жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« дё»иҰҒдёәеӨ§е®¶еұ•зӨәдәҶвҖңPythonеҰӮдҪ•е®һзҺ°ж•°жҚ®йҖҸи§ҶиЎЁвҖқпјҢеҶ…е®№з®ҖиҖҢжҳ“жҮӮпјҢжқЎзҗҶжё…жҷ°пјҢеёҢжңӣиғҪеӨҹеё®еҠ©еӨ§е®¶и§ЈеҶіз–‘жғ‘пјҢдёӢйқўи®©е°Ҹзј–еёҰйўҶеӨ§е®¶дёҖиө·з ”究并еӯҰд№ дёҖдёӢвҖңPythonеҰӮдҪ•е®һзҺ°ж•°жҚ®йҖҸи§ҶиЎЁвҖқиҝҷзҜҮж–Үз« еҗ§гҖӮ
з”ЁPythonйҮҢзҡ„PandasеҸҜд»Ҙе®һзҺ°пјҢиҷҪ然ж„ҹи§үExcelжӣҙж–№дҫҝ
дёҚеӨҹзӣҙи§ӮпјҢдёҚеҘҪзңӢ
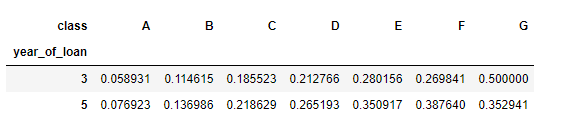
еҜ№иҙ·ж¬ҫе№ҙд»ҪпјҢиҙ·ж¬ҫз§Қзұ»еҲӣе»әж•°жҚ®йҖҸи§Ҷ
train_data.groupby(['year_of_loan', 'class']).agg(d_roat =('isDefault', 'mean'))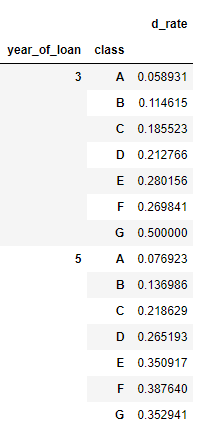
pandas.crosstab(index, columns,values, rownames=None, colnames, aggfunc, margins, margins_name, dropna, normalize)
дё»иҰҒз”ЁеҲ°зҡ„еҸӮж•°пјҡ
indexпјҡйҖүе“ӘдёӘеҸҳйҮҸеҒҡж•°жҚ®йҖҸи§ҶиЎЁзҡ„иЎҢ
columnsпјҡйҖүе“ӘдёӘеҸҳйҮҸеҒҡж•°жҚ®йҖҸи§ҶиЎЁзҡ„еҲ—
valuesпјҡиҰҒиҒҡеҗҲзҡ„еҖј
aggfuncпјҡдҪҝз”Ёзҡ„иҒҡеҗҲеҮҪж•°
marginsпјҡжҳҜеҗҰж·»еҠ жұҮжҖ»еҲ—/иЎҢ
margins_nameпјҡжұҮжҖ»иЎҢ/еҲ—зҡ„еҗҚеӯ—
дҫӢеӯҗ
еҜ№иҙ·ж¬ҫе№ҙд»ҪпјҢиҙ·ж¬ҫз§Қзұ»еҲӣе»әж•°жҚ®йҖҸи§Ҷ
pd.crosstab(train_data['year_of_loan'], train_data['class'], train_data['loan_id'], aggfunc='count',margins = True, margins_name = 'еҗҲи®Ў')
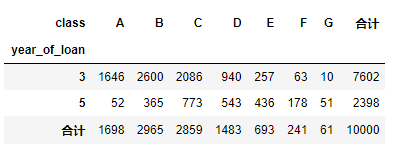
еҸҜд»ҘзӣҙжҺҘзңӢеҮәдәӨеҸүз»„еҗҲд№ӢеҗҺиҝқзәҰжҜ”дҫӢ
pd.crosstab(train_data['year_of_loan'], train_data['class'], train_data['isDefault'], aggfunc='mean')
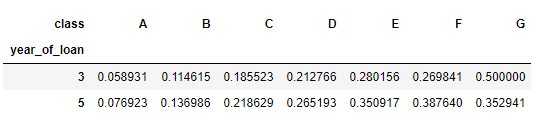
train_data.groupby(['year_of_loan', 'class'], as_index = False)['isDefault'].mean().pivot('year_of_loan', 'class', 'isDefault')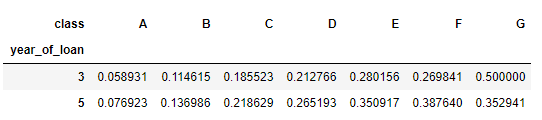
pandas.pivot_table(data, values, index, columns, aggfunc, fill_value, margins, dropna, margins_name, observed, sort)
еёёз”ЁеҸӮж•°дёҺcrosstabдёҖиҮҙ
дҫӢеӯҗ
е®һзҺ°еҗҢж ·зҡ„ж•°жҚ®йҖҸи§ҶиЎЁ
pandas.pivot_table(data, values, index, columns, aggfunc, fill_value, margins, dropna, margins_name, observed, sort)

pd.pivot_table(train_data[['year_of_loan', 'class', 'isDefault']], values='isDefault', index=['year_of_loan'], columns=['class'], aggfunc='mean')
д»ҘдёҠжҳҜвҖңPythonеҰӮдҪ•е®һзҺ°ж•°жҚ®йҖҸи§ҶиЎЁвҖқиҝҷзҜҮж–Үз« зҡ„жүҖжңүеҶ…е®№пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒзӣёдҝЎеӨ§е®¶йғҪжңүдәҶдёҖе®ҡзҡ„дәҶи§ЈпјҢеёҢжңӣеҲҶдә«зҡ„еҶ…е®№еҜ№еӨ§е®¶жңүжүҖеё®еҠ©пјҢеҰӮжһңиҝҳжғіеӯҰд№ жӣҙеӨҡзҹҘиҜҶпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