您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
虚拟机使用的oracle vm,安装的操作系统是centOs7
本地模式
1.安装JDK
Hadoop是要安装在JVM上运行的,所以都要安装JDK。所以必须安装JVM。
1.1 下载JDK
下载网址:
http://www.oracle.com/technetwork/cn/java/javase/downloads/jdk8-downloads-2133151-zhs.html
选择linux 64位系统,压缩后缀是tar.gz

1.2 解压
将下载的tar包拷贝到/home/hadoop/Downloads文件夹里,进入Downloads文件夹,再直接使用命令:
tar –zxvf jdk-8u111-linux-x64.gz
解压到当前文件夹里,然后使用命令将jdk文件夹剪切到/software/目录下,当然得先创建/software/目录,同时使用如下命令创建jdk软连接:
ln–s jdk1.8.0_111 jdk
1.3 配置JDK,JRE环境变量
使用vim命令修改配置文件/etc/profile
在文件尾添加:
export JAVA_HOME=/software/jdk
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
再用soure /etc/profile命令,使其生效:
1.4 验证
输入:java -version
能显示如下信息,就表示JDK配置成功。
[hadoop@s200 software]$ java -version
java version "1.8.0_111"
Java(TM) SE Runtime Environment (build1.8.0_111-b14)
Java HotSpot(TM) 64-Bit Server VM (build25.111-b14, mixed mode)
[hadoop@s200 software]$
2.安装Hadoop
这里安装本地模式
2.1下载
下载地址:
http://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/
我下载的2.7.2版本,点击hadoop-2.72/链接进入下载页面。
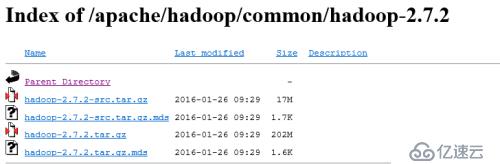
下载tar包和src源码包(源码包供开发调试使用)。
2.2解压
将hadoop-2.7.2.tar.gz包拷贝到与jdk相同的目录/home/hadoop/Downloads下。然后使用
tar –zxvf hadoop-2.7.2.tar.gz
解压后得到hadoop-2.7.2文件夹。然后使用命令:
mv hadoop-2.7.2 /software/
将hadoop目录剪切到/software/目录下
然后使用命令:
ln–s hadoop-2.7.2 hadoop创建软连接。
2.3配置Hadoop环境变量
使用vim命令修改配置文件/etc/profile
在文件尾添加:
export HADOOP_HOME=/software/hadoop
exportPATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
再用soure /etc/profile命令,使其生效。
2.4 验证
使用hadoop version得到如下版本号信息,则表示安装成功。
[hadoop@s200 software]$ hadoop version
Hadoop 2.7.2
Subversionhttps://git-wip-us.apache.org/repos/asf/hadoop.git -rb165c4fe8a74265c792ce23f546c64604acf0e41
Compiled by jenkins on 2016-01-26T00:08Z
Compiled with protoc 2.5.0
From source with checksumd0fda26633fa762bff87ec759ebe689c
This command was run using/software/hadoop-2.7.2/share/hadoop/common/hadoop-common-2.7.2.jar
[hadoop@s200 software]$
伪分布模式
1、安装SSH
1.1、安装SSH,在命令行输入如下:
sudo apt-get install openssh-server
1.2配置可以免密码登陆本机
在命令行输入(注意其中的ssh前面还有一个 “ . ” 不要遗漏)
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
(解释一下上面这条命令, ssh-keygen 代表生成密钥; -t 表示指定生成的密钥 类型; rsa 是 rsa 密钥认证的意思; -P 用于提供密语(接着后面是两个单引号, 不要打错); -f 表示指定生成密钥文件)
这条命令完成后,会在当前文件夹下面的 .ssh 文件夹下创建 id_rsa 和 id_rsa.pub两个文件,这是 SSH 的一对私钥和公钥,把 id_rsa.pub (公钥)追加到授权的 key中去,输入如下命令:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
至此,免密码登陆本机已经配置完毕。
说明:一般来说,安装SSH时会自动在当前用户下创建.ssh这个隐藏文件夹,一般不会直接看到,除非安装好了以后,在命令行使用命令ls -al才会看到。
1.3、 输入 ssh localhost ,显示登陆成功信息。
[hadoop@s200 hadoop]$ ssh localhost
Last login: Mon Nov 21 21:53:49 2016
[hadoop@s200 ~]$
2、 在本地模式的基础上需要添加下面的操作。
3、 修改etc/hadoop/hadoop-env.sh如下配置项
export JAVA_HOME=/software/jdk
4、配置etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
5、配置etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
6、配置etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
7、配置etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
8、使用hdfs namenode –format命令格式化文件系统
[hadoop@s200 hadoop]$ hdfs namenode -format
16/11/21 22:52:03 INFO namenode.NameNode:STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = s200/192.168.1.200
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.7.2
