您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
在学习Spark前,建议先正确理解spark,可以参考:正确理解spark
本篇对JavaRDD基本的action api进行了详细的描述
先定义两个Comparator实现,一个是实现升序,一个是实现降序
//升序排序比较器
private static class AscComparator implements Comparator<Integer>, Serializable {
@Override
public int compare(java.lang.Integer o1, java.lang.Integer o2) {
return o1 - o2;
}
}
//降序排序比较器
private static class DescComparator implements Comparator<Integer>, Serializable {
@Override
public int compare(java.lang.Integer o1, java.lang.Integer o2) {
return o2 - o1;
}
}再定义一个RDD:
JavaRDD<Integer> listRDD = sc.parallelize(Arrays.asList(1, 2, 4, 3, 3, 6), 2);
一、collect、take、top、first
//结果: [1, 2, 4, 3, 3, 6] 将RDD的所有数据收集到driver端来,用于小数据或者实验,
// 对大数据量的RDD进行collect会出现driver端内存溢出
System.out.println("collect = " + listRDD.collect());
//结果:[1, 2] 将RDD前面两个元素收集到java端
//take的原理大致为:先看看RDD第一个分区的元素够不够我们想take的数量
//不够的话再根据剩余的需要take的数据量来估算需要扫描多少个分区的数据,直到take到了我们想要的数据个数为止
System.out.println("take(2) = " + listRDD.take(2));
//结果:[6, 4] 取RDD升序的最大的两个元素
System.out.println("top(2) = " + listRDD.top(2));
//结果:[1, 2] 取RDD降序的最大的两个元素(即取RDD最小的两个元素)
System.out.println("DescComparator top(2) = " + listRDD.top(2, new DescComparator()));
//结果:1 其底层实现就是take(1)
System.out.println("first = " + listRDD.first());二、min、max
//结果:1。 按照升序取最小值,就是RDD的最小值
System.out.println("min = " + listRDD.min(new AscComparator()));
//结果:6 按照降序取最小值,就是RDD的最大值
System.out.println("min = " + listRDD.min(new DescComparator()));
//结果:6 按照升序取最大值,就是RDD的最大值
System.out.println("max = " + listRDD.max(new AscComparator()));
//结果:1 按照降序取最大值,就是RDD的最小值
System.out.println("max = " + listRDD.max(new DescComparator()));min和max的底层是用reduce api来实现的,下面是伪代码
min() == reduce((x, y) => if (x <= y) x else y) max() == redcue((x, y) => if (x >= y) x else y)
对于reduce api我们见下面的讲解
三、takeOrdered
//结果:[1, 2] 返回该RDD最小的两个元素
System.out.println("takeOrdered(2) = " + listRDD.takeOrdered(2));
//结果:[1, 2] 返回RDD按照升序的前面两个元素,即返回该RDD最小的两个元素
System.out.println("takeOrdered(2) = " + listRDD.takeOrdered(2, new AscComparator()));
//结果:[6, 4] 返回RDD按照降序的前面两个元素,即返回该RDD最大的两个元素
System.out.println("takeOrdered(2) = " + listRDD.takeOrdered(2, new DescComparator()));四、foreach和foreachPartition
foreach是对RDD每一个元素应用自定义的函数,而foreachPartition是对RDD的每一个partition应用自定义的函数,使用时需要注意下面的建议
先定义一个比较耗时的操作:
public static Integer getInitNumber(String source) {
System.out.println("get init number from " + source + ", may be take much time........");
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
return 1;
}listRDD.foreach(new VoidFunction<Integer>() {
@Override
public void call(Integer element) throws Exception {
//这个性能太差,遍历每一个元素的时候都需要调用比较耗时的getInitNumber
//建议采用foreachPartition来代替foreach操作
Integer initNumber = getInitNumber("foreach");
System.out.println((element + initNumber) + "=========");
}
});
listRDD.foreachPartition(new VoidFunction<Iterator<Integer>>() {
@Override
public void call(Iterator<Integer> integerIterator) throws Exception {
//和foreach api的功能是一样,只不过一个是将函数应用到每一条记录,这个是将函数应用到每一个partition
//如果有一个比较耗时的操作,只需要每一分区执行一次这个操作就行,则用这个函数
//这个耗时的操作可以是连接数据库等操作,不需要计算每一条时候去连接数据库,一个分区只需连接一次就行
Integer initNumber = getInitNumber("foreach");
