жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жң¬зҜҮж–Үз« дёәеӨ§е®¶еұ•зӨәдәҶElasticSearchеӨ§ж•°жҚ®еҲҶеёғејҸеј№жҖ§жҗңзҙўеј•ж“ҺиҜҘеҰӮдҪ•дҪҝз”ЁпјҢеҶ…е®№з®ҖжҳҺжүјиҰҒ并且容жҳ“зҗҶи§ЈпјҢз»қеҜ№иғҪдҪҝдҪ зңјеүҚдёҖдә®пјҢйҖҡиҝҮиҝҷзҜҮж–Үз« зҡ„иҜҰз»Ҷд»Ӣз»ҚеёҢжңӣдҪ иғҪжңүжүҖ收иҺ·гҖӮ
дёӨе№ҙеүҚжңүжңәдјҡжҺҘи§ҰиҝҮelasticsearchпјҢдҪҶжҳҜжңӘеҒҡж·ұе…ҘеӯҰд№ пјҢеҸӘжҳҜе·ҘдҪңдёӯз”ЁеҲ°дәҶгҖӮи¶ҠжқҘи¶ҠеҸ‘зҺ°esжҳҜдёӘдёҚй”ҷзҡ„еҘҪдёңиҘҝпјҢжүҖд»ҘиҠұдәҶзӮ№ж—¶й—ҙеҘҪеҘҪеӯҰд№ дәҶдёӢгҖӮеңЁеӯҰд№ иҝҮзЁӢдёӯд№ҹеҸ‘зҺ°дәҶдёҖдәӣй—®йўҳпјҢзҪ‘дёҠеӨ§еӨҡиө„ж–ҷйғҪеҫҲйӣ¶ж•ЈпјҢеӨ§йғЁеҲҶйғҪжҳҜе®һйӘҢжҖ§зҡ„demoпјҢеҫҲеӨҡй—®йўҳ并没жңүи®Іжё…жҘҡд№ҹ并没жңүзі»з»ҹзҡ„и®Іе®Ңж•ҙдёҖж•ҙеҘ—ж–№жЎҲпјҢжүҖд»ҘиҖҗеҝғзҡ„ж‘ёзҙўе’ҢжҖ»з»“дәҶдёҖдәӣдёңиҘҝеҲҶдә«еҮәжқҘгҖӮ
жҜ•з«ҹеҪ“дҪ з”Ёз”ҹдә§дҪҝз”Ёзҡ„ж ҮеҮҶжқҘдҪҝз”Ёesж—¶дјҡжңүеҫҲеӨҡй—®йўҳпјҢиҝҷеҜ№дҪ зҡ„еӯҰд№ жҸҗеҮәжқҘдәҶж–°зҡ„ж ҮеҮҶгҖӮ
жҜ”еҰӮпјҢдҪҝз”Ёelasticsearch servicewrapperиҝӣиЎҢиҮӘеҗҜеҠЁзҡ„ж—¶еҖҷйҡҫйҒ“е°ұжІЎеҸ‘зҺ°е®ғзҡ„й…ҚзҪ®дёӯжңүдёҖдёӘе°ҸbugеҜјиҮҙloadдёҚдәҶelasticsearch jarеҢ…дёӯзҡ„classеҗ—гҖӮ
иҝҳжңүesдёҚеҗҢзүҲжң¬д№Ӣй—ҙзҡ„е·®ејӮе·ЁеӨ§пјҢжҜ”еҰӮпјҢ1.0дёӯзҡ„еҲҶеёғејҸroutingеңЁ2.0дёӯиҝӣиЎҢдәҶе·ЁеӨ§е·®ејӮзҡ„дҝ®ж”№гҖӮеҺҹжң¬routingжҳҜи·ҹзқҖmappingдёҖиө·й…ҚзҪ®зҡ„пјҢеҲ°дәҶ2.0еҚҙи·ҹзқҖindexеҠЁжҖҒиө°дәҶгҖӮиҝҷдёӘи°ғж•ҙзҡ„жң¬иҙЁзӣ®зҡ„жҳҜеҘҪзҡ„пјҢи®©еҗҢдёҖдёӘindexзҡ„дёҚеҗҢtypeйғҪжңүжңәдјҡйҖүжӢ©shardзҡ„зүҮй”®гҖӮеҰӮжһңжҳҜи·ҹзқҖmappingиө°зҡ„иҜқе°ұеҸӘиғҪйҷҗе®ҡдәҺеҪ“еүҚindexзҡ„жүҖжңүtypeгҖӮ
esжҳҜдёӘеҘҪдёңиҘҝпјҢзҺ°еңЁи¶ҠжқҘи¶ҠеӨҡзҡ„еҲҶеёғејҸзі»з»ҹйғҪйңҖиҰҒз”ЁеҲ°е®ғжқҘи§ЈеҶій—®йўҳгҖӮд»ҺELKиҝҷз§Қзі»з»ҹеұӮзҡ„е·Ҙе…·еҲ°з”өе•Ҷе№іеҸ°зҡ„ж ёеҝғдёҡеҠЎдәӨжҳ“зі»з»ҹзҡ„и®ҫи®ЎйғҪйңҖиҰҒе®ғжқҘж”Ҝж’‘е®һж—¶еӨ§ж•°жҚ®жҗңзҙўеҲҶжһҗгҖӮжҜ”еҰӮпјҢе•Ҷе“Ғдёӯеҝғзҡ„дёҠеҚғдёҮзҡ„skuйңҖиҰҒе®һж—¶жҗңзҙўпјҢеҶҚеҲ°жө·йҮҸзҡ„еңЁзәҝи®ўеҚ•е®һж—¶жҹҘиҜўйғҪйңҖиҰҒз”ЁеҲ°жҗңзҙўгҖӮ
еңЁдёҖдәӣDevOpsзҡ„е·Ҙе…·дёӯйғҪйңҖиҰҒesжқҘжҸҗдҫӣејәеӨ§зҡ„е®һж—¶жҗңзҙўеҠҹиғҪгҖӮеҖјеҫ—иҠұзӮ№ж—¶й—ҙеҘҪеҘҪз ”з©¶еӯҰд№ дёӢгҖӮ
дҪңдёәз”өе•Ҷжһ¶жһ„еёҲпјҢжүҖд»ҘжІЎжңүд»Җд№ҲзҗҶз”ұдёҚеҺ»еӯҰд№ е’ҢдҪҝз”Ёе®ғжқҘжҸҗй«ҳзі»з»ҹзҡ„ж•ҙдҪ“жңҚеҠЎж°ҙе№ігҖӮжң¬зҜҮж–Үз« е°ҶиҮӘе·ұиҝҷж®өж—¶й—ҙеӯҰд№ зҡ„з»ҸйӘҢжҖ»з»“еҮәжқҘеҲҶдә«з»ҷеӨ§е®¶гҖӮ
йҰ–е…ҲдҪ йңҖиҰҒеҮ еҸ°linuxжңәеҷЁпјҢдҪ и·‘иҷҡжңәд№ҹиЎҢгҖӮдҪ еҸҜд»ҘеңЁдёҖеҸ°иҷҡжӢҹжңәдёҠе®ҢжҲҗе®үиЈ…е’Ңй…ҚзҪ®пјҢ然еҗҺе°ҶеҪ“еүҚиҷҡжӢҹжңәcloneеҮәеӨҡд»Ҫдҝ®ж”№дёӢIPгҖҒHWaddrгҖҒUUIDеҚіз”ЁпјҢиҝҷж ·ж–№дҫҝдҪ дҪҝз”ЁпјҢиҖҢдёҚйңҖиҰҒеҶҚйҮҚеӨҚзҡ„е®үиЈ…й…ҚзҪ®гҖӮ
1.жҲ‘жң¬ең°жҳҜдёүеҸ°Linux centos6.5пјҢIPеҲҶеҲ«жҳҜпјҢ192.168.0.10гҖҒ192.168.0.20гҖҒ192.168.0.30гҖӮ
(жҲ‘们е…ҲеңЁ192.168.0.10дёҠжү§иЎҢе®үиЈ…й…ҚзҪ®пјҢ然еҗҺдёҖеҲҮе°ұз»Әд№ӢеҗҺжҲ‘们е°ҶиҝҷдёӘиҠӮзӮ№cloneеҮәжқҘдҝ®ж”№й…ҚзҪ®пјҢ然еҗҺеҶҚй…ҚзҪ®йӣҶзҫӨеҸӮж•°пјҢжңҖеҗҺеҪўжҲҗеҸҜд»Ҙе·ҘдҪңзҡ„д»ҘдёүдёӘnodeз»„жҲҗзҡ„йӣҶзҫӨе®һдҫӢгҖӮпјү
2.з”ұдәҺElasticSearchжҳҜjavaиҜӯиЁҖејҖеҸ‘зҡ„пјҢжүҖд»ҘжҲ‘们йңҖиҰҒйў„е…Ҳе®үиЈ…еҘҪjavaзӣёе…ізҺҜеўғгҖӮжҲ‘дҪҝз”Ёзҡ„жҳҜJDK8пјҢзӣҙжҺҘдҪҝз”Ёyumе®үиЈ…еҚіеҸҜпјҢyumд»“еә“жңүжңҖж–°зҡ„жәҗгҖӮ
е…ҲжҹҘзңӢдҪ еҪ“еүҚжңәеҷЁжҳҜеҗҰе®үиЈ…дәҶjavaзҺҜеўғпјҡ
yum info installed |grep java*
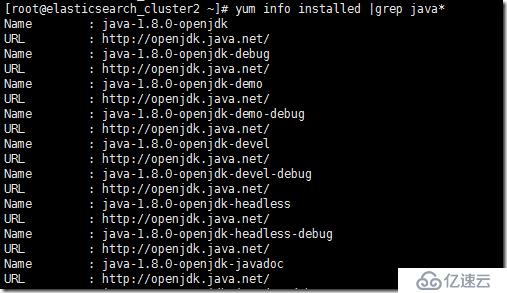
еҰӮжһңе·Із»ҸеӯҳеңЁjavaзҺҜеўғдё”иҝҷдёӘзҺҜеўғдёҚжҳҜдҪ жғіиҰҒзҡ„пјҢдҪ еҸҜд»ҘеҚёиҪҪ然еҗҺйҮҚж–°е®үиЈ…дҪ жғіиҰҒзҡ„зүҲжң¬гҖӮ(yum вҖ“y remove xxx)еҰӮжһңеҚёиҪҪдёҚе№ІеҮҖпјҢдҪ еҸҜд»ҘзӣҙжҺҘfind жҹҘжүҫзӣёе…іж–Ү件пјҢ然еҗҺзӣҙжҺҘзү©зҗҶеҲ йҷӨгҖӮlinuxзҡ„зі»з»ҹйғҪжҳҜеҹәдәҺж–Ү件зҡ„пјҢеҸӘиҰҒиғҪжүҫеҲ°еҹәжң¬дёҠйғҪеҸҜд»ҘеҲ йҷӨгҖӮ
е…ҲзңӢдёӢжңүе“ӘдәӣзүҲжң¬пјҡ
yum search java
java-1.8.0-openjdk.x86_64 : OpenJDK Runtime EnvironmentпјҲжүҫеҲ°иҝҷдёӘжәҗпјү
然еҗҺжү§иЎҢе®үиЈ…пјҡ
yum вҖ“y install java-1.8.0-openjdk.x86_64
е®үиЈ…еҘҪд№ӢеҗҺжҹҘзңӢjava зӣёе…іеҸӮж•°пјҡ
java вҖ“version

