жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
ж ‘еҪўз»“жһ„ж•°жҚ®еә“иЎЁSchemaи®ҫи®Ўзҡ„дёӨз§Қж–№жЎҲжҳҜжҖҺж ·зҡ„пјҢй’ҲеҜ№иҝҷдёӘй—®йўҳпјҢиҝҷзҜҮж–Үз« иҜҰз»Ҷд»Ӣз»ҚдәҶзӣёеҜ№еә”зҡ„еҲҶжһҗе’Ңи§Јзӯ”пјҢеёҢжңӣеҸҜд»Ҙеё®еҠ©жӣҙеӨҡжғіи§ЈеҶіиҝҷдёӘй—®йўҳзҡ„е°ҸдјҷдјҙжүҫеҲ°жӣҙз®ҖеҚ•жҳ“иЎҢзҡ„ж–№жі•гҖӮ
зЁӢеәҸи®ҫи®ЎиҝҮзЁӢдёӯпјҢжҲ‘д»¬еёёеёёз”Ёж ‘еҪўз»“жһ„жқҘиЎЁеҫҒжҹҗдәӣж•°жҚ®зҡ„е…іиҒ”е…ізі»пјҢеҰӮдјҒдёҡдёҠдёӢзә§йғЁй—ЁгҖҒж Ҹзӣ®з»“жһ„гҖҒе•Ҷе“ҒеҲҶзұ»зӯүзӯүпјҢйҖҡеёёиҖҢиЁҖпјҢиҝҷдәӣж ‘зҠ¶з»“жһ„йңҖиҰҒеҖҹеҠ©дәҺж•°жҚ®еә“е®ҢжҲҗжҢҒд№…еҢ–гҖӮ然иҖҢзӣ®еүҚзҡ„еҗ„з§ҚеҹәдәҺе…ізі»зҡ„ж•°жҚ®еә“пјҢйғҪжҳҜд»ҘдәҢз»ҙиЎЁзҡ„еҪўејҸи®°еҪ•еӯҳеӮЁж•°жҚ®дҝЎжҒҜпјҢеӣ жӯӨжҳҜдёҚиғҪзӣҙжҺҘе°ҶTreeеӯҳе…ҘDBMSпјҢи®ҫи®ЎеҗҲйҖӮзҡ„SchemaеҸҠе…¶еҜ№еә”зҡ„CRUDз®—жі•жҳҜе®һзҺ°е…ізі»еһӢж•°жҚ®еә“дёӯеӯҳеӮЁж ‘еҪўз»“жһ„зҡ„е…ій”®гҖӮ
зҗҶжғідёӯж ‘еҪўз»“жһ„еә”иҜҘе…·еӨҮеҰӮдёӢзү№еҫҒпјҡж•°жҚ®еӯҳеӮЁеҶ—дҪҷеәҰе°ҸгҖҒзӣҙи§ӮжҖ§ејәпјӣжЈҖзҙўйҒҚеҺҶиҝҮзЁӢз®ҖеҚ•й«ҳж•ҲпјӣиҠӮзӮ№еўһеҲ ж”№жҹҘCRUDж“ҚдҪңй«ҳж•ҲгҖӮж— ж„ҸдёӯеңЁзҪ‘дёҠжҗңзҙўеҲ°дёҖз§ҚеҫҲе·§еҰҷзҡ„и®ҫи®ЎпјҢеҺҹж–ҮжҳҜиӢұж–ҮпјҢзңӢиҝҮеҗҺж„ҹи§үжңүзӮ№ж„ҸжҖқпјҢдәҺжҳҜдҫҝж•ҙзҗҶдәҶдёҖдёӢгҖӮжң¬ж–Үе°Ҷд»Ӣз»ҚдёӨз§Қж ‘еҪўз»“жһ„зҡ„Schemaи®ҫи®Ўж–№жЎҲпјҡдёҖз§ҚжҳҜзӣҙи§ӮиҖҢз®ҖеҚ•зҡ„и®ҫи®ЎжҖқи·ҜпјҢеҸҰдёҖз§ҚжҳҜеҹәдәҺе·ҰеҸіеҖјзј–з Ғзҡ„ж”№иҝӣж–№жЎҲгҖӮ
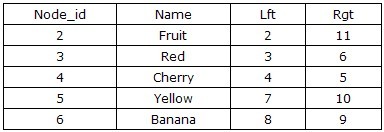
