жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚдәҶеҰӮдҪ•дҪҝз”ЁPythonжӯЈеҲҷиЎЁиҫҫејҸпјҢе…·жңүдёҖе®ҡеҖҹйүҙд»·еҖјпјҢж„ҹе…ҙи¶Јзҡ„жңӢеҸӢеҸҜд»ҘеҸӮиҖғдёӢпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« д№ӢеҗҺеӨ§жңү收иҺ·пјҢдёӢйқўи®©е°Ҹзј–еёҰзқҖеӨ§е®¶дёҖиө·дәҶи§ЈдёҖдёӢгҖӮ
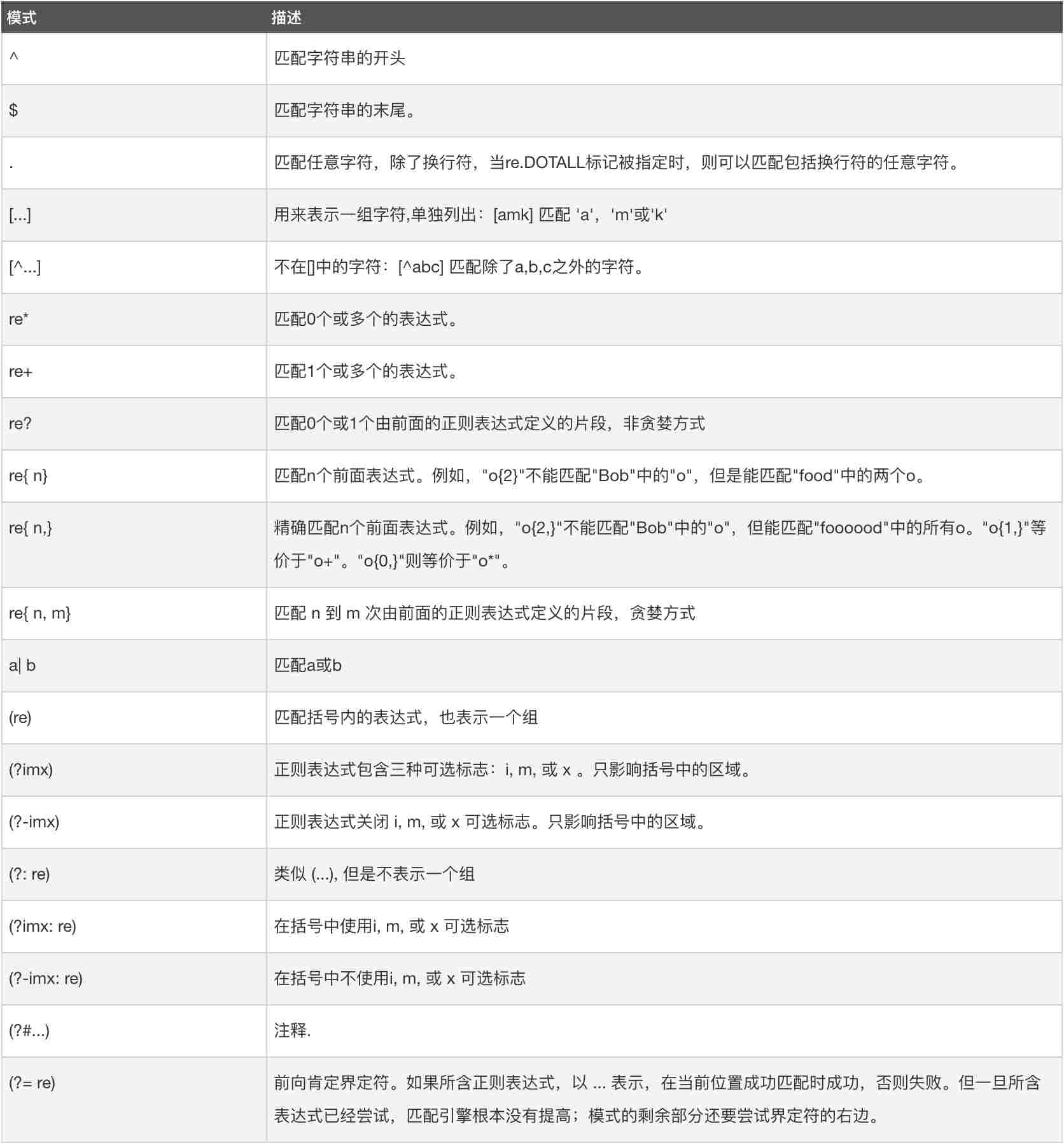
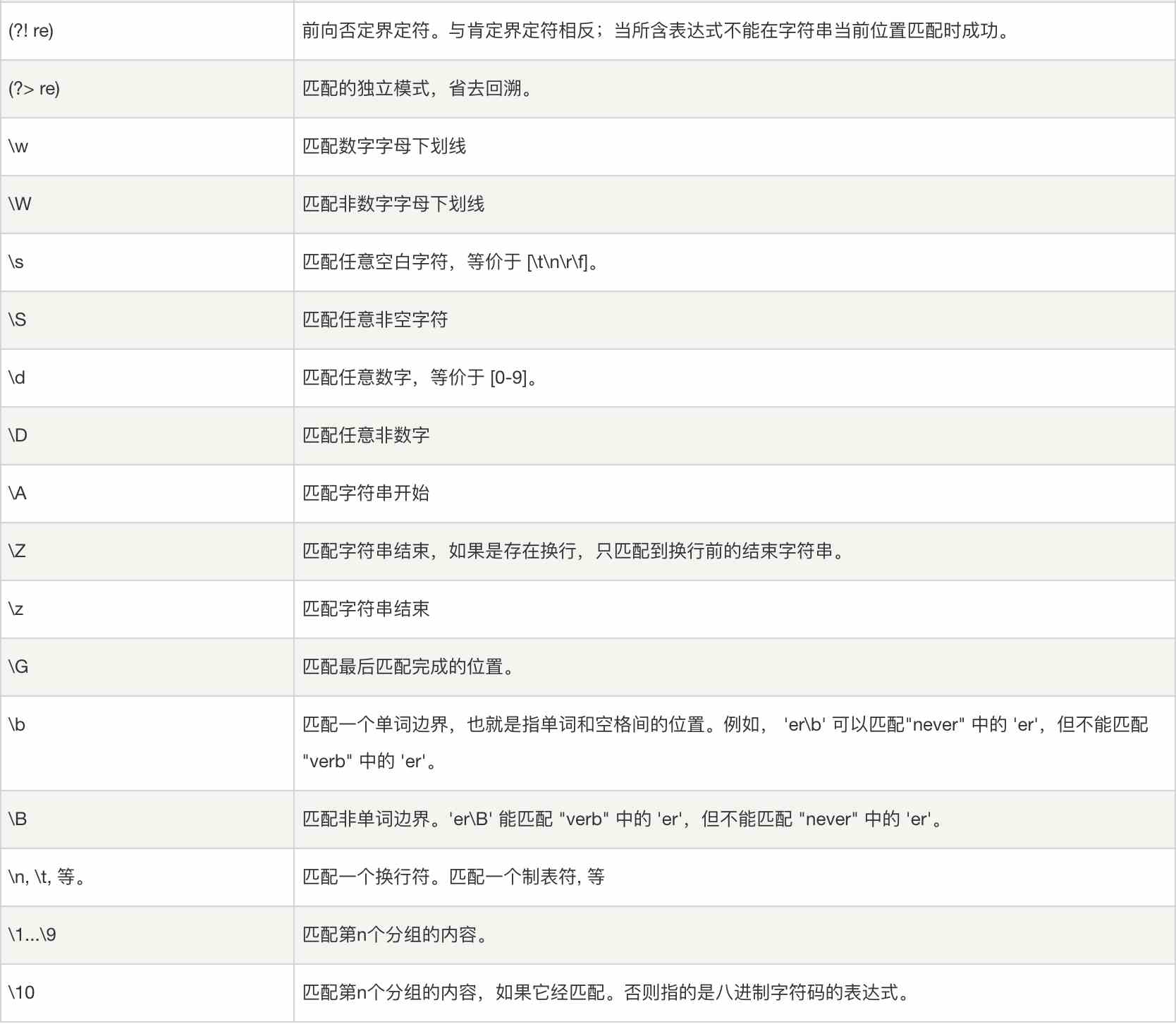
жӯЈеҲҷиЎЁиҫҫејҸжҳҜдёҖдёӘзү№ж®Ҡзҡ„еӯ—з¬ҰеәҸеҲ—пјҢе®ғиғҪеё®еҠ©дҪ ж–№дҫҝзҡ„жЈҖжҹҘдёҖдёӘеӯ—з¬ҰдёІжҳҜеҗҰдёҺжҹҗз§ҚжЁЎејҸеҢ№й…ҚгҖӮжң¬ж–Үдё»иҰҒйҳҗиҝ°reеҢ…дёӯзҡ„дё»иҰҒеҮҪж•°гҖӮ
еңЁйҳҗиҝ°reеҢ…дёӯзҡ„еҮҪж•°д№ӢеүҚпјҢжҲ‘们йҰ–е…ҲзңӢи®®жЎҲжӯЈеҲҷиЎЁиҫҫејҸзҡ„жЁЎејҸпјҢеҚідҪҝз”Ёзү№ж®Ҡзҡ„иҜӯжі•жқҘиЎЁзӨәдёҖдёӘжӯЈеҲҷиЎЁиҫҫејҸгҖӮ
re.match е°қиҜ•д»Һеӯ—з¬ҰдёІзҡ„иө·е§ӢдҪҚзҪ®еҢ№й…ҚдёҖдёӘжЁЎејҸпјҢеҰӮжһңдёҚжҳҜиө·е§ӢдҪҚзҪ®еҢ№й…ҚжҲҗеҠҹзҡ„иҜқпјҢmatch()е°ұиҝ”еӣһnoneгҖӮ
еҮҪж•°з”Ёжі•пјҡre.match(pattern, string, flags=0)
pattern: жүҖиҰҒеҢ№й…Қзҡ„жӯЈеҲҷиЎЁиҫҫејҸstring: иҰҒеҢ№й…Қзҡ„еӯ—з¬ҰдёІflags: ж Үеҝ—дҪҚпјҢз”ЁдәҺжҺ§еҲ¶жӯЈеҲҷиЎЁиҫҫејҸзҡ„еҢ№й…Қж–№ејҸпјҢеҰӮпјҡжҳҜеҗҰеҢәеҲҶеӨ§е°ҸеҶҷпјҢеӨҡиЎҢеҢ№й…ҚзӯүзӯүгҖӮ
re.I еҝҪз•ҘеӨ§е°ҸеҶҷ
re.L иЎЁзӨәзү№ж®Ҡеӯ—з¬ҰйӣҶ \w, \W, \b, \B, \s, \S дҫқиө–дәҺеҪ“еүҚзҺҜеўғ