йў„еӨҮе·ҘдҪңжҲ‘们已з»ҸеҒҡеҘҪпјҢжҺҘдёӢжқҘжҲ‘们е°Ҷжү§иЎҢElasticSearchзҡ„зҺҜеўғе®үиЈ…е’Ңй…ҚзҪ®гҖӮ
дҪ еҸҜд»ҘжңүеҮ з§Қж–№ејҸе®үиЈ…гҖӮдҪҝз”Ёyum repositoryжҳҜжңҖеҝ«жңҖдҫҝжҚ·зҡ„пјҢдҪҶжҳҜдёҖиҲ¬иҝҷйҮҢйқўзҡ„зүҲжң¬еә”иҜҘжҳҜжҜ”иҫғж»һеҗҺзҡ„гҖӮжүҖд»ҘжҲ‘жҳҜзӣҙжҺҘеҲ°е®ҳзҪ‘дёӢиҪҪrpmеҢ…е®үиЈ…зҡ„гҖӮ
elasticsearchе®ҳж–№дёӢиҪҪең°еқҖпјҡhttps://www.elastic.co/downloads/elasticsearch
жүҫеҲ°дҪ еҜ№еә”зҡ„зі»з»ҹзұ»еһӢж–Ү件пјҢеҪ“然еҰӮжһңдҪ жҳҜwindowsзі»з»ҹйӮЈе°ұзӣҙжҺҘдёӢиҪҪzipеҢ…дҪҝз”Ёе°ұиЎҢдәҶгҖӮиҝҷйҮҢжҲ‘йңҖиҰҒrpmж–Ү件гҖӮ
дҪ д№ҹеҸҜд»Ҙе®үиЈ…жң¬ең°yum жәҗпјҢ然еҗҺиҝҳжҳҜдҪҝз”Ёyumе‘Ҫд»Өе®үиЈ…гҖӮ
жҲ‘жҳҜдҪҝз”Ёwget е·Ҙе…·зӣҙжҺҘдёӢиҪҪRPMж–Ү件еҲ°жң¬ең°зҡ„гҖӮпјҲеҰӮжһңдҪ зҡ„еҢ…жңүдҫқиө–е»әи®®иҝҳжҳҜyumж–№ејҸе®үиЈ…гҖӮпјү
пјҲеҰӮжһңдҪ зҡ„wgetе‘Ҫд»ӨдёҚиө·дҪңз”ЁпјҢи®°еҫ—е…Ҳе®үиЈ…пјҡyum -y install wgetпјү
wget https://download.elastic.co/elasticsearch/release/org/elasticsearch/distribution/rpm/elasticsearch/2.4.0/elasticsearch-2.4.0.rpm
然еҗҺзӯүеҫ…дёӢиҪҪе®ҢжҲҗгҖӮ
иҝҷйҮҢжңүдёӘдёңиҘҝйңҖиҰҒжҸҗйҶ’дёӢпјҢе°ұжҳҜдҪ жҳҜеҗҰиҰҒе®үиЈ…жңҖж–°зүҲжң¬зҡ„elasticsearchпјҢдёӘдәәе»әи®®иҝҳжҳҜе®үиЈ…зЁҚеҫ®дҪҺдёҖдёӘзүҲжң¬зҡ„пјҢжҲ‘жң¬ең°е®үиЈ…зҡ„жҳҜ2.3.4зҡ„зүҲжң¬гҖӮдёәд»Җд№ҲиҰҒиҝҷж ·ејәи°ғе°јпјҢеӣ дёәеҪ“дҪ е®үиЈ…дәҶеҫҲй«ҳзҡ„зүҲжң¬д№ӢеҗҺжңүдёҖдёӘеҫҲеӨ§зҡ„й—®йўҳе°ұжҳҜдёӯж–ҮеҲҶиҜҚеҷЁиғҪеҗҰж”ҜжҢҒеҲ°иҝҷдёӘзүҲжң¬гҖӮд»Һ2.3.5д№ӢеҗҺе°ұзӣҙжҺҘеҲ°2.4.0зҡ„зүҲжң¬дәҶпјҢжҲ‘еҪ“ж—¶е®үиЈ…зҡ„жҳҜ2.3.5зҡ„зүҲжң¬еҗҺжқҘеҸ‘зҺ°дёҖдёӘй—®йўҳе°ұжҳҜikдёӯж–ҮеҲҶиҜҚеҷЁжҲ‘еҫ—git cloneдёӢжқҘзј–иҜ‘еҗҺжүҚиғҪжңүиҫ“еҮәйғЁзҪІж–Ү件гҖӮжүҖд»Ҙе»әи®®еӨ§е®¶е®үиЈ…2.3.4зҡ„зүҲжң¬пјҢ2.3.4зҡ„зүҲжң¬дёӯж–ҮеҲҶиҜҚеҷЁе°ұеҸҜд»ҘзӣҙжҺҘеңЁlinuxжңҚеҠЎеҷЁйҮҢдёӢиҪҪйғЁзҪІпјҢеҫҲж–№дҫҝгҖӮ
жү§иЎҢе®үиЈ…пјҡ
rpm -iv elasticsearch-2.3.4.rpm
然еҗҺзӯүеҫ…е®үиЈ…е®ҢжҲҗгҖӮ
дёҚеҮәд»Җд№Ҳж„ҸеӨ–пјҢе®үиЈ…е°ұеә”иҜҘе®ҢжҲҗдәҶгҖӮжҲ‘们иҝӣиЎҢдёӢеҹәжң¬зҡ„е®үиЈ…дҝЎжҒҜжҹҘзңӢпјҢжҳҜеҗҰе®үиЈ…д№ӢеҗҺзјәе°‘д»Җд№Ҳж–Ү件гҖӮеӣ дёәжңүдәӣеҢ…йҮҢйқўдјҡзјәе°‘дёҖдәӣconfigй…ҚзҪ®гҖӮеҰӮжһңзјәе°‘жҲ‘们иҝҳеҫ—иЎҘе……е®Ңж•ҙгҖӮ
дёәдәҶж–№дҫҝжҹҘзңӢе®үиЈ…ж¶үеҸҠеҲ°зҡ„ж–Ү件пјҢдҪ еҸҜд»ҘеҜјиҲӘеҲ°ж №зӣ®еҪ•дёӢ findгҖӮ
cd /
find . вҖ“name elasticsearch
./var/lib/elasticsearch
./var/log/elasticsearch
./var/run/elasticsearch
./etc/rc.d/init.d/elasticsearch
./etc/sysconfig/elasticsearch
./etc/elasticsearch
./usr/share/elasticsearch
./usr/share/elasticsearch/bin/elasticsearch
еҹәжң¬дёҠе·®дёҚеӨҡдәҶпјҢдҪ иҝҳеҫ—зңӢдёӢжҳҜеҗҰзјәе°‘configпјҢеӣ дёәжҲ‘е®үиЈ…зҡ„ж—¶еҖҷжҳҜзјәе°‘зҡ„гҖӮ
cd /usr/share/elasticsearch/
ll
drwxr-xr-x. 2 root root 4096 9жңҲ 4 01:10 bin
drwxr-xr-x. 2 root root 4096 9жңҲ 4 01:10 lib
-rw-r--r--. 1 root root 11358 6жңҲ 30 19:22 LICENSE.txt
drwxr-xr-x. 5 root root 4096 9жңҲ 4 01:10 modules
-rw-r--r--. 1 root root 150 6жңҲ 30 19:22 NOTICE.txt
drwxr-xr-x. 2 elasticsearch elasticsearch 4096 6жңҲ 30 19:32 plugins
-rw-r--r--. 1 root root 8700 6жңҲ 30 19:22 README.textile
еӨ§жҰӮзңӢдёӢдҪ еә”иҜҘд№ҹжҳҜзјәе°‘configж–Ү件еӨ№зҡ„гҖӮжҲ‘们иҝҳеҫ—жҠҠиҝҷдёӘж–Ү件еӨ№е»әеҘҪпјҢеҗҢж—¶иҝҳйңҖиҰҒдёҖдёӘelasticsearch.ymlй…ҚзҪ®ж–Ү件гҖӮиҰҒдёҚ然еҗҜеҠЁзҡ„ж—¶еҖҷиӮҜе®ҡжҳҜжҠҘй”ҷзҡ„гҖӮ
mkdir config
cd config
vim elasticsearch.yml
жүҫдёҖдёӢelasticsearch.ymlй…ҚзҪ®иҙҙдёҠеҺ»пјҢжҲ–иҖ…дҪ з”Ёж–Ү件зҡ„ж–№ејҸдј йҖҒд№ҹиЎҢгҖӮиҝҷдәӣй…ҚзҪ®йғҪжҳҜеҹәжң¬зҡ„пјҢеӣһеӨҙиҝҳйңҖиҰҒж №жҚ®жғ…еҶөи°ғж•ҙй…ҚзҪ®зҡ„гҖӮжңүдәӣй…ҚзҪ®еңЁй…ҚзҪ®ж–Ү件дёӯжҳҜжІЎжңүзҡ„пјҢиҝҳйңҖиҰҒеҲ°е®ҳж–№дёҠеҺ»жҹҘжүҫзҡ„гҖӮжүҖд»ҘиҝҷйҮҢж— жүҖи°“й…ҚзҪ®ж–Ү件зҡ„е…ЁжҲ–иҖ…дёҚе…ЁгҖӮе…ідәҺй…ҚзҪ®йЎ№зҪ‘дёҠжңүеҫҲеӨҡиө„ж–ҷпјҢжүҖд»ҘиҝҷдёӘж— жүҖи°“зҡ„гҖӮ
дҝқеӯҳдёӢelasticsearch.ymlж–Ү件гҖӮ
дҪ иҝҳйңҖиҰҒдёҖдёӘlogging.ymlж—Ҙеҝ—й…ҚзҪ®ж–Ү件гҖӮesдҪңдёәжңҚеҠЎеҷЁеҗҺеҸ°иҝҗиЎҢзҡ„жңҚеҠЎжҳҜиӮҜе®ҡйңҖиҰҒж—Ҙеҝ—ж–Ү件зҡ„гҖӮиҝҷйғЁеҲҶж—Ҙеҝ—дјҡиў«дҪ зҡ„ж—Ҙеҝ—е№іеҸ°ж”¶йӣҶе’Ңзӣ‘жҺ§пјҢз”ЁжқҘеҒҡдёәиҝҗз»ҙеҒҘеә·жЈҖжҹҘгҖӮlogging.ymlжң¬иҙЁдёҠжҳҜдёҖдёӘlog4jзҡ„й…ҚзҪ®ж–Ү件пјҢиҝҷдёӘеә”иҜҘеӨ§е®¶йғҪжҜ”иҫғзҶҹжӮүдәҶгҖӮи·ҹelasticsearch.ymlзұ»дјјпјҢиҰҒд№ҲеӨҚеҲ¶зІҳиҙҙиҰҒд№Ҳж–Үд»¶дј йҖҒгҖӮ
ж—Ҙеҝ—зҡ„иҫ“еҮәеңЁlogsзӣ®еҪ•дёӢпјҢиҝҷдёӘзӣ®еҪ•дјҡиў«иҮӘеҠЁеҲӣе»әгҖӮдҪҶжҳҜжҲ‘иҝҳжҳҜе–ңж¬ўеҲӣе»әеҘҪпјҢдёҚе–ңж¬ўжңүдёҚзЎ®е®ҡеӣ зҙ пјҢд№ҹи®ёе®ғе°ұдёҚдјҡиҮӘеҠЁеҲӣе»әгҖӮ
mkdir logs
жңҖеҗҺйңҖиҰҒи®ҫзҪ®дёӢеҲҡжүҚжҲ‘们添еҠ зҡ„ж–Ү件зҡ„жү§иЎҢжқғйҷҗгҖӮиҰҒдёҚ然дҪ зҡ„ж–Ү件еҗҚеӯ—еә”иҜҘжҳҜзҷҪиүІзҡ„пјҢжҳҜдёҚе…Ғи®ёиў«жү§иЎҢгҖӮ

cd ..
chmod вҖ“R u+x config/

зҺ°еңЁеҹәжң¬дёҠе®үиЈ…з®—жҳҜе®ҢжҲҗдәҶпјҢиҜ•зқҖcdеҲ°ж–Ү件зҡ„еҗҜеҠЁзӣ®еҪ•дёӢеҗҜеҠЁesпјҢжқҘжЈҖжҹҘдёӢжҳҜеҗҰиғҪжӯЈеёёеҗҜеҠЁгҖӮ
дёҚеҮәж„ҸеӨ–дҪ дјҡ收еҲ°дёҖдёӘ вҖңjava.lang.RuntimeException: don't run elasticsearch as rootвҖқејӮеёёгҖӮиҝҷиҜҙжҳҺжҲ‘们е®ҢжҲҗдәҶ第дёҖжӯҘе®үиЈ…иҝҮзЁӢпјҢдёӢиҠӮжҲ‘们жқҘзңӢжңүе…іеҗҜеҠЁиҙҰжҲ·зҡ„й—®йўҳгҖӮ

й»ҳи®Өжғ…еҶөдёӢesжҳҜдёҚе…Ғи®ёrootиҙҰжҲ·еҗҜеҠЁзҡ„пјҢиҝҷжҳҜдёәдәҶе®үе…Ёиө·и§ҒгҖӮesй»ҳи®ӨеҶ…еөҢдәҶgroovyи„ҡжң¬еј•ж“Һзҡ„еҠҹиғҪпјҢиҝҳжңүеҫҲеӨҡpluginи„ҡжң¬еј•ж“ҺжҸ’件пјҢзЎ®е®һдёҚГ—Г—Г—е…ЁгҖӮesеҲҡеҮәжқҘзҡ„ж—¶еҖҷиҝҳжңүgroovyжјҸжҙһпјҢжүҖд»Ҙе»әи®®еңЁдә§зәҝзҡ„es instance е…іжҺүиҝҷдёӘи„ҡжң¬еҠҹиғҪгҖӮиҷҪ然й»ҳи®ӨдёҚжҳҜејҖеҗҜзҡ„пјҢе®үе…Ёиө·и§ҒиҝҳжҳҜжЈҖжҹҘдёҖдёӢдҪ зҡ„й…ҚзҪ®гҖӮ
жүҖд»ҘжҲ‘们йңҖиҰҒдёәesй…ҚзҪ®зӢ¬з«Ӣзҡ„иҙҰжҲ·е’Ңз»„гҖӮеңЁеҲӣе»әesдё“з”ЁиҙҰжҲ·д№ӢеүҚе…ҲжҹҘзңӢдёӢзі»з»ҹйҮҢйқўжҳҜеҗҰе·Із»ҸжңүдәҶesдё“з”ЁиҙҰжҲ·гҖӮеӣ дёәеңЁжҲ‘们еүҚйқўrpmе®үиЈ…зҡ„ж—¶еҖҷдјҡиҮӘеҠЁе®үиЈ…elasticsearchз»„е’Ңз”ЁжҲ·гҖӮе…ҲжҹҘзңӢдёӢпјҢеҰӮжһңдҪ зҡ„е®үиЈ…жІЎжңүеёҰдёҠдё“з”Ёз»„е’Ңз”ЁжҲ·з„¶еҗҺдҪ еңЁеҲӣе»әгҖӮиҝҷж ·д»Ҙе…ҚдҪ иҮӘе·ұеўһеҠ зҡ„е’Ңзі»з»ҹеҲӣе»әзҡ„жҗһж··ж·ҶгҖӮ
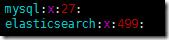
жҹҘзңӢдёӢз»„:
cat /etc/group
жҹҘзңӢдёӢз”ЁжҲ·пјҡ
cat /etc/passwd

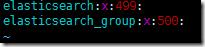
еҹәжң¬дёҠйғҪеҲӣе»әеҘҪдәҶгҖӮ499зҡ„groupеңЁpasswdдёӯд№ҹеҲӣе»әдәҶеҜ№еә”зҡ„elasticsearchиҙҰеҸ·гҖӮ
еҰӮжһңдҪ зі»з»ҹйҮҢжІЎжңүиҮӘеҠЁеҲӣе»әеҜ№еә”зҡ„з»„е’ҢиҙҰеҸ·пјҢдҪ е°ұеҠЁжүӢиҮӘе·ұеҲӣе»әпјҢеҰӮдёӢпјҡ
еҲӣе»әз»„пјҡ
groupadd elasticsearch_group
еҲӣе»әз”ЁжҲ·пјҡ
useradd elasticsearch_user -g elasticsearch_group -s /sbin/nologin

жіЁж„ҸпјҡжӯӨиҙҰжҲ·жҳҜдёҚе…·жңүзҷ»еҪ•жқғйҷҗзҡ„гҖӮе®ғзҡ„shellжҳҜеңЁ/sbin/nologinгҖӮ
дёәдәҶжј”зӨәпјҢеңЁжҲ‘зҡ„з”өи„‘дёҠжңүдёӨз»„elasticsearchдё“з”ЁиҙҰжҲ·пјҢжҲ‘е°ҶеҲ йҷӨвҖң_groupвҖқе’ҢвҖң_userвҖқз»“е°ҫзҡ„иҙҰеҸ·пјҢд»ҘrpmиҮӘеҠЁе®үиЈ…зҡ„дёәesзҡ„еҗҜеҠЁиҙҰеҸ·пјҲelasticsearchпјүгҖӮ
жҺҘдёӢжқҘжҲ‘们йңҖиҰҒеҒҡзҡ„е°ұжҳҜе…іиҒ”esж–Ү件е’ҢelasticsearchиҙҰеҸ·пјҢе°Ҷesзӣёе…ізҡ„ж–Ү件и®ҫзҪ®жҲҗelasticsearchз”ЁжҲ·дёәжүҖжңүиҖ…пјҢиҝҷж ·elasticsearchз”ЁжҲ·е°ұеҸҜд»ҘжІЎжңүд»»дҪ•жқғйҷҗйҷҗеҲ¶зҡ„дҪҝз”ЁesжүҖжңүж–Ү件гҖӮ
еҜјиҲӘеҲ°elasticsearchдёҠзә§зӣ®еҪ•пјҡ
cd /usr/share
ll

chown -R elasticsearch:elasticsearch elasticsearch/

жӯӨж—¶пјҢдҪ зҡ„elasticsearchж–Ү件зҡ„ownerжҳҜelasticsearchгҖӮ
дёәдәҶжөӢиҜ•еҗҜеҠЁesе®һдҫӢпјҢжҲ‘们йңҖиҰҒжҡӮж—¶зҡ„е°Ҷelasticsearchзҡ„з”ЁжҲ·еҲҮжҚўеҲ°/bin/bashгҖӮиҝҷж ·жҲ‘们е°ұеҸҜд»Ҙsu elasticsearchпјҢ然еҗҺеҗҜеҠЁesе®һдҫӢгҖӮ
su elasticsearch
cd /usr/share/elasticsearch/bin
./elasticsearch

еҗҜеҠЁе®ҢжҲҗпјҢжӯӨж—¶еә”иҜҘжІЎеҸ‘з”ҹд»»дҪ•ејӮеёёгҖӮзңӢдёӢзі»з»ҹз«ҜеҸЈжҳҜеҗҰеҗҜеҠЁжҲҗй•ҝгҖӮ
netstat вҖ“tnl

继з»ӯжҹҘзңӢдёӢHTTPжңҚеҠЎжҳҜеҗҰеҗҜеҠЁжӯЈеёёгҖӮ
curl вҖ“get http://192.168.0.103:9200/_cat
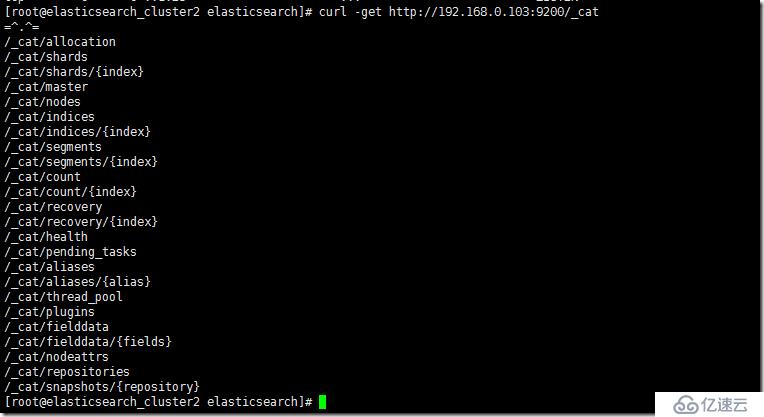
з”ұдәҺжӯӨж—¶жҲ‘们并没жңүе®үиЈ…д»»дҪ•иҫ…еҠ©з®ЎзҗҶе·Ҙе…·пјҢеҰӮпјҢplugin/headгҖӮжүҖд»Ҙз”ЁеҶ…зҪ®зҡ„_cat rest endpoitиҝҳжҳҜжҢәж–№дҫҝзҡ„гҖӮ
curl -get http://192.168.0.103:9200/_cat/nodes
192.168.0.103 192.168.0.103 4 64 0.00 d * node-1
еҸҜд»ҘзңӢи§ҒпјҢзӣ®еүҚеҸӘжңүдёҖдёӘиҠӮзӮ№еңЁе·ҘдҪңпјҢ192.168.0.103пјҢдё”е®ғжҳҜдёҖдёӘdata nodeгҖӮ
пјҲеӨҮжіЁпјҡдёәдәҶиҠӮзңҒж—¶й—ҙпјҢжҲ‘жҡӮж—¶е…ҲдҪҝз”ЁдёҖеҸ°103зҡ„е№ІеҮҖзҺҜеўғдҪңдёәе®үиЈ…е’ҢзҺҜеўғжҗӯе»әжј”зӨәпјҢеҪ“жҗӯе»әйӣҶзҫӨзҡ„ж—¶еҖҷжҲ‘дјҡcloneеҮәжқҘе’Ңдҝ®ж”№IPгҖӮ)
esзҡ„зі»з»ҹиҮӘеҗҜеҠЁжңүдёҖдёӘејҖжәҗзҡ„wrapperеҢ…еҸҜд»ҘдҪҝз”ЁгҖӮеҰӮжһңдҪ дёҚдҪҝз”ЁиҝҷдёӘwrapperд№ҹеҸҜд»ҘиҮӘе·ұеҺ»еҶҷshellи„ҡжң¬пјҢдҪҶжҳҜйҮҢйқўзҡ„еҫҲеӨҡеҸӮж•°йңҖиҰҒдҪ жҗһзҡ„йқһеёёжё…жҘҡжүҚиЎҢпјҢеңЁеҠ дёҠжңүдәӣе…ій”®еҸӮж•°йңҖиҰҒи®ҫзҪ®гҖӮжүҖд»ҘиҝҳжҳҜе»әи®®еңЁelasticsearchwrapperеҢ…зҡ„еҹәзЎҖдёҠиҝӣиЎҢдҝ®ж”№ж•ҲзҺҮдјҡй«ҳзӮ№пјҢиҖҢдё”дҪ иҝҳиғҪеңЁelasticsearch shellдёӯзңӢи§ҒдёҖдәӣesж·ұеұӮж¬Ўзҡ„й…ҚзҪ®е’ҢеҺҹзҗҶгҖӮ
(еӨҮжіЁпјҡеҰӮжһңдҪ жҳҜ.neterпјҢдҪ еҸҜд»Ҙе°ҶservicewrapperзҗҶи§ЈжҲҗжҳҜејҖжәҗ.net topshelfгҖӮжң¬иҙЁе°ұжҳҜе°ҶзЁӢеәҸеҢ…иЈ…жҲҗе…·жңүзі»з»ҹжңҚеҠЎеҠҹиғҪпјҢдҪ еҸҜд»Ҙе®үиЈ…гҖҒеҚёиҪҪпјҢд№ҹеҸҜд»ҘзӣҙжҺҘеҗҜеҠЁгҖҒеҒңжӯўпјҢжҲ–иҖ…е№Іи„ҶзӣҙжҺҘеүҚеҸ°иҝҗиЎҢгҖӮпјү
elasticsearchwrapper githubйҰ–йЎөпјҢhttps://github.com/elastic/elasticsearch-servicewrapper
еӨҚеҲ¶ git repository ең°еқҖеҲ°еүӘиҙҙжқҝпјҢ然еҗҺзӣҙжҺҘcloneеҲ°жң¬ең°гҖӮ
git clone https://github.com/elastic/elasticsearch-servicewrapper.git
(дҪ йңҖиҰҒеңЁеҪ“еүҚlinuxжңәеҷЁдёҠе®үиЈ…gitе®ўжҲ·з«Ҝпјҡyum вҖ“y install gitпјҢжҲ‘е®үиЈ…зҡ„жҳҜй»ҳи®Ө1.7зҡ„зүҲжң¬гҖӮпјү
然еҗҺзӯүеҫ…cloneе®ҢжҲҗгҖӮ