STARTUP_MSG: classpath =/software/hadoop-2.7.2/etc/hadoop:/software/hadoop-2.7.2/share/hadoop/common/lib/commons-compress-1.4.1.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/jersey-server-1.9.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/jets3t-0.9.0.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/jersey-core-1.9.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/hadoop-auth-2.7.2.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/commons-digester-1.8.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/log4j-1.2.17.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/java-xmlbuilder-0.4.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/curator-client-2.7.1.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/jetty-util-6.1.26.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/xmlenc-0.52.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/activation-1.1.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/jackson-core-asl-1.9.13.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/jaxb-impl-2.2.3-1.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/curator-framework-2.7.1.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/apacheds-kerberos-codec-2.0.0-M15.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/netty-3.6.2.Final.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/commons-collections-3.2.2.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/htrace-core-3.1.0-incubating.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/apacheds-i18n-2.0.0-M15.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/jetty-6.1.26.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/commons-configuration-1.6.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/asm-3.2.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/commons-io-2.4.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/commons-codec-1.4.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/jackson-mapper-asl-1.9.13.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/curator-recipes-2.7.1.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/mockito-all-1.8.5.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/commons-math4-3.1.1.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/commons-net-3.1.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/snappy-java-1.0.4.1.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/jsch-0.1.42.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/stax-api-1.0-2.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/jackson-jaxrs-1.9.13.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/api-util-1.0.0-M20.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/jsp-api-2.1.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/httpclient-4.2.5.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/guava-11.0.2.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/zookeeper-3.4.6.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/commons-lang-2.6.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/xz-1.0.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/jackson-xc-1.9.13.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/hadoop-annotations-2.7.2.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/jaxb-api-2.2.2.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/jersey-json-1.9.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/protobuf-java-2.5.0.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/httpcore-4.2.5.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/avro-1.7.4.