re.M еӨҡиЎҢжЁЎејҸre.S еҚідёә' . вҖҳ并且еҢ…жӢ¬жҚўиЎҢз¬ҰеңЁеҶ…зҡ„д»»ж„Ҹеӯ—з¬ҰпјҲ' . 'дёҚеҢ…жӢ¬жҚўиЎҢз¬Ұпјү
re.U иЎЁзӨәзү№ж®Ҡеӯ—з¬ҰйӣҶ \w, \W, \b, \B, \d, \D, \s, \S дҫқиө–дәҺ Unicode еӯ—з¬ҰеұһжҖ§ж•°жҚ®еә“
re.X дёәдәҶеўһеҠ еҸҜиҜ»жҖ§пјҢеҝҪз•Ҙз©әж је’Ң' # 'еҗҺйқўзҡ„жіЁйҮҠ
еҢ№й…ҚеҜ№иұЎж–№жі•пјҡ
group(num=0): еҢ№й…Қзҡ„ж•ҙдёӘиЎЁиҫҫејҸзҡ„еӯ—з¬ҰдёІпјҢgroup() еҸҜд»ҘдёҖж¬Ўиҫ“е…ҘеӨҡдёӘз»„еҸ·пјҢеңЁиҝҷз§Қжғ…еҶөдёӢе®ғе°Ҷиҝ”еӣһдёҖдёӘеҢ…еҗ«йӮЈдәӣз»„жүҖеҜ№еә”еҖјзҡ„е…ғз»„гҖӮ
groups(): иҝ”еӣһдёҖдёӘеҢ…еҗ«жүҖжңүе°Ҹз»„еӯ—з¬ҰдёІзҡ„е…ғз»„пјҢд»Һ 1 еҲ° жүҖеҗ«зҡ„е°Ҹз»„еҸ·гҖӮ
import re
print(re.match("xixi", "xixi_haha_heihei").group())xixi
line = 'Cats are smarter than dogs' b = re.match(r'(.*) are (.*?) .*', line, re.M|re.I) print(b.group()) # иҝ”еӣһжүҖжңү print(b.group(1)) # иҝ”еӣһ第дёҖз»„пјҢеҚі(.*)еҜ№еә”зҡ„ print(b.group(2)) # иҝ”еӣһ第дәҢз»„пјҢеҚі(.*?)еҜ№еә”зҡ„
Cats are smarter than dogs Cats smarter
re.search жү«жҸҸж•ҙдёӘеӯ—з¬Ұ串并иҝ”еӣһ第дёҖдёӘжҲҗеҠҹзҡ„еҢ№й…ҚгҖӮ
еҮҪж•°з”Ёжі•пјҡre.search(pattern, string, flags=0)
print(re.match('heihei', 'xixi_haha_heihei'))
print(re.search('heihei', 'xixi_haha_heihei').group())None heihei
