жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
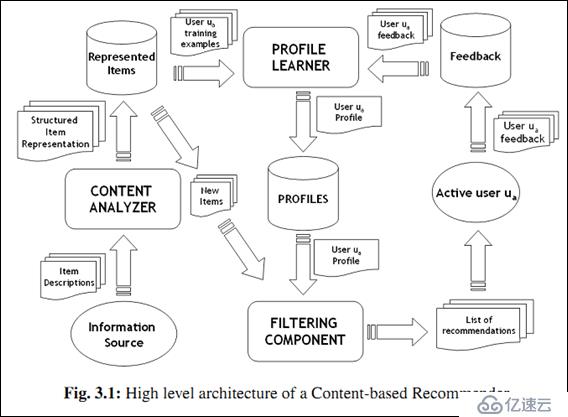
ж•°жҚ®жҢ–жҺҳвҖ”вҖ”жҺЁиҚҗзі»з»ҹ
еӨ§ж•°жҚ®еҸҜд»Ҙи®ӨдёәжҳҜи®ёеӨҡж•°жҚ®зҡ„иҒҡеҗҲпјҢж•°жҚ®жҢ–жҺҳжҳҜжҠҠиҝҷдәӣж•°жҚ®зҡ„д»·еҖјеҸ‘жҺҳеҮәжқҘпјҢжҜ”еҰӮжңүиҝҮеҺ»10е№ҙзҡ„ж°”иұЎж•°жҚ®пјҢйҖҡиҝҮж•°жҚ®жҢ–жҺҳпјҢеҮ д№ҺеҸҜд»Ҙйў„жөӢжҳҺеӨ©зҡ„еӨ©ж°”жҳҜжҖҺд№Ҳж ·зҡ„пјҢжңүиҫғеӨ§жҰӮзҺҮжҳҜжӯЈзЎ®зҡ„гҖӮ
жңәеҷЁеӯҰд№ жҳҜдәәе·ҘжҷәиғҪзҡ„ж ёеҝғпјҢеҜ№еӨ§ж•°жҚ®иҝӣиЎҢеҸ‘жҺҳпјҢйқ дәәе·ҘиӮҜе®ҡжҳҜеҒҡдёҚжқҘзҡ„пјҢйӮЈе°ұеҫ—йқ жңәеҷЁд»Јжӣҝдәәе·Ҙеҫ—еҲ°дёҖдёӘжңүж•ҲжЁЎеһӢпјҢйҖҡиҝҮиҜҘжЁЎеһӢе°ҶеӨ§ж•°жҚ®дёӯзҡ„д»·еҖјдҪ“зҺ°еҮәжқҘгҖӮ
жң¬з« еҶ…е®№пјҡ
1) ж•°жҚ®жҢ–жҺҳе’ҢжңәеҷЁеӯҰд№ жҰӮеҝө
2) дёҖдёӘжңәеҷЁеӯҰд№ еә”з”Ёж–№еҗ‘вҖ”вҖ”жҺЁиҚҗзі»з»ҹ
3) жҺЁиҚҗз®—жі•вҖ”вҖ”еҹәдәҺеҶ…е®№зҡ„жҺЁиҚҗж–№жі•
4) жҺЁиҚҗз®—жі•вҖ”вҖ”еҹәдәҺеҚҸеҗҢиҝҮж»Өзҡ„жҺЁиҚҗж–№жі•
5) еҹәдәҺMapReduceзҡ„еҚҸеҗҢиҝҮж»Өз®—жі•зҡ„е®һзҺ°
жңәеҷЁеӯҰд№ е’Ңж•°жҚ®жҢ–жҺҳжҠҖжңҜе·Із»ҸејҖе§ӢеңЁеӨҡеӘ’дҪ“гҖҒи®Ўз®—жңәеӣҫеҪўеӯҰгҖҒи®Ўз®—жңәзҪ‘з»ңд№ғиҮіж“ҚдҪңзі»з»ҹгҖҒиҪҜ件е·ҘзЁӢзӯүи®Ўз®—жңә科еӯҰзҡ„дј—еӨҡйўҶеҹҹдёӯеҸ‘жҢҘдҪңз”ЁпјҢзү№еҲ«жҳҜеңЁи®Ўз®—жңәи§Ҷ и§үе’ҢиҮӘ然иҜӯиЁҖеӨ„зҗҶйўҶеҹҹпјҢжңәеҷЁеӯҰд№ е’Ңж•°жҚ®жҢ–жҺҳе·Із»ҸжҲҗдёәжңҖжөҒиЎҢгҖҒжңҖзғӯй—Ёзҡ„жҠҖжңҜпјҢд»ҘиҮідәҺеңЁиҝҷдәӣйўҶеҹҹзҡ„йЎ¶зә§дјҡи®®дёҠзӣёеҪ“еӨҡзҡ„и®әж–ҮйғҪдёҺжңәеҷЁеӯҰд№ е’Ңж•°жҚ®жҢ–жҺҳжҠҖжңҜжңүе…ігҖӮжҖ»зҡ„жқҘзңӢпјҢеј•е…ҘжңәеҷЁеӯҰд№ е’Ңж•°жҚ®жҢ–жҺҳжҠҖжңҜеңЁи®Ўз®—жңә科еӯҰзҡ„дј—еӨҡеҲҶж”ҜйўҶеҹҹдёӯйғҪжҳҜдёҖдёӘйҮҚиҰҒи¶ӢеҠҝгҖӮ
еҜ№дәҺж•°жҚ®жҢ–жҺҳпјҢж•°жҚ®еә“жҸҗдҫӣж•°жҚ®з®ЎзҗҶжҠҖжңҜпјҢжңәеҷЁеӯҰд№ жҸҗдҫӣж•°жҚ®еҲҶжһҗжҠҖжңҜгҖӮйҖҡеёёжҲ‘们иҰҒеӨ„зҗҶзҡ„еӨ§ж•°жҚ®йҖҡиҝҮHDFSдә‘еӯҳеӮЁе№іеҸ°жқҘиҝӣиЎҢж•°жҚ®з®ЎзҗҶпјҢзӣ®еүҚHadoopз”ҹжҖҒеңҲе·Із»ҸеҸ‘еұ•жҲҗзҶҹпјҢеҗ„з§Қе·Ҙе…·е’ҢжҺҘеҸЈеҹәжң¬ж»Ўи¶іеӨ§еӨҡж•°ж•°жҚ®з®ЎзҗҶзҡ„йңҖиҰҒгҖӮйқўеҜ№иҝҷж ·еәһеӨ§зҡ„ж•°жҚ®иө„жәҗпјҢйңҖиҰҒжңүдёҖз§Қж–№жі•йңҖиҰҒи®©е…¶дёӯзҡ„д»·еҖјдҪ“зҺ°еҮәжқҘпјҢжңәеҷЁеӯҰд№ жҸҗдҫӣдәҶдёҖзі»еҲ—зҡ„еҲҶжһҗжҢ–жҺҳж•°жҚ®зҡ„ж–№жі•гҖӮ
