您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
Hive中的分区就是分目录,把一个大的数据集根据业务需要分割成更小的数据集。那么在Hive中如何进行数据分区呢?分区时应该注意什么样的问题呢?它的分区数如何进行限制呢?
一、Hive only:加载分区数据的快捷方法
如果指定的分区不存在Hive将创建新的分区

这个命令将:
(1)如果不存在的话添加分区到表的元数据;
(2)如果存在的话,创建子目录:/user/hive/warehouse/call_logs/call_date=2014-10-02
(3)移动HDFS文件call-20141002.log到分区子目录
二、查看、添加和移除分区
(1)查看当前表分区

(2)使用ALTER TABLE添加或删除分区
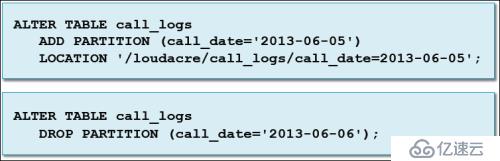
从已存在的分区目录创建分区
(1)HDFS的分区目录可以在Hive或Impala之外进行创建和数据,比如:通过Spark或MapReduce应用
(2) Hive中使用MSCK REPAIR TABLE命令来为已存在的表创建分区

四、什么时候使用分区
下列情况使用分区
(1)读取整个数据集需要花费很长时间
(2)查询几乎只对分区字段进行过滤
(3)分区列有合理数量的不同的值
(4)数据生成或ETL过程是按文件或目录名来分段数据的
(5)分区列值不在数据本身
五、什么时候不使用分区
(1)避免把数据分区到很多小数据文件
–不要对有太多惟一值的列进行分区
(2)注意:当使用动态分区时容易发生
–比如:按照fname来分区客户表会产生上千个分区
Hive进行分区
在旧的Hive版本中,动态分区默认没有启用 ,通过设置这两个属性启用:

但是在hive分区中我们应该注意一些问题,比如:
(1)注意:Beeline设置的Hive变量只在当前会话有效,系统管理员可以设置永久生效
(2)注意:如果分区列有很多唯一值,将会创建很多分区
另外,我们可以给Hive配置参数来限制分区数 :
(1)hive.exec.max.dynamic.partitions.pernode
查询在某个节点上可以创建的最大动态分区数,默认100
(2)hive.exec.max.dynamic.partitions
一个HiveQL语句可以创建的最大动态分区数 ,默认1000
(3)hive.exec.max.created.files
一个查询总共可以创建的最大动态分区数,默认1000000
以上就是对Hive中进行数据分区做的分享。平时要多去掌握和了解,它对于大数据学习有着至关重要的作用。这里推荐“大数据cn”微信订阅号,对于大数据的一些介绍还不错,可以关注一下。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。