line = 'Cats are smarter than dogs' b = re.search(r'(.*) are (.*?) .*', line, re.M|re.I) print(b.group()) # иҝ”еӣһжүҖжңү print(b.group(1)) # иҝ”еӣһ第дёҖз»„пјҢеҚі(.*)еҜ№еә”зҡ„ print(b.group(2)) # иҝ”еӣһ第дәҢз»„пјҢеҚі(.*?)еҜ№еә”зҡ„
Cats are smarter than dogs Cats smarter
matchеҸӘеҢ№й…Қеӯ—з¬ҰдёІзҡ„ејҖе§ӢпјҢеҰӮжһңеӯ—з¬ҰдёІејҖе§ӢдёҚз¬ҰеҗҲжӯЈеҲҷиЎЁиҫҫејҸпјҢеҲҷеҢ№й…ҚеӨұиҙҘпјҢеҮҪж•°иҝ”еӣһNoneпјӣиҖҢsearchеҢ№й…Қж•ҙдёӘеӯ—з¬ҰдёІпјҢзӣҙеҲ°жүҫеҲ°дёҖдёӘеҢ№й…ҚгҖӮ
reжҸҗдҫӣдәҶre.subжқҘжӣҝжҚўеӯ—з¬ҰдёІдёӯзҡ„еҢ№й…ҚйЎ№гҖӮ
еҮҪж•°з”Ёжі•пјҡre.sub(pattern, repl, string, count=0, flags=0)
pattern : жӯЈеҲҷдёӯзҡ„жЁЎејҸеӯ—з¬ҰдёІгҖӮ
repl : жӣҝжҚўзҡ„еӯ—з¬ҰдёІпјҢд№ҹеҸҜдёәдёҖдёӘеҮҪж•°гҖӮ
string : иҰҒиў«жҹҘжүҫжӣҝжҚўзҡ„еҺҹе§Ӣеӯ—з¬ҰдёІгҖӮ
count : жЁЎејҸеҢ№й…ҚеҗҺжӣҝжҚўзҡ„жңҖеӨ§ж¬Ўж•°пјҢй»ҳи®Ө 0 иЎЁзӨәжӣҝжҚўжүҖжңүзҡ„еҢ№й…ҚгҖӮ
flags : зј–иҜ‘ж—¶з”Ёзҡ„еҢ№й…ҚжЁЎејҸпјҢж•°еӯ—еҪўејҸгҖӮ
phone = '133-3333-3333 # this is a phone number'
num = re.sub(r'#.*$', '', phone)
print('phone num', num)
# 移йҷӨжіЁйҮҠпјҢжүҫеҲ°д»Ҙ#ејҖеӨҙзҡ„гҖӮ
num = re.sub(r'\D', '', phone)
print('phone num', num)
# 移йҷӨйқһж•°еӯ—еҶ…е®№phone num 133-3333-3333 phone num 13333333333
replжҳҜеҮҪж•°зҡ„жғ…еҶө