Hadoopз”ҹжҖҒеңҲдёӯжңүдёҖдёӘжңәеҷЁеӯҰд№ ејҖжәҗеә“зҡ„йЎ№зӣ®вҖ”вҖ”MahoutпјҢжҸҗдҫӣдәҶдё°еҜҢзҡ„еҸҜжү©еұ•зҡ„жңәеҷЁеӯҰд№ йўҶеҹҹз»Ҹе…ёз®—жі•зҡ„е®һзҺ°пјҢж—ЁеңЁеё®еҠ©ејҖеҸ‘дәәе‘ҳжӣҙеҠ ж–№дҫҝеҝ«жҚ·ең°еҲӣе»әжҷәиғҪеә”з”ЁзЁӢеәҸпјҢMahoutеҢ…еҗ«и®ёеӨҡе®һзҺ°пјҢеҢ…жӢ¬иҒҡзұ»гҖҒеҲҶзұ»гҖҒжҺЁиҚҗиҝҮж»ӨгҖҒйў‘з№ҒеӯҗйЎ№жҢ–жҺҳгҖӮ
жҺЁиҚҗз®—жі•жҳҜжңҖдёәеӨ§дј—жүҖзҹҘзҡ„дёҖз§ҚжңәеҷЁеӯҰд№ жЁЎеһӢгҖӮжҺЁиҚҗжҳҜеҫҲеӨҡзҪ‘з«ҷиғҢеҗҺзҡ„ж ёеҝғ组件д№ӢдёҖпјҢжңүж—¶д№ҹжҳҜдёҖдёӘйҮҚиҰҒзҡ„收е…ҘжқҘжәҗгҖӮ
дёҖиҲ¬жқҘи®ІпјҢжҺЁиҚҗзі»з»ҹиҜ•еӣҫеҜ№з”ЁжҲ·дёҺжҹҗзұ»зү©е“Ғд№Ӣй—ҙзҡ„иҒ”зі»е»әжЁЎгҖӮжҜ”еҰӮжҲ‘们еҲ©з”ЁжҺЁиҚҗзі»з»ҹжқҘе‘ҠиҜүз”ЁжҲ·жңүе“Әдәӣз”өеҪұ他们дјҡеҸҜиғҪе–ңж¬ўгҖӮеҰӮжһңиҝҷдёҖзӮ№еҒҡзҡ„еҫҲеҘҪзҡ„иҜқпјҢе°ұиғҪеӨҹеҗёеј•жӣҙеӨҡзҡ„з”ЁжҲ·жҢҒз»ӯдҪҝз”ЁжҲ‘们зҡ„жңҚеҠЎгҖӮиҝҷеҜ№еҸҢж–№йғҪжңүеҘҪеӨ„гҖӮеҗҢж ·пјҢеҰӮжһңиғҪеҮҶзЎ®е‘ҠиҜүз”ЁжҲ·жңүе“Әдәӣз”өеҪұдёҺжҹҗдёҖдёӘз”өеҪұзӣёдјјпјҢе°ұиғҪж–№дҫҝз”ЁжҲ·еңЁз«ҷзӮ№дёҠжүҫеҲ°жӣҙеӨҡж„ҹе…ҙи¶Јзҡ„дҝЎжҒҜгҖӮиҝҷд№ҹиғҪжҸҗеҚҮз”ЁжҲ·зҡ„дҪ“йӘҢгҖҒеҸӮдёҺеәҰд»ҘеҸҠз«ҷзӮ№еҶ…е®№еҜ№з”ЁжҲ·зҡ„еҗёеј•еҠӣгҖӮеҜ№дәҺеӨ§еһӢзҪ‘з«ҷжқҘиҜҙпјҢеҫҲеӨҡеҶ…е®№жҳҜжқҘиҮӘдәҺзӢ¬з«Ӣзҡ„第дёүж–№вҖ”вҖ”еҶ…е®№жҸҗдҫӣе•ҶпјҢжҜ”еҰӮж·ҳе®қзҡ„е•Ҷе“Ғе®қиҙқеҹәжң¬жқҘиҮӘеҗ„дёӘеә—й“әгҖҒеҘҮиүәдёҠзҡ„з”өеҪұеҫҲеӨҡжқҘиҮӘдёҺдё“дёҡзҡ„дј еӘ’йӣҶеӣўе’Ңе·ҘдҪңе®ӨгҖҒеҫ®дҝЎдёҠеҲ¶дҪңзІҫиүҜзҡ„е№ҝе‘Ҡд№ҹжҳҜжқҘиҮӘдәҺеҗ„дёӘиЎҢдёҡзҡ„е№ҝе‘Ҡдё»гҖӮ
е»әз«ӢдёҖдёӘиүҜеҘҪзҡ„жҺЁиҚҗз”ҹжҖҒеңҲпјҢеҜ№дәҺз”ЁжҲ·гҖҒзҪ‘з«ҷе№іеҸ°д»ҘеҸҠеҶ…е®№жҸҗдҫӣе•ҶпјҢйғҪжҳҜжңүеҘҪеӨ„зҡ„пјҢйҰ–е…Ҳз”ЁжҲ·еҫ—еҲ°д»–们жғіиҰҒзҡ„зү©е“ҒпјҢе№іеҸ°иҺ·еҫ—жӣҙеӨҡзҡ„жөҒйҮҸе’Ң收е…ҘпјҢеҶ…е®№жҸҗдҫӣе•Ҷе”®еҚ–е…¶зү©е“Ғзҡ„ж•ҲзҺҮд№ҹдјҡжҸҗй«ҳпјҢжүҖд»ҘжҳҜдёҖдёӘдёүиҖ…е…ұиөўзҡ„дёҖдёӘеңәжҷҜпјҢжүҖд»ҘдёҖдёӘеҘҪзҡ„жҺЁиҚҗзі»з»ҹдјҡеёҰжқҘеҫҲеӨ§зҡ„д»·еҖјгҖӮ
