您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
一、配置环境
1.设置主机名和对应的地址映射
[root@master ~]# cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.230.130 master 192.168.230.131 slave1 192.168.230.100 slave2 #分别对三台设备配置hostname和hosts
2.在三个节点上分别新建hadoop用户
[root@master ~]# tail -1 /etc/passwd hadoop:x:1001:1001::/home/hadoop:/bin/bash
二、为hadoop配置所有节点之间的ssh免密登陆
1.生成密钥
[hadoop@master ~]$ ssh-keygen -t rsa Generating public/private rsa key pair. Enter file in which to save the key (/home/hadoop/.ssh/id_rsa): /home/hadoop/.ssh/id_rsa already exists. Overwrite (y/n)? y Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /home/hadoop/.ssh/id_rsa. Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub. The key fingerprint is: 1c:16:61:04:4f:76:93:cd:da:9a:08:04:15:58:7d:96 hadoop@master The key's randomart p_w_picpath is: +--[ RSA 2048]----+ | .===B.o= | | . .=.oE.o | | . +o o | | .o .. . | | .S. o | | . o | | | | | | | +-----------------+ [hadoop@master ~]$
2.发送公钥
[hadoop@master ~]$ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop@slave1 The authenticity of host 'slave1 (192.168.230.131)' can't be established. ECDSA key fingerprint is 32:1a:8a:37:f8:11:bc:cc:ec:35:e6:37:c2:b8:e1:45. Are you sure you want to continue connecting (yes/no)? yes /usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed /usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys hadoop@slave1's password: Number of key(s) added: 1 Now try logging into the machine, with: "ssh 'hadoop@slave1'" and check to make sure that only the key(s) you wanted were added. [hadoop@master ~]$
[hadoop@master ~]$ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop@slave2 [hadoop@master ~]$ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop@master #slave1和slave2对其他节点略
3.验证登陆
[hadoop@master ~]$ ssh hadoop@slave1 Last login: Wed Jul 26 01:11:22 2017 from master [hadoop@slave1 ~]$ exit logout Connection to slave1 closed. [hadoop@master ~]$ ssh hadoop@slave2 Last login: Wed Jul 26 13:12:00 2017 from master [hadoop@slave2 ~]$ exit logout Connection to slave2 closed. [hadoop@master ~]$
三、配置JAVA
1.使用xftp将hadoop-2.7.3.tar.gz和jdk-8u131-linux-x64.tar.gz上传至master
[hadoop@master ~]$ ls hadoop-2.7.3.tar.gz jdk-8u131-linux-x64.tar.gz
2.使用root用户解压并移动到/usr/local 下
[hadoop@master ~]$ exit exit [root@master ~]# cd /home/hadoop/ [root@master hadoop]# ls hadoop-2.7.3.tar.gz jdk-8u131-linux-x64.tar.gz [root@master hadoop]# tar -zxf jdk-8u131-linux-x64.tar.gz [root@master hadoop]# ls hadoop-2.7.3.tar.gz jdk1.8.0_131 jdk-8u131-linux-x64.tar.gz [root@master hadoop]# mv jdk1.8.0_131 /usr/local/ [root@master hadoop]# cd /usr/local/ [root@master local]# ls bin etc games include jdk1.8.0_131 lib lib64 libexec sbin share src [root@master local]#
3.配置java环境变量(这里使用的是全局变量)
[root@master ~]# vim /etc/profile #在文件末尾添加如下java环境变量 [root@master ~]# tail -5 /etc/profile export JAVA_HOME=/usr/local/jdk1.8.0_131 #注意jdk版本 export JRE_HOME=$JAVA_HOME/jre export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib export PATH=$JAVA_HOME/bin:$PATH [root@master ~]# [root@master ~]# source /etc/profile #使配置生效
4.测试master上的java是否配置完成
[root@master ~]# java -version java version "1.8.0_131" Java(TM) SE Runtime Environment (build 1.8.0_131-b11) Java HotSpot(TM) 64-Bit Server VM (build 25.131-b11, mixed mode) [root@master ~]#
5.使用scp将jdk拷贝到slave1和slave2
[root@master ~]# scp -r /usr/local/jdk1.8.0_131/ root@slave1:/usr/local/ [root@master ~]# scp -r /usr/local/jdk1.8.0_131/ root@slave2:/usr/local/
6.配置slave1和slave2上的环境变量(同步骤3),配置完后使用java -version验证一下
四、配置hadoop环境
1.解压hadoop并移动到/usr/local 下
[root@master ~]# cd /home/hadoop/ [root@master hadoop]# ls hadoop-2.7.3.tar.gz jdk-8u131-linux-x64.tar.gz [root@master hadoop]# tar -zxf hadoop-2.7.3.tar.gz [root@master hadoop]# mv hadoop-2.7.3 /usr/local/hadoop [root@master hadoop]# ls /usr/local/ bin etc games hadoop include jdk1.8.0_131 lib lib64 libexec sbin share src
2.更改hadoop的文件所属用户
[root@master ~]# cd /usr/local [root@master local]# chown -R hadoop:hadoop /usr/local/hadoop [root@master local]# ll drwxr-xr-x 9 hadoop hadoop 149 Aug 17 2016 hadoop [root@master local]#
3.配置hadoop环境变量
[root@master local]# vim /etc/profile [root@master local]# tail -4 /etc/profile #hadoop export HADOOP_HOME=/usr/local/hadoop #注意路径 export PATH="$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin" [root@master local]# [root@master local]# source /etc/profile #使配置生效
