您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
Spark是近年来发展较快的分布式并行数据处理框架,了解和掌握spark对于学习大数据有着至关重要的意义。但是spark依赖于函数单元,它的函数编程过程是怎样的呢?我们怎么来应用呢?
一、Spark的函数式编程
Spark依赖于函数单元,函数是其编程的基本单元,只有输入输出,没有state和side effect。它的关键概念就是把函数作为其他函数的输入,不过在使用函数的过程中 使用的都是匿名函数,因为这个函数只是满足当下计算,因此不需要固化下来进行其它应用。
把函数作为参数传递
很多RDD操作把函数作为参数传递,这里我们看一下RDD map操作伪代码,把函数fn应用到RDD的每条记录。但这并不是它执行的一个真正的代码,只是通过这个代码去看一下它处理的逻辑。

示例:传递命名的函数
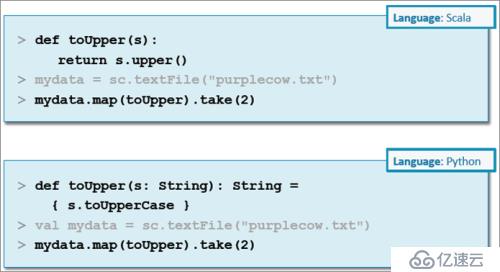
匿名函数
匿名函数是没有标识符的嵌入式定义的函数,最适合于临时一次性的函数。在很多编程语言中支持,比如:
(1)Python:lambda x
(2)Scala:x =>
(3)Java 8:x ->
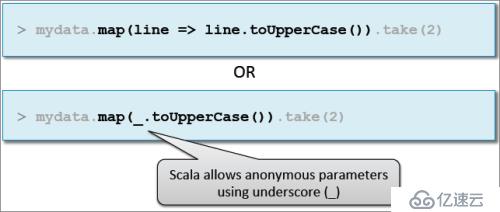
示例:传递匿名函数
(1)Python

(2)Scala
示例:Java
(1)Python

(2)Scala

Spark作为当下大数据中重要的子目,必须深度掌握学习。但是大数据还在起步发展,并没有形成完整成熟的理论系统,需要我们多方位,多渠道的挖掘学习。这里推荐“大数据cn”微信公众平台,里面介绍了很多大数据的相关知识,很不错的!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。