жҹҘзңӢдёӢcloneдёӢжқҘзҡ„жң¬ең°д»“еә“ж–Ү件жғ…еҶөгҖӮиҝӣе…ҘelasticsearchwrapperпјҢжҹҘзңӢеҪ“еүҚgit еҲҶж”ҜгҖӮ
cd /root/elasticsearch-servicewrapper
git branch
*master
ll
дёҖеҲҮйғҪеҫҲжӯЈеёёпјҢиҜҙжҳҺжҲ‘们cloneдёӢжқҘжІЎй—®йўҳпјҢеҢ…жӢ¬еҲҶж”Ҝд№ҹжҳҜеҫҲжё…жҷ°зҡ„гҖӮserviceж–Ү件е°ұжҳҜжҲ‘们иҰҒе®үиЈ…зҡ„е®үиЈ…ж–Ү件гҖӮ

жҲ‘们йңҖиҰҒе°Ҷserviceж–Ү件copyеҲ°elasticsearch/binзӣ®еҪ•дёӢгҖӮ
cp -R service/ /usr/share/elasticsearch/bin/
cd /usr/share/elasticsearch/bin/

serviceйҮҢзҡ„е®үиЈ…ж–Ү件йңҖиҰҒеңЁelasticsearch/binзӣ®еҪ•дёӢе·ҘдҪңгҖӮ
cd service/
ll
./elasticsearch
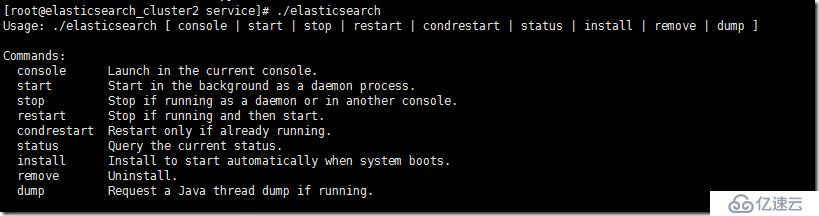
еҸӮиҖғgithubдёҠelasticsearchwrapperдҪҝз”ЁиҜҙжҳҺгҖӮelasticsearch servicewrapperзҡ„еҠҹиғҪиҝҳжҳҜиӣ®еӨҡзҡ„пјҢstatusгҖҒdumpйғҪжҳҜеҫҲеҘҪзҡ„жЈҖжҹҘе’Ңи°ғиҜ•е·Ҙе…·гҖӮ
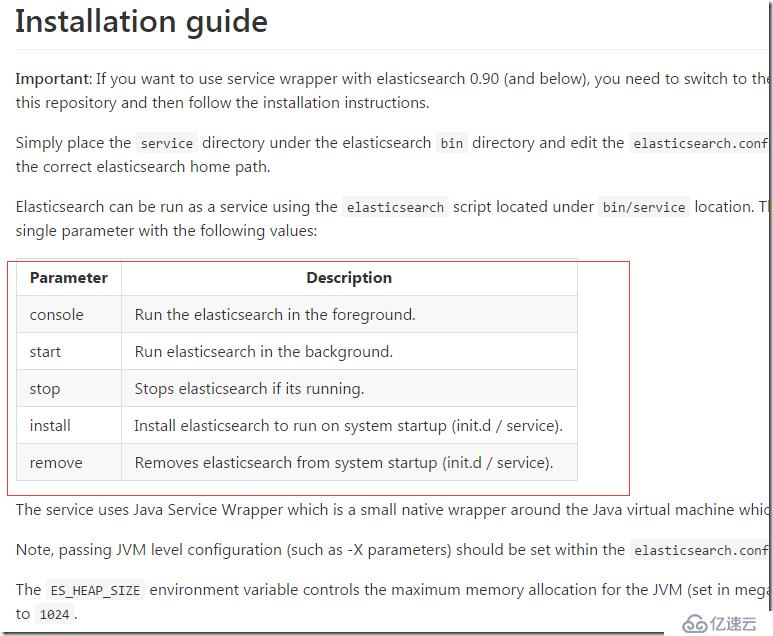
еңЁе®үиЈ…д№ӢеүҚпјҢжҲ‘们йңҖиҰҒжҡӮж—¶еңЁеүҚеҸ°иҝҗиЎҢesе®һдҫӢпјҢиҝҷж ·еҸҜд»ҘжҹҘзңӢдёҖдәӣlogжҳҜеҗҰжңүејӮеёёжғ…еҶөгҖӮParameterзҡ„еҗ„дёӘеҸӮж•°еҶҷзҡ„еҫҲжё…жҘҡпјҢжҲ‘们иҝҷйҮҢдҪҝз”ЁconsoleжҺ§еҲ¶еҸ°иҫ“еҮәеҗҜеҠЁesе®һдҫӢгҖӮ
./elasticsearch console
жӯӨж—¶дҪ еә”иҜҘдјҡ收еҲ°дёҖдёӘErrorзҡ„жҸҗзӨәпјҡ
WrapperSimpleApp Error: Unable to locate the class org.elasticsearch.bootstrap.ElasticsearchF : java.lang.ClassNotFoundException: org.elasticsearch.bootstrap.ElasticsearchF
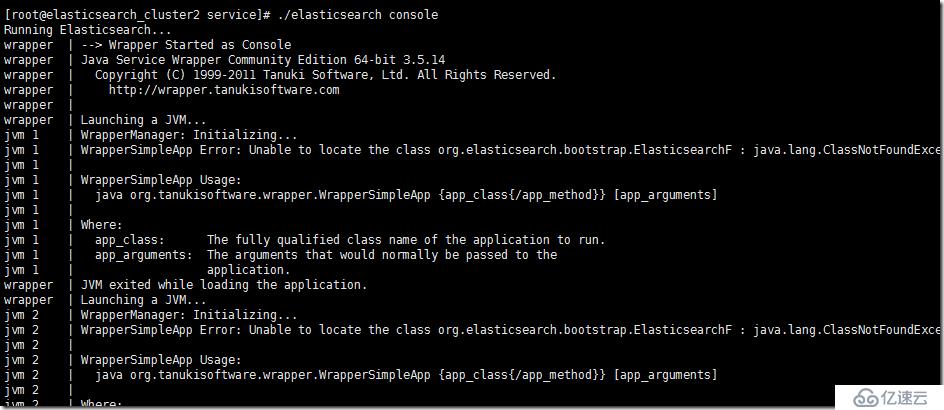
第дёҖж¬ЎзңӢеҲ°иҝҷдёӘжҲ‘жңүзӮ№и’ҷпјҢиҝҷдёӘElasticsearchFжҳҜдёӘд»Җд№ҲеҜ№иұЎгҖӮе‘ҪеҗҚжңүзӮ№зү№ж®ҠпјҢеҶҚиҝӣдёҖжӯҘжҹҘзңӢExceptionзҡ„дҝЎжҒҜпјҢе…¶е®һжҳҜдёҖдёӘClassNotFoundExceptionејӮеёёгҖӮиҜҙжҳҺжүҫдёҚеҲ°иҝҷдёӘElasticSearchFзұ»гҖӮ
дёӨз§ҚеҸҜиғҪжҖ§пјҢ第дёҖе°ұжҳҜjava elasticsearchзӣёе…іеҢ…зҡ„й—®йўҳпјҢзЎ®е®һзјәе°‘иҝҷдёӘзұ»гҖӮдҪҶжҳҜиҝҷдёӘеҸҜиғҪжҖ§еҫҲе°ҸпјҢеӣ дёәжҲ‘们д№ӢеүҚзӣҙжҺҘиҝҗиЎҢelasticsearchжҳҜжҲҗеҠҹзҡ„гҖӮжҲ‘еҪ“ж—¶з”Ёjd-guiзҝ»дәҶдёӢesзҡ„еҢ…пјҢзЎ®е®һжІЎжңүиҝҷдёӘзұ»гҖӮ
第дәҢе°ұжҳҜиҝҷйҮҢзҡ„й…ҚзҪ®й”ҷиҜҜпјҢеә”иҜҘе°ұдёӘжүӢиҜҜпјҢзЎ®е®һжІЎжңүElasticsearchFиҝҷдёӘзұ»гҖӮ
жҲ‘们жҹҘзңӢдёӢservice/elasticsearch.confй…ҚзҪ®ж–Ү件йҮҢжҳҜдёҚжҳҜжңүиҝҷдёӘвҖҳelasticsearchFвҖҷеӯ—з¬ҰдёІгҖӮпјҲwrapperеҢ…жҳҜдҪҝз”ЁеҪ“еүҚзӣ®еҪ•дёӢзҡ„elasticsearch.confдҪңдёәй…ҚзҪ®ж–Ү件дҪҝз”Ёзҡ„пјү
grep вҖ“i elasticsearchf elasticsearch.conf

зЎ®е®һжңүиҝҷдёӘеӯ—з¬ҰдёІпјҢжҲ‘们иҝӣиЎҢзј–иҫ‘дҝқеӯҳпјҢеҺ»жҺүжңҖеҗҺзҡ„вҖҳFвҖҷгҖӮ

然еҗҺжҲ‘们еңЁиҝӣиЎҢеҗҜеҠЁе°қиҜ•гҖӮ
./elasticsearch console
жҲ‘дёҚзҹҘйҒ“дҪ жҳҜдёҚжҳҜдјҡе’ҢжҲ‘зҡ„жғ…еҶөдёҖж ·пјҢжҸҗзӨәзӣёе…іе‘Ҫд»ӨйғҪжҳҜдёҚ规иҢғзҡ„гҖӮ
иҝҷдёӘиҝҗиЎҢй“ҫи·Ҝеҹәжң¬дёҠз»ҸиҝҮдёүдёӘи·Ҝеҫ„пјҢ第дёҖдёӘе°ұжҳҜservice/elasticsearch shellеҗҜеҠЁи„ҡжң¬пјҢ然еҗҺиҺ·еҸ–е‘Ҫд»ӨеҲҶжһҗе‘Ҫд»ӨеҶҚеҗҜеҠЁexecдёӢзҡ„зӣёе…іjava servicewrapperзЁӢеәҸгҖӮ
иҝҷдёӘjava servicewrapperзЁӢеәҸпјҢзүҲжң¬жҳҜ3.5.14гҖӮж №жҚ®дёҠиҝ°жҖқи·ҜпјҢйҖҡиҝҮжҹҘзңӢelasticsearch shellзЁӢеәҸпјҢе®ғеңЁжҺҘ收еҲ°еӨ–йғЁзҡ„е‘Ҫд»Өд№ӢеҗҺдјҡеҗҜеҠЁexecдёӢзҡ„java servicewrapperзЁӢеәҸгҖӮжҲ‘жғіиҜ•зқҖзј–иҫ‘дәҶдёӢelasticsearch shellж–Ү件пјҢиҫ“еҮәдёҖдәӣдҝЎжҒҜеҮәжқҘпјҢжҹҘзңӢдёӢжҳҜдёҚжҳҜиҺ·еҸ–зӣёе…іи·Ҝеҫ„жҲ–иҖ…еҸӮж•°д№Ӣзұ»зҡ„еҜјиҮҙй”ҷиҜҜгҖӮпјҲйҒҮеҲ°й—®йўҳдёҚжҖ•пјҢиҮіе°‘жҲ‘们иҰҒдёҖи·Ҝи·ҹдёӢеҺ»пјҢзңӢдёӢ究з«ҹжҳҜжҖҺд№ҲеӣһдәӢгҖӮпјү
vim ./elasticsearch
esc
:/console
жүҫдёӢconsoleеңЁе“ӘйҮҢпјҢ然еҗҺеҠ дёҠи°ғиҜ•ж–Үжң¬дҝЎжҒҜпјҢиҫ“еҮәеҲ°з•ҢйқўдёҠгҖӮ
еҶҚиҝҗиЎҢпјҢжҹҘзңӢе‘Ҫд»ӨеҸӮж•°жҳҜеҗҰжңүй—®йўҳгҖӮ