жң¬ж–ҮеҲ—дёҫдәҶдёҖдёӘйЈҹе“Ғж—Ҹи°ұзҡ„дҫӢеӯҗиҝӣиЎҢи®Іи§ЈпјҢйҖҡиҝҮзұ»еҲ«гҖҒйўңиүІе’Ңе“Ғз§Қз»„з»ҮйЈҹе“ҒпјҢж ‘еҪўз»“жһ„еӣҫеҰӮдёӢпјҡ
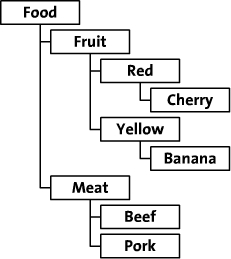
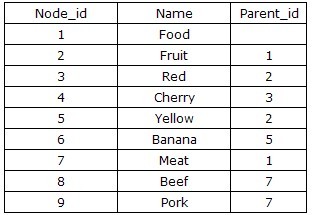
еҜ№ж ‘еҪўз»“жһ„жңҖзӣҙи§Ӯзҡ„еҲҶжһҗиҺ«иҝҮдәҺиҠӮзӮ№д№Ӣй—ҙзҡ„继жүҝе…ізі»дёҠпјҢйҖҡиҝҮжҳҫзӨәең°жҸҸиҝ°жҹҗдёҖиҠӮзӮ№зҡ„зҲ¶иҠӮзӮ№пјҢд»ҺиҖҢиғҪеӨҹе»әз«ӢдәҢз»ҙзҡ„е…ізі»иЎЁпјҢеҲҷиҝҷз§Қж–№жЎҲзҡ„TreeиЎЁз»“жһ„йҖҡеёёи®ҫи®Ўдёәпјҡ{Node_id,Parent_id}пјҢдёҠиҝ°ж•°жҚ®еҸҜд»ҘжҸҸиҝ°дёәеҰӮдёӢеӣҫжүҖзӨәпјҡ
иҝҷз§Қж–№жЎҲзҡ„дјҳзӮ№еҫҲжҳҺжҳҫпјҡи®ҫи®Ўе’Ңе®һзҺ°иҮӘ然иҖҢ然пјҢйқһеёёзӣҙи§Ӯе’Ңж–№дҫҝгҖӮзјәзӮ№еҪ“然д№ҹжҳҜйқһеёёзҡ„зӘҒеҮәпјҡз”ұдәҺзӣҙжҺҘең°и®°еҪ•дәҶиҠӮзӮ№д№Ӣй—ҙзҡ„继жүҝе…ізі»пјҢеӣ жӯӨеҜ№Treeзҡ„д»»дҪ•CRUDж“ҚдҪңйғҪе°ҶжҳҜдҪҺж•Ҳзҡ„пјҢиҝҷдё»иҰҒеҪ’ж №дәҺйў‘з№Ғзҡ„вҖңйҖ’еҪ’вҖқж“ҚдҪңпјҢйҖ’еҪ’иҝҮзЁӢдёҚж–ӯең°и®ҝй—®ж•°жҚ®еә“пјҢжҜҸж¬Ўж•°жҚ®еә“IOйғҪдјҡжңүж—¶й—ҙејҖй”ҖгҖӮеҪ“然пјҢиҝҷз§Қж–№жЎҲ并йқһжІЎжңүз”ЁжӯҰд№Ӣең°пјҢеңЁTree规模зӣёеҜ№иҫғе°Ҹзҡ„жғ…еҶөдёӢпјҢжҲ‘们еҸҜд»ҘеҖҹеҠ©дәҺзј“еӯҳжңәеҲ¶жқҘеҒҡдјҳеҢ–пјҢе°ҶTreeзҡ„дҝЎжҒҜиҪҪе…ҘеҶ…еӯҳиҝӣиЎҢеӨ„зҗҶпјҢйҒҝе…ҚзӣҙжҺҘеҜ№ж•°жҚ®еә“IOж“ҚдҪңзҡ„жҖ§иғҪејҖй”ҖгҖӮ
еңЁеҹәдәҺж•°жҚ®еә“зҡ„дёҖиҲ¬еә”з”ЁдёӯпјҢжҹҘиҜўзҡ„йңҖжұӮжҖ»иҰҒеӨ§дәҺеҲ йҷӨе’Ңдҝ®ж”№гҖӮдёәдәҶйҒҝе…ҚеҜ№дәҺж ‘еҪўз»“жһ„жҹҘиҜўж—¶зҡ„вҖңйҖ’еҪ’вҖқиҝҮзЁӢпјҢеҹәдәҺTreeзҡ„еүҚеәҸйҒҚеҺҶи®ҫи®ЎдёҖз§Қе…Ёж–°зҡ„ж— йҖ’еҪ’жҹҘиҜўгҖҒж— йҷҗеҲҶз»„зҡ„е·ҰеҸіеҖјзј–з Ғж–№жЎҲпјҢжқҘдҝқеӯҳиҜҘж ‘зҡ„ж•°жҚ®гҖӮ