еҹәдәҺеҶ…е®№зҡ„жҺЁиҚҗпјҲContent Basedпјүеә”иҜҘз®—жңҖж—©иў«дҪҝз”Ёзҡ„жҺЁиҚҗж–№жі•пјҢе®ғж №жҚ®з”ЁжҲ·иҝҮеҺ»е–ңж¬ўзҡ„дә§е“ҒпјҲжң¬ж–Үз»ҹз§°дёә itemпјүпјҢдёәз”ЁжҲ·жҺЁиҚҗе’Ңд»–иҝҮеҺ»е–ңж¬ўзҡ„дә§е“Ғзӣёдјјзҡ„дә§е“ҒгҖӮдҫӢеҰӮпјҢдёҖдёӘжҺЁиҚҗйҘӯеә—зҡ„зі»з»ҹеҸҜд»ҘдҫқжҚ®жҹҗдёӘз”ЁжҲ·д№ӢеүҚе–ңж¬ўеҫҲеӨҡзҡ„зғӨиӮүеә—иҖҢдёәд»–жҺЁиҚҗзғӨиӮүеә—гҖӮ CBжңҖж—©дё»иҰҒжҳҜеә”з”ЁеңЁдҝЎжҒҜжЈҖзҙўзі»з»ҹеҪ“дёӯпјҢжүҖд»ҘеҫҲеӨҡдҝЎжҒҜжЈҖзҙўеҸҠдҝЎжҒҜиҝҮж»ӨйҮҢзҡ„ж–№жі•йғҪиғҪз”ЁдәҺCBдёӯгҖӮ
CBзҡ„иҝҮзЁӢдёҖиҲ¬еҢ…жӢ¬д»ҘдёӢдёүжӯҘпјҡ
1) Item RepresentationпјҡдёәжҜҸдёӘitemжҠҪеҸ–еҮәдёҖдәӣзү№еҫҒпјҲд№ҹе°ұжҳҜitemзҡ„contentдәҶпјүжқҘиЎЁзӨәжӯӨitemпјӣ
2) Profile LearningпјҡеҲ©з”ЁдёҖдёӘз”ЁжҲ·иҝҮеҺ»е–ңж¬ўпјҲеҸҠдёҚе–ңж¬ўпјүзҡ„itemзҡ„зү№еҫҒж•°жҚ®пјҢжқҘеӯҰд№ еҮәжӯӨз”ЁжҲ·зҡ„е–ңеҘҪзү№еҫҒпјҲprofileпјүпјӣ
3) Recommendation GenerationпјҡйҖҡиҝҮжҜ”иҫғдёҠдёҖжӯҘеҫ—еҲ°зҡ„з”ЁжҲ·profileдёҺеҖҷйҖүitemзҡ„зү№еҫҒпјҢдёәжӯӨз”ЁжҲ·жҺЁиҚҗдёҖз»„зӣёе…іжҖ§жңҖеӨ§зҡ„itemгҖӮ
дёҫдёӘдҫӢеӯҗиҜҙжҳҺеүҚйқўзҡ„дёүдёӘжӯҘйӘӨгҖӮеҜ№дәҺдёӘжҖ§еҢ–йҳ…иҜ»жқҘиҜҙпјҢдёҖдёӘitemе°ұжҳҜдёҖзҜҮж–Үз« гҖӮж №жҚ®дёҠйқўзҡ„第дёҖжӯҘпјҢжҲ‘们йҰ–е…ҲиҰҒд»Һж–Үз« еҶ…е®№дёӯжҠҪеҸ–еҮәд»ЈиЎЁе®ғ们зҡ„еұһжҖ§гҖӮеёёз”Ёзҡ„ж–№жі•е°ұжҳҜеҲ©з”ЁеҮәзҺ°еңЁдёҖзҜҮж–Үз« дёӯиҜҚжқҘд»ЈиЎЁиҝҷзҜҮж–Үз« пјҢиҖҢжҜҸдёӘиҜҚеҜ№еә”зҡ„жқғйҮҚеҫҖеҫҖдҪҝз”ЁдҝЎжҒҜжЈҖзҙўдёӯзҡ„tf-idfжқҘи®Ўз®—гҖӮжҜ”еҰӮеҜ№дәҺжң¬ж–ҮжқҘиҜҙпјҢиҜҚвҖңCBвҖқгҖҒвҖңжҺЁиҚҗвҖқе’ҢвҖңе–ңеҘҪвҖқзҡ„жқғйҮҚдјҡжҜ”иҫғеӨ§пјҢиҖҢвҖңзғӨиӮүвҖқиҝҷдёӘиҜҚзҡ„жқғйҮҚдјҡжҜ”иҫғдҪҺгҖӮеҲ©з”Ёиҝҷз§Қж–№жі•пјҢдёҖзҜҮжҠҪиұЎзҡ„ж–Үз« е°ұеҸҜд»ҘдҪҝз”Ёе…·дҪ“зҡ„дёҖдёӘеҗ‘йҮҸжқҘиЎЁзӨәдәҶгҖӮ第дәҢжӯҘе°ұжҳҜж №жҚ®з”ЁжҲ·иҝҮеҺ»е–ңж¬ўд»Җд№Ҳж–Үз« жқҘдә§з”ҹеҲ»з”»жӯӨз”ЁжҲ·е–ңеҘҪзҡ„ profileдәҶпјҢжңҖз®ҖеҚ•зҡ„ж–№жі•еҸҜд»ҘжҠҠз”ЁжҲ·жүҖжңүе–ңж¬ўзҡ„ж–Үз« еҜ№еә”зҡ„еҗ‘йҮҸзҡ„е№іеқҮеҖјдҪңдёәжӯӨз”ЁжҲ·зҡ„profileгҖӮжҜ”еҰӮжҹҗдёӘз”ЁжҲ·з»Ҹеёёе…іжіЁдёҺжҺЁиҚҗзі»з»ҹжңүе…ізҡ„ж–Үз« пјҢйӮЈд№Ҳд»–зҡ„profileдёӯвҖңCBвҖқгҖҒвҖңCFвҖқе’ҢвҖңжҺЁиҚҗвҖқеҜ№еә”зҡ„жқғйҮҚеҖје°ұдјҡиҫғй«ҳгҖӮеңЁиҺ·еҫ—дәҶдёҖдёӘз”ЁжҲ·зҡ„profileеҗҺпјҢCBе°ұеҸҜд»ҘеҲ©з”ЁжүҖжңүitemдёҺжӯӨз”ЁжҲ·profileзҡ„зӣёе…іеәҰеҜ№д»–иҝӣиЎҢжҺЁиҚҗж–Үз« дәҶгҖӮдёҖдёӘеёёз”Ёзҡ„зӣёе…іеәҰи®Ўз®—ж–№жі•жҳҜcosineгҖӮжңҖз»ҲжҠҠеҖҷйҖүitemйҮҢдёҺжӯӨз”ЁжҲ·жңҖзӣёе…іпјҲcosineеҖјжңҖеӨ§пјүзҡ„NдёӘitemдҪңдёәжҺЁиҚҗиҝ”еӣһз»ҷжӯӨз”ЁжҲ·гҖӮ