жҹҘзңӢдәҶдёӢпјҢиҫ“еҮәзҡ„еҸӮж•°еҹәжң¬йғҪжІЎжңүй—®йўҳгҖӮдёҖж—¶ж— и§ЈгҖӮеҘҪеҘҮеҝғдҪңжҖӘпјҢжң¬жғіеҶҚиҝӣдёҖжӯҘзңӢдёӢexec/elasticsearch-linux-x86-64.soж–Ү件зҡ„пјҢеҗҺжқҘеҸ‘зҺ°жү“ејҖж №жң¬е°ұзңӢдёҚжҮӮгҖӮжүҖд»Ҙе°ұеҸҰеҜ»е…¶д»–ж–№жі•пјҢжҲ‘жүҫдәҶwindowsзүҲжң¬servicewrapperпјҢеҸ‘зҺ°windowsзҡ„elasticsearchservicewrapperжҳҜжІЎжңү32дҪҚзҡ„servicewrapperзҡ„гҖӮжҲ‘иҜ•зқҖиҝҗиЎҢиө·жқҘеҹәжң¬дёҠд№ҹжҳҜжҠҘзӣёеҗҢзҡ„й”ҷиҜҜпјҢдҪҶжҳҜwindowsзҡ„wrapperзҡ„errorдҝЎжҒҜжҜ”иҫғеӨҡзӮ№пјҢжҸҗзӨәеҮәй”ҷзҡ„еҺҹеӣ еңЁе“ӘйҮҢгҖӮ
жҲ‘жғідҝ®ж”№дёӢж—Ҙеҝ—зҡ„иҫ“еҮәзә§еҲ«пјҢзңӢиғҪеҗҰиҫ“еҮәдёҖдәӣеҸҜд»Ҙз”Ёзҡ„дҝЎжҒҜгҖӮзј–иҫ‘service/elasticsearch.conf wrapperеҢ…дё“з”Ёй…ҚзҪ®гҖӮ
# Log Level for console output. (See docs for log levels)
wrapper.console.loglevel=TRACE
# Log Level for console output. (See docs for log levels)
wrapper.console.loglevel=TRACE
жҲ‘们е°Ҷж—Ҙеҝ—иҫ“еҮәзә§еҲ«и®ҫзҪ®жҲҗtraceпјҢжңүдёӨеӨ„йңҖиҰҒи®ҫзҪ®пјҢжҲ‘们еҶҚзңӢиҫ“еҮәдҝЎжҒҜгҖӮ
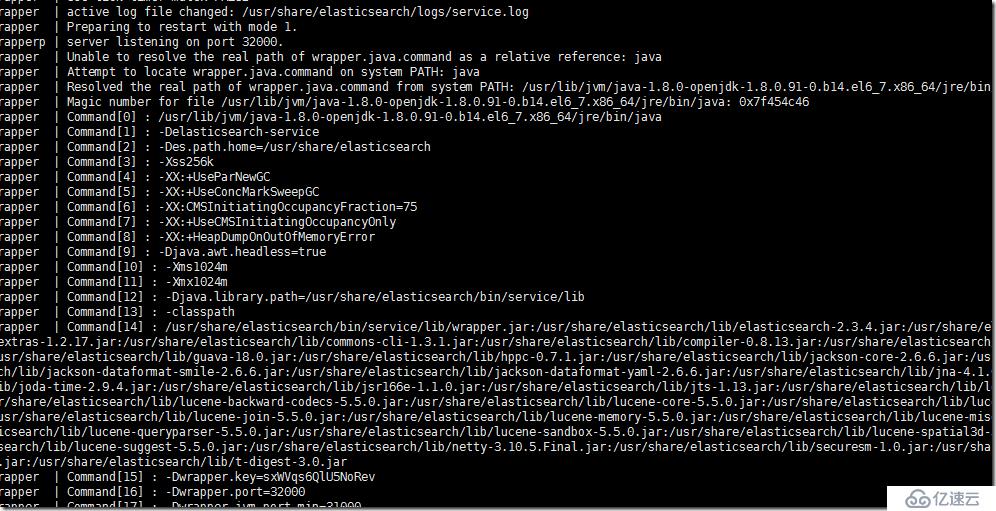
жҳҜиҫ“еҮәдәҶдёҖдәӣжңүз”Ёзҡ„дҝЎжҒҜпјҢеҸҜд»ҘжҹҘзңӢlogж–Ү件иҜҰжғ…гҖӮ
WrapperManager Debug: Received a packet LOGFILE : /usr/share/elasticsearch/logs/service.log
дҪҶжҳҜжңүе…ідәҺerrorзҡ„дҝЎжҒҜиҝҳжҳҜеҸӘжңүдёҖжқЎгҖӮ
иҝҷйҮҢе°ұе‘ҠдёҖж®өиҗҪгҖӮжҲ‘们зҡ„зӣ®зҡ„жҳҜдёәдәҶдҪҝз”ЁconsoleжқҘиҝҗиЎҢпјҢжғіжҹҘзңӢдёӢдёҖдәӣиҝҗиЎҢж—Ҙеҝ—пјҢдҪҶжҳҜи·‘дёҚиө·жқҘд№ҹж— жүҖи°“пјҢжҲ‘们继з»ӯжү§иЎҢе®үиЈ…ж“ҚдҪңгҖӮ
пјҲе“ӘдҪҚеҚҡеҸӢеҰӮжһңзҹҘйҒ“й—®йўҳеңЁе“ӘйҮҢзҡ„еҸҜд»ҘеҲҶдә«еҮәжқҘпјҢжҲ‘и§үеҫ—иҝҷдёӘй—®йўҳдёҚжҳҜдёҖдёӘеҒ¶еҸ‘жҖ§й—®йўҳпјҢеә”иҜҘйғҪдјҡйҒҮеҲ°гҖӮжҲ‘е…ҲжҠӣеҮәй—®йўҳпјҢиҮіе°‘еҸҜд»ҘжңҚеҠЎе°ҶжқҘзҡ„дҪҝз”ЁиҖ…гҖӮиҝҷйҮҢе…Ҳи°ўи°ўдәҶгҖӮпјү
е…¶е®һпјҢеҰӮжһңдҪ дёҚдҪҝз”Ёelasticsearch servicewrapperжқҘеҢ…иЈ…иҖҢжҳҜиҮӘе·ұеҺ»дёӢиҪҪjava serivcewrapperжқҘеҢ…иЈ…elasticsearchд№ҹжҳҜеҸҜд»Ҙзҡ„пјҢе®һзҺ°иө·жқҘд№ҹеҫҲж–№дҫҝгҖӮ
жҲ‘们еӣһеҲ°дё»йўҳпјҢ既然жҲ‘д»¬ж— жі•consoleиҝҗиЎҢпјҢд№ҹзңӢдёҚдәҶдёҖдәӣwrapper consoleжү§иЎҢж—¶зҡ„жғ…еҶөпјҢйӮЈжҲ‘们е°ұеҸӘиғҪиҝӣиЎҢе®үиЈ…дәҶгҖӮ
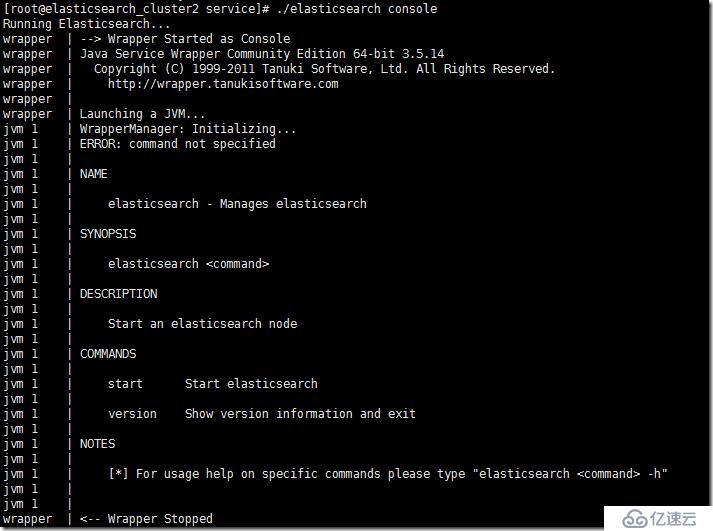
жҢүз…§elasticsearch servicewrapper parameterеҸӮж•°жҢҮзӨәпјҢжҲ‘们жү§иЎҢе®үиЈ…гҖӮ
./elasticsearch install
Installing the Elasticsearch daemon..
е®ҲжҠӨиҝӣзЁӢе®үиЈ…е®ҢжҲҗгҖӮжҲ‘们иҝҳжҳҜеүҚеҺ»зі»з»ҹзӣ®еҪ•дёӢжҹҘзңӢжҳҜдёҚжҳҜе®үиЈ…жҲҗеҠҹпјҲжҠҖжңҜдәәе‘ҳе§Ӣз»ҲдҝқжҢҒдёҖдёӘдёҘи°Ёзҡ„еҝғжҖҒжҳҜжңүеҝ…иҰҒзҡ„гҖӮпјүеүҚеҫҖ/etc/init.d/зӣ®еҪ•дёӢжҹҘзңӢгҖӮ
ll /etc/init.d/
-rwxrwxr--. 1 root root 4496 10жңҲ 4 01:43 elasticsearch
жҲ‘иҝҷйҮҢи®ҫзҪ®иҝҮchmod u+x ./elasticsearchгҖӮеҲ«еҝҳи®°и®ҫзҪ®ж–Ү件зҡ„жү§иЎҢжқғйҷҗпјҢиҝҷеңЁжҲ‘们гҖҗ2.1иҠӮгҖ‘йҮҢе°Ҷз»“жһңпјҢиҝҷйҮҢе°ұдёҚйҮҚеӨҚдәҶгҖӮ
жҲ‘们ејҖе§Ӣзј–иҫ‘elasticsearchеҗҜеҠЁж–Ү件гҖӮ
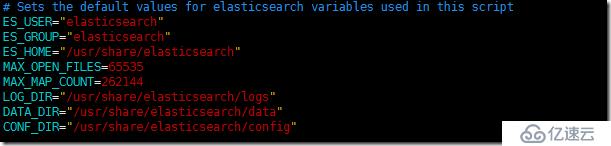
дё»иҰҒе°ұжҳҜиҝҷж®өпјҢеЎ«еҶҷеҘҪй…ҚзҪ®зҡ„esзҡ„дё“з”ЁиҙҰжҲ·пјҲelasticsearchгҖҗ2.2.иҠӮгҖ‘пјүпјҢиҝҳжңүзӣёеә”зҡ„ж–Ү件и·Ҝеҫ„гҖӮиҝҷйҮҢе…ҲеҝҪз•ҘMAX_OPEN_FILESгҖҒMAX_MAP_COUNTдёӨдёӘй…ҚзҪ®йЎ№пјҢеңЁеҗҺйқўгҖҗ3.3.иҠӮгҖ‘й…ҚзҪ®йғЁеҲҶдјҡи®Іи§ЈеҲ°гҖӮ
е°Ҷе…¶ж·»еҠ еҲ°зі»з»ҹжңҚеҠЎдёӯпјҢд»Ҙдҫҝиў«зі»з»ҹиҮӘеҠЁеҗҜеҠЁгҖӮ
chkconfig --add elasticsearch
chkconfig вҖ“list
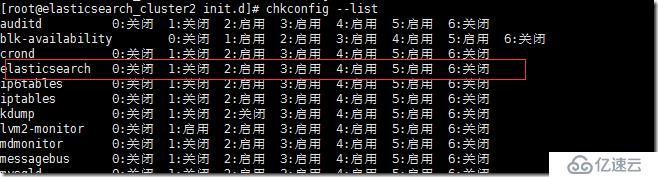
е·Із»Ҹж·»еҠ еҘҪзі»з»ҹиҮӘеҗҜеҠЁжңҚеҠЎеҲ—иЎЁдёӯгҖӮ
service elasticsearch start
еҗҜеҠЁesе®һдҫӢпјҢзӯүеҫ…з«ҜеҸЈеҗҜеҠЁе®ҢжҲҗпјҢзЁҚзӯүзүҮеҲ»жҹҘзңӢз«ҜеҸЈжғ…еҶөгҖӮ
netstat вҖ“tnl
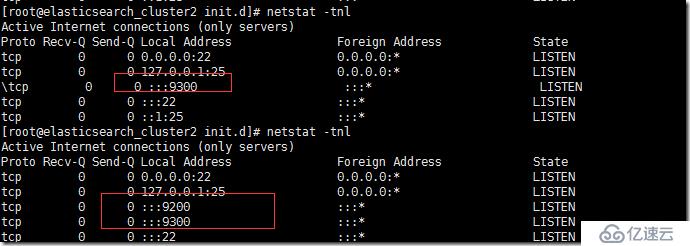
9300з«ҜеҸЈжҜ”9200з«ҜеҸЈе…ҲеҗҜеҠЁпјҢеӣ дёә9300з«ҜеҸЈжҳҜ clusterеҶ…йғЁз®ЎзҗҶз«ҜеҸЈгҖӮ9200жҳҜrest endpoint жңҚеҠЎз«ҜеҸЈгҖӮеҪ“然пјҢиҝҷдёӘж—¶й—ҙ延й•ҝдёҚдјҡеҫҲй•ҝгҖӮ
з«ҜеҸЈйғҪеҗҜеҠЁжҲҗеҠҹд№ӢеҗҺпјҢжҲ‘们жҹҘзңӢдёӢиғҪеҗҰжӯЈеёёи®ҝй—®esе®һдҫӢгҖӮ
curl -get http://192.168.0.103:9200/
{
"name" : "node-1",
"cluster_name" : "orderSearch_cluster",
"version" : {
"number" : "2.3.4",
"build_hash" : "e455fd0c13dceca8dbbdbb1665d068ae55dabe3f",
"build_timestamp" : "2016-06-30T11:24:31Z",
"build_snapshot" : false,
"lucene_version" : "5.5.0"
},
"tagline" : "You Know, for Search"
}
жҲ‘们иҝҳжҳҜдҪҝз”Ё_cat rest endpointжқҘжҹҘзңӢгҖӮ
curl -get http://192.168.0.103:9200/_cat/nodes
192.168.0.103 192.168.0.103 4 61 0.00 d * node-1
еҰӮжһңдҪ еҸҜд»ҘеңЁжң¬жңәи®ҝй—®пјҢдҪҶжҳҜеңЁеӨ–йғЁжөҸи§ҲеҷЁдёӯж— жі•и®ҝй—®пјҢеҫҲеҸҜиғҪжҳҜйҳІзҒ«еўҷзҡ„и®ҫзҪ®й—®йўҳпјҢдҪ еҸҜд»ҘеҺ»и®ҫзҪ®дёӢйҳІзҒ«еўҷгҖӮ
vim /etc/sysconfig/iptables
йҮҚеҗҜзҪ‘з»ңжңҚеҠЎпјҢд»ҘдҫҝеҠ иҪҪйҳІзҒ«еўҷи®ҫзҪ®йЎ№гҖӮ
service network restart
然еҗҺеҶҚе°қиҜ•зңӢиғҪеҗҰеӨ–йғЁи®ҝй—®пјҢеҰӮжһңдёҚиЎҢдҪ е°ұtelnetз«ҜеҸЈдёӢгҖӮ
еӣ дёәи®ҝй—®дёҚдәҶиҝҳжңүдёҖдёӘеҺҹеӣ жҳҜе’Ңelasticsearch.ymlдёҖдёӘй…ҚзҪ®йЎ№жңүе…ізі»гҖӮи§ҒгҖҗ3.1.1иҠӮгҖ‘гҖӮ
йҮҚеҗҜжңәеҷЁпјҢжҹҘзңӢesе®һдҫӢжҳҜеҗҰдјҡиҮӘеҠЁеҗҜеҠЁгҖӮ
shutdown вҖ“r now
зЁҚзӯүзүҮеҲ»пјҢ然еҗҺе°қиҜ•иҝһжҺҘжңәеҷЁгҖӮ
еҰӮжһңжІЎеҮәд»Җд№Ҳж„ҸеӨ–пјҢйғҪеә”иҜҘжӯЈеёёзҡ„пјҢз«ҜеҸЈд№ҹеҗҜеҠЁжҲҗеҠҹдәҶгҖӮиҜҙжҳҺжҲ‘们е®ҢжҲҗдәҶesе®һдҫӢиҮӘеҗҜеҠЁеҠҹиғҪпјҢе®ғзҺ°еңЁдҪңдёәlinuxзі»з»ҹжңҚеҠЎиў«иҮӘеҠЁз®ЎзҗҶгҖӮ
е®үиЈ…жҲҗжңҚеҠЎд№ӢеҗҺпјҢelasticsearch servicewrapperе’ҢжҲ‘们е°ұжІЎжңүеӨӘеӨҡе…ізі»дәҶгҖӮеӣ дёәе®ғзҡ„parameterйғҪжҳҜеӣҙз»•иҖ…жҲ‘们еҹәдәҺservicewrapperжқҘдҪҝз”Ёзҡ„гҖӮ
дёәдәҶеҫҲеҘҪзҡ„з®ЎзҗҶйӣҶзҫӨпјҢжҲ‘们йңҖиҰҒзӣёеә”зҡ„е·Ҙе…·пјҢheadжҳҜжҜ”иҫғжөҒиЎҢе’ҢйҖҡз”Ёзҡ„пјҢиҖҢдё”жҳҜе…Қиҙ№зҡ„гҖӮеҪ“然иҝҳжңүеҫҲеӨҡеҘҪз”Ёзҡ„е…¶д»–е·Ҙе…·пјҢеҰӮпјҢBigdeskгҖҒMarvelпјҲе•Ҷ用收иҙ№пјүгҖӮpluginзҡ„е®үиЈ…йғҪеӨ§еҗҢе°ҸејӮпјҢжҲ‘们иҝҷйҮҢе°ұдҪҝз”ЁйҖҡз”Ёзҡ„headе·Ҙе…·гҖӮ
е…ҲзңӢдёӢпјҢheadз»ҷжҲ‘们еёҰжқҘзҡ„жё…жҷ°зҡ„йӣҶзҫӨиҠӮзӮ№з®ЎзҗҶи§ҶеӣҫгҖӮ
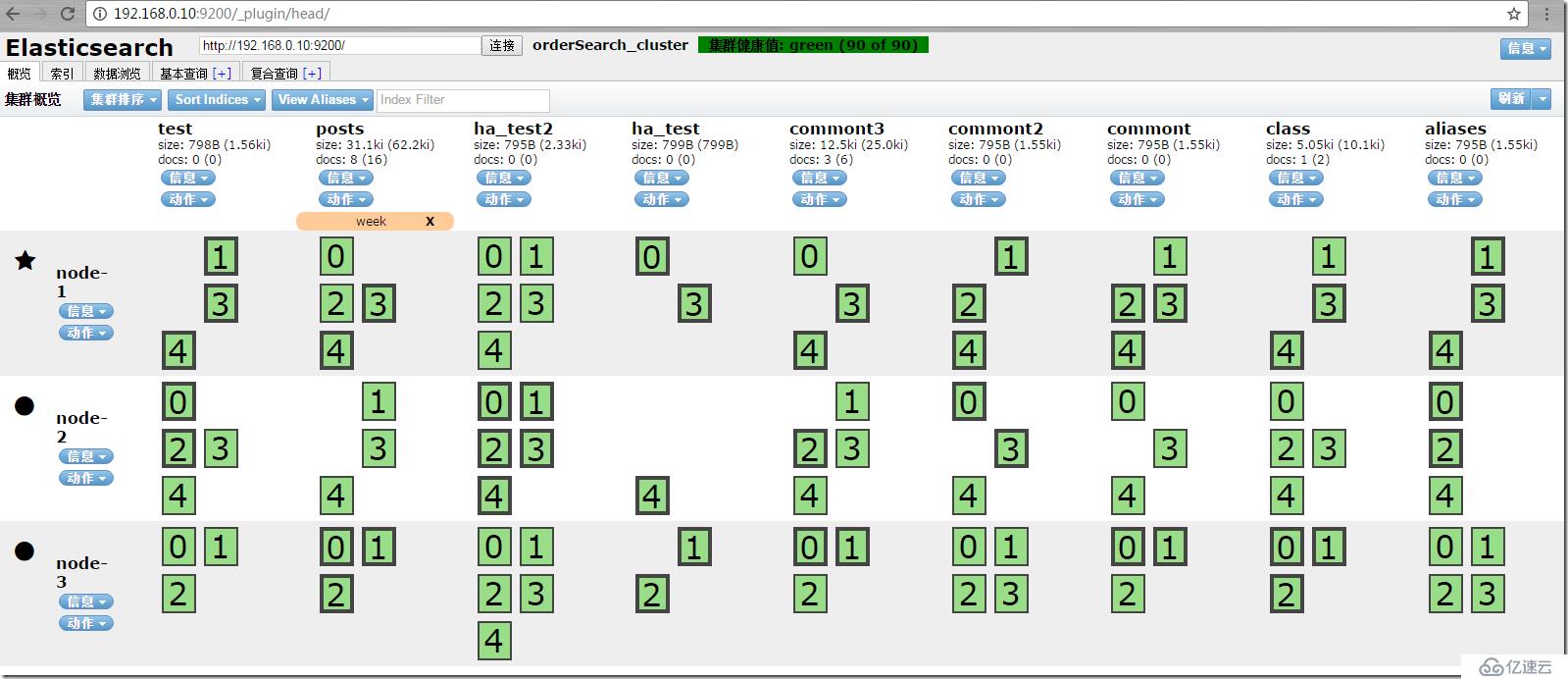
иҝҷжҳҜжңүдёүдёӘиҠӮзӮ№зҡ„esйӣҶзҫӨе®һдҫӢгҖӮе®ғжҳҜдёҖдёӘдәҢз»ҙзҹ©йҳөжҺ’еҲ—пјҢжңҖдёҠйқўжЁӘеҗ‘жҳҜзҙўеј•пјҢжңҖе·Ұиҫ№жҳҜиҠӮзӮ№пјҢдәӨеҸүзҡ„ең°ж–№жҳҜзҙўеј•зҡ„еҲҶзүҮдҝЎжҒҜе’ҢеҲҶзүҮжҜ”дҫӢгҖӮ
е®үиЈ…headжҸ’件иҝҳжҳҜжҜ”иҫғж–№дҫҝзҡ„пјҢдҪ д№ҹеҸҜд»ҘзӣҙжҺҘcopyж–Ү件зҡ„ж–№ејҸдҪҝз”ЁгҖӮеңЁelasticsearchзҡ„homeзӣ®еҪ•дёӢжңүдёҖдёӘpluginsзӣ®еҪ•пјҢе®ғжҳҜжүҖжңүжҸ’件зҡ„зӣ®еҪ•пјҢжүҖжңүзҡ„жҸ’件йғҪдјҡеңЁиҝҷдёӘж–Ү件еӨ№жҹҘжүҫе’ҢеҠ иҪҪгҖӮ
жҲ‘们зңӢдёӢе®үиЈ…headжҸ’件方法гҖӮеңЁelasticsearch/bin зӣ®еҪ•дёӢжңүдёҖдёӘpluginеҸҜжү§иЎҢж–Ү件пјҢе®ғжҳҜдё“й—Ёз”ЁжқҘе®үиЈ…жҸ’件用зҡ„зЁӢеәҸгҖӮ
./plugin -install mobz/elasticsearch-head
жҸ’件зҡ„жҹҘжүҫи·Ҝеҫ„жңүеҮ дёӘelasticsearchе®ҳзҪ‘жҳҜдёҖдёӘпјҢgithubжҳҜдёҖдёӘгҖӮиҝҷйҮҢдјҡе…Ҳе°қиҜ•еңЁgithubдёҠжҹҘжүҫпјҢзЁҚзӯүзүҮеҲ»пјҢзӯүеҫ…е®үиЈ…е®ҢжҲҗгҖӮжҲ‘们е°қиҜ•и®ҝй—®headжҸ’件ең°еқҖrestең°еқҖ/_plugin/headгҖӮ
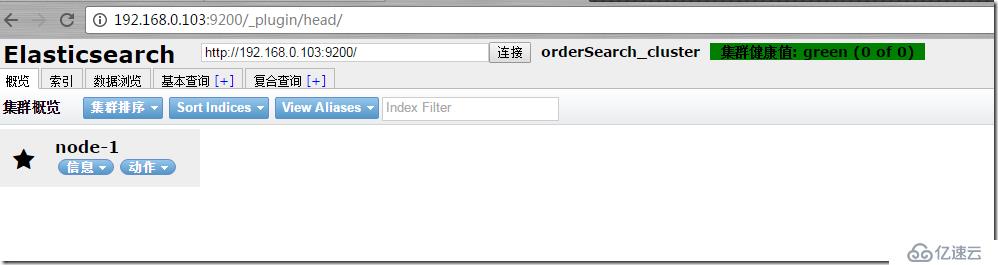
зңӢеҲ°иҝҷдёӘз•Ңйқўеҹәжң¬е®үиЈ…жҲҗеҠҹдәҶпјҢnode-1й»ҳи®ӨжҳҜmasterиҠӮзӮ№гҖӮ
chromдёӯжңүеҫҲеӨҡеҸҜд»ҘдҪҝз”Ёзҡ„elasticsearchе®ўжҲ·з«ҜжҸ’件пјҢдҫҝдәҺејҖеҸ‘е’Ңз»ҙжҠӨпјҢе»әи®®зӣҙжҺҘдҪҝз”Ёchromдёӯзҡ„жҸ’件гҖӮеҸӘиҰҒжҗңзҙўдёӢelasticsearchе…ій”®еӯ—е°ұдјҡеҮәжқҘеҫҲеӨҡгҖӮ

