您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
本篇内容主要讲解“java怎么实现多语言配置i18n”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“java怎么实现多语言配置i18n”吧!
一个资源包中的每个资源文件都必须拥有共同的基名。除了基名,每个资源文件的名称中还必须有标识其本地信息的附加部分。
例如:一个资源包的基名是“inspectionJsonMsg”,则与中文、英文环境相对应的资源文件名则为: "inspectionJsonMsg_zh_CN.properties" "inspectionJsonMsg_en_US.properties"
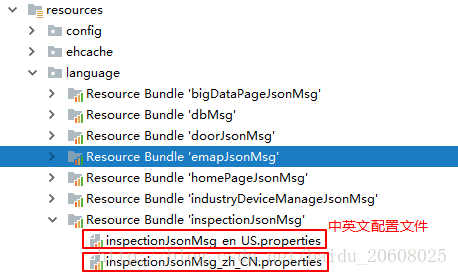
资源文件的内容通常采用"关键字=值"的形式,软件根据关键字检索值显示在页面上。一个资源包中的所有资源文件的关键字必须相同,值则为相应国家的文字。并且资源文件中采用的是properties格式文件,所以文件中的所有字符都必须是ASCII字码,属性(properties)文件是不能保存中文的,对于像中文这样的非ACSII字符,须先进行编码
例如:
国际化的中文环境的properties文件

国际化的英文环境的properties文件

applicationContext.xml
<!--多语言的配置 开始--> <bean id="messageSource" class="org.springframework.context.support.ResourceBundleMessageSource"> <property name="basenames"> <list> <value>language/inspectionJsonMsg</value> </list> </property> <property name="defaultEncoding" value="UTF-8" /> </bean> <bean id="localeResolver" class="org.springframework.web.servlet.i18n.CookieLocaleResolver"> <property name="cookieName" value="spmsLanguage"/> <property name="cookieMaxAge" value="94608000"/> <property name="defaultLocale" value="zh_CN" /> </bean> <!--多语言的配置 结束-->
public class InspectionConst {
//设备查询成功
public static final String INSPECTION_DEVICE_QUERY_SUCCESS = "ny.spms.java.inspection.device.query.success";
//设备查询失败
public static final String INSPECTION_DEVICE_QUERY_ERROR = "ny.spms.java.inspection.device.query.error";
}package com.hikvision.energy.util.i18n;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.context.MessageSource;
import org.springframework.context.MessageSourceResolvable;
import org.springframework.context.i18n.LocaleContextHolder;
import com.hikvision.energy.core.util.AppContext;
import java.util.Locale;
/**
* 多语言查询value工具类
*
* @author wanjiadong
* @date 2017-11-6
*
*/
public class I18nUtil {
private static MessageSource messageSource;
private final static Logger log = LoggerFactory.getLogger(I18nUtil.class);
static {
messageSource = AppContext.getBean("messageSource");
}
/**
* 根据CODE查询,默认无通配参数,Local跟随当前cookie
* @Author: wanjiadong
* @Description:
* @Date: 2017-11-6
* @param: code
*/
public static String getMessage(String code){
return getMessage(code,null,getLocal());
}
public static String getMessage(String code,Locale locale){
return getMessage(code,null,locale);
}
/**
* 根据CODE查询,自定义默认值,默认无通配参数,Local跟随当前cookie
* @Author: wanjiadong