жҺҘдёӢжқҘжҲ‘们иҜҰз»Ҷд»Ӣз»ҚдёӢдёҠйқўзҡ„дёүдёӘжӯҘйӘӨгҖӮ
1) Item Representationпјҡ
зңҹе®һеә”з”Ёдёӯзҡ„itemеҫҖеҫҖйғҪдјҡжңүдёҖдәӣеҸҜд»ҘжҸҸиҝ°е®ғзҡ„еұһжҖ§гҖӮиҝҷдәӣеұһжҖ§йҖҡеёёеҸҜд»ҘеҲҶдёәдёӨз§Қпјҡз»“жһ„еҢ–зҡ„пјҲstructuredпјүеұһжҖ§дёҺйқһз»“жһ„еҢ–зҡ„пјҲunstructuredпјүеұһжҖ§гҖӮжүҖи°“з»“жһ„еҢ–зҡ„еұһжҖ§е°ұжҳҜиҝҷдёӘеұһжҖ§зҡ„ж„Ҹд№үжҜ”иҫғжҳҺзЎ®пјҢе…¶еҸ–еҖјйҷҗе®ҡеңЁжҹҗдёӘиҢғеӣҙпјӣиҖҢйқһз»“жһ„еҢ–зҡ„еұһжҖ§еҫҖеҫҖе…¶ж„Ҹд№үдёҚеӨӘжҳҺзЎ®пјҢеҸ–еҖјд№ҹжІЎд»Җд№ҲйҷҗеҲ¶пјҢдёҚеҘҪзӣҙжҺҘдҪҝз”ЁгҖӮжҜ”еҰӮеңЁдәӨеҸӢзҪ‘з«ҷдёҠпјҢitemе°ұжҳҜдәәпјҢдёҖдёӘitemдјҡжңүз»“жһ„еҢ–еұһжҖ§еҰӮиә«й«ҳгҖҒеӯҰеҺҶгҖҒзұҚиҙҜзӯүпјҢд№ҹдјҡжңүйқһз»“жһ„еҢ–еұһжҖ§пјҲеҰӮitemиҮӘе·ұеҶҷзҡ„дәӨеҸӢе®ЈиЁҖпјҢеҚҡе®ўеҶ…е®№зӯүзӯүпјүгҖӮеҜ№дәҺз»“жһ„еҢ–ж•°жҚ®пјҢжҲ‘们иҮӘ然еҸҜд»ҘжӢҝжқҘе°ұз”ЁпјӣдҪҶеҜ№дәҺйқһз»“жһ„еҢ–ж•°жҚ®пјҲеҰӮж–Үз« пјүпјҢжҲ‘们еҫҖеҫҖиҰҒе…ҲжҠҠе®ғиҪ¬еҢ–дёәз»“жһ„еҢ–ж•°жҚ®еҗҺжүҚиғҪеңЁжЁЎеһӢйҮҢеҠ д»ҘдҪҝз”ЁгҖӮзңҹе®һеңәжҷҜдёӯзў°еҲ°жңҖеӨҡзҡ„йқһз»“жһ„еҢ–ж•°жҚ®еҸҜиғҪе°ұжҳҜж–Үз« дәҶпјҲеҰӮдёӘжҖ§еҢ–йҳ…иҜ»дёӯпјүгҖӮдёӢйқўжҲ‘们е°ұиҜҰз»Ҷд»Ӣз»ҚдёӢеҰӮдҪ•жҠҠйқһз»“жһ„еҢ–зҡ„дёҖзҜҮж–Үз« з»“жһ„еҢ–гҖӮ
еҰӮдҪ•д»ЈиЎЁдёҖзҜҮж–Үз« еңЁдҝЎжҒҜжЈҖзҙўдёӯе·Із»Ҹиў«з ”з©¶дәҶеҫҲеӨҡе№ҙдәҶпјҢдёӢйқўд»Ӣз»Қзҡ„иЎЁзӨәжҠҖжңҜе…¶жқҘжәҗд№ҹжҳҜдҝЎжҒҜжЈҖзҙўпјҢе…¶еҗҚз§°дёәеҗ‘йҮҸз©әй—ҙжЁЎеһӢпјҲVector Space ModelпјҢз®Җз§°VSMпјүгҖӮ
и®°жҲ‘们иҰҒиЎЁзӨәзҡ„жүҖжңүж–Үз« йӣҶеҗҲдёә 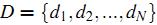 пјҢиҖҢжүҖжңүж–Үз« дёӯеҮәзҺ°зҡ„иҜҚпјҲеҜ№дәҺдёӯж–Үж–Үз« пјҢйҰ–е…Ҳеҫ—еҜ№жүҖжңүж–Үз« иҝӣиЎҢеҲҶиҜҚпјүзҡ„йӣҶеҗҲпјҲд№ҹз§°дёәиҜҚе…ёпјүдёә
пјҢиҖҢжүҖжңүж–Үз« дёӯеҮәзҺ°зҡ„иҜҚпјҲеҜ№дәҺдёӯж–Үж–Үз« пјҢйҰ–е…Ҳеҫ—еҜ№жүҖжңүж–Үз« иҝӣиЎҢеҲҶиҜҚпјүзҡ„йӣҶеҗҲпјҲд№ҹз§°дёәиҜҚе…ёпјүдёә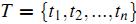 гҖӮд№ҹжҳҜиҜҙпјҢжҲ‘们жңүNзҜҮиҰҒеӨ„зҗҶзҡ„ж–Үз« пјҢиҖҢиҝҷдәӣж–Үз« йҮҢеҢ…еҗ«дәҶnдёӘдёҚеҗҢзҡ„иҜҚгҖӮжҲ‘们жңҖз»ҲиҰҒдҪҝз”ЁдёҖдёӘеҗ‘йҮҸжқҘиЎЁзӨәдёҖзҜҮж–Үз« пјҢжҜ”еҰӮ第jзҜҮж–Үз« иў«иЎЁзӨәдёә