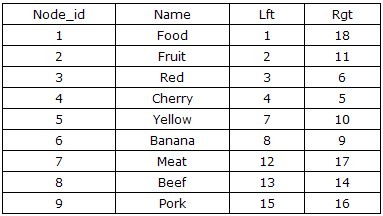
第дёҖж¬ЎзңӢи§Ғиҝҷз§ҚиЎЁз»“жһ„пјҢзӣёдҝЎеӨ§йғЁеҲҶдәәйғҪдёҚжё…жҘҡе·ҰеҖјпјҲLftпјүе’ҢеҸіеҖјпјҲRgtпјүжҳҜеҰӮдҪ•и®Ўз®—еҮәжқҘзҡ„пјҢиҖҢдё”иҝҷз§ҚиЎЁи®ҫи®Ўдјјд№Һ并没жңүдҝқеӯҳзҲ¶еӯҗиҠӮзӮ№зҡ„继жүҝе…ізі»гҖӮдҪҶеҪ“дҪ з”ЁжүӢжҢҮжҢҮзқҖиЎЁдёӯзҡ„ж•°еӯ—д»Һ1ж•°еҲ°18пјҢдҪ еә”иҜҘдјҡеҸ‘зҺ°зӮ№д»Җд№Ҳеҗ§гҖӮеҜ№пјҢдҪ жүӢжҢҮ移еҠЁзҡ„йЎәеәҸе°ұжҳҜеҜ№иҝҷжЈөж ‘иҝӣиЎҢеүҚеәҸйҒҚеҺҶзҡ„йЎәеәҸпјҢеҰӮдёӢеӣҫжүҖзӨәгҖӮеҪ“жҲ‘们д»Һж №иҠӮзӮ№Foodе·Ұдҫ§ејҖе§ӢпјҢж Үи®°дёә1пјҢ并жІҝеүҚеәҸйҒҚеҺҶзҡ„ж–№еҗ‘пјҢдҫқж¬ЎеңЁйҒҚеҺҶзҡ„и·Ҝеҫ„дёҠж ҮжіЁж•°еӯ—пјҢжңҖеҗҺжҲ‘们еӣһеҲ°дәҶж №иҠӮзӮ№FoodпјҢ并еңЁеҸіиҫ№еҶҷдёҠдәҶ18гҖӮ
第дёҖж¬ЎзңӢи§Ғиҝҷз§ҚиЎЁз»“жһ„пјҢзӣёдҝЎеӨ§йғЁеҲҶдәәйғҪдёҚжё…жҘҡе·ҰеҖјпјҲLftпјүе’ҢеҸіеҖјпјҲRgtпјүжҳҜеҰӮдҪ•и®Ўз®—еҮәжқҘзҡ„пјҢиҖҢдё”иҝҷз§ҚиЎЁи®ҫи®Ўдјјд№Һ并没жңүдҝқеӯҳзҲ¶еӯҗиҠӮзӮ№зҡ„继жүҝе…ізі»гҖӮдҪҶеҪ“дҪ з”ЁжүӢжҢҮжҢҮзқҖиЎЁдёӯзҡ„ж•°еӯ—д»Һ1ж•°еҲ°18пјҢдҪ еә”иҜҘдјҡеҸ‘зҺ°зӮ№д»Җд№Ҳеҗ§гҖӮеҜ№пјҢдҪ жүӢжҢҮ移еҠЁзҡ„йЎәеәҸе°ұжҳҜеҜ№иҝҷжЈөж ‘иҝӣиЎҢеүҚеәҸйҒҚеҺҶзҡ„йЎәеәҸпјҢеҰӮдёӢеӣҫжүҖзӨәгҖӮеҪ“жҲ‘们д»Һж №иҠӮзӮ№Foodе·Ұдҫ§ејҖе§ӢпјҢж Үи®°дёә1пјҢ并жІҝеүҚеәҸйҒҚеҺҶзҡ„ж–№еҗ‘пјҢдҫқж¬ЎеңЁйҒҚеҺҶзҡ„и·Ҝеҫ„дёҠж ҮжіЁж•°еӯ—пјҢжңҖеҗҺжҲ‘们еӣһеҲ°дәҶж №иҠӮзӮ№FoodпјҢ并еңЁеҸіиҫ№еҶҷдёҠдәҶ18гҖӮ
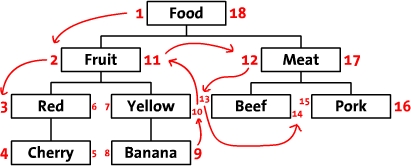
