您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章主要介绍了python中tensorflow如何实现解猫狗识别功能,具有一定借鉴价值,感兴趣的朋友可以参考下,希望大家阅读完这篇文章之后大有收获,下面让小编带着大家一起了解一下。
| train | cats:1000 ,dogs:1000 |
|---|---|
| test | cats: 500,dogs:500 |
| validation | cats:500,dogs:500 |
train_dir = 'Data/train' test_dir = 'Data/test' validation_dir = 'Data/validation' train_datagen = ImageDataGenerator(rescale=1/255, rotation_range=10, width_shift_range=0.2, #图片水平偏移的角度 height_shift_range=0.2, #图片数值偏移的角度 shear_range=0.2, #剪切强度 zoom_range=0.2, #随机缩放的幅度 horizontal_flip=True, #是否进行随机水平翻转 # fill_mode='nearest' ) train_generator = train_datagen.flow_from_directory(train_dir, (224,224),batch_size=1,class_mode='binary',shuffle=False) test_datagen = ImageDataGenerator(rescale=1/255) test_generator = test_datagen.flow_from_directory(test_dir, (224,224),batch_size=1,class_mode='binary',shuffle=True) validation_datagen = ImageDataGenerator(rescale=1/255) validation_generator = validation_datagen.flow_from_directory( validation_dir,(224,224),batch_size=1,class_mode='binary') print(train_datagen) print(test_datagen) print(train_datagen)
我这里是将ImageDataGenerator类里的数据提取出来,将数据与标签分别存放在两个列表,后面在转为np.array,也可以使用model.fit_generator,我将数据放在内存为了后续调参数时模型训练能更快读取到数据,不用每次训练一整轮都去读一次数据(应该是这样的…我是这样理解…)
注意我这里的数据集构建后,三种数据都是存放在内存中的,我电脑内存是16g的可以存放下。
train_data=[] train_labels=[] a=0 for data_train, labels_train in train_generator: train_data.append(data_train) train_labels.append(labels_train) a=a+1 if a>1999: break x_train=np.array(train_data) y_train=np.array(train_labels) x_train=x_train.reshape(2000,224,224,3)
test_data=[] test_labels=[] a=0 for data_test, labels_test in test_generator: test_data.append(data_test) test_labels.append(labels_test) a=a+1 if a>999: break x_test=np.array(test_data) y_test=np.array(test_labels) x_test=x_test.reshape(1000,224,224,3)
validation_data=[] validation_labels=[] a=0 for data_validation, labels_validation in validation_generator: validation_data.append(data_validation) validation_labels.append(labels_validation) a=a+1 if a>999: break x_validation=np.array(validation_data) y_validation=np.array(validation_labels) x_validation=x_validation.reshape(1000,224,224,3)
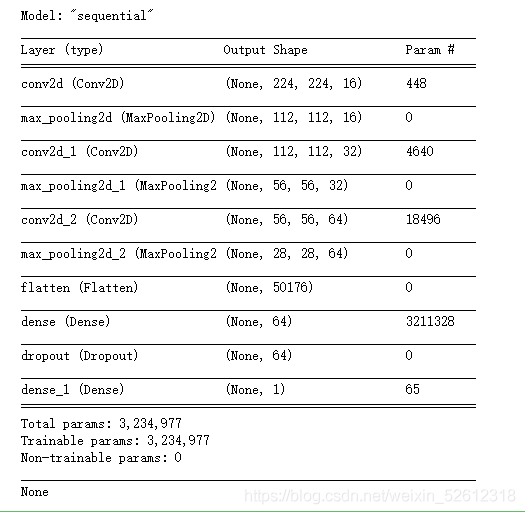
model1 = tf.keras.models.Sequential([ # 第一层卷积,卷积核为,共16个,输入为150*150*1 tf.keras.layers.Conv2D(16,(3,3),activation='relu',padding='same',input_shape=(224,224,3)), tf.keras.layers.MaxPooling2D((2,2)), # 第二层卷积,卷积核为3*3,共32个, tf.keras.layers.Conv2D(32,(3,3),activation='relu',padding='same'), tf.keras.layers.MaxPooling2D((2,2)), # 第三层卷积,卷积核为3*3,共64个, tf.keras.layers.Conv2D(64,(3,3),activation='relu',padding='same'), tf.keras.layers.MaxPooling2D((2,2)), # 数据铺平 tf.keras.layers.Flatten(), tf.keras.layers.Dense(64,activation='relu'), tf.keras.layers.Dropout(0.5), tf.keras.layers.Dense(1,activation='sigmoid') ]) print(model1.summary())
模型summary:
model1.compile(optimize=tf.keras.optimizers.SGD(0.00001),
loss=tf.keras.losses.binary_crossentropy,
metrics=['acc'])
history1=model1.fit(x_train,y_train,
# validation_split=(0~1) 选择一定的比例用于验证集,可被validation_data覆盖
validation_data=(x_validation,y_validation),
batch_size=10,
shuffle=True,
epochs=10)
model1.save('cats_and_dogs_plain1.h6')
print(history1)
plt.plot(history1.epoch,history1.history.get('acc'),label='acc')
plt.plot(history1.epoch,history1.history.get('val_acc'),label='val_acc')
plt.title('正确率')
plt.legend()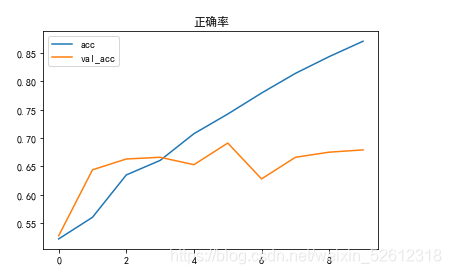
可以看到我们的模型泛化能力还是有点差,测试集的acc能达到0.85以上,验证集却在0.65~0.70之前跳动。
model1.evaluate(x_validation,y_validation)
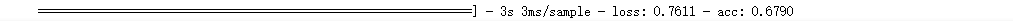
最后我们的模型在测试集上的正确率为0.67,可以说还不够好,有点过拟合,可能是训练数据不够多,后续可以数据增广或者从验证集、测试集中调取一部分数据用于训练模型,可能效果好一些。
感谢你能够认真阅读完这篇文章,希望小编分享的“python中tensorflow如何实现解猫狗识别功能”这篇文章对大家有帮助,同时也希望大家多多支持亿速云,关注亿速云行业资讯频道,更多相关知识等着你来学习!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。