гҖӮд№ҹжҳҜиҜҙпјҢжҲ‘们жңүNзҜҮиҰҒеӨ„зҗҶзҡ„ж–Үз« пјҢиҖҢиҝҷдәӣж–Үз« йҮҢеҢ…еҗ«дәҶnдёӘдёҚеҗҢзҡ„иҜҚгҖӮжҲ‘们жңҖз»ҲиҰҒдҪҝз”ЁдёҖдёӘеҗ‘йҮҸжқҘиЎЁзӨәдёҖзҜҮж–Үз« пјҢжҜ”еҰӮ第jзҜҮж–Үз« иў«иЎЁзӨәдёә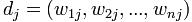 пјҢе…¶дёӯ
пјҢе…¶дёӯ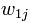 иЎЁзӨә第1дёӘиҜҚ
иЎЁзӨә第1дёӘиҜҚ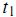 еңЁж–Үз« jдёӯзҡ„жқғйҮҚпјҢеҖји¶ҠеӨ§иЎЁзӨәи¶ҠйҮҚиҰҒпјӣ
еңЁж–Үз« jдёӯзҡ„жқғйҮҚпјҢеҖји¶ҠеӨ§иЎЁзӨәи¶ҠйҮҚиҰҒпјӣ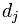 дёӯе…¶д»–еҗ‘йҮҸзҡ„и§ЈйҮҠзұ»дјјгҖӮжүҖд»ҘпјҢдёәдәҶиЎЁзӨә第jзҜҮж–Үз« пјҢзҺ°еңЁе…ій”®зҡ„е°ұжҳҜеҰӮдҪ•и®Ўз®—
дёӯе…¶д»–еҗ‘йҮҸзҡ„и§ЈйҮҠзұ»дјјгҖӮжүҖд»ҘпјҢдёәдәҶиЎЁзӨә第jзҜҮж–Үз« пјҢзҺ°еңЁе…ій”®зҡ„е°ұжҳҜеҰӮдҪ•и®Ўз®—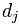 еҗ„еҲҶйҮҸзҡ„еҖјдәҶгҖӮдҫӢеҰӮпјҢжҲ‘们еҸҜд»ҘйҖүеҸ–
еҗ„еҲҶйҮҸзҡ„еҖјдәҶгҖӮдҫӢеҰӮпјҢжҲ‘们еҸҜд»ҘйҖүеҸ–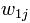 дёә1пјҢеҰӮжһңиҜҚ
дёә1пјҢеҰӮжһңиҜҚ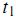 еҮәзҺ°еңЁз¬¬ j зҜҮж–Үз« дёӯпјӣйҖүеҸ–дёә0пјҢеҰӮжһң
еҮәзҺ°еңЁз¬¬ j зҜҮж–Үз« дёӯпјӣйҖүеҸ–дёә0пјҢеҰӮжһң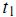 жңӘеҮәзҺ°еңЁз¬¬jзҜҮж–Үз« дёӯгҖӮжҲ‘们д№ҹеҸҜд»ҘйҖүеҸ–
жңӘеҮәзҺ°еңЁз¬¬jзҜҮж–Үз« дёӯгҖӮжҲ‘们д№ҹеҸҜд»ҘйҖүеҸ–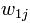 дёәиҜҚ
дёәиҜҚ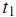 еҮәзҺ°еңЁз¬¬ j зҜҮж–Үз« дёӯзҡ„ж¬Ўж•°пјҲfrequencyпјүгҖӮдҪҶжҳҜз”Ёзҡ„жңҖеӨҡзҡ„и®Ўз®—ж–№жі•иҝҳжҳҜдҝЎжҒҜжЈҖзҙўдёӯеёёз”Ёзҡ„иҜҚйў‘-йҖҶж–ҮжЎЈйў‘зҺҮпјҲterm frequencyвҖ“inverse document frequencyпјҢз®Җз§°tf-idfпјүгҖӮ第jзҜҮж–Үз« дёӯдёҺиҜҚе…ёйҮҢ第kдёӘиҜҚеҜ№еә”зҡ„tf-idfдёәпјҡ
еҮәзҺ°еңЁз¬¬ j зҜҮж–Үз« дёӯзҡ„ж¬Ўж•°пјҲfrequencyпјүгҖӮдҪҶжҳҜз”Ёзҡ„жңҖеӨҡзҡ„и®Ўз®—ж–№жі•иҝҳжҳҜдҝЎжҒҜжЈҖзҙўдёӯеёёз”Ёзҡ„иҜҚйў‘-йҖҶж–ҮжЎЈйў‘зҺҮпјҲterm frequencyвҖ“inverse document frequencyпјҢз®Җз§°tf-idfпјүгҖӮ第jзҜҮж–Үз« дёӯдёҺиҜҚе…ёйҮҢ第kдёӘиҜҚеҜ№еә”зҡ„tf-idfдёәпјҡ
