жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« е°ҶдёәеӨ§е®¶иҜҰз»Ҷи®Іи§Јжңүе…іжҖҺд№ҲдҪҝз”ЁpythonзҲ¬еҸ–зҹҘд№ҺзғӯжҰңTop50ж•°жҚ®пјҢе°Ҹзј–и§үеҫ—жҢәе®һз”Ёзҡ„пјҢеӣ жӯӨеҲҶдә«з»ҷеӨ§е®¶еҒҡдёӘеҸӮиҖғпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеҸҜд»ҘжңүжүҖ收иҺ·гҖӮ
import urllib.request,urllib.error #иҜ·жұӮзҪ‘йЎө from bs4 import BeautifulSoup # и§Јжһҗж•°жҚ® import sqlite3 # еҜје…Ҙж•°жҚ®еә“ import re # жӯЈеҲҷиЎЁиҫҫејҸ import time # иҺ·еҸ–еҪ“еүҚж—¶й—ҙ
def main():
# еЈ°жҳҺзҲ¬еҸ–зҪ‘йЎө
baseurl = "https://www.zhihu.com/hot"
# зҲ¬еҸ–зҪ‘йЎө
datalist = getData(baseurl)
#дҝқеӯҳж•°жҚ®
dbname = time.strftime("%Y-%m-%d", time.localtime()) #
dbpath = "zhihuTop50 " + dbname
saveData(datalist,dbpath)#жӯЈеҲҷиЎЁиҫҫејҸ findlink = re.compile(r'<a class="css-hi1lih" href="(.*?)" rel="external nofollow" rel="external nofollow" ') #й—®йўҳй“ҫжҺҘ findid = re.compile(r'<div class="css-blkmyu">(.*?)</div>') #й—®йўҳжҺ’еҗҚ findtitle = re.compile(r'<h2 class="css-3yucnr">(.*?)</h2>') #й—®йўҳж Үйўҳ findintroduce = re.compile(r'<div class="css-1o6sw4j">(.*?)</div>') #з®ҖиҰҒд»Ӣз»Қ findscore = re.compile(r'<div class="css-1iqwfle">(.*?)</div>') #зғӯй—ЁиҜ„еҲҶ findimg = re.compile(r'<img class="css-uw6cz9" src="(.*?)"/>') #ж–Үз« й…Қеӣҫ
import urllib.request,urllib.error
from bs4 import BeautifulSoup
import sqlite3
import re
import time
def main():
# еЈ°жҳҺзҲ¬еҸ–зҪ‘йЎө
baseurl = "https://www.zhihu.com/hot"
# зҲ¬еҸ–зҪ‘йЎө
datalist = getData(baseurl)
#дҝқеӯҳж•°жҚ®
dbname = time.strftime("%Y-%m-%d", time.localtime())
dbpath = "zhihuTop50 " + dbname
saveData(datalist,dbpath)
print()
#жӯЈеҲҷиЎЁиҫҫејҸ
findlink = re.compile(r'<a class="css-hi1lih" href="(.*?)" rel="external nofollow" rel="external nofollow" ') #й—®йўҳй“ҫжҺҘ
findid = re.compile(r'<div class="css-blkmyu">(.*?)</div>') #й—®йўҳжҺ’еҗҚ
findtitle = re.compile(r'<h2 class="css-3yucnr">(.*?)</h2>') #й—®йўҳж Үйўҳ
findintroduce = re.compile(r'<div class="css-1o6sw4j">(.*?)</div>') #з®ҖиҰҒд»Ӣз»Қ
findscore = re.compile(r'<div class="css-1iqwfle">(.*?)</div>') #зғӯй—ЁиҜ„еҲҶ
findimg = re.compile(r'<img class="css-uw6cz9" src="(.*?)"/>') #ж–Үз« й…Қеӣҫ
def getData(baseurl):
datalist = []
html = askURL(baseurl)
# print(html)
soup = BeautifulSoup(html,'html.parser')
