您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
1、说明
这篇文章是在xxx基础上进行部署的,需要hadoop的相关配置和依赖等等,Spark on Yarn的模式,Spark安装配置好即可,在Yarn集群的所有节点安装并同步配置,在无需启动服务,没有master、slave之分,Spark提交任务给Yarn,由ResourceManager做任务调度。
2、安装
yum -y install spark-core spark-netlib spark-python
3、配置
vim /etc/spark/conf/spark-defaults.conf spark.eventLog.enabled false spark.executor.extraJavaOptions -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=70 -XX:MaxHeapFreeRatio=70 -XX:+CMSClassUnloadingEnabled spark.driver.extraJavaOptions -Dspark.driver.log.level=INFO -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=70 -XX:MaxHeapFreeRatio=70 -XX:+CMSClassUnloadingEnabled -XX:MaxPermSize=512M spark.master yarn ##指定spark的运行模式
PS:关于spark-env.sh的配置,因为我的hadoop集群是通过yum安装的,估使用默认配置就可以找到hadoop的相关配置和依赖,如果hadoop集群是二进制包安装需要修改相应的路径
4、测试
a、通过spark-shell 测试
[root@ip-10-10-103-144 conf]# cat test.txt
11
22
33
44
55
[root@ip-10-10-103-144 conf]# hadoop fs -put test.txt /tmp/
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=128m; support was removed in 8.0
[roo[root@ip-10-10-103-246 conf]# spark-shell
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=512M; support was removed in 8.0
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel).
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/lib/zookeeper/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/lib/flume-ng/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/lib/parquet/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/lib/avro/avro-tools-1.7.6-cdh6.11.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.6.0
/_/
Using Scala version 2.10.5 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_121)
Type in expressions to have them evaluated.
Type :help for more information.
Spark context available as sc (master = yarn-client, app id = application_1494472050574_0009).
SQL context available as sqlContext.
scala> val file=sc.textFile("hdfs://mycluster:8020/tmp/test.txt")
file: org.apache.spark.rdd.RDD[String] = hdfs://mycluster:8020/tmp/test.txt MapPartitionsRDD[1] at textFile at <console>:27
scala> val count=file.flatMap(line=>line.split(" ")).map(test=>(test,1)).reduceByKey(_+_)
count: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[4] at reduceByKey at <console>:29
scala> count.collect()
res0: Array[(String, Int)] = Array((33,1), (55,1), (22,1), (44,1), (11,1))
scala>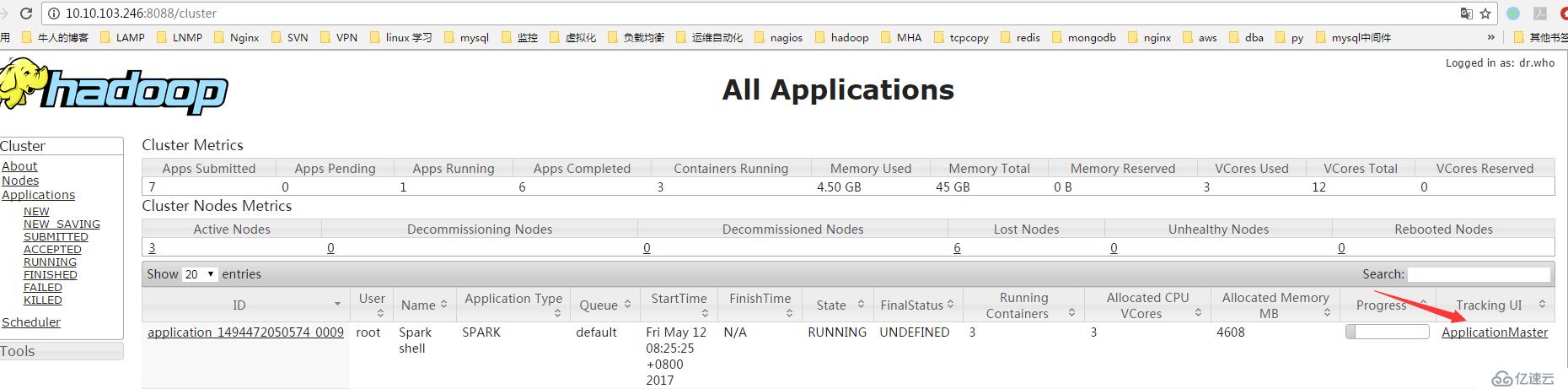
b、通过run-example测试
[root@ip-10-10-103-246 conf]# /usr/lib/spark/bin/run-example SparkPi 2>&1 | grep "Pi is roughly" Pi is roughly 3.1432557162785812
5、遇到的问题
执行spark-shell计算报错如下:
scala> val count=file.flatMap(line=>line.split(" ")).map(word=>(word,1)).reduceByKey(_+_)
17/05/11 21:06:28 ERROR lzo.GPLNativeCodeLoader: Could not load native gpl library
java.lang.UnsatisfiedLinkError: no gplcompression in java.library.path
at java.lang.ClassLoader.loadLibrary(ClassLoader.java:1867)
at java.lang.Runtime.loadLibrary0(Runtime.java:870)
at java.lang.System.loadLibrary(System.java:1122)
at com.hadoop.compression.lzo.GPLNativeCodeLoader.<clinit>(GPLNativeCodeLoader.java:32)
at com.hadoop.compression.lzo.LzoCodec.<clinit>(LzoCodec.java:71)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:348)
at $line20.$read.<init>(<console>:48)
at $line20.$read$.<init>(<console>:52)
at $line20.$read$.<clinit>(<console>)
at $line20.$eval$.<init>(<console>:7)
at $line20.$eval$.<clinit>(<console>)
at $line20.$eval.$print(<console>)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.repl.SparkIMain$ReadEvalPrint.call(SparkIMain.scala:1045)
at org.apache.spark.repl.SparkIMain$Request.loadAndRun(SparkIMain.scala:1326)
at org.apache.spark.repl.SparkIMain.loadAndRunReq$1(SparkIMain.scala:821)
at org.apache.spark.repl.SparkIMain.interpret(SparkIMain.scala:852)
at org.apache.spark.repl.SparkIMain.interpret(SparkIMain.scala:800)
at org.apache.spark.repl.SparkILoop.reallyInterpret$1(SparkILoop.scala:857)
at org.apache.spark.repl.SparkILoop.interpretStartingWith(SparkILoop.scala:902)解决方案:
在spark-env.sh添加
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/lib/hadoop/lib/native/
让Spark能找到lzo的lib包即可。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。