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/commons-beanutils-core-1.8.0.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/servlet-api-2.5.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/api-asn1-api-1.0.0-M20.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/gson-2.2.4.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/commons-cli-1.2.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/junit-4.11.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/jettison-1.1.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/jsr305-3.0.0.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/commons-logging-1.1.3.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/hamcrest-core-1.3.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/slf4j-api-1.7.10.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/commons-httpclient-3.1.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/commons-beanutils-1.7.0.jar:/software/hadoop-2.7.2/share/hadoop/common/lib/paranamer-2.3.jar:/software/hadoop-2.7.2/share/hadoop/common/hadoop-nfs-2.7.2.jar:/software/hadoop-2.7.2/share/hadoop/common/hadoop-common-2.7.2.jar:/software/hadoop-2.7.2/share/hadoop/common/hadoop-common-2.7.2-tests.jar:/software/hadoop-2.7.2/share/hadoop/hdfs:/software/hadoop-2.7.2/share/hadoop/hdfs/lib/jersey-server-1.9.jar:/software/hadoop-2.7.2/share/hadoop/hdfs/lib/leveldbjni-all-1.8.jar:/software/hadoop-2.7.2/share/hadoop/hdfs/lib/jersey-core-1.9.jar:/software/hadoop-2.7.2/share/hadoop/hdfs/lib/netty-all-4.0.23.Final.jar:/software/hadoop-2.7.2/share/hadoop/hdfs/lib/log4j-1.2.17.jar:/software/hadoop-2.7.2/share/hadoop/hdfs/lib/jetty-util-6.1.26.jar:/software/hadoop-2.7.2/share/hadoop/hdfs/lib/xmlenc-0.52.jar:/software/hadoop-2.7.2/share/hadoop/hdfs/lib/xercesImpl-2.9.1.jar:/software/hadoop-2.7.2/share/hadoop/hdfs/lib/jackson-core-asl-1.9.13.jar:/software/hadoop-2.7.2/share/hadoop/hdfs/lib/commons-daemon-1.0.13.jar:/software/hadoop-2.7.2/share/hadoop/hdfs/lib/netty-3.6.2.Final.jar:/software/hadoop-2.7.2/share/hadoop/hdfs/lib/htrace-core-3.1.0-incubating.jar:/software/hadoop-2.7.2/share/hadoop/hdfs/lib/jetty-6.1.26.jar:/software/hadoop-2.7.2/share/hadoop/hdfs/lib/asm-3.2.jar:/software/hadoop-2.7.2/share/hadoop/hdfs/lib/commons-io-2.4.jar:/software/hadoop-2.7.2/share/hadoop/hdfs/lib/xml-apis-1.3.04.jar:/software/hadoop-2.7.2/share/hadoop/hdfs/lib/commons-codec-1.4.jar:/software/hadoop-2.7.2/share/hadoop/hdfs/lib/jackson-mapper-asl-1.9.13.jar:/software/hadoop-2.7.2/share/hadoop/hdfs/lib/guava-11.0.2.jar:/software/hadoop-2.7.2/share/hadoop/hdfs/lib/commons-lang-2.6.jar:/software/hadoop-2.7.2/share/hadoop/hdfs/lib/protobuf-java-2.5.0.jar:/software/hadoop-2.7.2/share/hadoop/hdfs/lib/servlet-api-2.5.jar:/software/hadoop-2.7.2/share/hadoop/hdfs/lib/commons-cli-1.2.jar:/software/hadoop-2.7.2/share/hadoop/hdfs/lib/jsr305-3.0.0.jar:/software/hadoop-2.7.2/share/hadoop/hdfs/lib/commons-logging-1.1.3.jar:/software/hadoop-2.7.2/share/hadoop/hdfs/hadoop-hdfs-2.7.2-tests.jar:/software/hadoop-2.7.2/share/hadoop/hdfs/hadoop-hdfs-2.7.2.jar:/software/hadoop-2.7.2/share/hadoop/hdfs/hadoop-hdfs-nfs-2.7.2.jar:/software/hadoop-2.7.2/share/hadoop/yarn/lib/commons-compress-1.4.1.jar:/software/hadoop-2.7.2/share/hadoop/yarn/lib/jersey-server-1.9.jar:/software/hadoop-2.7.2/share/hadoop/yarn/lib/leveldbjni-all-1.8.jar:/software/hadoop-2.7.2/share/hadoop/yarn/lib/jersey-core-1.9.jar:/software/hadoop-2.7.2/share/hadoop/yarn/lib/log4j-1.2.17.jar:/software/hadoop-2.7.2/share/hadoop/yarn/lib/jersey-client-1.9.jar:/software/hadoop-2.7.2/share/hadoop/yarn/lib/jetty-util-6.1.26.jar:/software/hadoop-2.7.2/share/hadoop/yarn/lib/activation-1.1.jar:/software/hadoop-2.7.2/share/hadoop/yarn/lib/jackson-core-asl-1.9.13.jar:/software/hadoop-2.7.2/share/hadoop/yarn/lib/jaxb-impl-2.2.3-1.jar:/software/hadoop-2.7.2/share/hadoop/yarn/lib/netty-3.6.2.Final.jar:/software/hadoop-2.7.2/share/hadoop/yarn/lib/commons-collections-3.2.2.jar:/software/hadoop-2.7.2/share/hadoop/yarn/lib/aopalliance-1.0.jar:/software/hadoop-2.7.2/share/hadoop/yarn/lib/jetty-6.1.26.jar:/software/hadoop-2.7.2/share/hadoop/yarn/lib/asm-3.2.jar:/software/hadoop-2.7.2/share/hadoop/yarn/lib/commons-io-2.4.jar:/software/hadoop-2.7.2/share/hadoop/yarn/lib/commons-codec-1.4.jar:/software/hadoop-2.7.2/share/hadoop/yarn/lib/jersey-guice-1.9.jar:/software/hadoop-2.7.2/share/hadoop/yarn/lib/jackson-mapper-asl-1.9.13.jar:/software/hadoop-2.7.2/share/hadoop/yarn/lib/zookeeper-3.4.6-tests.jar:/software/hadoop-2.7.2/share/hadoop/yarn/lib/javax.inject-1.jar:/software/hadoop-2.7.2/share/hadoop/yarn/lib/stax-api-1.0-2.jar:/software/hadoop-2.7.2/share/hadoop/yarn/lib/jackson-jaxrs-1.9.13.jar:/software/hadoop-2.7.2/share/hadoop/yarn/lib/guice-3.0.jar:/software/hadoop-2.7.2/share/hadoop/yarn/lib/guava-11.0.2.jar:/software/hadoop-2.7.2/share/hadoop/yarn/lib/zookeeper-3.4.6.jar:/software/hadoop-2.7.2/share/hadoop/yarn/lib/commons-lang-2.6.jar:/software/hadoop-2.7.2/share/hadoop/yarn/lib/xz-1.0.jar:/software/hadoop-2.7.2/share/hadoop/yarn/lib/jackson-xc-1.9.13.jar:/software/hadoop-2.7.2/share/hadoop/yarn/lib/jaxb-api-2.2.2.jar:/software/hadoop-2.7.2/share/hadoop/yarn/lib/jersey-json-1.9.jar:/software/hadoop-2.7.2/share/hadoop/yarn/lib/protobuf-java-2.5.0.jar:/software/hadoop-2.7.2/share/hadoop/yarn/lib/servlet-api-2.5.jar:/software/hadoop-2.7.2/share/hadoop/yarn/lib/guice-servlet-3.0.jar:/software/hadoop-2.7.2/share/hadoop/yarn/lib/commons-cli-1.2.jar:/software/hadoop-2.7.2/share/hadoop/yarn/lib/jettison-1.1.jar:/software/hadoop-2.7.2/share/hadoop/yarn/lib/jsr305-3.0.0.jar:/software/hadoop-2.7.2/share/hadoop/yarn/lib/commons-logging-1.1.3.jar:/software/hadoop-2.7.2/share/hadoop/yarn/hadoop-yarn-api-2.7.2.jar:/software/hadoop-2.7.2/share/hadoop/yarn/hadoop-yarn-server-applicationhistoryservice-2.7.2.jar:/software/hadoop-2.7.2/share/hadoop/yarn/hadoop-yarn-server-web-proxy-2.7.2.jar:/software/hadoop-2.7.2/share/hadoop/yarn/hadoop-yarn-server-resourcemanager-2.7.2.jar:/software/hadoop-2.7.2/share/hadoop/yarn/hadoop-yarn-server-sharedcachemanager-2.7.2.jar:/software/hadoop-2.7.2/share/hadoop/yarn/hadoop-yarn-applications-distributedshell-2.7.2.jar:/software/hadoop-2.7.2/share/hadoop/yarn/hadoop-yarn-applications-unmanaged-am-launcher-2.7.2.jar:/software/hadoop-2.7.2/share/hadoop/yarn/hadoop-yarn-registry-2.7.2.jar:/software/hadoop-2.7.2/share/hadoop/yarn/hadoop-yarn-client-2.7.2.jar:/software/hadoop-2.7.2/share/hadoop/yarn/hadoop-yarn-common-2.7.2.jar:/software/hadoop-2.7.2/share/hadoop/yarn/hadoop-yarn-server-common-2.7.2.jar:/software/hadoop-2.7.2/share/hadoop/yarn/hadoop-yarn-server-nodemanager-2.7.2.jar:/software/hadoop-2.7.2/share/hadoop/yarn/hadoop-yarn-server-tests-2.7.2.jar:/software/hadoop-2.7.2/share