for item in soup.find_all('a',class_="css-hi1lih"):
# print(item)
data = []
item = str(item)
Id = re.findall(findid,item)
if(len(Id) == 0):
Id = re.findall(r'<div class="css-mm8qdi">(.*?)</div>',item)[0]
else: Id = Id[0]
data.append(Id)
# print(Id)
Link = re.findall(findlink,item)[0]
data.append(Link)
# print(Link)
Title = re.findall(findtitle,item)[0]
data.append(Title)
# print(Title)
Introduce = re.findall(findintroduce,item)
if(len(Introduce) == 0):
Introduce = " "
else:Introduce = Introduce[0]
data.append(Introduce)
# print(Introduce)
Score = re.findall(findscore,item)[0]
data.append(Score)
# print(Score)
Img = re.findall(findimg,item)
if (len(Img) == 0):
Img = " "
else: Img = Img[0]
data.append(Img)
# print(Img)
datalist.append(data)
return datalist
def askURL(baseurl):
# и®ҫзҪ®иҜ·жұӮеӨҙ
head = {
# "User-Agent": "Mozilla/5.0 (Windows NT 10.0;Win64;x64) AppleWebKit/537.36(KHTML, likeGecko) Chrome/80.0.3987.163Safari/537.36"
"User-Agent": "Mozilla / 5.0(iPhone;CPUiPhoneOS13_2_3likeMacOSX) AppleWebKit / 605.1.15(KHTML, likeGecko) Version / 13.0.3Mobile / 15E148Safari / 604.1"
}
request = urllib.request.Request(baseurl, headers=head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
# print(html)
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html
print()
def saveData(datalist,dbpath):
init_db(dbpath)
conn = sqlite3.connect(dbpath)
cur = conn.cursor()
for data in datalist:
sql = '''
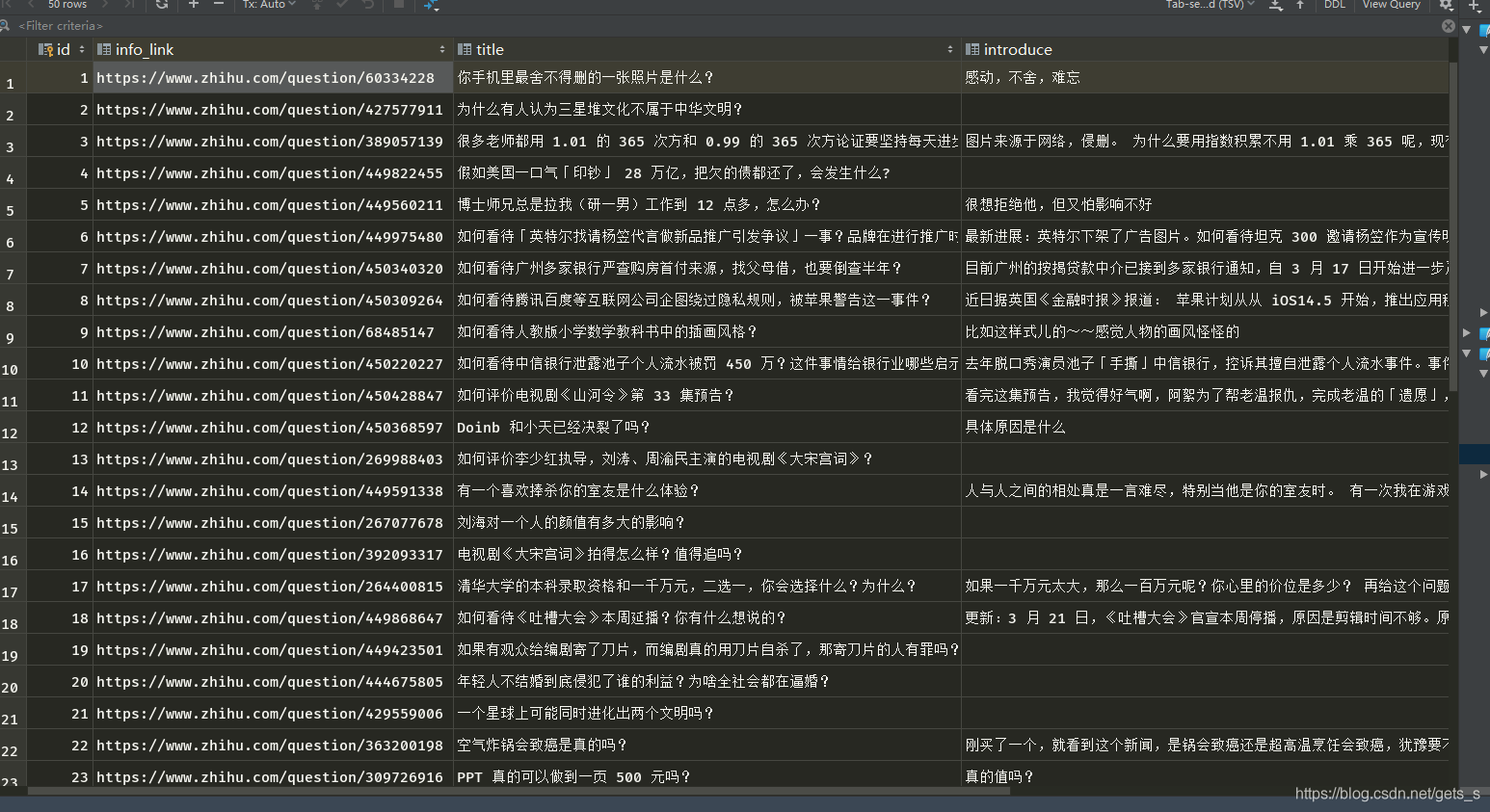
insert into Top50(
id,info_link,title,introduce,score,img)
values("%s","%s","%s","%s","%s","%s")'''%(data[0],data[1],data[2],data[3],data[4],data[5])
print(sql)
cur.execute(sql)
conn.commit()
cur.close()
conn.close()
def init_db(dbpath):
sql = '''
create table Top50
(
id integer primary key autoincrement,
info_link text,
title text,
introduce text,
score text,
img text
)
'''
conn = sqlite3.connect(dbpath)
cursor = conn.cursor()
cursor.execute(sql)
conn.commit()
conn.close()
if __name__ =="__main__":
main()е…ідәҺвҖңжҖҺд№ҲдҪҝз”ЁpythonзҲ¬еҸ–зҹҘд№ҺзғӯжҰңTop50ж•°жҚ®вҖқиҝҷзҜҮж–Үз« е°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢдҪҝеҗ„дҪҚеҸҜд»ҘеӯҰеҲ°жӣҙеӨҡзҹҘиҜҶпјҢеҰӮжһңи§үеҫ—ж–Үз« дёҚй”ҷпјҢиҜ·жҠҠе®ғеҲҶдә«еҮәеҺ»и®©жӣҙеӨҡзҡ„дәәзңӢеҲ°гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