дҫқжҚ®жӯӨи®ҫи®ЎпјҢжҲ‘们еҸҜд»ҘжҺЁж–ӯеҮәжүҖжңүе·ҰеҖјеӨ§дәҺ2пјҢ并且еҸіеҖје°ҸдәҺ11зҡ„иҠӮзӮ№йғҪжҳҜFruitзҡ„еҗҺз»ӯиҠӮзӮ№пјҢж•ҙжЈөж ‘зҡ„з»“жһ„йҖҡиҝҮе·ҰеҖје’ҢеҸіеҖјеӯҳеӮЁдәҶдёӢжқҘгҖӮ然иҖҢпјҢиҝҷиҝҳдёҚеӨҹпјҢжҲ‘们зҡ„зӣ®зҡ„жҳҜиғҪеӨҹеҜ№ж ‘иҝӣиЎҢCRUDж“ҚдҪңпјҢеҚійңҖиҰҒжһ„йҖ еҮәдёҺд№Ӣй…ҚеҘ—зҡ„зӣёе…із®—жі•гҖӮ
еҸӘйңҖиҰҒдёҖжқЎSQLиҜӯеҸҘпјҢеҚіеҸҜиҝ”еӣһиҜҘиҠӮзӮ№еӯҗеӯҷиҠӮзӮ№зҡ„еүҚеәҸйҒҚеҺҶеҲ—иЎЁпјҢд»ҘFruitдёәдҫӢпјҡSELECT* FROM Tree WHERE Lft BETWEEN 2 AND 11 ORDER BY Lft ASCгҖӮжҹҘиҜўз»“жһңеҰӮдёӢжүҖзӨәпјҡ
йӮЈд№ҲжҹҗдёӘиҠӮзӮ№еҲ°еә•жңүеӨҡе°‘зҡ„еӯҗеӯҷиҠӮзӮ№е‘ўпјҹйҖҡиҝҮиҜҘиҠӮзӮ№зҡ„е·ҰгҖҒеҸіеҖјжҲ‘们еҸҜд»Ҙе°Ҷе…¶еӯҗеӯҷиҠӮзӮ№еңҲиҝӣжқҘпјҢеҲҷеӯҗеӯҷжҖ»ж•° = (еҸіеҖј вҖ“ е·ҰеҖјвҖ“ 1) / 2пјҢд»ҘFruitдёәдҫӢпјҢе…¶еӯҗеӯҷжҖ»ж•°дёәпјҡ(11 вҖ“2 вҖ“ 1) / 2 = 4гҖӮеҗҢж—¶пјҢдёәдәҶжӣҙдёәзӣҙи§Ӯең°еұ•зҺ°ж ‘еҪўз»“жһ„пјҢжҲ‘们йңҖиҰҒзҹҘйҒ“иҠӮзӮ№еңЁж ‘дёӯжүҖеӨ„зҡ„еұӮж¬ЎпјҢйҖҡиҝҮе·ҰгҖҒеҸіеҖјзҡ„SQLжҹҘиҜўеҚіеҸҜе®һзҺ°пјҢд»ҘFruitдёәдҫӢпјҡSELECTCOUNT(*) FROM Tree WHERE Lft <= 2 AND Rgt >=11гҖӮдёәдәҶж–№дҫҝжҸҸиҝ°пјҢжҲ‘们еҸҜд»ҘдёәTreeе»әз«ӢдёҖдёӘи§ҶеӣҫпјҢж·»еҠ дёҖдёӘеұӮж¬Ўж•°еҲ—пјҢиҜҘеҲ—ж•°еҖјеҸҜд»ҘеҶҷдёҖдёӘиҮӘе®ҡд№үеҮҪж•°жқҘи®Ўз®—пјҢеҮҪж•°е®ҡд№үеҰӮдёӢпјҡ
CREATE FUNCTION dbo.CountLayer ( @node_id int ) RETURNS int AS begin declare @result int set @result = 0 declare @lft int declare @rgt int if exists(select Node_id from Tree where Node_id = @node_id) begin select @lft = Lft, @rgt = Rgt from Tree where node_id = @node_id select @result = count(*) from Tree where Lft <= @lft and Rgt >= @rgt end return @result end GO