/hadoop/mapreduce/lib/commons-compress-1.4.1.jar:/software/hadoop-2.7.2/share/hadoop/mapreduce/lib/jersey-server-1.9.jar:/software/hadoop-2.7.2/share/hadoop/mapreduce/lib/leveldbjni-all-1.8.jar:/software/hadoop-2.7.2/share/hadoop/mapreduce/lib/jersey-core-1.9.jar:/software/hadoop-2.7.2/share/hadoop/mapreduce/lib/log4j-1.2.17.jar:/software/hadoop-2.7.2/share/hadoop/mapreduce/lib/jackson-core-asl-1.9.13.jar:/software/hadoop-2.7.2/share/hadoop/mapreduce/lib/netty-3.6.2.Final.jar:/software/hadoop-2.7.2/share/hadoop/mapreduce/lib/aopalliance-1.0.jar:/software/hadoop-2.7.2/share/hadoop/mapreduce/lib/asm-3.2.jar:/software/hadoop-2.7.2/share/hadoop/mapreduce/lib/commons-io-2.4.jar:/software/hadoop-2.7.2/share/hadoop/mapreduce/lib/jersey-guice-1.9.jar:/software/hadoop-2.7.2/share/hadoop/mapreduce/lib/jackson-mapper-asl-1.9.13.jar:/software/hadoop-2.7.2/share/hadoop/mapreduce/lib/javax.inject-1.jar:/software/hadoop-2.7.2/share/hadoop/mapreduce/lib/snappy-java-1.0.4.1.jar:/software/hadoop-2.7.2/share/hadoop/mapreduce/lib/guice-3.0.jar:/software/hadoop-2.7.2/share/hadoop/mapreduce/lib/xz-1.0.jar:/software/hadoop-2.7.2/share/hadoop/mapreduce/lib/hadoop-annotations-2.7.2.jar:/software/hadoop-2.7.2/share/hadoop/mapreduce/lib/protobuf-java-2.5.0.jar:/software/hadoop-2.7.2/share/hadoop/mapreduce/lib/avro-1.7.4.jar:/software/hadoop-2.7.2/share/hadoop/mapreduce/lib/guice-servlet-3.0.jar:/software/hadoop-2.7.2/share/hadoop/mapreduce/lib/junit-4.11.jar:/software/hadoop-2.7.2/share/hadoop/mapreduce/lib/hamcrest-core-1.3.jar:/software/hadoop-2.7.2/share/hadoop/mapreduce/lib/paranamer-2.3.jar:/software/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar:/software/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-client-hs-plugins-2.7.2.jar:/software/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-client-common-2.7.2.jar:/software/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.2-tests.jar:/software/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-client-hs-2.7.2.jar:/software/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-client-shuffle-2.7.2.jar:/software/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.7.2.jar:/software/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.2.jar:/software/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-client-app-2.7.2.jar:/software/hadoop/contrib/capacity-scheduler/*.jar
STARTUP_MSG: build =https://git-wip-us.apache.org/repos/asf/hadoop.git -rb165c4fe8a74265c792ce23f546c64604acf0e41; compiled by 'jenkins' on 2016-01-26T00:08Z
STARTUP_MSG: java = 1.8.0_111
************************************************************/
16/11/21 22:52:03 INFO namenode.NameNode:registered UNIX signal handlers for [TERM, HUP, INT]
16/11/21 22:52:03 INFO namenode.NameNode:createNameNode [-format]
Formatting using clusterid:CID-dd4d717c-52a6-49b1-b228-303eba107996
16/11/21 22:52:05 INFOnamenode.FSNamesystem: No KeyProvider found.
16/11/21 22:52:05 INFOnamenode.FSNamesystem: fsLock is fair:true
16/11/21 22:52:05 INFOblockmanagement.DatanodeManager: dfs.block.invalidate.limit=1000
16/11/21 22:52:05 INFOblockmanagement.DatanodeManager:dfs.namenode.datanode.registration.ip-hostname-check=true
16/11/21 22:52:05 INFOblockmanagement.BlockManager: dfs.namenode.startup.delay.block.deletion.sec isset to 000:00:00:00.000
