您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章主要介绍了怎么使用java线程池,具有一定借鉴价值,感兴趣的朋友可以参考下,希望大家阅读完这篇文章之后大有收获,下面让小编带着大家一起了解一下。
在学习多线程之前,读者可能会有疑问?如果单线程跑得太慢,那么是否就能多创建多个线程来跑任务?并发的情况,线程是不是创建越多越好?这是一个很经典的问题,画图表示一下创建很多线程的情况,然后进行情况分析。
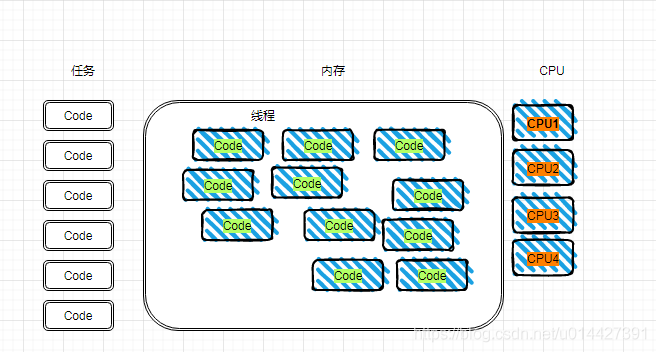
创建线程和销毁线程都是需要时间的,如果创建时间+销毁时间>执行任务时间就很不划算
创建后的线程是需要内存去存放的,创建的线程对应一个Thread对象,对象是会占用JVM的堆内存的,根据jvm规范,一个线程默认最大栈大小为1M,这个栈空间也是需要从系统内存中分配的,所以线程越多,需要的内存就越多
创建线程,操作系统是需要频繁进行线程上下文切换的,所以线程创建太多,是会影响性能的
上下文切换(context switch):对于单核CPU来说,在一个时刻只能运行一个线程,对于并行来说,单核cpu也是可以支持多线程执行代码的,CPU是通过给线程分配时间片来解决的,所谓时间片是CPU给每个线程分配的时间,时间片的时间是非常短的,所以执行完成一个时间片后,进行任务切换,切换之前先保存这个任务的状态,以便于下次换回来的时候,可以加载这个任务的状态,所以从保存任务状态到再加载任务的过程称为上下文切换,不仅在线程间可以上下文切换,进程也同样可以
如果是计算型任务?
CPU数量的1~2倍即
可如果是IO密集型任务?
就需要多一些线程,要根据具体的io阻塞时长来进行考量决定
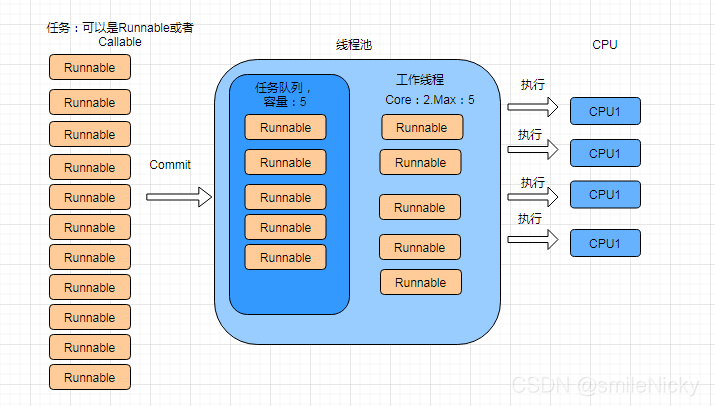
接收任务,放入线程池的任务仓库
工作线程从线程池的任务仓库取,执行
没有任务时,线程阻塞,有任务时唤醒线程
Executor : 接口类
ExecutorService:加入关闭方法和对Runnable、Callable、Future的支持
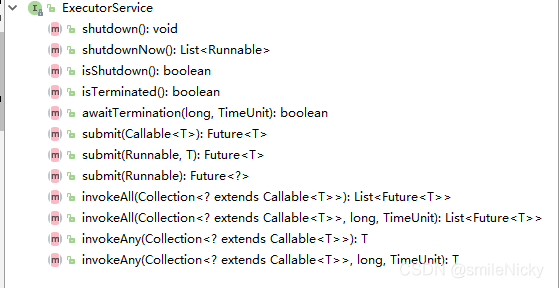
shutdown:已经提交的会执行完成
shutdownNow:正在执行的会执行完成,未来执行的返回
awaitTermination:阻塞等待任务关闭完成
submit类型的:都是提交任务的,支持Runnable和Callable
invokeAll类型的:执行集合中所有任务
ScheduleExecutorService :加入对定时任务的支持
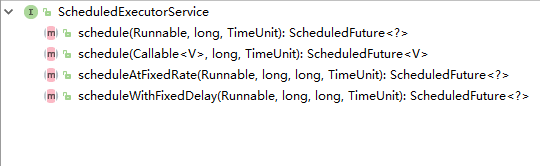
其中schedule(Runablle , long, Timeunit)和schedule(Callable<V> , long, TimeUnit)表示的是多久后执行,而scheduleAtFixedRate方法和scheduleWithFixedDelay方法表示的都是周期性重复执行的
再描述scheduleAtFixedRate方法和scheduleWithFixedDelay方法的区别:
scheduleAtFixedRate:以固定的时间频率重复执行任务,如每10s ,也就是两个任务直接以固定的时间间隔执行,不管任务执行完成与否