def double(matched):
value = int(matched.group('value'))
return str(value * 2)
s = 'A233Sfd34'
print(re.sub('(?P<value>\d+)', double, s))A466Sfd68
compile еҮҪж•°з”ЁдәҺзј–иҜ‘жӯЈеҲҷиЎЁиҫҫејҸпјҢз”ҹжҲҗдёҖдёӘжӯЈеҲҷиЎЁиҫҫејҸпјҲ Pattern пјүеҜ№иұЎпјҢдҫӣ match() е’Ң search() иҝҷдёӨдёӘеҮҪж•°дҪҝз”ЁгҖӮ
еҮҪж•°дҪҝз”Ёпјҡre.compile(pattern, flags)
pattern = re.compile(r'/d+')
m = pattern.match('ones123412')
print(m)None
еңЁеӯ—з¬ҰдёІдёӯжүҫеҲ°жӯЈеҲҷиЎЁиҫҫејҸжүҖеҢ№й…Қзҡ„жүҖжңүеӯҗдёІпјҢ并иҝ”еӣһдёҖдёӘеҲ—иЎЁпјҢеҰӮжһңжІЎжңүжүҫеҲ°еҢ№й…Қзҡ„пјҢеҲҷиҝ”еӣһз©әеҲ—иЎЁгҖӮ
жіЁж„Ҹпјҡmatchе’ҢsearchжҳҜеҢ№й…ҚдёҖж¬ЎпјҢдҪҶжҳҜfindallжҳҜеҢ№й…ҚжүҖжңүгҖӮ
еҮҪж•°дҪҝз”Ёпјҡfindall(string, pos, endpos)
string еҫ…еҢ№й…Қзҡ„еӯ—з¬ҰдёІгҖӮ
pos еҸҜйҖүеҸӮж•°пјҢжҢҮе®ҡеӯ—з¬ҰдёІзҡ„иө·е§ӢдҪҚзҪ®пјҢй»ҳи®Өдёә 0гҖӮ
endpos еҸҜйҖүеҸӮж•°пјҢжҢҮе®ҡеӯ—з¬ҰдёІзҡ„з»“жқҹдҪҚзҪ®пјҢй»ҳи®Өдёәеӯ—з¬ҰдёІзҡ„й•ҝеәҰгҖӮ
pattern = re.compile(r'\d+')
result1 = pattern.findall('xixixix 123 heihiehei 456')
result2 = pattern.findall('xixixix 123 heihiehei 456', 0, 15)
print(result1)
print(result2)['123', '456'] ['123']