16/11/21 22:52:05 INFOblockmanagement.BlockManager: The block deletion will start around 2016 Nov 2122:52:05
16/11/21 22:52:05 INFO util.GSet: Computingcapacity for map BlocksMap
16/11/21 22:52:05 INFO util.GSet: VMtype = 64-bit
16/11/21 22:52:05 INFO util.GSet: 2.0% maxmemory 966.7 MB = 19.3 MB
16/11/21 22:52:05 INFO util.GSet:capacity = 2^21 = 2097152 entries
16/11/21 22:52:05 INFOblockmanagement.BlockManager: dfs.block.access.token.enable=false
16/11/21 22:52:05 INFOblockmanagement.BlockManager: defaultReplication = 1
16/11/21 22:52:05 INFOblockmanagement.BlockManager: maxReplication = 512
16/11/21 22:52:05 INFOblockmanagement.BlockManager: minReplication = 1
16/11/21 22:52:05 INFOblockmanagement.BlockManager: maxReplicationStreams = 2
16/11/21 22:52:05 INFOblockmanagement.BlockManager: replicationRecheckInterval = 3000
16/11/21 22:52:05 INFOblockmanagement.BlockManager: encryptDataTransfer = false
16/11/21 22:52:05 INFOblockmanagement.BlockManager: maxNumBlocksToLog = 1000
16/11/21 22:52:05 INFOnamenode.FSNamesystem: fsOwner = hadoop (auth:SIMPLE)
16/11/21 22:52:05 INFOnamenode.FSNamesystem: supergroup = supergroup
16/11/21 22:52:05 INFOnamenode.FSNamesystem: isPermissionEnabled = true
16/11/21 22:52:05 INFOnamenode.FSNamesystem: HA Enabled: false
16/11/21 22:52:05 INFOnamenode.FSNamesystem: Append Enabled: true
16/11/21 22:52:05 INFO util.GSet: Computingcapacity for map INodeMap
16/11/21 22:52:05 INFO util.GSet: VMtype = 64-bit
16/11/21 22:52:05 INFO util.GSet: 1.0% maxmemory 966.7 MB = 9.7 MB
16/11/21 22:52:05 INFO util.GSet:capacity = 2^20 = 1048576 entries
16/11/21 22:52:05 INFO namenode.FSDirectory:ACLs enabled? false
16/11/21 22:52:05 INFOnamenode.FSDirectory: XAttrs enabled? true
16/11/21 22:52:05 INFOnamenode.FSDirectory: Maximum size of an xattr: 16384
16/11/21 22:52:05 INFO namenode.NameNode:Caching file names occuring more than 10 times
16/11/21 22:52:05 INFO util.GSet: Computingcapacity for map cachedBlocks
16/11/21 22:52:05 INFO util.GSet: VMtype = 64-bit
16/11/21 22:52:05 INFO util.GSet: 0.25% maxmemory 966.7 MB = 2.4 MB
16/11/21 22:52:05 INFO util.GSet:capacity = 2^18 = 262144 entries
16/11/21 22:52:05 INFOnamenode.FSNamesystem: dfs.namenode.safemode.threshold-pct = 0.9990000128746033
16/11/21 22:52:05 INFOnamenode.FSNamesystem: dfs.namenode.safemode.min.datanodes = 0
16/11/21 22:52:05 INFOnamenode.FSNamesystem: dfs.namenode.safemode.extension = 30000
16/11/21 22:52:05 INFO metrics.TopMetrics:NNTop conf: dfs.namenode.top.window.num.buckets = 10
16/11/21 22:52:05 INFO metrics.TopMetrics:NNTop conf: dfs.namenode.top.num.users = 10
16/11/21 22:52:05 INFO metrics.TopMetrics:NNTop conf: dfs.namenode.top.windows.minutes = 1,5,25
16/11/21 22:52:05 INFOnamenode.FSNamesystem: Retry cache on namenode is enabled
16/11/21 22:52:05 INFOnamenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cacheentry expiry time is 600000 millis
16/11/21 22:52:05 INFO util.GSet: Computingcapacity for map NameNodeRetryCache
16/11/21 22:52:05 INFO util.GSet: VMtype = 64-bit
16/11/21 22:52:05 INFO util.GSet: 0.029999999329447746%max memory 966.7 MB = 297.0 KB
16/11/21 22:52:05 INFO util.GSet:capacity = 2^15 = 32768 entries
16/11/21 22:52:06 INFO namenode.FSImage:Allocated new BlockPoolId: BP-1695203913-192.168.1.200-1479739926047
16/11/21 22:52:06 INFO common.Storage:Storage directory /tmp/hadoop-hadoop/dfs/name has been successfully formatted.