4.测试
[root@master local]# hadoop version Hadoop 2.7.3 Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r baa91f7c6bc9cb92be5982de4719c1c8af91ccff Compiled by root on 2016-08-18T01:41Z Compiled with protoc 2.5.0 From source with checksum 2e4ce5f957ea4db193bce3734ff29ff4 This command was run using /usr/local/hadoop/share/hadoop/common/hadoop-common-2.7.3.jar [root@master local]#
5.配置hadoop-env.sh
[root@master local]# cd $HADOOP_HOME/etc/hadoop [root@master hadoop]# pwd /usr/local/hadoop/etc/hadoop [root@master hadoop]# [root@master hadoop]# vim hadoop-env.sh [root@master hadoop]# tail -1 hadoop-env.sh export JAVA_HOME=/usr/local/jdk1.8.0_131 #在末尾添加 [root@master hadoop]#
6.配置core-site.xml
<configuration> <!-- 指定hdfs的nameService --> <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> </configuration>
7.配置hdfs-site.xml
<configuration> <!-- 数据节点数 --> <property> <name>dfs.replication</name> <value>1</value> </property> <!-- nameNode数据目录 --> #目录不存在需要手动创建,并把所属改为hadoop <property> <name>dfs.namenode.name.dir</name> <value>/usr/local/hadoop/dfs/name</value> </property> <!-- dataNode数据目录 --> #目录不存在需要手动创建,并把所属改为hadoop <property> <name>dfs.datanode.data.dir</name> <value>/usr/local/hadoop/dfs/data</value> </property> </configuration>
8.配置yarn-site.xml
<configuration> <!-- 指定YARN的ResourceManager的地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>master</value> </property> <!-- reducer取数据的方式 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
9.配置mapred-site.xml
[root@master hadoop]# cp mapred-site.xml.template mapred-site.xml [root@master hadoop]# vim mapred-site.xml <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
10.配置slaves
[root@master hadoop]# vim slaves [root@master hadoop]# cat slaves slave1 slave2 [root@master hadoop]#
11.使用scp将配置好的hadoop传输到slave1和slave2节点上
[root@master ~]# scp -r /usr/local/hadoop root@slave1:/usr/local/ [root@master ~]# scp -r /usr/local/hadoop root@slave2:/usr/local/
12.配置slave1和slave2上的环境变量(同步骤3),配置完后使用hadoop version验证一下
13.格式化 hdfs namenode–format
[root@master hadoop]# su hadoop [hadoop@master hadoop]$ cd /usr/local/hadoop/ [hadoop@master hadoop]$ hdfs namenode -format #一定要在hadoop用户下进行 17/07/26 20:26:12 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = master/192.168.230.130 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.7.3 . . . 17/07/26 20:26:15 INFO util.ExitUtil: Exiting with status 0 #status 为0才是成功 17/07/26 20:26:15 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at master/192.168.230.130 ************************************************************/ [hadoop@master hadoop]$
五、启动hadoop服务
1.启动所有的服务
[hadoop@master dfs]$ start-all.sh This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh Starting namenodes on [master] hadoop@master's password: #输入master上的hadoop的密码 master: starting namenode, logging to /usr/local/hadoop/logs/hadoop-hadoop-namenode-master.out slave1: starting datanode, logging to /usr/local/hadoop/logs/hadoop-hadoop-datanode-slave1.out slave2: starting datanode, logging to /usr/local/hadoop/logs/hadoop-hadoop-datanode-slave2.out Starting secondary namenodes [0.0.0.0] hadoop@0.0.0.0's password: #输入master上的hadoop的密码 0.0.0.0: starting secondarynamenode, logging to /usr/local/hadoop/logs/hadoop-hadoop-secondarynamenode-master.out starting yarn daemons starting resourcemanager, logging to /usr/local/hadoop/logs/yarn-hadoop-resourcemanager-master.out slave1: starting nodemanager, logging to /usr/local/hadoop/logs/yarn-hadoop-nodemanager-slave1.out slave2: starting nodemanager, logging to /usr/local/hadoop/logs/yarn-hadoop-nodemanager-slave2.out [hadoop@master dfs]$
2.验证
[hadoop@master dfs]$ jps #master上的进程 7491 Jps 6820 NameNode 7014 SecondaryNameNode 7164 ResourceManager [hadoop@master dfs]$
[root@slave1 name]# jps #slave1上的进程 3160 NodeManager 3050 DataNode 3307 Jps [root@slave1 name]#
[root@slave2 name]# jps #slave2上的进程 3233 DataNode 3469 Jps 3343 NodeManager [root@slave2 name]#
3.使用浏览器管理
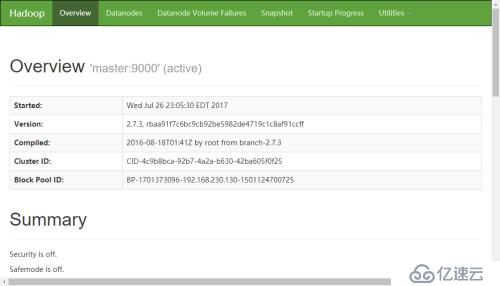
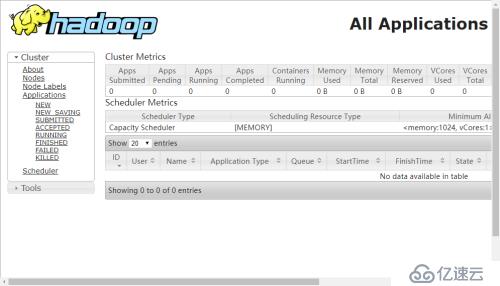
六、总结
1.格式化 hdfs namenode–format时是root用户,导致/usr/local/hadoop/dfs/data目录权限为root。切换为hadoop用户启动时发现NameNode启动不了;
2.出现问题分析日志文件找出问题原因才能有针对性的解决;
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。