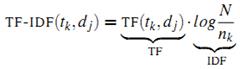
е…¶дёӯ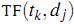 жҳҜ第kдёӘиҜҚеңЁж–Үз« jдёӯеҮәзҺ°зҡ„ж¬Ўж•°пјҢиҖҢ
жҳҜ第kдёӘиҜҚеңЁж–Үз« jдёӯеҮәзҺ°зҡ„ж¬Ўж•°пјҢиҖҢ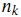 жҳҜжүҖжңүж–Үз« дёӯеҢ…жӢ¬з¬¬kдёӘиҜҚзҡ„ж–Үз« ж•°йҮҸгҖӮ
жҳҜжүҖжңүж–Үз« дёӯеҢ…жӢ¬з¬¬kдёӘиҜҚзҡ„ж–Үз« ж•°йҮҸгҖӮ
жңҖз»Ҳ第kдёӘиҜҚеңЁж–Үз« jдёӯзҡ„жқғйҮҚз”ұдёӢйқўзҡ„е…¬ејҸиҺ·еҫ—пјҡ
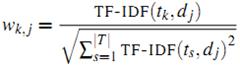
еҒҡеҪ’дёҖеҢ–зҡ„еҘҪеӨ„жҳҜдёҚеҗҢж–Үз« д№Ӣй—ҙзҡ„иЎЁзӨәеҗ‘йҮҸиў«еҪ’дёҖеҲ°дёҖдёӘйҮҸзә§дёҠпјҢдҫҝдәҺдёӢйқўжӯҘйӘӨзҡ„ж“ҚдҪңгҖӮ
2) Profile Learning
еҒҮи®ҫз”ЁжҲ·uе·Із»ҸеҜ№дёҖдәӣitemз»ҷеҮәдәҶд»–зҡ„е–ңеҘҪеҲӨж–ӯпјҢе–ңж¬ўе…¶дёӯзҡ„дёҖйғЁеҲҶitemпјҢдёҚе–ңж¬ўе…¶дёӯзҡ„еҸҰдёҖйғЁеҲҶгҖӮйӮЈд№ҲпјҢиҝҷдёҖжӯҘиҰҒеҒҡзҡ„е°ұжҳҜйҖҡиҝҮз”ЁжҲ·uиҝҮеҺ»зҡ„иҝҷдәӣе–ңеҘҪеҲӨж–ӯпјҢдёәд»–дә§з”ҹдёҖдёӘжЁЎеһӢгҖӮжңүдәҶиҝҷдёӘжЁЎеһӢпјҢжҲ‘们е°ұеҸҜд»Ҙж №жҚ®жӯӨжЁЎеһӢжқҘеҲӨж–ӯз”ЁжҲ·uжҳҜеҗҰдјҡе–ңж¬ўдёҖдёӘж–°зҡ„itemгҖӮжүҖд»ҘпјҢжҲ‘们иҰҒи§ЈеҶізҡ„жҳҜдёҖдёӘе…ёеһӢзҡ„жңүзӣ‘зқЈеҲҶзұ»й—®йўҳпјҢзҗҶи®әдёҠжңәеҷЁеӯҰд№ йҮҢзҡ„еҲҶзұ»з®—жі•йғҪеҸҜд»Ҙз…§жҗ¬иҝӣиҝҷйҮҢгҖӮ
дёӢйқўжҲ‘们з®ҖеҚ•д»Ӣз»ҚдёӢCBйҮҢеёёз”Ёзҡ„еӯҰд№ з®—жі•вҖ”вҖ”KNNпјҡ
еҜ№дәҺдёҖдёӘж–°зҡ„itemпјҢжңҖиҝ‘йӮ»ж–№жі•йҰ–е…Ҳжүҫз”ЁжҲ·uе·Із»ҸиҜ„еҲӨиҝҮ并дёҺжӯӨж–°itemжңҖзӣёдјјзҡ„kдёӘitemпјҢ然еҗҺдҫқжҚ®з”ЁжҲ·uеҜ№иҝҷkдёӘitemзҡ„е–ңеҘҪзЁӢеәҰжқҘеҲӨж–ӯе…¶еҜ№жӯӨж–°itemзҡ„е–ңеҘҪзЁӢеәҰгҖӮиҝҷз§ҚеҒҡжі•е’ҢCFдёӯзҡ„item-based kNNеҫҲзӣёдјјпјҢе·®еҲ«еңЁдәҺиҝҷйҮҢзҡ„itemзӣёдјјеәҰжҳҜж №жҚ®itemзҡ„еұһжҖ§еҗ‘йҮҸи®Ўз®—еҫ—еҲ°пјҢиҖҢCFдёӯжҳҜж №жҚ®жүҖжңүз”ЁжҲ·еҜ№itemзҡ„иҜ„еҲҶи®Ўз®—еҫ—еҲ°гҖӮ
еҜ№дәҺиҝҷдёӘж–№жі•пјҢжҜ”иҫғе…ій”®зҡ„еҸҜиғҪе°ұжҳҜеҰӮдҪ•йҖҡиҝҮitemзҡ„еұһжҖ§еҗ‘йҮҸи®Ўз®—itemд№Ӣй—ҙзҡ„дёӨдёӨзӣёдјјеәҰгҖӮ[2]дёӯе»әи®®еҜ№дәҺз»“жһ„еҢ–ж•°жҚ®пјҢзӣёдјјеәҰи®Ўз®—дҪҝ用欧еҮ йҮҢеҫ—и·қзҰ»пјӣиҖҢеҰӮжһңдҪҝз”Ёеҗ‘йҮҸз©әй—ҙжЁЎеһӢпјҲVSMпјүжқҘиЎЁзӨәitemзҡ„иҜқпјҢеҲҷзӣёдјјеәҰи®Ўз®—еҸҜд»ҘдҪҝз”ЁcosineгҖӮ