жңүдёӨдёӘжҜ”иҫғеёёз”ЁпјҢд№ҹжҜ”иҫғеҘҪз”ЁпјҢEalsticSearch ToolboxгҖҒSense(иҮӘеҠЁжҸҗзӨәdslзј–иҫ‘е·Ҙе…·пјүгҖӮchromжҸ’件йғҪжҳҜйӮЈд№Ҳзҡ„й…·пјҢдҪҝз”Ёиө·жқҘйғҪеҫҲиөҸеҝғжӮҰзӣ®гҖӮ
elasticsearch toolbox еҸҜд»ҘеҫҲж–№дҫҝзҡ„жҹҘиҜўе’ҢеҜјеҮәж•°жҚ®гҖӮ
senseеҸҜд»Ҙи®©дҪ зј–иҫ‘elasticsearch dsl зү№е®ҡиҜӯиЁҖдјҡжңүеҗҜеҠЁжҸҗзӨәеё®еҠ©пјҢиҝҷж ·зј–еҶҷиө·еӨҚжқӮзҡ„dslж•ҲзҺҮдјҡй«ҳиҖҢдё”дёҚжҳ“еҮәй”ҷгҖӮе…¶д»–зҡ„е·Ҙе…·жҲ‘д№ҹжІЎз”ЁиҝҮпјҢж„ҹи§үйғҪеҸҜд»Ҙе°қиҜ•з”Ёз”ЁзңӢгҖӮ
пјҲеӨҮжіЁпјҡеҰӮжһңдҪ ж— жі•и®ҝй—®chromе•Ҷеә—дёӯеҝғе°ұйңҖиҰҒзү№ж®ҠеӨ„зҗҶдёӢпјҢиҝҷйҮҢе°ұдёҚи§ЈйҮҠдәҶгҖӮпјү
еңЁдёҖдәӣзү№ж®Ҡзҡ„жғ…еҶөдёӢдҪ еҸҜиғҪж— жі•зӣҙжҺҘдҪҝз”ЁpluginжқҘеё®дҪ з®ЎзҗҶжҲ–иҖ…жҹҘзңӢйӣҶзҫӨжғ…еҶөгҖӮжӯӨж—¶дҪ еҸҜд»ҘзӣҙжҺҘдҪҝз”ЁelasticsearchиҮӘеёҰзҡ„rest _catжҹҘзңӢйӣҶзҫӨжғ…еҶөпјҢжҜ”еҰӮпјҢдҪ еҸҜиғҪеҸ‘зҺ°_plugin/headжңүдёҖдәӣиҠӮзӮ№жІЎжңүдёҠжқҘпјҢдҪҶжҳҜдҪ еҸҲдёҚзЎ®е®ҡеҸ‘з”ҹдәҶд»Җд№Ҳжғ…еҶөпјҢдҪ е°ұеҸҜд»ҘдҪҝз”Ё/_cat/nodesжқҘжҹҘзңӢжүҖжңүnodeзҡ„жғ…еҶөгҖӮжңүж—¶еҖҷзЎ®е®һжңүзҡ„иҠӮзӮ№жІЎжңүеҗҜеҠЁиө·жқҘпјҢдҪҶжҳҜеӨ§еӨҡж•°жғ…еҶөдёӢйғҪжҳҜеҗ„иҮӘдёәж”ҝпјҲи„‘иЈӮпјүпјҢдҪ еҸҜиғҪйңҖиҰҒ让他们йҮҚж–°йҖүдёҫжҲ–иҖ…еҠ еҝ«зҡ„йҖүдёҫиҝҮзЁӢгҖӮ
http://192.168.0.20:9200/_cat/nodes?v (жҹҘзңӢnodesжғ…еҶөпјү
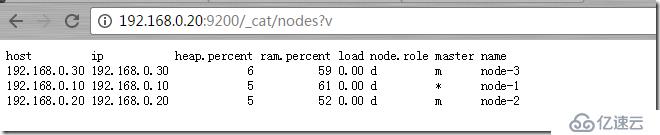
_cat restз«ҜзӮ№еёҰжңүдёҖдёӘvзҡ„еҸӮж•°пјҢиҝҷдёӘеҸӮж•°жҳҜеё®еҠ©дҪ йҳ…иҜ»зҡ„еҸӮж•°гҖӮ_search restз«ҜзӮ№еёҰжңүprettyеҸӮж•°пјҢиҝҷдёӘеҸӮж•°жҳҜеё®еҠ©жҹҘиҜўж•°жҚ®йҳ…иҜ»зҡ„гҖӮжҜҸдёҖдёӘз«ҜзӮ№еҹәжң¬дёҠйғҪжңүеҗ„иҮӘзҡ„иҫ…еҠ©йҳ…иҜ»еҸӮж•°гҖӮ
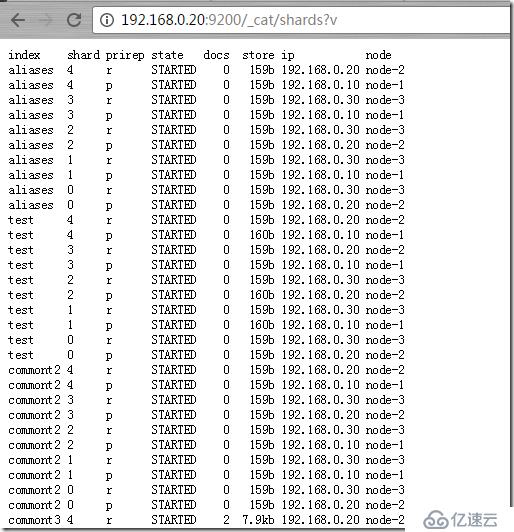
http://192.168.0.20:9200/_cat/shards?vпјҲжҹҘзңӢshardsжғ…еҶөпјү
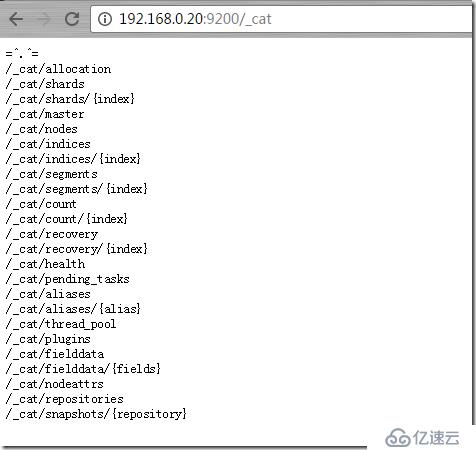
http://192.168.0.20:9200/_cat/ пјҲжҹҘзңӢжүҖжңүеҸҜд»Ҙcatзҡ„еҠҹиғҪпјү
дҪ еҸҜд»ҘжҹҘзңӢзі»з»ҹ aliasesеҲ«еҗҚгҖҒsegmentsзүҮж®өпјҲзңӢдёӢжҜҸдёӘзүҮж®өзҡ„жҸҗдәӨзүҲжң¬дёҖиҮҙжҖ§пјүгҖҒindicesзҙўеј•йӣҶеҗҲзӯүзӯүгҖӮ
еҪ“жҲ‘们е®ҢжҲҗдәҶеҜ№дёҖеҸ°жңәеҷЁзҡ„е®үиЈ…д№ӢеҗҺпјҢжҺҘдёӢжқҘе°ұйңҖиҰҒжҗӯе»әеҲҶеёғејҸзі»з»ҹгҖӮеҲҶеёғејҸзі»з»ҹе°ұйңҖиҰҒеӨҡиҠӮзӮ№жңәеҷЁпјҢжҢүз…§esеҲҶеёғејҸйӣҶзҫӨжҗӯе»әжңҖдҪіе®һи·өпјҢдҪ иҮіе°‘йңҖиҰҒдёүдёӘиҠӮзӮ№гҖӮжүҖд»ҘжҲ‘们е°Ҷе·Із»Ҹе®үиЈ…е®ҢжҲҗзҡ„иҝҷдёӘжңәеҷЁcloneеҮәжқҘдёӨеҸ°пјҢдёҖе…ұдёүеҸ°з»„жҲҗеҸҜд»Ҙе·ҘдҪңзҡ„дёүдёӘиҠӮзӮ№зҡ„еҲҶеёғејҸзі»з»ҹгҖӮ
йҰ–е…ҲcloneеҪ“еүҚе®үиЈ…е®ҢжҲҗзҡ„жңәеҷЁпјҢ192.168.0.103пјҢcloneеҘҪд№ӢеҗҺеҗҜеҠЁиө·жқҘдҝ®ж”№еҮ дёӘй…ҚзҪ®еҚіеҸҜгҖӮпјҲеӣ дёәдҪ жҳҜcloneеҮәжқҘзҡ„пјҢжүҖд»Ҙй…ҚзҪ®е·Із»ҸйҮҚеӨҚпјҢжҜ”еҰӮпјҢзҪ‘еҚЎең°еқҖгҖҒIPең°еқҖпјү
зј–иҫ‘зҪ‘еҚЎй…ҚзҪ®ж–Ү件пјҡ
vim /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE=eth4
HWADDR=00:0C:29:CF:48:23
TYPE=Ethernet
UUID=b848e750-d491-4c9d-b2ca-c853f21bf40b
ONBOOT=yes
NM_CONTROLLED=yes
BOOTPROTO=static
BROADCAST=192.168.233.255
IPADDR=192.168.0.103
NETMASK=255.255.255.0
GATEWAY=192.168.0.1
DEVICE жҳҜзҪ‘еҚЎж ҮзӨәпјҢж №жҚ®дҪ жң¬ең°зҡ„зҪ‘еҚЎж ҮиҜҶдҝ®ж”№жҲҗеҜ№еә”зҡ„еҚіеҸҜпјҢеҸҜд»ҘйҖҡиҝҮifconfigжҹҘзңӢгҖӮHWADDRзҪ‘еҚЎең°еқҖпјҢйҡҸж„Ҹдҝ®ж”№дёӢпјҢдҝқиҜҒеңЁдҪ зҡ„зҪ‘ж®өеҶ…дёҚйҮҚеӨҚеҚіеҸҜгҖӮUUIDд№ҹжҳҜе’ҢHWADDRдёҖж ·дҝ®ж”№гҖӮ
IPең°еқҖдҝ®ж”№жҲҗдҪ иҮӘе·ұи§үеҫ—еҗҲйҖӮзҡ„IPпјҢжңҖеҘҪеҸӮиҖғдҪ еҪ“еүҚзү©зҗҶжңәеҷЁзҡ„зӣёе…ій…ҚзҪ®гҖӮGATEWAYзҪ‘е…іең°еқҖиҰҒеҸӮиҖғдҪ зү©зҗҶжңәеҷЁзҡ„зҪ‘е…іең°еқҖпјҢеҰӮжһңдҪ зҡ„иҷҡжӢҹжңәдҪҝз”Ёзҡ„жҳҜжЎҘжҺҘжЁЎејҸзҡ„зҪ‘з»ңиҝһжҺҘпјҢиҝҷйҮҢе°ұйңҖиҰҒи®ҫзҪ®пјҢиҰҒдёҚ然зҪ‘з»ңе°ұиҝһжҺҘдёҚдёҠгҖӮ
йҮҚеҗҜзҪ‘з»ңжңҚеҠЎпјҡ
service network restart
зЁҚзӯүзүҮеҲ»пјҢsshйҮҚж–°иҝһжҺҘпјҢ然еҗҺifconfigзңӢдёӢзҪ‘з»ңзӣёе…іеҸӮж•°жҳҜеҗҰжӯЈзЎ®пјҢжңҖеҗҺеҶҚpingдёҖдёӢеӨ–йғЁзҪ‘еқҖе’ҢдҪ еҪ“еүҚзү©зҗҶжңәеҷЁзҡ„IPпјҢдҝқиҜҒзҪ‘з»ңйғҪжҳҜйҖҡз•…зҡ„гҖӮ
жңҖеҗҺжҲ‘们йңҖиҰҒдҝ®ж”№дёӢlinuxзҡ„зі»з»ҹж—¶й—ҙпјҢиҝҷжҳҜдёәдәҶйҳІжӯўжңҚеҠЎеҷЁж—¶й—ҙдёҚдёҖиҮҙпјҢеҜјиҮҙеҫҲеӨҡз»Ҷеҫ®зҡ„й—®йўҳпјҢжҜ”еҰӮпјҢesйӣҶзҫӨmasterйҖүдёҫзҡ„ж—¶й—ҙжҲій—®йўҳгҖҒlog4jиҫ“еҮәзҡ„ж—Ҙеҝ—зҡ„и®°еҪ•й—®йўҳзӯүзӯүгҖӮеңЁеҲҶеёғејҸзі»з»ҹдёӯпјҢж—¶й’ҹйқһеёёйҮҚиҰҒгҖӮ
date -s '20161008 20:47:00'
ж—¶еҢәзҡ„иҜқеҰӮжһңдҪ йңҖиҰҒд№ҹеҸҜд»Ҙи®ҫзҪ®пјҢиҝҷйҮҢжҡӮж—¶дёҚйңҖиҰҒгҖӮ
ж №жҚ®дҪ иҮӘе·ұзҡ„йңҖиҰҒпјҢдҪ cloneеҮ еҸ°жңәеҷЁгҖӮжҢүз…§й»ҳи®Өзҡ„ж–№ејҸжҲ‘们еӨ§жҰӮзәҰе®ҡдёәпјҢ192.168.0.10гҖҒ192.168.0.20гҖҒ192.168.0.30пјҢиҝҷдёүеҸ°жңәеҷЁе°Ҷз»„жҲҗдёҖдёӘesеҲҶеёғејҸйӣҶзҫӨгҖӮ
йӣҶзҫӨзҡ„еҗ„дёӘиҠӮзӮ№жҲ‘们已з»ҸеҮҶеӨҮеҘҪдәҶпјҢжҲ‘们жҺҘдёӢжқҘеҮҶеӨҮй…ҚзҪ®йӣҶзҫӨпјҢи®©иҝҷдёүдёӘиҠӮзӮ№еҸҜд»ҘиҝһжҺҘеңЁдёҖиө·гҖӮиҝҷйҮҢж¶үеҸҠзҡ„й…ҚзҪ®жҜ”иҫғз®ҖеҚ•пјҢеҸӘжҳҜе®ҢжҲҗйӣҶзҫӨзҡ„дёҖдёӘеҹәжң¬еёёз”ЁеҠҹиғҪпјҢеҰӮжңүзү№ж®Ҡзҡ„йңҖжұӮеҸҜд»ҘиҮӘиЎҢжҹҘзңӢelasticsearchе®ҳзҪ‘жҲ–иҖ…зҷҫеәҰпјҢиҝҷж–№йқўзҡ„иө„ж–ҷе·Із»ҸеҫҲдё°еҜҢдәҶгҖӮ
иҝҷйҮҢзҡ„дёҖдәӣй…ҚзҪ®жҲ‘们其е®һе·Із»ҸеҸ—зӣҠдәҺelasticsearch servicewrapperз®ҖеҢ–дәҶеҫҲеӨҡгҖӮ
д»ҺиҝҷйҮҢејҖе§ӢпјҢжҲ‘们е°ҶеҜ№дёүеҸ°жңәеҷЁиҝӣиЎҢй…ҚзҪ®пјҢ192.168.160.10гҖҒ192.168.160.20гҖҒ192.168.160.30гҖӮ
еңЁelasticsearchзҡ„configзӣ®еҪ•дёӢйғҪжҳҜй…ҚзҪ®ж–Ү件гҖӮеҜјиҲӘеҲ° cd /usr/share/elasticsearch/configзӣ®еҪ•гҖӮ
иҝҷйҮҢжңүдёӨдёӘйңҖиҰҒжҸҗйҶ’дёӢпјҢ第дёҖдёӘе°ұжҳҜIPи®ҝй—®йҷҗеҲ¶пјҢ第дәҢдёӘе°ұжҳҜesе®һдҫӢзҡ„й»ҳи®Өз«ҜеҸЈеҸ·9200гҖӮIPи®ҝй—®йҷҗеҲ¶еҸҜд»Ҙйҷҗе®ҡе…·дҪ“зҡ„IPи®ҝй—®жңҚеҠЎеҷЁпјҢиҝҷжңүдёҖе®ҡзҡ„е®үе…ЁиҝҮж»ӨдҪңз”ЁгҖӮ
# Set the bind address to a specific IP (IPv4 or IPv6):
#
network.host: 0.0.0.0
еҰӮжһңи®ҫзҪ®жҲҗ0.0.0.0еҲҷжҳҜдёҚйҷҗеҲ¶д»»дҪ•IPи®ҝй—®гҖӮдёҖиҲ¬еңЁз”ҹдә§зҡ„жңҚеҠЎеҷЁеҸҜиғҪдјҡйҷҗе®ҡеҮ еҸ°IPпјҢйҖҡеёёз”ЁдәҺз®ЎзҗҶдҪҝз”ЁгҖӮ