е’Ң findall зұ»дјјпјҢеңЁеӯ—з¬ҰдёІдёӯжүҫеҲ°жӯЈеҲҷиЎЁиҫҫејҸжүҖеҢ№й…Қзҡ„жүҖжңүеӯҗдёІпјҢ并жҠҠе®ғ们дҪңдёәдёҖдёӘиҝӯд»ЈеҷЁиҝ”еӣһгҖӮ
ittt = re.finditer(r'\d+', '12dsfasdf123asdf534') for ttt in ittt: print(ttt.group())
12 123 534
split ж–№жі•жҢүз…§иғҪеӨҹеҢ№й…Қзҡ„еӯҗдёІе°Ҷеӯ—з¬ҰдёІеҲҶеүІеҗҺиҝ”еӣһеҲ—иЎЁгҖӮ
еҮҪж•°дҪҝз”Ёпјҡ
re.split(pattern, string, maxsplit=0, flags=0)
patternпјҡ еҢ№й…Қзҡ„жӯЈеҲҷиЎЁиҫҫејҸ
stringпјҡ иҰҒеҢ№й…Қзҡ„еӯ—з¬ҰдёІгҖӮ
maxsplitпјҡ еҲҶйҡ”ж¬Ўж•°пјҢmaxsplit=1 еҲҶйҡ”дёҖж¬ЎпјҢй»ҳи®Өдёә 0пјҢдёҚйҷҗеҲ¶ж¬Ўж•°гҖӮ
flagsпјҡ ж Үеҝ—дҪҚпјҢз”ЁдәҺжҺ§еҲ¶жӯЈеҲҷиЎЁиҫҫејҸзҡ„еҢ№й…Қж–№ејҸпјҢ
print(re.split('\W+', 'xxixix, xixixi, hehiehei'))
print(re.split('(\W+)', ' xxixix, xixixi, hehiehei'))['xxixix', 'xixixi', 'hehiehei'] ['', ' ', 'xxixix', ', ', 'xixixi', ', ', 'hehiehei']
ж„ҹи°ўдҪ иғҪеӨҹи®Өзңҹйҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« пјҢеёҢжңӣе°Ҹзј–еҲҶдә«зҡ„вҖңеҰӮдҪ•дҪҝз”ЁPythonжӯЈеҲҷиЎЁиҫҫејҸвҖқиҝҷзҜҮж–Үз« еҜ№еӨ§е®¶жңүеё®еҠ©пјҢеҗҢж—¶д№ҹеёҢжңӣеӨ§е®¶еӨҡеӨҡж”ҜжҢҒдәҝйҖҹдә‘пјҢе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢжӣҙеӨҡзӣёе…ізҹҘиҜҶзӯүзқҖдҪ жқҘеӯҰд№ !
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