3) Recommendation Generation
йҖҡиҝҮдёҠдёҖжӯҘзҡ„еӯҰд№ пјҢдјҡеҫ—еҲ°дёҖдёӘжҺЁиҚҗеҲ—иЎЁпјҢжҲ‘们зӣҙжҺҘжҠҠиҝҷдёӘеҲ—иЎЁдёӯдёҺз”ЁжҲ·еұһжҖ§жңҖзӣёе…ізҡ„nдёӘitemдҪңдёәжҺЁиҚҗиҝ”еӣһз»ҷз”ЁжҲ·еҚіеҸҜгҖӮ
дҝ—иҜқиҜҙвҖңзү©д»Ҙзұ»иҒҡгҖҒдәәд»ҘзҫӨеҲҶвҖқпјҢ继з»ӯжӢҝзңӢз”өеҪұиҝҷдёӘдҫӢеӯҗжқҘиҜҙпјҢеҰӮжһңдҪ е–ңж¬ўгҖҠиқҷиқ дҫ гҖӢгҖҒгҖҠзўҹдёӯи°ҚгҖӢгҖҒгҖҠжҳҹйҷ…з©ҝи¶ҠгҖӢгҖҒгҖҠжәҗд»Јз ҒгҖӢзӯүз”өеҪұпјҢеҸҰеӨ–жңүдёӘдәәд№ҹйғҪе–ңж¬ўиҝҷдәӣз”өеҪұпјҢиҖҢдё”д»–иҝҳе–ңж¬ўгҖҠй’ўй“Ғдҫ гҖӢпјҢеҲҷеҫҲжңүеҸҜиғҪдҪ д№ҹе–ңж¬ўгҖҠй’ўй“Ғдҫ гҖӢиҝҷйғЁз”өеҪұгҖӮ
жүҖд»ҘиҜҙпјҢеҪ“дёҖдёӘз”ЁжҲ· A йңҖиҰҒдёӘжҖ§еҢ–жҺЁиҚҗж—¶пјҢеҸҜд»Ҙе…ҲжүҫеҲ°е’Ңд»–е…ҙи¶Јзӣёдјјзҡ„з”ЁжҲ·зҫӨдҪ“GпјҢ然еҗҺжҠҠ G е–ңж¬ўзҡ„гҖҒ并且 A жІЎжңүеҗ¬иҜҙиҝҮзҡ„зү©е“ҒжҺЁиҚҗз»ҷ AпјҢиҝҷе°ұжҳҜеҹәдәҺз”ЁжҲ·зҡ„зі»з»ҹиҝҮж»Өз®—жі•гҖӮ
ж №жҚ®дёҠиҝ°еҹәжң¬еҺҹзҗҶпјҢжҲ‘们еҸҜд»Ҙе°ҶеҹәдәҺз”ЁжҲ·зҡ„еҚҸеҗҢиҝҮж»ӨжҺЁиҚҗз®—жі•жӢҶеҲҶдёәдёӨдёӘжӯҘйӘӨпјҡ
1) еҸ‘зҺ°е…ҙи¶Јзӣёдјјзҡ„з”ЁжҲ·
йҖҡеёёз”Ё Jaccard е…¬ејҸжҲ–иҖ…дҪҷејҰзӣёдјјеәҰи®Ўз®—дёӨдёӘз”ЁжҲ·д№Ӣй—ҙзҡ„зӣёдјјеәҰгҖӮи®ҫ N(u) дёәз”ЁжҲ· u е–ңж¬ўзҡ„зү©е“ҒйӣҶеҗҲпјҢN(v) дёәз”ЁжҲ· v е–ңж¬ўзҡ„зү©е“ҒйӣҶеҗҲпјҢйӮЈд№Ҳ u е’Ң v зҡ„зӣёдјјеәҰжҳҜеӨҡе°‘е‘ўпјҡ
Jaccard е…¬ејҸпјҡ
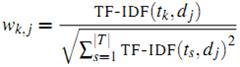
дҪҷејҰзӣёдјјеәҰпјҡ
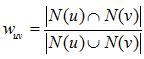
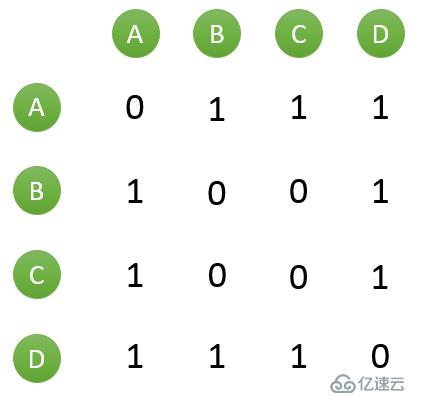
еҒҮи®ҫзӣ®еүҚе…ұжңү4дёӘз”ЁжҲ·пјҡ AгҖҒBгҖҒCгҖҒDпјӣе…ұжңү5дёӘзү©е“ҒпјҡaгҖҒbгҖҒcгҖҒdгҖҒeгҖӮз”ЁжҲ·дёҺзү©е“Ғзҡ„е…ізі»пјҲз”ЁжҲ·е–ңж¬ўзү©е“ҒпјүеҰӮдёӢеӣҫжүҖзӨәпјҡ
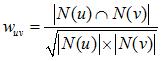
еҰӮдҪ•дёҖдёӢеӯҗи®Ўз®—жүҖжңүз”ЁжҲ·д№Ӣй—ҙзҡ„зӣёдјјеәҰе‘ўпјҹдёәи®Ўз®—ж–№дҫҝпјҢйҖҡеёёйҰ–е…ҲйңҖиҰҒе»әз«ӢвҖңзү©е“ҒвҖ”з”ЁжҲ·вҖқзҡ„еҖ’жҺ’иЎЁпјҢеҰӮдёӢеӣҫжүҖзӨәпјҡ

然еҗҺеҜ№дәҺжҜҸдёӘзү©е“ҒпјҢе–ңж¬ўд»–зҡ„з”ЁжҲ·пјҢдёӨдёӨд№Ӣй—ҙзӣёеҗҢзү©е“ҒеҠ 1гҖӮдҫӢеҰӮе–ңж¬ўзү©е“Ғ a зҡ„з”ЁжҲ·жңү A е’Ң BпјҢйӮЈд№ҲеңЁзҹ©йҳөдёӯ他们дёӨдёӨеҠ 1гҖӮеҰӮдёӢеӣҫжүҖзӨәпјҡ

