您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章给大家分享的是有关pyspark如何操作hive表的内容。小编觉得挺实用的,因此分享给大家做个参考,一起跟随小编过来看看吧。
pyspark 操作hive表,hive分区表动态写入;最近发现spark动态写入hive分区,和saveAsTable存表方式相比,文件压缩比大约 4:1。针对该问题整理了 spark 操作hive表的几种方式。
1> saveAsTable写入
saveAsTable(self, name, format=None, mode=None, partitionBy=None, **options)
示例:
df.write.saveAsTable("表名",mode='overwrite')注意:
1、表不存在则创建表,表存在全覆盖写入;
2、表存在,数据字段有变化,先删除后重新创建表;
3、当正在存表时报错或者终止程序会导致表丢失;
4、数据默认采用parquet压缩,文件名称 part-00000-5efbfc08-66fe-4fd1-bebb-944b34689e70.gz.parquet
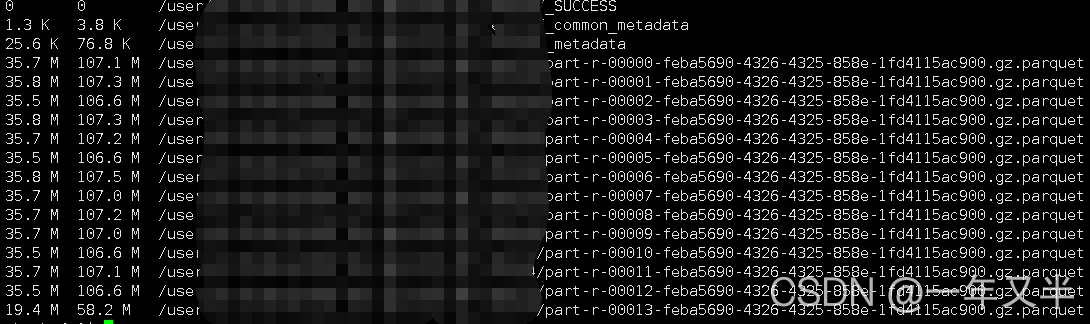
数据文件在hdfs上显示:
2> insertInto写入
insertInto(self, tableName, overwrite=False):
示例:
# append 写入
df.repartition(1).write.partitionBy('dt').insertInto("表名")
# overwrite 写入
df.repartition(1).write.partitionBy('dt').insertInto("表名",overwrite=True)
# 动态分区使用该方法注意:
1、df.write.mode("overwrite").partitionBy("dt").insertInto("表名") 不会覆盖数据
2、需要表必须存在且当前DF的schema与目标表的schema必须一致
3、插入的文件不会压缩;文件以part-00....结尾。文件较大
数据文件在hdfs上显示:

2.1> 问题说明
两种方式存储数据量一样的数据,磁盘文件占比却相差很大,.gz.parquet 文件 相比 part-00000文件要小很多。想用spark操作分区表,又想让文件压缩,百度了一些方式,都没有解决。
从stackoverflow中有一个类似的问题 Spark compression when writing to external Hive table 。用里面的方法并没有解决。
最终从hive表数据文件压缩角度思考,问题得到解决。
hive 建表指定压缩格式下面是hive parquet的几种压缩方式
-- 使用snappy
CREATE TABLE if not exists ods.table_test(
id string,
open_time string
)
COMMENT '测试'
PARTITIONED BY (`dt` string COMMENT '按天分区')
row format delimited fields terminated by '\001'
STORED AS PARQUET
TBLPROPERTIES ('parquet.compression'='SNAPPY');
-- 使用gzip
CREATE TABLE if not exists ods.table_test(
id string,
open_time string
)
COMMENT '测试'
PARTITIONED BY (`dt` string COMMENT '按天分区')
row format delimited fields terminated by '\001'
STORED AS PARQUET
TBLPROPERTIES ('parquet.compression'='GZIP');
-- 使用uncompressed
CREATE TABLE if not exists ods.table_test(
id string,
open_time string
)
COMMENT '测试'
PARTITIONED BY (`dt` string COMMENT '按天分区')
row format delimited fields terminated by '\001'
STORED AS PARQUET
TBLPROPERTIES ('parquet.compression'='UNCOMPRESSED');
-- 使用默认
CREATE TABLE if not exists ods.table_test(
id string,
open_time string
)
COMMENT '测试'
PARTITIONED BY (`dt` string COMMENT '按天分区')
row format delimited fields terminated by '\001'
STORED AS PARQUET;
-- 设置参数 set parquet.compression=SNAPPY;2.2> 解决办法
建表时指定TBLPROPERTIES,采用gzip 压缩
示例:
drop table if exists ods.table_test
CREATE TABLE if not exists ods.table_test(
id string,
open_time string
)
COMMENT '测试'
PARTITIONED BY (`dt` string COMMENT '按天分区')
row format delimited fields terminated by '\001'
STORED AS PARQUET
TBLPROPERTIES ('parquet.compression'='GZIP');执行效果
数据文件在hdfs上显示:

可以看到文件大小占比已经和 *.gz.parquet 文件格式一样了
3>saveAsTextFile写入直接操作文件saveAsTextFile(self, path, compressionCodecClass=None)
该方式通过rdd 以文件形式直接将数据存储在hdfs上。
示例:
rdd.saveAsTextFile('hdfs://表全路径')感谢各位的阅读!关于“pyspark如何操作hive表”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,让大家可以学到更多知识,如果觉得文章不错,可以把它分享出去让更多的人看到吧!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。