еҹәдәҺеұӮж¬Ўи®Ўз®—еҮҪж•°пјҢжҲ‘们еҲӣе»әдёҖдёӘи§ҶеӣҫпјҢж·»еҠ дәҶж–°зҡ„и®°еҪ•иҠӮзӮ№еұӮж¬Ўзҡ„ж•°еҲ—пјҡ
CREATE VIEW dbo.TreeView AS SELECT Node_id, Name, Lft, Rgt, dbo.CountLayer(Node_id) AS Layer FROM dbo.Tree ORDER BY Lft GO
еҲӣе»әеӯҳеӮЁиҝҮзЁӢпјҢз”ЁдәҺи®Ўз®—з»ҷе®ҡиҠӮзӮ№зҡ„жүҖжңүеӯҗеӯҷиҠӮзӮ№еҸҠзӣёеә”зҡ„еұӮж¬Ўпјҡ
CREATE PROCEDURE [dbo].[GetChildrenNodeList] ( @node_id int ) AS declare @lft int declare @rgt int if exists(select Node_id from Tree where node_id = @node_id) begin select @lft = Lft, @rgt = Rgt from Tree where Node_id = @node_id select * from TreeView where Lft between @lft and @rgt order by Lft ASC end GO
зҺ°еңЁпјҢжҲ‘们дҪҝз”ЁдёҠйқўзҡ„еӯҳеӮЁиҝҮзЁӢжқҘи®Ўз®—иҠӮзӮ№FruitжүҖжңүеӯҗеӯҷиҠӮзӮ№еҸҠеҜ№еә”еұӮж¬ЎпјҢжҹҘиҜўз»“жһңеҰӮдёӢпјҡ
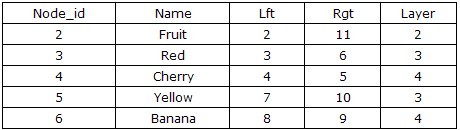
д»ҺдёҠйқўзҡ„е®һзҺ°дёӯпјҢжҲ‘们еҸҜд»ҘзңӢеҮәйҮҮз”Ёе·ҰеҸіеҖјзј–з Ғзҡ„и®ҫи®Ўж–№жЎҲпјҢеңЁиҝӣиЎҢж ‘зҡ„жҹҘиҜўйҒҚеҺҶж—¶пјҢеҸӘйңҖиҰҒиҝӣиЎҢ2ж¬Ўж•°жҚ®еә“жҹҘиҜўпјҢж¶ҲйҷӨдәҶйҖ’еҪ’пјҢеҶҚеҠ дёҠжҹҘиҜўжқЎд»¶йғҪжҳҜж•°еӯ—зҡ„жҜ”иҫғпјҢжҹҘиҜўзҡ„ж•ҲзҺҮжҳҜжһҒй«ҳзҡ„пјҢйҡҸзқҖж ‘и§„жЁЎзҡ„дёҚж–ӯжү©еӨ§пјҢеҹәдәҺе·ҰеҸіеҖјзј–з Ғзҡ„и®ҫи®Ўж–№жЎҲе°ҶжҜ”дј з»ҹзҡ„йҖ’еҪ’ж–№жЎҲжҹҘиҜўж•ҲзҺҮжҸҗй«ҳжӣҙеӨҡгҖӮеҪ“然пјҢеүҚйқўжҲ‘们еҸӘз»ҷеҮәдәҶдёҖдёӘз®ҖеҚ•зҡ„иҺ·еҸ–иҠӮзӮ№еӯҗеӯҷзҡ„з®—жі•пјҢзңҹжӯЈең°дҪҝз”ЁиҝҷжЈөж ‘жҲ‘们йңҖиҰҒе®һзҺ°жҸ’е…ҘгҖҒеҲ йҷӨеҗҢеұӮ平移иҠӮзӮ№зӯүеҠҹиғҪгҖӮ