й»ҳи®Өзҡ„з«ҜеҸЈ9200еңЁдёҖиҲ¬жғ…еҶөдёӢд№ҹжңүзӮ№йЈҺйҷ©пјҢеҸҜд»Ҙе°Ҷй»ҳи®Өзҡ„з«ҜеҸЈдҝ®ж”№жҲҗеҸҰеӨ–дёҖдёӘпјҢиҝҷиҝҳжңүдёҖдёӘеҺҹеӣ е°ұжҳҜжҖ•ејҖеҸ‘дәәе‘ҳиҜҜж“ҚдҪңпјҢиҝһжҺҘдёҠйӣҶзҫӨгҖӮеҪ“然пјҢеҰӮжһңдҪ зҡ„е…¬еҸёзҪ‘з»ңйҡ”зҰ»еҒҡзҡ„еҫҲеҘҪд№ҹж— жүҖи°“гҖӮ
#
# Set a custom port for HTTP:
#
http.port: 9200
transport.tcp.port: 9300
иҝҷйҮҢзҡ„9300жҳҜйӣҶзҫӨеҶ…йғЁйҖҡи®ҜдҪҝз”Ёзҡ„з«ҜеҸЈпјҢиҝҷдёӘд№ҹеҸҜд»Ҙдҝ®ж”№жҺүгҖӮеӣ дёәиҝһжҺҘйӣҶзҫӨзҡ„ж–№ејҸжңүдёӨз§ҚпјҢйҖҡиҝҮжү®жј”йӣҶзҫӨnodeд№ҹжҳҜеҸҜд»Ҙиҝӣе…ҘйӣҶзҫӨзҡ„пјҢжүҖд»ҘиҝҳжҳҜе®үе…Ёиө·и§ҒпјҢдҝ®ж”№жҺүй»ҳи®Өзҡ„з«ҜеҸЈгҖӮ
пјҲеӨҮжіЁпјҡи®°еҫ—дҝ®ж”№дёүдёӘиҠӮзӮ№зҡ„зӣёеҗҢй…ҚзҪ®пјҢиҰҒдёҚ然иҠӮзӮ№д№Ӣй—ҙж— жі•е»әз«ӢиҝһжҺҘе·ҘдҪңпјҢд№ҹдјҡжҠҘй”ҷгҖӮпјү
зҙ§жҺҘзқҖдҝ®ж”№йӣҶзҫӨиҠӮзӮ№IPең°еқҖпјҢиҝҷж ·еҸҜд»Ҙи®©йӣҶзҫӨеңЁи§„е®ҡзҡ„еҮ дёӘиҠӮзӮ№д№Ӣй—ҙе·ҘдҪңгҖӮelasticsearchпјҢй»ҳи®ӨжҳҜдҪҝз”ЁиҮӘеҠЁеҸ‘зҺ°IPжңәеҲ¶гҖӮе°ұжҳҜеңЁеҪ“еүҚзҪ‘ж®өеҶ…пјҢеҸӘиҰҒиғҪиў«иҮӘеҠЁж„ҹзҹҘеҲ°зҡ„IPе°ұиғҪиҮӘеҠЁеҠ е…ҘеҲ°йӣҶзҫӨдёӯгҖӮиҝҷжңүеҘҪеӨ„д№ҹжңүеқҸеӨ„гҖӮеҘҪеӨ„е°ұжҳҜиҮӘеҠЁеҢ–дәҶпјҢеҪ“дҪ зҡ„esйӣҶзҫӨйңҖиҰҒдә‘еҢ–зҡ„ж—¶еҖҷе°ұдјҡйқһеёёж–№дҫҝгҖӮдҪҶжҳҜд№ҹдјҡеёҰжқҘдёҖдәӣдёҚзЁіе®ҡзҡ„жғ…еҶөпјҢеҰӮпјҢmasterзҡ„йҖүдёҫй—®йўҳгҖҒж•°жҚ®еӨҚеҲ¶й—®йўҳгҖӮ
еҜјиҮҙmasterйҖүдёҫзҡ„еӣ зҙ д№ӢдёҖе°ұжҳҜйӣҶзҫӨжңүиҠӮзӮ№иҝӣе…ҘгҖӮеҪ“ж•°жҚ®еӨҚеҲ¶еҸ‘з”ҹзҡ„ж—¶еҖҷд№ҹдјҡеҪұе“ҚйӣҶзҫӨпјҢеӣ дёәиҰҒеҒҡж•°жҚ®е№іиЎЎеӨҚеҲ¶е’ҢеҶ—дҪҷгҖӮиҝҷйҮҢйқўеҸҜд»ҘзӢ¬з«ӢmasterйӣҶзҫӨпјҢеү”йҷӨmasterйӣҶзҫӨзҡ„ж•°жҚ®иҠӮзӮ№иғҪеҠӣгҖӮ
еӣәе®ҡеҲ—иЎЁзҡ„IPеҸ‘зҺ°жңүдёӨз§Қй…ҚзҪ®ж–№ејҸпјҢдёҖз§ҚжҳҜдә’зӣёдҫқиө–еҸ‘зҺ°пјҢдёҖз§ҚжҳҜе…ЁйҮҸеҸ‘зҺ°гҖӮеҗ„жңүдјҳеҠҝеҗ§пјҢжҲ‘жҳҜдҪҝз”Ёзҡ„дҫқиө–еҸ‘зҺ°жқҘеҒҡзҡ„гҖӮиҝҷжңүдёӘеҫҲйҮҚиҰҒзҡ„еҸӮиҖғж ҮеҮҶпјҢе°ұжҳҜдҪ зҡ„йӣҶзҫӨжү©еұ•йҖҹеәҰжңүеӨҡеҝ«гҖӮеӣ дёәиҝҷжңүдёӘй—®йўҳе°ұжҳҜпјҢеҪ“е…ЁйҮҸеҸ‘зҺ°зҡ„ж—¶еҖҷпјҢеҰӮжһңжҳҜеҲқе§ӢеҢ–йӣҶзҫӨдјҡжңүеҫҲеӨ§зҡ„й—®йўҳпјҢе°ұжҳҜmasterе…ЁеұҖдјҡеҫҲй•ҝпјҢ然еҗҺиҠӮзӮ№д№Ӣй—ҙзҡ„еҗҜеҠЁйҖҹеәҰеҗ„дёҚдёҖж ·гҖӮжүҖд»ҘжҲ‘йҮҮз”ЁдәҶйқ и°ұзӮ№зҡ„дҫқиө–еҸ‘зҺ°гҖӮ
дҪ йңҖиҰҒеңЁ192.168.0.20зҡ„elasticsearchдёӯй…ҚзҪ®жҲҗпјҡ
# --------------------------------- Discovery ----------------------------------
#
# Pass an initial list of hosts to perform discovery when new node is started:
# The default list of hosts is ["127.0.0.1", "[::1]"]
#
discovery.zen.ping.unicast.hosts: [ "192.168.0.10:9300" ]
и®©д»–еҺ»еҸ‘зҺ°10зҡ„жңәеҷЁпјҢд»ҘжӯӨеҶ…жҺЁпјҢе®ҢжҲҗеү©дёӢзҡ„30зҡ„й…ҚзҪ®гҖӮ
пјҲеӨҮжіЁпјҡзҪ‘дёҠжңүеҫҲеӨҡй’ҲеҜ№дёҚеҗҢеңәжҷҜзҡ„еҸ‘зҺ°й…ҚзҪ®пјҢеӨ§е®¶еҸҜд»Ҙе°ұжӯӨжҠӣз –еј•зҺүпјҢеҜ№иҝҷдёӘдё»йўҳж„ҹе…ҙи¶Јзҡ„еҸҜд»ҘзҷҫеәҰеҫҲеӨҡиө„ж–ҷзҡ„гҖӮпјү
然еҗҺдҪ йңҖиҰҒй…ҚзҪ®дёӢйӣҶзҫӨеҗҚз§°пјҢе°ұжҳҜдҪ еҪ“еүҚиҠӮзӮ№жүҖеңЁйӣҶзҫӨзҡ„еҗҚз§°пјҢиҝҷжңүеҠ©дәҺдҪ 规еҲ’дҪ зҡ„йӣҶзҫӨгҖӮеҸӘжңүйӣҶзҫӨеҗҚз§°дёҖж ·жүҚиғҪз»„жҲҗдёҖдёӘйҖ»иҫ‘йӣҶзҫӨгҖӮ
# ---------------------------------- Cluster -----------------------------------
#
# Use a descriptive name for your cluster:
#
cluster.name: orderSearch_cluster
#
# ------------------------------------ Node ------------------------------------
#
# Use a descriptive name for the node:
#
node.name: node-2
д»ҘжӯӨзұ»жҺЁпјҢе®ҢжҲҗеҸҰеӨ–дёӨдёӘиҠӮзӮ№зҡ„й…ҚзҪ®гҖӮcluster.nameзҡ„еҗҚз§°еҝ…йЎ»дҝқжҢҒдёҖж ·гҖӮ然еҗҺеҲҶеҲ«и®ҫзҪ®node.nameгҖӮ
иҝҷйҮҢжңүдёҖдёӘе°Ҹе°Ҹзҡ„з»ҸйӘҢеҲҶдә«дёӢпјҢе°ұжҳҜжҲ‘еңЁдҪҝз”ЁйӣҶзҫӨзҡ„ж—¶еҖҷпјҢеӣ дёәжҲ‘жҳҜиҷҡжӢҹеҢ–еҮәжқҘзҡ„жңәеҷЁжүҖд»Ҙз»Ҹеёёдјҡе…ій—ӯе’ҢйҮҚеҗҜйӣҶзҫӨгҖӮжңүж—¶еҖҷеҸ‘зҺ°йӣҶзҫӨmasterе®Јй…’дјҡжңүдёҖдёӘй—®йўҳе°ұжҳҜпјҢеҰӮжһңдҪ зҡ„йӣҶзҫӨе…ій—ӯзҡ„ж–№ејҸдёҚеҜ№пјҢдјҡзӣҙжҺҘеҪұе“ҚдёӢдёӘmasterйҖүдёҫзҡ„йҖ»иҫ‘гҖӮ
жҲ‘жҹҘдәҶдёӢйҖүдёҫзҡ„еӨ§жҰӮйҖ»иҫ‘пјҢе®ғдјҡж №жҚ®еҲҶзүҮзҡ„ж•°жҚ®зҡ„еүҚеҗҺж–°йІңзЁӢеәҰжқҘдҪңдёәйҖүдёҫзҡ„дёҖдёӘйҮҚиҰҒйҖ»иҫ‘гҖӮпјҲж—Ҙеҝ—гҖҒж•°жҚ®гҖҒж—¶й—ҙйғҪдјҡдҪңдёәйӣҶзҫӨmasterе…ЁеұҖзҡ„йҮҚиҰҒжҢҮж Үпјү
еӣ дёәиҖғиҷ‘еҲ°ж•°жҚ®дёҖиҮҙжҖ§й—®йўҳпјҢеҪ“然жҳҜз”ЁжңҖж–°зҡ„ж•°жҚ®иҠӮзӮ№дҪңдёәmasterпјҢ然еҗҺиҝӣиЎҢж–°ж•°жҚ®зҡ„еӨҚеҲ¶е’ҢеҲ·ж–°е…¶д»–nodeгҖӮ
еҰӮжһңдҪ еҸ‘зҺ°жңүдёҖдёӘиҠӮзӮ№иҝҹиҝҹиҝӣдёҚдәҶйӣҶзҫӨпјҢеҸҜд»Ҙе°қиҜ•йҮҚеҗҜдёӢesжңҚеҠЎпјҢи®©йӣҶзҫӨmasterйҮҚж–°е…ЁеұҖгҖӮ
еңЁlinuxзі»з»ҹдёӯпјҢиҰҒжғідҪҝз”ЁжңҖеӨ§еҢ–зҡ„зі»з»ҹиө„жәҗйңҖиҰҒеҗ‘ж“ҚдҪңзі»з»ҹеҺ»з”іиҜ·гҖӮз”ұдәҺelasticsearchйңҖиҰҒеңЁindexзҡ„ж—¶еҖҷз”ЁеҲ°еӨ§йҮҸзҡ„ж–Ү件еҸҘжҹ„иө„жәҗпјҢеңЁеҺҹжқҘlinuxй»ҳи®Өзҡ„иө„жәҗдёӢеҸҜиғҪдјҡдёҚеӨҹз”ЁгҖӮжүҖд»ҘиҝҷйҮҢе°ұйңҖиҰҒжҲ‘们еңЁдҪҝз”Ёзҡ„ж—¶еҖҷдәӢе…Ҳи®ҫзҪ®еҘҪгҖӮ
иҝҷдёӘй…ҚзҪ®еңЁгҖҠElasticSearch еҸҜжү©еұ•зҡ„ејҖжәҗеј№жҖ§жҗңзҙўи§ЈеҶіж–№жЎҲгҖӢдёҖд№ҰдёӯдҪңдёәйҮҚзӮ№й…ҚзҪ®д»Ӣз»ҚпјҢеҸҜжғіиҖҢзҹҘиҝҳжҳҜжңүдёҚе°‘дәәиё©еҲ°иҝҮзҡ„еқ‘гҖӮ
иҝҷдёӘй…ҚзҪ®еңЁelasticsearch service wrapperдёӯеё®жҲ‘们й…ҚзҪ®еҘҪдәҶгҖӮ
vim /etc/init.d/elasticsearch
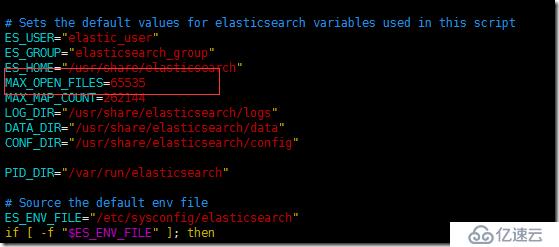
иҝҷдёӘй…ҚзҪ®дјҡиў«еҗҜеҠЁзҡ„ж—¶еҖҷи®ҫзҪ®еҲ°esе®һдҫӢдёӯеҺ»гҖӮ
иҝҷдёӘж—¶еҖҷиҜ•зқҖйҮҚеҗҜдёүеҸ°жңәеҷЁзҡ„esе®һдҫӢпјҢзңӢиғҪдёҚиғҪеңЁ_plugin/headдёӯжҹҘзңӢеҲ°дёүеҸ°жңәеҷЁзҡ„йӣҶзҫӨзҠ¶жҖҒгҖӮпјҲи®°еҫ—и®ҝй—®е®үиЈ…дәҶheadжҸ’件зҡ„йӮЈеҸ°жңәеҷЁпјҢжҲ‘иҝҷйҮҢжҳҜеңЁ10жңәеҷЁдёҠе®үиЈ…зҡ„пјү
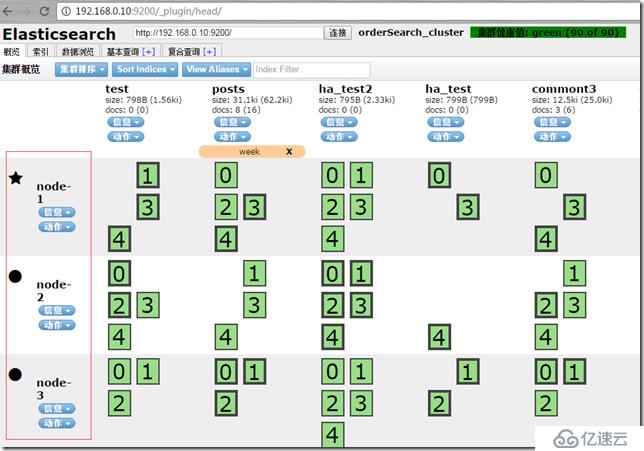
зәўиүІзҡ„е°ұжҳҜдҪ и®ҫзҪ®зҡ„node.nameиҠӮзӮ№еҗҚз§°пјҢ他们еңЁдёҖдёӘйӣҶзҫӨйҮҢе·ҘдҪңгҖӮ
жӯӨж—¶йӣҶзҫӨеә”иҜҘеҸҜд»Ҙе·ҘдҪңдәҶпјҢжҲ‘们иҝҳйңҖиҰҒй…ҚзҪ®дёӯж–ҮеҲҶиҜҚеҷЁпјҢжҜ•з«ҹжҲ‘们дҪҝз”Ёзҡ„дёӯж–ҮпјҢelasticsearchзҡ„иҮӘеёҰзҡ„еҲҶиҜҚеҷЁеҜ№дёӯж–ҮеҲҶиҜҚж”ҜжҢҒзҡ„дёҚеӨӘйҖӮеҗҲжң¬еңҹгҖӮ