* @Description:
* @Date: 2017-11-6
* @param: code
*/
public static String getMessage(String code,String defaultMessage){
return getMessage(code,null,defaultMessage,getLocal());
}
/**
* 根据CODE和args查询,Local跟随当前cookie
* @Author: wanjiadong
* @Description:
* @Date: 2017-11-6
* @param: code
* @param: args 通配符的参数
*/
public static String getMessage(String code,Object[] args){
return getMessage(code,args,getLocal());
}
public static String getMessage(String code,Object[] args,String defaultMessage,Locale locale){
return messageSource.getMessage(code,args,defaultMessage,locale);
}
public static String getMessage(String code, Object[] args, Locale locale){
try{
return messageSource.getMessage(code,args,locale);
}catch (Exception e){
log.error("Query message value by key[{}] error. The reason is:"+e.getMessage(),code);
return null;
}
}
public static String getMessage(MessageSourceResolvable resolvable, Locale locale){
try{
return messageSource.getMessage(resolvable,locale);
}catch (Exception e){
log.error("Query message value error. The reason is:"+e.getMessage());
return null;
}
}
//解析用户区域
public static Locale getLocal() {
return LocaleContextHolder.getLocale();
}
}I18nUtil.getMessage(InspectionConst.TEMPORARY_JOB_OVER_BEGIN_TIME, new Object[]{InspectionConst.TEMPORARA_TIME})或
I18nUtil.getMessage(InspectionConst.INSPECTION_TEMPORARY_JOB_ADD_SUCCESS)
i18n(其来源是英文单词internationalization的首末字符i和n,18为中间的字符数)是“国际化”的简称。对程序来说,在不修改内部代码的情况下,能根据不同语言及地区显示相应的界面。
这就要求,仅仅是页面语言的翻译是不够的,即便在一个国家在不同地区都可能会存在不同习惯方言操作习惯等等(例如我们国家搜索结果习惯左对齐,但是有的国家就习惯右对齐),这就导致了“本地化”(L10n)机制的出现。
国际化和本地化的出现,在语言、文化、书写习惯、阅读习惯、符合当地主题的全面配置,使得一个Web应用程序在运行时能够根据客户端请求所来自的国家和语言显示不同的用户界面。
根据以上简介和查看的具体软件的配置,理解一下i18n吧,所以小编查看了一下QQ的i18n配置文件,如下:
<?xml version="1.0" encoding="utf-8" ?> <i18n> <!-- 默认的语言,以主程序的优?--> <locale id="2052" /> <!-- 语言文字列表 --> <StringBundle> <configfile name="GFStringBundle.xml"/> <configfile name="StringBundle.xml"/> <configfile name="UrlBundle.xml"/> </StringBundle> <!-- 地区信息,目前只需要一?--> <Location2> <configfile name="LocList.xml"/> </Location2> <LangList> <configfile name="LangList.xml"/> </LangList> </i18n>
又查看了一下要读取的LangList.xml文件,很壮观,如下:
<?xml version="1.0" encoding="utf-8"?> <Languages> <Language LCID="1078" Name="南非荷兰语" Code="af"/> <Language LCID="1052" Name="阿尔巴尼亚语" Code="sq"/> <Language LCID="1025" Name="阿拉伯语" Code="ar"/> <Language LCID="1067" Name="亚美尼亚语" Code="hy"/> <Language LCID="2092" Name="阿塞拜疆语" Code="az"/> <Language LCID="1059" Name="白俄罗斯语" Code="be"/> <Language LCID="5146" Name="波斯尼亚语" Code="bs-ba"/> <Language LCID="1026" Name="保加利亚语" Code="bg"/> <Language LCID="1109" Name="缅甸语" Code="my"/> <Language LCID="3076" Name="中文(繁体)" Code="zh-hk"/> <Language LCID="1027" Name="加泰罗尼亚语" Code="ca"/> <Language LCID="1050" Name="克罗地亚语" Code="hr"/> <Language LCID="1029" Name="捷克语" Code="cs"/> <Language LCID="1030" Name="丹麦语" Code="da"/> <Language LCID="1043" Name="荷兰语" Code="nl"/> <Language LCID="1033" Name="英语" Code="en-us"/> <Language LCID="1061" Name="爱沙尼亚语" Code="et"/> <Language LCID="1065" Name="波斯语" Code="fa"/> <Language LCID="1035" Name="芬兰语" Code="fi"/> <Language LCID="1036" Name="法语" Code="fr"/> <Language LCID="2108" Name="盖尔语" Code="gd"/> <Language LCID="1031" Name="德语" Code="de"/> <Language LCID="1032" Name="希腊语" Code="el"/> <Language LCID="1095" Name="古吉拉特语" Code="gu"/> <Language LCID="1037" Name="希伯来语" Code="he"/> <Language LCID="1081" Name="印地语" Code="hi"/> <Language LCID="1038" Name="匈牙利语" Code="hu"/> <Language LCID="1039" Name="冰岛语" Code="is"/> <Language LCID="1057" Name="印度尼西亚语" Code="id"/> <Language LCID="1040" Name="意大利语" Code="it"/> <Language LCID="1041" Name="日语" Code="ja"/> <Language LCID="1107" Name="高棉语" Code="km"/> <Language LCID="1042" Name="朝鲜语" Code="ko"/> <Language LCID="1108" Name="老挝语" Code="lo"/> <Language LCID="1062" Name="拉脱维亚语" Code="lv"/> <Language LCID="1063" Name="立陶宛语" Code="lt"/> <Language LCID="1071" Name="马其顿语" Code="mk"/> <Language LCID="1086" Name="马来西亚语" Code="ms"/> <Language LCID="2052" Name="中文(简体)" Code="zh-cn"/> <Language LCID="1104" Name="蒙古语" Code="mn"/> <Language LCID="1044" Name="挪威语" Code="no"/> <Language LCID="1045" Name="波兰语" Code="pl"/> <Language LCID="2070" Name="葡萄牙语" Code="pt"/> <Language LCID="1094" Name="旁遮普语" Code="pa"/> <Language LCID="1048" Name="罗马尼亚语" Code="ro"/> <Language LCID="1049" Name="俄语" Code="ru"/> <Language LCID="3098" Name="塞尔维亚语" Code="sr"/> <Language LCID="1113" Name="信德语" Code="sd"/> <Language LCID="1051" Name="斯洛伐克语" Code="sk"/> <Language LCID="1060" Name="斯洛文尼亚语" Code="sl"/> <Language LCID="1143" Name="索马里语" Code="so"/> <Language LCID="1034" Name="西班牙语" Code="es"/> <Language LCID="1089" Name="斯瓦西里语" Code="sw"/> <Language LCID="1053" Name="瑞典语" Code="sv"/> <Language LCID="1097" Name="泰米尔语" Code="ta"/> <Language LCID="1092" Name="鞑靼语" Code="tt"/> <Language