scheduleWithFixedDelay:以固定的任务时延迟来重复执行任务,这种任务不管任务执行多久都执行完成,然后隔预定的如3s,接着执行下一个任务,每个任务之间的间隔都是一样的

Executors:快速得到线程池的工具类,创建线程池的工厂类
newFixedThreadPool(int nThreads):创建一个固定大小、任务队列 无界的线程池。线程池的核心线程数=最大线程池=nThreads
newCachedThreadPool():创建的是一个大小无界的缓冲线程池。它的任务队列是一个同步队列。如果队列中有空闲的线程,则用空闲线程执行,如果没有就创建新线程执行。池中线程空闲超过60s,就会被释放。缓冲线程池使用于执行耗时比较小的异步任务。线程池的核心线程数=0,最大线程池=Integer.MAX_VALUE
newSingleThreadExecutor():创建的是只有一个线程来执行无界任务队列的单一线程池。该线程池按顺序执行一个一个加入的任务,任何时刻都只有一个线程在执行。单一线程池和newFixedThreadPool(1)的区别在于,单一线程池的池大小是不能再改变的
newScheduleThreadPool(int corePoolSize): 能定时执行任务的线程池,该池的核心线程数由参数corePoolSize指定,最大线程数=Integer.MAX_VALUE
newWorkStealingPool():以当前系统可用的处理器数作为并行级别创建的work-stealing thread pool(ForkJoinPool)
newWorkStealingPool(int parallelism):以指定的parallelism并行级别创建的work-stealing thread pool(ForkJoinPool)
ThreadPoolExecutor:线程池的标准实现
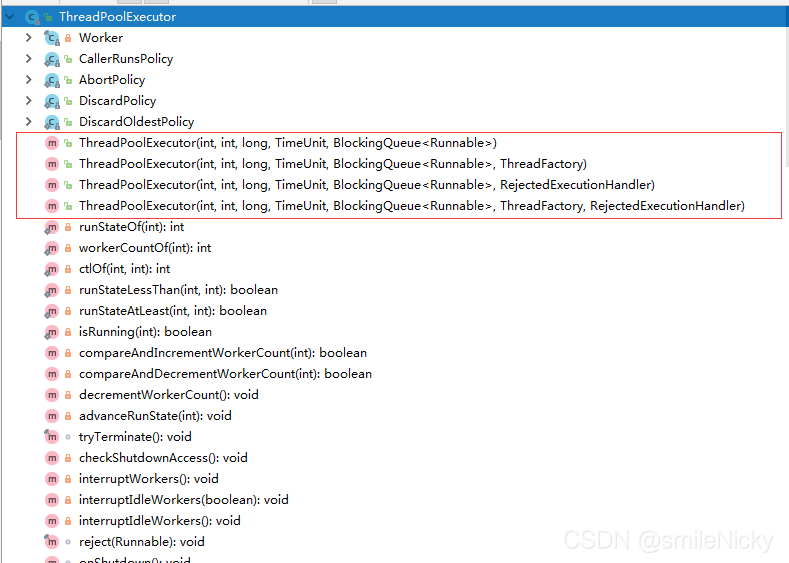
下面列举出ThreadPoolExecutor的主要参数:
| 参数 | 描述 |
|---|---|
| corePoolSize | 核心线程数量 |
| maxPoolSize | 最大线程数量 |
| keepAliveTime+时间单位 | 空闲线程的存活时间 |
| ThreadFactory | 线程工厂,用于创建线程 |
| workQueue | 用于存放任务的队列,可以称之为工作队列 |
| Handler | 用于处理被拒绝的任务 |
虽然Executors使用起来很方便,不过在阿里编程规范里是强调了慎用Executors创建线程池,下面摘录自阿里编程规范手册:
【强制】线程池不允许使用Executors去创建,而是通过ThreadPoolExecutor的方式,
这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。
说明:Executors各个方法的弊端:
1)newFixedThreadPool和newSingleThreadExecutor:
主要问题是堆积的请求处理队列可能会耗费非常大的内存,甚至OOM。
2)newCachedThreadPool和newScheduledThreadPool:
主要问题是线程数最大数是Integer.MAX_VALUE,可能会创建数量非常多的线程,甚至OOM。
ThreadPoolExecutor的基本参数:
new ThreadPoolExecutor( 2, // 核心线程数 5, // 最大线程数 60L, // keepAliveTime,线程空闲超过这个数,就会被销毁释放 TimeUnit.SECONDS, // keepAliveTime的时间单位 new ArrayBlockingQueue(5)); // 传入边界为5的工作队列
画流程图表示,线程池的核心参数是corePoolSize、maxPoolSize、workQueue(工作队列)
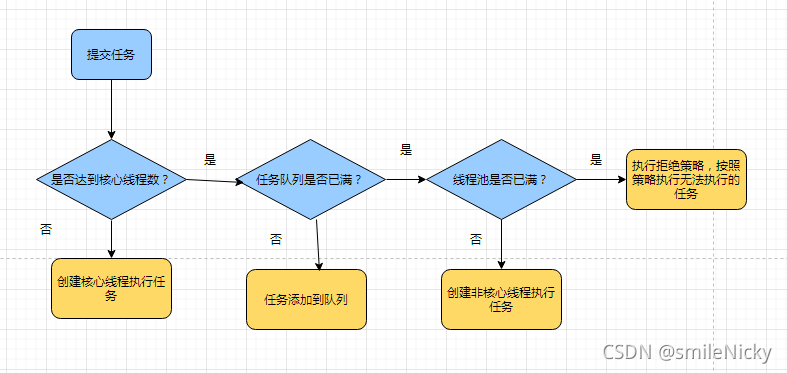
线程池工作原理示意图:任务可以一直放,直到线程池满了的情况,才会拒绝,然后除了核心线程,其它的线程会被合理回收。所以正常情况下,线程池中的线程数量会处在 corePoolSize 与 maximumPoolSize 的闭区间内
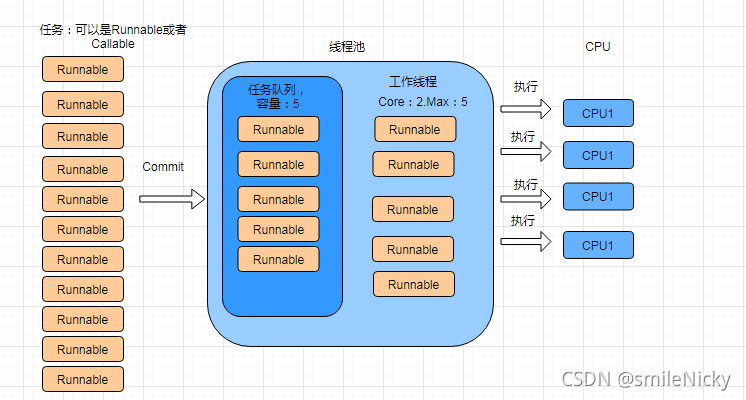
ThreadPoolExecutor基本实例:
ExecutorService service = new ThreadPoolExecutor(2, 5,
60L, TimeUnit.SECONDS,
new ArrayBlockingQueue(5));
service.execute(() ->{
System.out.println(String.format("thread name:%s",Thread.currentThread().getName()));
});
// 避免内存泄露,记得关闭线程池
service.shutdown();ThreadPoolExecutor加上Callable、Future使用的例子:
public static void main(String[] args) {
ExecutorService service = new ThreadPoolExecutor(2, 5,
60L, TimeUnit.SECONDS,
new ArrayBlockingQueue(5));
Future<Integer> future = service.submit(new CallableTask());
Thread.sleep(3000);
System.out.println("future is done?" + future.isDone());
if (future.isDone()) {
System.out.println("callableTask返回参数:"+future.get());
}
service.shutdown();
}
static class CallableTask implements Callable<Integer>{
@Override
public Integer call() {
return ThreadLocalRandom.current().ints(0, (99 + 1)).limit(1).findFirst().getAsInt();
}
}感谢你能够认真阅读完这篇文章,希望小编分享的“怎么使用java线程池”这篇文章对大家有帮助,同时也希望大家多多支持亿速云,关注亿速云行业资讯频道,更多相关知识等着你来学习!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。