жҲ‘жҳҜдҪҝз”Ёзҡ„ikеҲҶиҜҚеҷЁпјҢеңЁgithubдёҠзҡ„ең°еқҖпјҡhttps://github.com/medcl/elasticsearch-analysis-ik
е…ҲеҲ«жҖҘзҡ„cloneпјҢжҲ‘们е…ҲжқҘзңӢдёӢikеҲҶиҜҚеҷЁжүҖж”ҜжҢҒзҡ„elasticsearchеҜ№еә”зҡ„зүҲжң¬гҖӮ
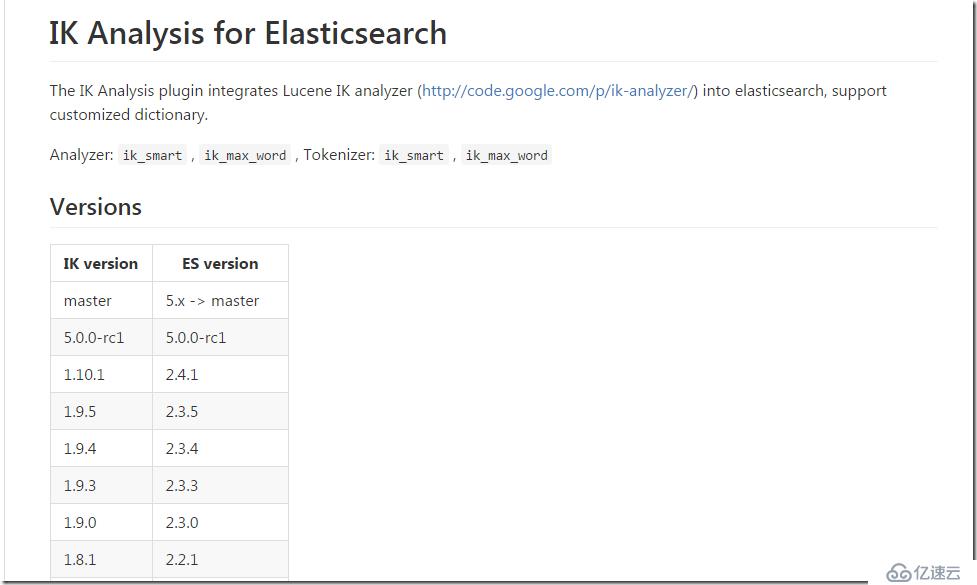
жҲ‘们дҪҝз”Ёзҡ„elasticsearchзүҲжң¬дёә2.3.4гҖӮжүҖд»ҘжҲ‘们иҰҒжүҫеҜ№еә”зҡ„ikзүҲжң¬пјҢиҰҒдёҚ然еҗҜеҠЁзҡ„ж—¶еҖҷе°ұзӣҙжҺҘжҠҘеҠ иҪҪдёҚдәҶеҜ№еә”зүҲжң¬зҡ„ikжҸ’件гҖӮеҲҮжҚўеҲ°releaseзүҲжң¬еҲ—иЎЁпјҢжүҫеҲ°еҜ№еә”зҡ„зүҲжң¬з„¶еҗҺдёӢиҪҪдёӢжқҘгҖӮ
дҪ еҸҜд»ҘзӣҙжҺҘдёӢиҪҪеҲ°LinuxжңәеҷЁдёҠпјҢд№ҹеҸҜд»ҘдёӢиҪҪеҲ°дҪ зҡ„е®ҝдё»жңәеҷЁдёҠ然еҗҺеӨҚеҲ¶еҲ°иҷҡжӢҹжңәдёҠгҖӮеҰӮжһңдҪ зҡ„elasticsearchзүҲжң¬жҳҜжңҖж–°зҡ„пјҢдҪ еҸҜиғҪе°ұйңҖиҰҒдёӢиҪҪikжәҗз ҒдёӢжқҘзј–иҜ‘д№ӢеҗҺеҶҚйғЁзҪІгҖӮ
еҪ“然дҪ еҸҜд»ҘдҪҝз”Ёgit+mavenзҡ„ж–№ејҸе®үиЈ…пјҢиҜҰз»Ҷзҡ„е®үиЈ…жӯҘйӘӨеҸҜд»ҘеҸӮи§Ғпјҡhttps://github.com/medcl/elasticsearch-analysis-ik
иҝҷд№ҹжҜ”иҫғз®ҖеҚ•пјҢжҲ‘иҝҷйҮҢе°ұдёҚйҮҚеӨҚдәҶгҖӮе®үиЈ…еҘҪд№ӢеҗҺйҮҚеҗҜesе®һдҫӢгҖӮ
еҸҜд»Ҙиҝҷж ·и§„еҲ’дёҖдёӘйӣҶзҫӨгҖӮmasterеҸҜд»ҘдёӨеҸ°пјҢиҝҷдёӨдёӘиҠӮзӮ№йғҪжҳҜдҪңдёәcommanderз»ҹзӯ№йӣҶзҫӨеұӮйқўзҡ„дәӢеҠЎпјҢеҸ–ж¶ҲиҝҷдёӨеҸ°зҡ„dataжқғеҲ©гҖӮ然еҗҺеңЁи§„еҲ’еҮәдёүдёӘиҠӮзӮ№зҡ„dataйӣҶзҫӨпјҢеҸ–ж¶ҲиҝҷдёүдёӘиҠӮзӮ№зҡ„masterжқғеҲ©гҖӮ让他们е®үеҝғзҡ„еҒҡеҘҪж•°жҚ®еӯҳеӮЁе’ҢжЈҖзҙўжңҚеҠЎгҖӮиҝҷжҳҜжңҖе°Ҹзҡ„зІ’еәҰйӣҶзҫӨз»“жһ„пјҢеҸҜд»ҘеҹәдәҺиҝҷдёӘз»“жһ„иҝӣиЎҢжү©еұ•гҖӮ
иҝҷж ·еҒҡжңүдёҖдёӘеҘҪеӨ„пјҢе°ұжҳҜиҒҢиҙЈеҲҶжҳҺпјҢеҸҜд»ҘжңҖеӨ§йҷҗеәҰзҡ„йҳІжӯўmasterиҠӮзӮ№жңүдәӢdataиҠӮзӮ№пјҢеҜјиҮҙдёҚзЁіе®ҡеӣ зҙ еҸ‘з”ҹгҖӮжҜ”еҰӮпјҢdataиҠӮзӮ№зҡ„ж•°жҚ®еӨҚеҲ¶пјҢж•°жҚ®е№іиЎЎпјҢи·Ҝз”ұзӯүзӯүпјҢзӣҙжҺҘеҪұе“Қmasterзҡ„зЁіе®ҡжҖ§гҖӮиҝӣиҖҢеҸҜиғҪдјҡеҸ‘з”ҹи„‘иЈӮй—®йўҳгҖӮ
жҲ‘们иҝӣе…ҘжңҖеҗҺдёҖдёӘзҺҜиҠӮпјҢжүҖжңүзҡ„дёңиҘҝйғҪеҮҶеӨҮеҘҪдәҶпјҢжҲ‘们жҳҜдёҚжҳҜеә”иҜҘж“ҚдҪңж“ҚдҪңиҝҷдёӘејәеӨ§зҡ„жҗңзҙўеј•ж“ҺдәҶгҖӮcome onгҖӮ
иҜҙеҲ°йӣҶзҫӨпјҢе°ұдјҡжңүзӣёеә”зҡ„й—®йўҳйҡҸд№ӢиҖҢжқҘпјҢй«ҳеҸҜз”ЁгҖҒй«ҳ并еҸ‘гҖҒеӨ§ж•°жҚ®гҖҒжЁӘеҗ‘жү©еұ•зӯүзӯүгҖӮйӮЈд№Ҳelasticsearhзҡ„йӣҶзҫӨеӨ§жҰӮжҳҜдёӘд»Җд№ҲеҺҹзҗҶгҖӮ
йҰ–е…Ҳclientзҡ„еңЁжҺҘе…ҘйӣҶзҫӨзҡ„ж—¶еҖҷдёәдәҶдҝқиҜҒй«ҳеҸҜз”ЁдёҚжҳҜйҮҮз”Ё vipжјӮ移е®һзҺ°й«ҳеҸҜз”ЁпјҢзұ»дјјkeepalived иҝҷз§ҚгҖӮelasticserachеңЁе®ўжҲ·з«ҜиҝһжҺҘзҡ„ж—¶еҖҷдҪҝз”Ёй…ҚзҪ®еӨҡдёӘIPзҡ„ж–№ејҸжқҘйҰ–е…Ҳе®ўжҲ·з«Ҝsdkзҡ„иҙҹиҪҪгҖӮиҝҷе·Із»ҸжҳҜеҲҶеёғејҸзі»з»ҹеёёи§Ғзҡ„еҒҡжі•дәҶгҖӮеҸӘжңүзұ»дјјDBгҖҒcacheиҝҷж ·дёӯеҝғеҢ–зҡ„йӣҶзҫӨйңҖиҰҒдҪҝз”ЁпјҢд»ҘдёәжҳҜе®ғ们зҡ„дҪҝз”Ёзү№зӮ№еҶіе®ҡдәҶгҖӮпјҲж•°жҚ®дёҖиҮҙжҖ§пјү
elasticsearchзҡ„жүҖжңүиҠӮзӮ№йғҪеҸҜд»ҘеӨ„зҗҶиҜ·жұӮпјҢиҠӮзӮ№и¶ҠеӨҡ并еҸ‘QPSи¶Ҡй«ҳпјҢзӣёеә”зҡ„TPSдјҡдёӢйҷҚпјҢдҪҶжҳҜдёӢйҷҚзҡ„жҖ§иғҪдёҚжҳҜж №жҚ®иҠӮзӮ№зҡ„жӯЈжҜ”дҫӢжқҘзҡ„гҖӮпјҲе®ғдҪҝз”ЁquorumпјҲжі•е®ҡдәәж•°пјүз®—жі•пјҢдҝқиҜҒеҸҜз”ЁжҖ§гҖӮпјүжүҖд»ҘиҠӮзӮ№зҡ„еӨҚеҲ¶дёҚжҳҜжҲ‘们жғіеҪ“然зҡ„йӮЈж ·гҖӮ
иҝһжҺҘesйӣҶзҫӨзҡ„ж–№ејҸжңүдёӨз§ҚпјҢжҖ§иғҪй«ҳзӮ№зҡ„е°ұжҳҜзӣҙжҺҘе°Ҷclientжү®жј”жҲҗcluster nodeиҝӣеҺ»йӣҶзҫӨпјҢеҗҢж—¶еҸ–ж¶ҲиҮӘе·ұзҡ„dataжқғеҲ©гҖӮиҝҷйҖҡеёёйғҪжҳҜз”ЁжқҘеҒҡдәҢж¬ЎејҖеҸ‘з”Ёзҡ„пјҢдҪ еҸҜд»Ҙgithub cloneдёӢжқҘжәҗз Ғж·»еҠ иҮӘе·ұзҡ„еңәжҷҜ然еҗҺиҝӣе…ҘйӣҶзҫӨпјҢеҸҜиғҪдҪ дјҡе№Ійў„йҖүдёҫпјҢд№ҹеҸҜиғҪдјҡе№Ійў„shardingпјҢд№ҹеҸҜиғҪдјҡе№Ійў„йӣҶзҫӨе№іиЎЎгҖӮ
elasticsearch дҪҝз”ЁиҮӘе·ұе®ҡд№үзҡ„дёҖеҘ—DSLиҜӯиЁҖпјҢдҪҝз”Ёrestfulж–№ејҸдҪҝз”ЁпјҢж №жҚ®дёҚеҗҢзҡ„rest end pointжқҘдҪҝз”ЁгҖӮжҜ”еҰӮпјҢ_searchгҖҒ_catгҖҒ_queryзӯүзӯүгҖӮиҝҷдәӣйғҪжҳҜжҢҮзӮ№зҡ„restз«ҜзӮ№гҖӮ然еҗҺдҪ еҸҜд»Ҙpost dslеҲ°elasticsearchжңҚеҠЎеҷЁеӨ„зҗҶгҖӮ
elasticsearch search dslпјҡhttps://www.elastic.co/guide/en/elasticsearch/reference/current/search.html
elasticsearch dsl apiпјҡhttp://elasticsearch-dsl.readthedocs.io/en/latest/
дҫӢпјҡ
POST _search
{
"query": {
"bool" : {
"must" : {
"query_string" : {
"query" : "query some test"
}
},
"filter" : {
"term" : { "user" : "plen" }
}
}
}
}
еҸҜиҜ»жҖ§еҫҲејәпјҢеңЁйҖҡиҝҮchromeжҸ’件Senseиҫ…еҠ©зј–еҶҷпјҢдјҡжҜ”иҫғж–№дҫҝгҖӮ
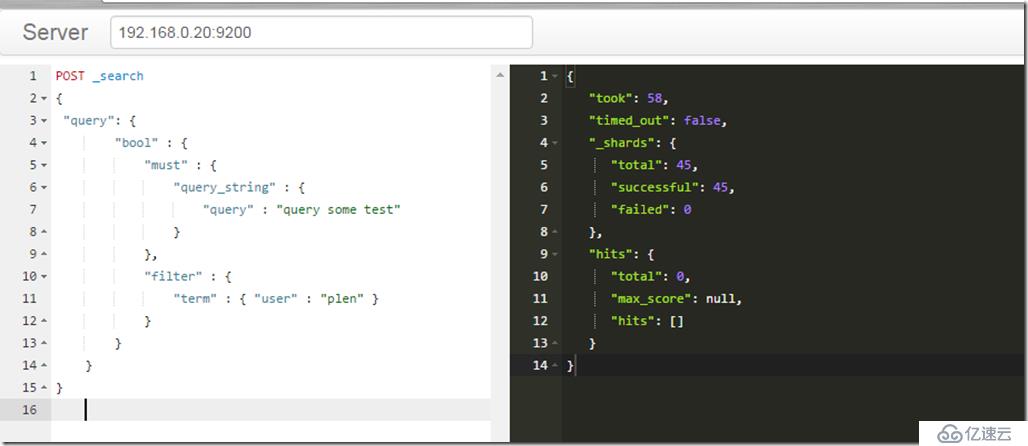
дҪҶжҳҜдёҖиҲ¬йғҪдёҚдјҡиҝҷд№ҲеҒҡпјҢдёҖиҲ¬йғҪжҳҜдҪҝз”ЁsdkиҝһжҺҘйӣҶзҫӨгҖӮзӣҙжҺҘдҪҝз”Ёdslзҡ„еӨ§еӨҡжҳҜеңЁжөӢиҜ•ж•°жҚ®зҡ„ж—¶еҖҷжҲ–иҖ…еңЁи°ғиҜ•зҡ„ж—¶еҖҷгҖӮзңӢsdkиҫ“еҮәзҡ„dslжҳҜеҗҰжӯЈзЎ®гҖӮе°ұи·ҹи°ғиҜ•SQLе·®дёҚеӨҡгҖӮ
.NETзЁӢеәҸжңүејҖжәҗеҢ…nestпјҢзӣҙжҺҘеңЁNugetдёҠжҗңзҙўе®үиЈ…еҚіеҸҜгҖӮ
е®ҳзҪ‘ең°еқҖпјҡhttps://www.elastic.co/guide/en/elasticsearch/client/net-api/1.x/nest-connecting.html
дҪҝз”Ёpoolй«ҳеҸҜз”Ёзҡ„ж–№ејҸиҝһжҺҘйӣҶзҫӨгҖӮ
var node1 = new Uri("http://192.168.0.10:9200");
var node2 = new Uri("http://192.168.0.20:9200");
var node3 = new Uri("http://192.168.0.30:9200");
var connectionPool = new SniffingConnectionPool(new[] { node1, node2, node3 });
var settings = new ConnectionSettings(connectionPool);
var client = new ElasticClient(settings);
жӯӨж—¶дҪҝз”ЁclientеҜ№иұЎе°ұжҳҜиҪҜиҙҹиҪҪзҡ„пјҢе®ғдјҡж №жҚ®дёҖе®ҡзҡ„зӯ–з•ҘжқҘеқҮиЎЎзҡ„иҝһжҺҘеҗҺеҸ°дёүдёӘnodeгҖӮпјҲеҸҜиғҪжҳҜе№іеқҮзҡ„гҖҒеҸҜиғҪжҳҜжқғйҮҚзҡ„пјҢе…·дҪ“жІЎз ”з©¶пјү
java зҡ„иҜқжҲ‘жҳҜдҪҝз”ЁjestгҖӮжҲ‘们еҲӣе»әдёҖдёӘmavenйЎ№зӣ®пјҢ然еҗҺж·»еҠ jest зӣёеә”зҡ„jarеҢ…mavenеј•з”ЁгҖӮ
<dependencies> <dependency> <groupId>io.searchbox</groupId> <artifactId>jest</artifactId> <version>2.0.3</version> </dependency> <dependency> <groupId>org.elasticsearch</groupId> <artifactId>elasticsearch</artifactId> <version>2.3.5</version> </dependency> </dependencies>
JestClientFactory factory = new JestClientFactory();