LCID="1054" Name="泰语" Code="th"/> <Language LCID="1055" Name="土耳其语" Code="tr"/> <Language LCID="1058" Name="乌克兰语" Code="uk"/> <Language LCID="1056" Name="乌尔都语" Code="ur"/> <Language LCID="1066" Name="越南语" Code="vi"/> <Language LCID="1106" Name="威尔士语" Code="cy-gb"/> <Language LCID="1085" Name="意第绪语" Code="yi"/> <Language LCID="1130" Name="约鲁巴语" Code="yo"/> </Languages>
Java.Util中有一个locale方法,该方法的其中一个构造方法为:
Locale(Stringlanguage,String country):根据语言和国家构造一个语言环境。每个国家都有一个locale信息,通过对象可以取得locale信息,locale信息来源于操作系统。如下:
package com.bjpowernode.i18n;
import java.util.Locale;
public class I18nSample {
public static void main(String[] args) {
Locale defaultLocale = Locale.getDefault();
System.out.println("country=" + defaultLocale.getCountry());
System.out.println("language=" + defaultLocale.getLanguage());
}
}运行结果为:
country=CN
language=zh
但是在我们下面的实践中,为了方便我们就直接进行设置了。
我们需要将硬编码文本转移到外部的资源文件,对资源文件的命名必须使用一定的规则,一般是以“统一字符+locale信息”命名,如MessagesBundle_zh_CN.properties,MessagesBundle_en_US.properties。准备资源包的过程,就是把对应不同语言的用户所涉及的文本和图片保存在多个文本文件中,客户端根据不同的环境需要进行更换。这些文件被称为“属性文件”,所有属性文件合在一起被称为资源包(ResourceBundle)。
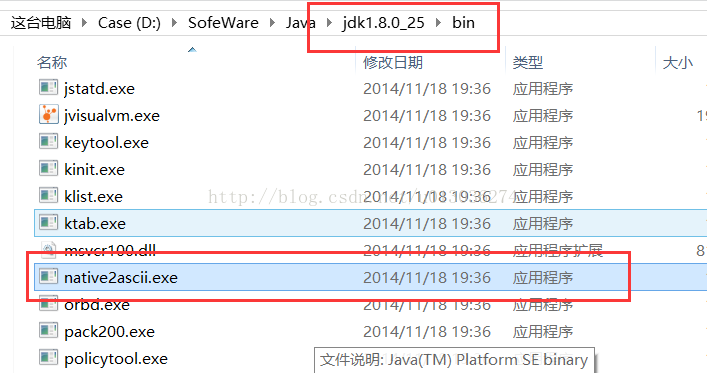
因为资源文件必须是Latin-1后者Unicode编码的字符,所以实践过程中,准备英文好说,准备中文的话,需要使用相应的Unicode编码,使用jdk自带的native2ascii.exe,将中文资源文件进行转换,如下:
如下:

也可以直接在资源文件中添加,会自动转换成Unicode编码,如下:
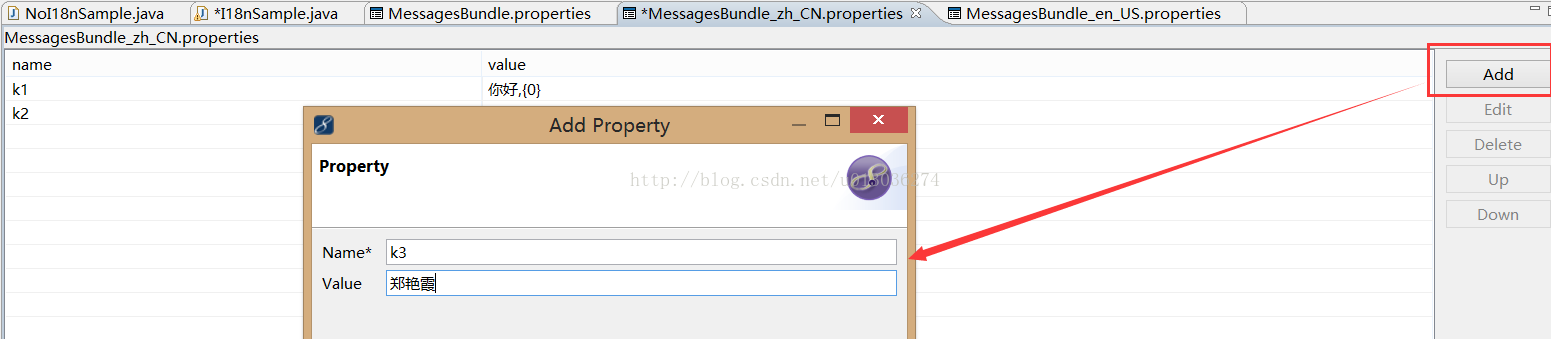
结果如下:

Demo中我们中文和英文准备的都是:k1=你好/hello,k2=再见/goodbye。
package com.bjpowernode.i18n;
import java.text.MessageFormat;
import java.util.Locale;
import java.util.ResourceBundle;
public class I18nSample {
public static void main(String[] args) {
// 为了实验,就不每次都修改操作系统的语言了,直接设置locale信息
// Locale currentLocale = new Locale("zh", "CN");
Locale currentLocale = new Locale("en", "US");
System.out.println("country=" + currentLocale.getCountry());
System.out.println("language=" + currentLocale.getLanguage());
// 根据locale信息寻找相应的资源包中的配置
ResourceBundle rb = ResourceBundle.getBundle(
"com.bjpowernode.resources.MessagesBundle", currentLocale);
System.out.println(rb.getString("k1"));
System.out.println(rb.getString("k2"));
// 在配置文件中用占位符来加入自定义设置,如登陆时显示:你好,***
MessageFormat mf = new MessageFormat(rb.getString("k1"));
System.out.println(mf.format(new Object[] { "张三" }));
}
}运行结果为:
country=US
language=en
hello,{0}
good bye
hello,张三
到此,相信大家对“java怎么实现多语言配置i18n”有了更深的了解,不妨来实际操作一番吧!这里是亿速云网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。