while (integerIterator.hasNext()) {
System.out.println((integerIterator.next() + initNumber) + "=========");
}
}
});五、reduce 和 treeReduce
Integer reduceResult = listRDD.reduce(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer ele1, Integer ele2) throws Exception {
return ele1 + ele2;
}
});
//结果:19
System.out.println("reduceResult = " + reduceResult);
Integer treeReduceResult = listRDD.treeReduce(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer integer, Integer integer2) throws Exception {
return integer + integer2;
}
}, 3); //这个3表示做3次聚合才计算出结果
//结果:19
System.out.println("treeReduceResult = " + treeReduceResult);它们俩的结果是一样的,但是执行流程不一样,如下流程:

如果分区数太多的话,使用treeReduce做多次聚合,可以提高性能,如下:
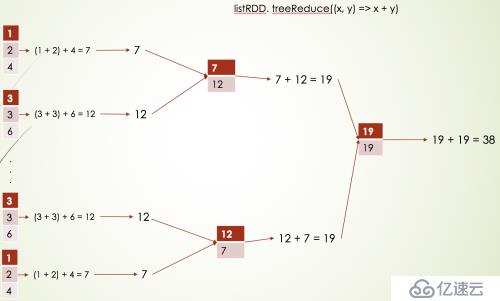
六、fold
fold其实和reduce的功能类似,只不过fold多了一个初始值而已
//和reduce的功能类似,只不过是在计算每一个分区的时候需要加上初始值0,最后再将每一个分区计算出来的值相加再加上这个初始值
Integer foldResult = listRDD.fold(0, new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer integer, Integer integer2) throws Exception {
return integer + integer2;
}
});
//结果:19
System.out.println("foldResult = " + foldResult);七、aggregate 和 treeAggregate
//先初始化一个我们想要的返回的数据类型的初始值
//然后在每一个分区对每一个元素应用函数一(acc, value) => (acc._1 + value, acc._2 + 1)进行聚合
//最后将每一个分区生成的数据应用函数(acc1, acc2) => (acc1._1 + acc2._1, acc1._2 + acc2._2)进行聚合
Tuple2 aggregateResult = listRDD.aggregate(new Tuple2<Integer, Integer>(0, 0),
new Function2<Tuple2<Integer, Integer>, Integer, Tuple2<Integer, Integer>>() {
@Override
public Tuple2<Integer, Integer> call(Tuple2<Integer, Integer> acc, Integer integer) throws Exception {
return new Tuple2<>(acc._1 + integer, acc._2 + 1);
}
}, new Function2<Tuple2<Integer, Integer>, Tuple2<Integer, Integer>, Tuple2<Integer, Integer>>() {
@Override
public Tuple2<Integer, Integer> call(Tuple2<Integer, Integer> acc1, Tuple2<Integer, Integer> acc2) throws Exception {
return new Tuple2<>(acc1._1 + acc2._1, acc1._2 + acc2._2);
}
});
//结果:(19,6)
System.out.println("aggregateResult = " + aggregateResult);
Tuple2 treeAggregateResult = listRDD.treeAggregate(new Tuple2<Integer, Integer>(0, 0),
new Function2<Tuple2<Integer, Integer>, Integer, Tuple2<Integer, Integer>>() {
@Override
public Tuple2<Integer, Integer> call(Tuple2<Integer, Integer> acc, Integer integer) throws Exception {
return new Tuple2<>(acc._1 + integer, acc._2 + 1);
}
}, new Function2<Tuple2<Integer, Integer>, Tuple2<Integer, Integer>, Tuple2<Integer, Integer>>() {
@Override
public Tuple2<Integer, Integer> call(Tuple2<Integer, Integer> acc1, Tuple2<Integer, Integer> acc2) throws Exception {
return new Tuple2<>(acc1._1 + acc2._1, acc1._2 + acc2._2);
}
}, 2);
//结果:(19,6)
System.out.println("treeAggregateResult = " + treeAggregateResult);两者的结果是一致的,只不过执行流程不一样,如下是aggregate的执行流程:

如果RDD的分区数非常多的话,建议使用treeAggregate,如下是treeAggregate的执行流程:
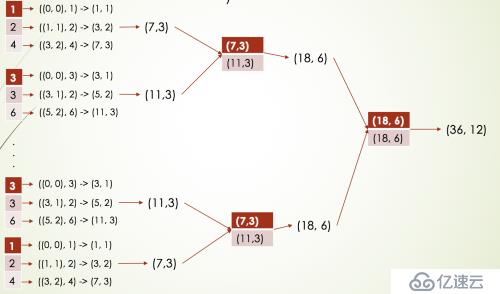
aggregate和treeAggregate的比较:
1: aggregate在combine上的操作,时间复杂度为O(n). treeAggregate的时间复杂度为O(lgn)。
n表示分区数
2: aggregate把数据全部拿到driver端,存在内存溢出的风险。treeAggregate则不会。
3:aggregate 比 treeAggregate在最后结果的reduce操作时,多使用了一次初始值
对于以上api的原理层面的讲解,可以参考spark core RDD api原理详解,因为用文字讲清楚原理性的东西是一件比较困难的事情,看了后记得也不深入
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。