еҒҮе®ҡжҲ‘们иҰҒиҺ·еҫ—жҹҗиҠӮзӮ№зҡ„ж—Ҹи°ұи·Ҝеҫ„пјҢеҲҷж №жҚ®е·ҰгҖҒеҸіеҖјеҲҶжһҗеҸӘйңҖиҰҒдёҖжқЎSQLиҜӯеҸҘеҚіеҸҜе®ҢжҲҗпјҢд»ҘFruitдёәдҫӢпјҡSELECT* FROM Tree WHERE Lft < 2 AND Rgt > 11 ORDER BY Lft ASC пјҢзӣёеҜ№е®Ңж•ҙзҡ„еӯҳеӮЁиҝҮзЁӢпјҡ
CREATE PROCEDURE [dbo].[GetParentNodePath] ( @node_id int ) AS declare @lft int declare @rgt int if exists(select Node_id from Tree where Node_id = @node_id) begin select @lft = Lft, @rgt = Rgt from Tree where Node_id = @node_id select * from TreeView where Lft < @lft and Rgt > @rgt order by Lft ASC end GO
еҒҮе®ҡжҲ‘们иҰҒеңЁиҠӮзӮ№вҖңRedвҖқдёӢж·»еҠ дёҖдёӘж–°зҡ„еӯҗиҠӮзӮ№вҖңAppleвҖқпјҢиҜҘж ‘е°ҶеҸҳжҲҗеҰӮдёӢеӣҫжүҖзӨәпјҢе…¶дёӯзәўиүІиҠӮзӮ№дёәж–°еўһиҠӮзӮ№гҖӮ
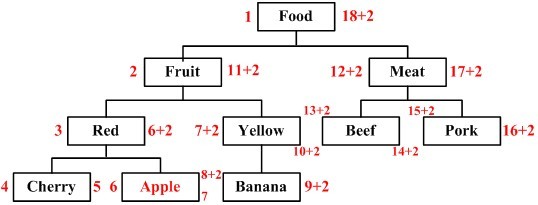
д»”з»Ҷи§ӮеҜҹеӣҫдёӯиҠӮзӮ№е·ҰеҸіеҖјеҸҳеҢ–пјҢзӣёдҝЎеӨ§е®¶йғҪеә”иҜҘиғҪеӨҹжҺЁж–ӯеҮәеҰӮдҪ•еҶҷSQLи„ҡжң¬дәҶеҗ§гҖӮжҲ‘们еҸҜд»Ҙз»ҷеҮәзӣёеҜ№е®Ңж•ҙзҡ„жҸ’е…ҘеӯҗиҠӮзӮ№зҡ„еӯҳеӮЁиҝҮзЁӢпјҡ
CREATE PROCEDURE [dbo].[AddSubNode] ( @node_id int, @node_name varchar(50) ) AS declare @rgt int if exists(select Node_id from Tree where Node_id = @node_id) begin SET XACT_ABORT ON BEGIN TRANSCTION select @rgt = Rgt from Tree where Node_id = @node_id update Tree set Rgt = Rgt + 2 where Rgt >= @rgt update Tree set Lft = Lft + 2 where Lft >= @rgt insert into Tree(Name, Lft, Rgt) values(@node_name, @rgt, @rgt + 1) COMMIT TRANSACTION SET XACT_ABORT OFF end GO
