipv4:")
if ipv4 == host.ip:
print(f'{ipv4}еҜ№еә”зҡ„дё»жңәдёә{host.hostname}')
else:
break
elif choice == '3':
print("еҲ йҷӨдә‘дё»жңә".center(50,"*"))
for host in hosts:
delete_hostname = input("please input delete hostname:")
if delete_hostname == host.hostname:
hosts.remove(host)
print(f'еҜ№еә”зҡ„дё»жңә{delete_hostname}е·Із»ҸеҲ йҷӨ')
else:
break
elif choice == '4':
print("дә‘дё»жңәеҲ—иЎЁ".center(50,"*"))
print("IP\t\t\thostname\tidc")
count = 0
for host in hosts:
count +=1
print(f"{host.ip}\t{host.hostname}\t{host.idc}")
print(f'дә‘дё»жңәжҖ»дёӘж•°дёә:{count}')
elif choice == '5':
print("зі»з»ҹжӯЈеңЁйҖҖеҮәпјҢж¬ўиҝҺдёӢж¬ЎдҪҝз”Ё......")
exit()
else:
print("иҜ·иҫ“е…ҘжӯЈзЎ®зҡ„йҖүйЎ№пјҒ")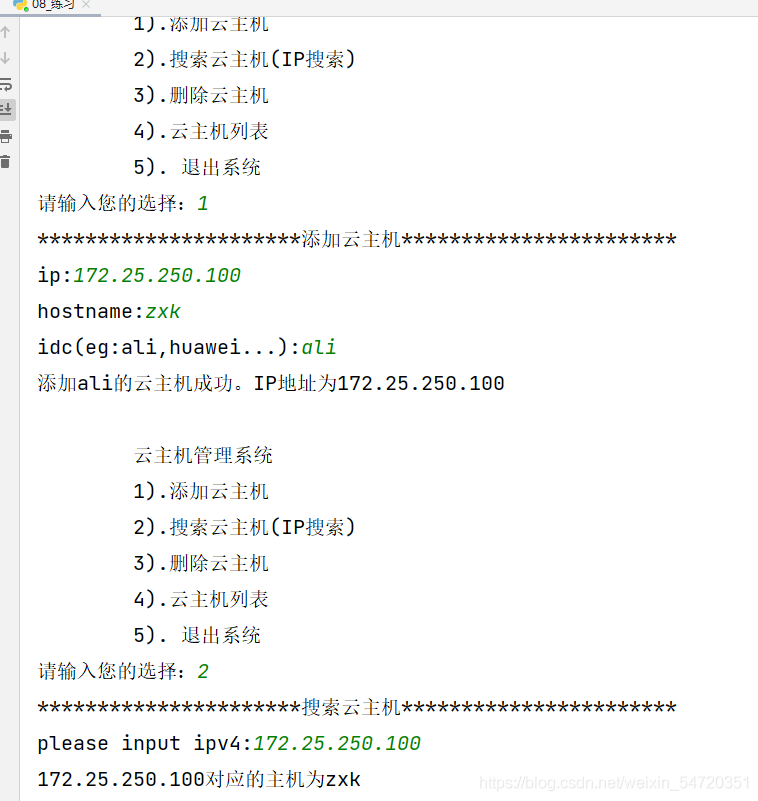
вҖңPythonеҶ…зҪ®ж•°жҚ®з»“жһ„еҲ—иЎЁдёҺе…ғз»„зҡ„иҜҰз»Ҷд»Ӣз»ҚвҖқзҡ„еҶ…е®№е°ұд»Ӣз»ҚеҲ°иҝҷйҮҢдәҶпјҢж„ҹи°ўеӨ§е®¶зҡ„йҳ…иҜ»гҖӮеҰӮжһңжғідәҶи§ЈжӣҙеӨҡиЎҢдёҡзӣёе…ізҡ„зҹҘиҜҶеҸҜд»Ҙе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–е°ҶдёәеӨ§е®¶иҫ“еҮәжӣҙеӨҡй«ҳиҙЁйҮҸзҡ„е®һз”Ёж–Үз« пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