и®Ўз®—з”ЁжҲ·дёӨдёӨд№Ӣй—ҙзҡ„зӣёдјјеәҰпјҢдёҠйқўзҡ„зҹ©йҳөд»…д»…д»ЈиЎЁзҡ„жҳҜе…¬ејҸзҡ„еҲҶеӯҗйғЁеҲҶгҖӮд»ҘдҪҷејҰзӣёдјјеәҰдёәдҫӢпјҢеҜ№дёҠеӣҫиҝӣиЎҢиҝӣдёҖжӯҘи®Ўз®—пјҡ
еҲ°жӯӨпјҢи®Ўз®—з”ЁжҲ·зӣёдјјеәҰе°ұеӨ§еҠҹе‘ҠжҲҗпјҢеҸҜд»ҘеҫҲзӣҙи§Ӯзҡ„жүҫеҲ°дёҺзӣ®ж Үз”ЁжҲ·е…ҙи¶Јиҫғзӣёдјјзҡ„з”ЁжҲ·гҖӮ
2) жҺЁиҚҗзү©е“Ғ
йҰ–е…ҲйңҖиҰҒд»Һзҹ©йҳөдёӯжүҫеҮәдёҺзӣ®ж Үз”ЁжҲ· u жңҖзӣёдјјзҡ„ K дёӘз”ЁжҲ·пјҢз”ЁйӣҶеҗҲ S(u, K) иЎЁзӨәпјҢе°Ҷ S дёӯз”ЁжҲ·е–ңж¬ўзҡ„зү©е“Ғе…ЁйғЁжҸҗеҸ–еҮәжқҘпјҢ并еҺ»йҷӨ u е·Із»Ҹе–ңж¬ўзҡ„зү©е“ҒгҖӮеҜ№дәҺжҜҸдёӘеҖҷйҖүзү©е“Ғ i пјҢз”ЁжҲ· u еҜ№е®ғж„ҹе…ҙи¶Јзҡ„зЁӢеәҰз”ЁеҰӮдёӢе…¬ејҸи®Ўз®—пјҡ
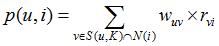
е…¶дёӯ rvi иЎЁзӨәз”ЁжҲ· v еҜ№ i зҡ„е–ңж¬ўзЁӢеәҰпјҢеңЁжң¬дҫӢдёӯйғҪжҳҜдёә 1пјҢеңЁдёҖдәӣйңҖиҰҒз”ЁжҲ·з»ҷдәҲиҜ„еҲҶзҡ„жҺЁиҚҗзі»з»ҹдёӯпјҢеҲҷиҰҒд»Је…Ҙз”ЁжҲ·иҜ„еҲҶгҖӮ
дёҫдёӘдҫӢеӯҗпјҢеҒҮи®ҫжҲ‘们иҰҒз»ҷ A жҺЁиҚҗзү©е“ҒпјҢйҖүеҸ– K = 3 дёӘзӣёдјјз”ЁжҲ·пјҢзӣёдјјз”ЁжҲ·еҲҷжҳҜпјҡBгҖҒCгҖҒDпјҢйӮЈд№Ҳ他们е–ңж¬ўиҝҮ并且 A жІЎжңүе–ңж¬ўиҝҮзҡ„зү©е“ҒжңүпјҡcгҖҒeпјҢйӮЈд№ҲеҲҶеҲ«и®Ўз®— p(A, c) е’Ң p(A, e)пјҡ
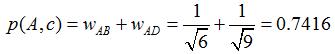
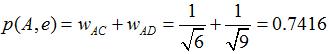
зңӢж ·еӯҗз”ЁжҲ· A еҜ№ c е’Ң e зҡ„е–ңж¬ўзЁӢеәҰеҸҜиғҪжҳҜдёҖж ·зҡ„пјҢеңЁзңҹе®һзҡ„жҺЁиҚҗзі»з»ҹдёӯпјҢеҸӘиҰҒжҢүеҫ—еҲҶжҺ’еәҸпјҢеҸ–еүҚеҮ дёӘзү©е“Ғе°ұеҸҜд»ҘдәҶгҖӮ
еҰӮдҪ•з”Ё4дёӘжңҲеӯҰдјҡHadoopејҖеҸ‘并жүҫеҲ°е№ҙи–Ә25дёҮе·ҘдҪңпјҹ
е…Қиҙ№еҲҶдә«дёҖеҘ—17е№ҙжңҖж–°HadoopеӨ§ж•°жҚ®ж•ҷзЁӢе’Ң100йҒ“HadoopеӨ§ж•°жҚ®еҝ…дјҡйқўиҜ•йўҳгҖӮ
еӣ дёәй“ҫжҺҘз»Ҹеёёиў«е’Ңи°җпјҢйңҖиҰҒзҡ„жңӢеҸӢиҜ·еҠ еҫ®дҝЎ ganshiyun666 жқҘиҺ·еҸ–жңҖж–°дёӢиҪҪй“ҫжҺҘпјҢжіЁжҳҺвҖң51CTOвҖқ
ж•ҷзЁӢе·Іеё®еҠ©300+дәәжҲҗеҠҹиҪ¬еһӢHadoopејҖеҸ‘пјҢ90%иө·и–Әи¶…иҝҮ20KпјҢе·Ҙиө„жҜ”д№ӢеүҚзҝ»дәҶдёҖеҖҚгҖӮ
зҷҫеәҰHadoopж ёеҝғжһ¶жһ„еёҲдәІиҮӘеҪ•еҲ¶
еҶ…е®№еҢ…жӢ¬0еҹәзЎҖе…Ҙй—ЁгҖҒHadoopз”ҹжҖҒзі»з»ҹгҖҒзңҹе®һе•ҶдёҡйЎ№зӣ®е®һжҲҳ3еӨ§йғЁеҲҶгҖӮе…¶дёӯе•ҶдёҡжЎҲдҫӢеҸҜд»Ҙи®©дҪ жҺҘи§Ұзңҹе®һзҡ„з”ҹдә§зҺҜеўғпјҢи®ӯз»ғиҮӘе·ұзҡ„ејҖеҸ‘иғҪеҠӣгҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