еҰӮжһңжҲ‘们жғіиҰҒеҲ йҷӨжҹҗдёӘиҠӮзӮ№пјҢдјҡеҗҢж—¶еҲ йҷӨиҜҘиҠӮзӮ№зҡ„жүҖжңүеӯҗеӯҷиҠӮзӮ№пјҢиҖҢиҝҷдәӣиў«еҲ йҷӨзҡ„иҠӮзӮ№зҡ„дёӘж•°дёәпјҡ(иў«еҲ йҷӨиҠӮзӮ№зҡ„еҸіеҖј вҖ“ иў«еҲ йҷӨиҠӮзӮ№зҡ„е·ҰеҖј+ 1) / 2пјҢиҖҢеү©дёӢзҡ„иҠӮзӮ№е·ҰгҖҒеҸіеҖјеңЁеӨ§дәҺиў«еҲ йҷӨиҠӮзӮ№е·ҰгҖҒеҸіеҖјзҡ„жғ…еҶөдёӢдјҡиҝӣиЎҢи°ғж•ҙгҖӮжқҘзңӢзңӢж ‘дјҡеҸ‘з”ҹд»Җд№ҲеҸҳеҢ–пјҢд»ҘBeefдёәдҫӢпјҢеҲ йҷӨж•ҲжһңеҰӮдёӢеӣҫжүҖзӨәгҖӮ
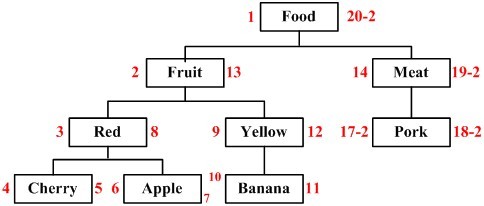
еҲҷжҲ‘们еҸҜд»Ҙжһ„йҖ еҮәзӣёеә”зҡ„еӯҳеӮЁиҝҮзЁӢпјҡ
CREATE PROCEDURE [dbo].[DelNode] ( @node_id int ) AS declare @lft int declare @rgt int if exists(select Node_id from Tree where Node_id = @node_id) begin SET XACT_ABORT ON BEGIN TRANSCTION select @lft = Lft, @rgt = Rgt from Tree where Node_id = @node_id delete from Tree where Lft >= @lft and Rgt <= @rgt update Tree set Lft = Lft вҖ“ (@rgt - @lft + 1) where Lft > @lft update Tree set Rgt = Rgt вҖ“ (@rgt - @lft + 1) where Rgt > @rgt COMMIT TRANSACTION SET XACT_ABORT OFF end GO
жҲ‘们еҸҜд»ҘеҜ№иҝҷз§ҚйҖҡиҝҮе·ҰеҸіеҖјзј–з Ғе®һзҺ°ж— йҷҗеҲҶз»„зҡ„ж ‘еҪўз»“жһ„Schemaи®ҫи®Ўж–№жЎҲеҒҡдёҖдёӘжҖ»з»“пјҡ
пјҲ1пјүдјҳзӮ№пјҡеңЁж¶ҲйҷӨдәҶйҖ’еҪ’ж“ҚдҪңзҡ„еүҚжҸҗдёӢе®һзҺ°дәҶж— йҷҗеҲҶз»„пјҢиҖҢдё”жҹҘиҜўжқЎд»¶жҳҜеҹәдәҺж•ҙеҪўж•°еӯ—зҡ„жҜ”иҫғпјҢж•ҲзҺҮеҫҲй«ҳгҖӮ
