您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
本篇文章给大家分享的是有关Python中pytorch模型选择及欠拟合和过拟合的示例分析,小编觉得挺实用的,因此分享给大家学习,希望大家阅读完这篇文章后可以有所收获,话不多说,跟着小编一起来看看吧。
训练误差是指,我们的模型在训练数据集上计算得到的误差。
泛化误差是指,我们将模型应用在同样从原始样本的分布中抽取的无限多的数据样本时,我们模型误差的期望。
在实际中,我们只能通过将模型应用于一个独立的测试集来估计泛化误差,该测试集由随机选取的、未曾在训练集中出现的数据样本构成。
在本节中将重点介绍几个倾向于影响模型泛化的因素:
可调整参数的数量。当可调整参数的数量(有时称为自由度)很大时,模型往往更容易过拟合。参数采用的值。当权重的取值范围较大时,模型可能更容易过拟合。训练样本的数量。即使模型非常简单,也很容易过拟合只包含一两个样本的数据集。而过拟合一个有数百万个样本的数据集则需要一个极其灵活的模型。 模型选择
在机器学习中,我们通常在评估几个候选模型后选择最终的模型。这个过程叫做模型的选择。有时,需要进行比较的模型在本质上是完全不同的(比如,决策树与线性模型)。又有时,我们需要比较不同的超参数设置下的同一类模型。
例如,训练多层感知机模型时,我们可能希望比较具有不同数量的隐藏层、不同数量的隐藏单元以及不同的激活函数组合的模型。为了确定候选模型的最佳模型,我们通常会使用验证集。
原则上,在我们确定所有的超参数之前,我们不应该用到测试集。如果我们在模型选择过程中使用了测试数据,可能会有过拟合测试数据的风险。
如果我们过拟合了训练数据,还有在测试数据上的评估来判断过拟合。
但是如果我们过拟合了测试数据,我们又应该怎么知道呢?
我们不能依靠测试数据进行模型选择。也不能仅仅依靠训练数据来选择模型,因为我们无法估计训练数据的泛化误差。
解决此问题的常见做法是将我们的数据分成三份,除了训练和测试数据集之外,还增加一个验证数据集(validation dataset),也叫验证集(validation set)。
但现实是,验证数据和测试数据之间的界限非常模糊。在之后实际上是使用应该被正确地称为训练数据和验证数据的东西,并没有真正的测试数据集。因此,之后的准确度都是验证集准确度,而不是测试集准确度。
当训练数据稀缺时,我们甚至可能无法提供足够的数据来构成一个合适的验证集。这个问题的一个流行的解决方案是采用 K K K折交叉验证。这里,原始训练数据被分成 K个不重叠的子集。然后执行K次模型训练和验证,每次在K−1个子集上进行训练,并在剩余的一个子集(在该轮中没有用于训练的子集)上进行验证。最后,通过K次实验的结果取平均来估计训练和验证误差。
当我们比较训练和验证误差时,我们要注意两种常见的情况。
首先,我们要注意这样的情况:训练误差和验证误差都很严重,但它们之间仅有一点差距。如果模型不能降低训练误差,这可能意味着我们的模型过于简单(即表达能力不足),无法捕获我们试图学习的模式。此外,由于我们的训练和验证误差之间的泛化误差很小,我们有理由相信可以用一个更复杂的模型降低训练误差。这种现象被称为欠拟合。
另一方面,当我们的训练误差明显低于验证误差时要小心,这表明严重的过拟合。注意,过拟合并不总是一件坏事。
我们是否过拟合或欠拟合可能取决于模型的复杂性和可用数据集的大小,这两个点将在下面进行讨论。

告诫多项式函数比低阶多项式函数复杂得多。高阶多项式的参数较多,模型函数的选择范围较广。因此在固定训练数据集的情况下,高阶多项式函数相对于低阶多项式的训练误差应该始终更低(最坏也是相等)。事实上,当数据样本包含了 x的不同取值时,函数阶数等于数据样本数量的多项式函数可以完美拟合训练集。在下图中,我们直观地描述了多项式的阶数和欠拟合与过拟合之间的关系。
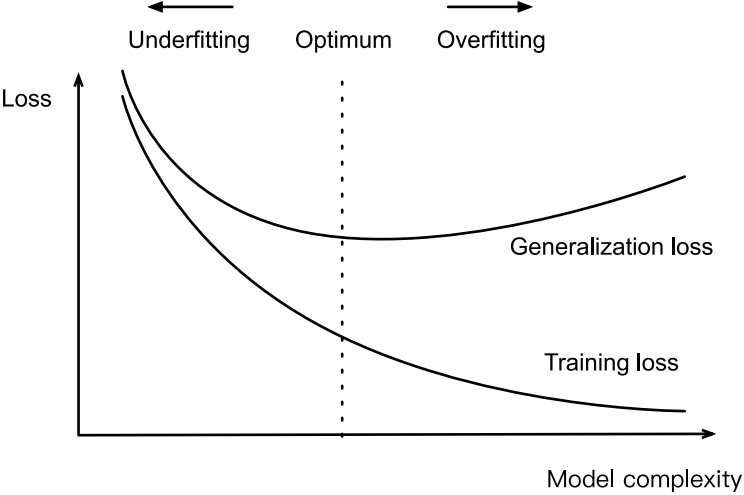
训练数据集中的样本越少,我们就越可能(且更严重地)遇到过拟合。随着训练数据量的增加,泛化误差通常会减小。此外,一般来说,更多的数据不会有什么坏处。
以上就是Python中pytorch模型选择及欠拟合和过拟合的示例分析,小编相信有部分知识点可能是我们日常工作会见到或用到的。希望你能通过这篇文章学到更多知识。更多详情敬请关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。