16/11/21 22:52:06 INFOnamenode.NNStorageRetentionManager: Going to retain 1 p_w_picpaths with txid >= 0
16/11/21 22:52:06 INFO util.ExitUtil:Exiting with status 0
16/11/21 22:52:06 INFO namenode.NameNode:SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode ats200/192.168.1.200
************************************************************/
[hadoop@s200 hadoop]$
9、启动hdfs
[hadoop@s200 hadoop]$ start-dfs.sh
Starting namenodes on [localhost]
localhost: starting namenode, logging to/software/hadoop-2.7.2/logs/hadoop-hadoop-namenode-s200.out
localhost: starting datanode, logging to/software/hadoop-2.7.2/logs/hadoop-hadoop-datanode-s200.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode,logging to /software/hadoop-2.7.2/logs/hadoop-hadoop-secondarynamenode-s200.out
10、验证hdfs是否启动成功,使用jps命令如出现NameNode、DataNode、SecondaryNameNode这3个进程则表示启动成功。
[hadoop@s200 hadoop]$ jps
5283 DataNode
5587 SecondaryNameNode
5797 Jps
5112 NameNode
11、启动yarn
[hadoop@s200 hadoop]$ start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to/software/hadoop-2.7.2/logs/yarn-hadoop-resourcemanager-s200.out
localhost: starting nodemanager, logging to/software/hadoop-2.7.2/logs/yarn-hadoop-nodemanager-s200.out
12、验证yarn是否启动成功,使用jps命令查看有ResourceManager和NodeManager两个进程,则表示yarn启动成功。
[hadoop@s200 hadoop]$ jps
5283 DataNode
5587 SecondaryNameNode
5112 NameNode
6233 Jps
5883 ResourceManager
6015 NodeManager
[hadoop@s200 hadoop]$
13、通过WEB UI浏览 验证
HDFS和YARN ResourceManager各自提供了web接口,通过这些接口可查看HDFS集群和YARN集群的状态信息,访问方式:
HDFS-NameNode :http://<NameNodeHost>:50070
YARN-ResourceManager : http://<ResourceManagerHost>:8088
完全分布式模式
1) 在伪分布模式的基础上进行下面的步骤。
2) 配置core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://s200</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-${user.name}</value>
</property>
</configuration>
3) 配置hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>s202:50090</value>
</property>
</configuration>
4) 配置yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>s200</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
5) 修改$HADOOP_HOME/etc/hadoop/slaves文件
s201
6) 集群上面分发上面修改的4个文件
7) 重新格式化文件系统
hdfs namenode -format
8) 启动hdfs文件系统
start-dfs.sh
注意:该步启动文件系统的时候可能会出现如下错误:
FATALorg.apache.hadoop.hdfs.server.datanode.DataNode: Initialization failed forblock pool Block pool BP-336454126-127.0.0.1-1419216478581 (storage idDS-445205871-127.0.0.1-50010-1419216613930) service to /192.168.149.128:9000
org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.hdfs.server.protocol.DisallowedDatanodeException):Datanode denied communication with namenode: DatanodeRegistration(0.0.0.0,storageID=DS-445205871-127.0.0.1-50010-1419216613930, infoPort=50075,ipcPort=50020,storageInfo=lv=-47;cid=CID-41993190-ade1-486c-8fe1-395c1d6f5739;nsid=1679060915;c=0)
at org.apache.hadoop.hdfs.server.blockmanagement.DatanodeManager.registerDatanode(DatanodeManager.java:739)
atorg.apache.hadoop.hdfs.server.namenode.FSNamesystem.registerDatanode(FSNamesystem.java:3929)
atorg.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.registerDatanode(NameNodeRpcServer.java:948)
atorg.apache.hadoop.hdfs.protocolPB.DatanodeProtocolServerSideTranslatorPB.registerDatanode(DatanodeProtocolServerSideTranslatorPB.java:90)
atorg.apache.hadoop.hdfs.protocol.proto.DatanodeProtocolProtos$DatanodeProtocolService$2.callBlockingMethod(DatanodeProtocolProtos.java:24079)
atorg.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:585)
atorg.apache.hadoop.ipc.RPC$Server.call(RPC.java:928)
atorg.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2048)
atorg.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2044)
atjava.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
atorg.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1491)
atorg.apache.hadoop.ipc.Server$Handler.run(Server.java:2042)
产生原因,一开始配置文件中使用的是localhost ,后来改成Ip, 再次格式化了namenode引起的。
解决方案:
1,删除dfs.namenode.name.dir和dfs.datanode.data.dir 目录下的所有文件
2,修改hosts
[tank@localhost hadoop-2.2.0]$ cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4localhost4.localdomain4
::1 localhostlocalhost.localdomain localhost6 localhost6.localdomain6
192.168.149.128 localhost
3,重新格式化:bin/hadoop namenode-format
4,启动
附:如果没有删除datanode 格式化了namenode,则会引起datanode与namenode版本号不一致的错误
解决方案:
修改dfs.datanode.data.dir下的current/version中的clusterID与
dfs.namenode.name.dir的一致重启即可。
9) 启动yarn
start-yarn.sh
10)使用jps查看各个节点的进程是否正确,如下图则表示成功,否则为失败。

免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。