пјҲ2пјүзјәзӮ№пјҡиҠӮзӮ№зҡ„ж·»еҠ гҖҒеҲ йҷӨеҸҠдҝ®ж”№д»Јд»·иҫғеӨ§пјҢе°Ҷдјҡж¶үеҸҠеҲ°иЎЁдёӯеӨҡж–№йқўж•°жҚ®зҡ„ж”№еҠЁгҖӮ
еҪ“然пјҢжң¬ж–ҮеҸӘз»ҷеҮәдәҶеҮ з§ҚжҜ”иҫғеёёи§Ғзҡ„CRUDз®—жі•зҡ„е®һзҺ°пјҢжҲ‘们еҗҢж ·еҸҜд»ҘиҮӘе·ұж·»еҠ иҜёеҰӮеҗҢеұӮиҠӮзӮ№е№із§»гҖҒиҠӮзӮ№дёӢ移гҖҒиҠӮзӮ№дёҠ移зӯүж“ҚдҪңгҖӮжңүе…ҙи¶Јзҡ„жңӢеҸӢеҸҜд»ҘиҮӘе·ұеҠЁжүӢзј–з Ғе®һзҺ°дёҖдёӢпјҢиҝҷйҮҢдёҚеңЁеҲ—дёҫдәҶгҖӮеҖјеҫ—жіЁж„Ҹзҡ„жҳҜпјҢе®һзҺ°иҝҷдәӣз®—жі•еҸҜиғҪдјҡжҜ”иҫғйә»зғҰпјҢдјҡж¶үеҸҠеҲ°еҫҲеӨҡжқЎupdateиҜӯеҸҘзҡ„йЎәеәҸжү§иЎҢпјҢеҰӮжһңйЎәеәҸи°ғеәҰиҖғиҷ‘дёҚе‘ЁиҜҰпјҢеҮәзҺ°Bugзҡ„иҜқе°ҶдјҡеҜ№ж•ҙдёӘж ‘еҪўз»“жһ„иЎЁдә§з”ҹжғҠдәәзҡ„з ҙеқҸгҖӮеӣ жӯӨпјҢеңЁеҜ№ж ‘еҪўз»“жһ„иҝӣиЎҢеӨ§и§„жЁЎдҝ®ж”№зҡ„ж—¶еҖҷпјҢеҸҜд»ҘйҮҮз”Ёдёҙж—¶иЎЁеҒҡдёӯд»ӢпјҢд»ҘйҷҚдҪҺд»Јз Ғзҡ„еӨҚжқӮеәҰпјҢеҗҢж—¶пјҢејәзғҲжҺЁиҚҗеңЁеҒҡдҝ®ж”№д№ӢеүҚеҜ№иЎЁиҝӣиЎҢе®Ңж•ҙеӨҮд»ҪпјҢд»ҘеӨҮдёҚж—¶д№ӢйңҖгҖӮеңЁд»ҘжҹҘиҜўдёәдё»зҡ„з»қеӨ§еӨҡж•°еҹәдәҺж•°жҚ®еә“зҡ„еә”з”Ёзі»з»ҹдёӯпјҢиҜҘж–№жЎҲзӣёжҜ”дј з»ҹзҡ„з”ұзҲ¶еӯҗ继жүҝе…ізі»жһ„е»әзҡ„ж•°жҚ®еә“SchemaжӣҙдёәйҖӮз”ЁгҖӮ
е…ідәҺж ‘еҪўз»“жһ„ж•°жҚ®еә“иЎЁSchemaи®ҫи®Ўзҡ„дёӨз§Қж–№жЎҲжҳҜжҖҺж ·зҡ„й—®йўҳзҡ„и§Јзӯ”е°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢеҰӮжһңдҪ иҝҳжңүеҫҲеӨҡз–‘жғ‘жІЎжңүи§ЈејҖпјҢеҸҜд»Ҙе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“дәҶи§ЈжӣҙеӨҡзӣёе…ізҹҘиҜҶгҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