List<String> nodes = new LinkedList<String>();
nodes.add("http://192.168.0.10:9200");
nodes.add("http://192.168.0.20:9200");
nodes.add("http://192.168.0.30:9200");
HttpClientConfig config = new HttpClientConfig.Builder(nodes).multiThreaded(true).build();
factory.setHttpClientConfig(config);
JestHttpClient client = (JestHttpClient) factory.getObject();
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.queryStringQuery("дёӯеҚҺдәәеҗҚе…ұе’ҢеӣҪ"));
searchSourceBuilder.field("name");
Search search = new Search.Builder(searchSourceBuilder.toString()).build();
JestResult rs = client.execute(search);
System.out.println(rs.getJsonString());{
"took": 71,
"timed_out": false,
"_shards": {
"total": 45,
"successful": 45,
"failed": 0
},
"hits": {
"total": 6,
"max_score": 0.6614378,
"hits": [
{
"_index": "posts",
"_type": "post",
"_id": "1",
"_score": 0.6614378,
"fields": {
"name": [
"зҺӢжё…еҹ№"
]
}
},
{
"_index": "posts",
"_type": "post",
"_id": "5",
"_score": 0.57875806,
"fields": {
"name": [
"зҺӢжё…еҹ№"
]
}
},
{
"_index": "posts",
"_type": "post",
"_id": "2",
"_score": 0.57875806,
"fields": {
"name": [
"зҺӢжё…еҹ№"
]
}
},
{
"_index": "posts",
"_type": "post",
"_id": "AVaKENIckgl39nrAi9V5",
"_score": 0.57875806,
"fields": {
"name": [
"зҺӢжё…еҹ№"
]
}
},
{
"_index": "class",
"_type": "student",
"_id": "1",
"_score": 0.17759356
},
{
"_index": "posts",
"_type": "post",
"_id": "3",
"_score": 0.17759356,
"fields": {
"name": [
"зҺӢжё…еҹ№"
]
}
}
]
}
}
иҝ”еӣһзҡ„ж•°жҚ®жЁӘи·ЁеӨҡдёӘзҙўеј•гҖӮдҪ еҸҜд»ҘйҖҡиҝҮдёҚж–ӯзҡ„debugжқҘжҹҘзңӢй“ҫжҺҘIPжҳҜдёҚжҳҜдјҡеҗҜеҠЁеҲҮжҚўпјҢжҳҜдёҚжҳҜдјҡиө·еҲ°еҸҜз”ЁжҖ§зҡ„дҪңз”ЁгҖӮ
зҙўеј•ејҖеҸ‘дёҖиҲ¬жӯҘйӘӨжҜ”иҫғз®ҖеҚ•пјҢйҰ–е…Ҳе»әз«ӢеҜ№еә”зҡ„mappingжҳ е°„пјҢй…ҚзҪ®еҘҪеҗ„дёӘtypeдёӯзҡ„fieldзҡ„зү№жҖ§гҖӮ
mappingжҳҜesе®һдҫӢз”ЁжқҘеңЁindexзҡ„ж—¶еҖҷпјҢдҪңдёәеҗ„дёӘеӯ—ж®өзҡ„ж“ҚдҪңдҫқжҚ®гҖӮжҜ”еҰӮпјҢusernameпјҢиҝҷдёӘеӯ—ж®өжҳҜеҗҰиҰҒзҙўеј•гҖҒжҳҜеҗҰиҰҒеӯҳеӮЁгҖҒй•ҝеәҰеӨ§е°ҸзӯүзӯүгҖӮиҷҪ然elasticsearchеҸҜд»ҘеҠЁжҖҒзҡ„еӨ„зҗҶиҝҷдәӣпјҢдҪҶжҳҜеҮәдәҺз®ЎзҗҶе’Ңиҝҗз»ҙзҡ„зӣ®зҡ„иҝҳжҳҜе»әи®®е»әз«ӢеҜ№еә”зҡ„зҙўеј•жҳ е°„пјҢиҝҷдёӘжҳ е°„еҸҜд»ҘдҝқеӯҳеңЁж–Ү件йҮҢпјҢд»Ҙдҫҝе°ҶжқҘйҮҚе»әзҙўеј•з”ЁгҖӮ
POST /demoindex
{
"mappings": {
"demotype": {
"properties": {
"contents": {
"type": "string",
"index": "analyzed"
},
"name": {
"store": true,
"type": "string",
"index": "analyzed"
},
"id": {
"store": true,
"type": "long"
},
"userId": {
"store": true,
"type": "long"
}
}
}
}
}
иҝҷжҳҜдёҖдёӘжңҖз®ҖеҚ•зҡ„mappingпјҢе®ҡд№үдәҶзҙўеј•еҗҚз§°дёәdemoindexпјҢзұ»еһӢдёәdemotypeзҡ„mappingгҖӮеҗ„дёӘеӯ—ж®өеҲҶеҲ«жҳҜдёҖдёӘjsonеҜ№иұЎпјҢйҮҢйқўжңүзұ»еһӢжңүзҙўеј•жҳҜеҗҰйңҖиҰҒгҖӮ
иҝҷдёӘеңЁsenseйҮҢзј–иҫ‘пјҢ然еҗҺзӣҙжҺҘpostжҸҗдәӨгҖӮ
{
"acknowledged": true
}
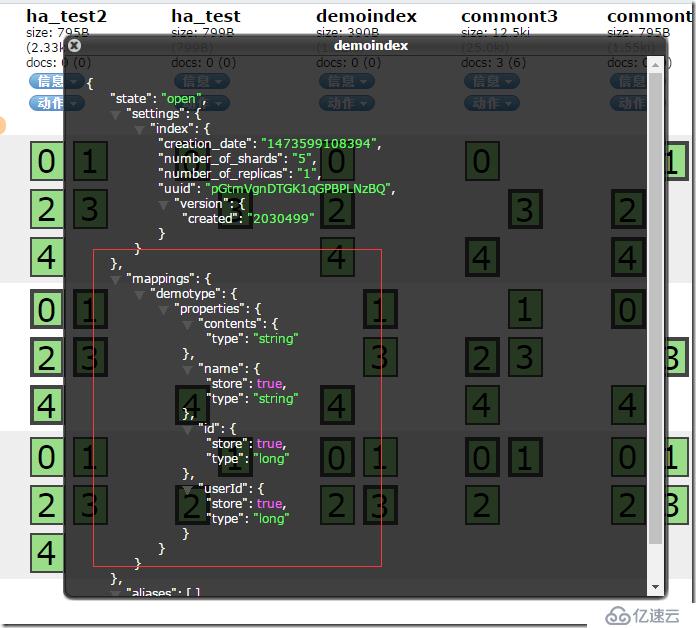
йҖҡиҝҮжҹҘзңӢеҲӣе»әеҘҪзҡ„зҙўеј•дҝЎжҒҜзЎ®и®ӨжҳҜеҗҰжҳҜдҪ жҸҗдәӨзҡ„mappingи®ҫзҪ®гҖӮ
жҜҸж¬ЎйғҪйҖҡиҝҮжүӢеҠЁзҡ„еҲӣе»әзұ»дјјзҡ„mappingе§Ӣз»ҲжҳҜдёӘдҪҺж•ҲзҺҮзҡ„дәӢжғ…пјҢelasticserachж”ҜжҢҒе»әз«ӢmappingжЁЎжқҝпјҢ然еҗҺи®©жЁЎжқҝиҮӘеҠЁеҢ№й…ҚдҪҝз”Ёе“ӘдёӘmappingе®ҡд№үгҖӮ
PUT log_template
{
"order": 10,
"template": "log_*",
"settings": {
"index": {
"number_of_replicas": "2",
"number_of_shards": "5"
}
},
"mappings": {
"_default_": {
"_source_": {
"enable": false
}
}
}
}
еҲӣе»әдёҖдёӘlogзұ»еһӢзҡ„зҙўеј•mappingгҖӮжҲ‘们и®ҫзҪ®дәҶдёӨдёӘеҹәжң¬зҡ„еұһжҖ§пјҢ "number_of_replicas": "2" еӨҚеҲ¶еҲҶж•°, "number_of_shards": "5" еҲҶзүҮдёӘж•°гҖӮmappingsйҮҢйқўи®ҫзҪ®дәҶsourceеӯ—ж®өй»ҳи®ӨдёҚејҖеҗҜгҖӮ
еҪ“жҲ‘们жҸҗдәӨжүҖжңүд»ҘвҖңlog_xxxвҖқеҗҚеӯ—ж јејҸзҡ„зҙўеј•ж—¶е°ҶиҮӘеҠЁе‘ҪдёӯиҝҷдёӘmappingжЁЎжқҝгҖӮ
еҸҜд»ҘйҖҡиҝҮ_template restз«ҜзӮ№жҹҘзңӢе·Із»ҸеӯҳеңЁзҡ„mappingжЁЎжқҝпјҢжҲ–иҖ…йҖҡиҝҮheadжҸ’件зҡ„еҸідёҠи§’зҡ„вҖқдҝЎжҒҜвҖқйҮҢйқўзҡ„вҖқжЁЎжқҝвҖқиҸңеҚ•жҹҘзңӢгҖӮ
{
"mq_template" : {
"order" : 10,
"template" : "mq*",
"settings" : {
"index" : {
"number_of_shards" : "5",
"number_of_replicas" : "2"
}
},
"mappings" : {
"_default_" : {
"_source_" : {
"enable" : false
}
}
},
"aliases" : { }
},
"log_template" : {
"order" : 10,
"template" : "log_*",
"settings" : {
"index" : {
"number_of_shards" : "5",
"number_of_replicas" : "2"
}
},
"mappings" : {
"_default_" : {
"_source_" : {
"enable" : false
}
}
},
"aliases" : { }
},
"error_template" : {
"order" : 10,
"template" : "error_*",
"settings" : {
"index" : {
"number_of_shards" : "5",
"number_of_replicas" : "2"
}
},
"mappings" : {
"_default_" : {
"_source_" : {
"enable" : false
}
}
},
"aliases" : { }
}
}иҝҷйҖҡеёёз”ЁдәҺдёҖдәӣдёҡеҠЎдёҚжғіе…ізҡ„еӯҳеӮЁдёӯпјҢжҜ”еҰӮж—Ҙеҝ—гҖҒж¶ҲжҒҜгҖҒйҮҚеӨ§й”ҷиҜҜйў„иӯҰзӯүзӯүйғҪеҸҜд»Ҙи®ҫзҪ®пјҢеҸӘиҰҒиҝҷдәӣйҮҚеӨҚзҡ„mappingжҳҜжңү规еҫӢзҡ„гҖӮ
еңЁesеҜ№ж•°жҚ®иҝӣиЎҢеҲҶзүҮзҡ„ж—¶еҖҷжҳҜйҮҮз”ЁhashеҸ–дҪҷзҡ„ж–№ејҸиҝӣиЎҢзҡ„пјҢжүҖд»ҘдҪ еҸҜд»Ҙдј йҖ’дёҖдёӘеӣәе®ҡзҡ„keyпјҢйӮЈд№ҲиҝҷдёӘkeyе°ҶдҪңдёәдҪ еӣәе®ҡзҡ„и·Ҝз”ұ规еҲҷгҖӮеңЁеҲӣе»әmappingsзҡ„ж—¶еҖҷеҸҜд»Ҙи®ҫзҪ®иҝҷдёӘ_routingеҸӮж•°гҖӮиҝҷеңЁ1.0зҡ„зүҲжң¬дёӯжҳҜиҝҷж ·зҡ„и®ҫзҪ®зҡ„пјҢд№ҹе°ұжҳҜиҜҙдҪ еҪ“еүҚtypeдёӢзҡ„жүҖжңүdocumentйғҪжҳҜеҸӘиғҪз”ЁзқҖиҝҷдёӘи·Ҝз”ұkeyиҝӣиЎҢгҖӮдҪҶжҳҜеңЁes2.0д№ӢеҗҺroutingи·ҹзқҖindexе…ғж•°жҚ®иө°пјҢиҝҷж ·еҸҜд»ҘжҺ§еҲ¶еҚ•дёӘindexзҡ„и·Ҝз”ұ规еҲҷпјҢеңЁжҸҗдәӨindexзҡ„ж—¶еҖҷеҸҜд»ҘеҚ•зӢ¬еҲ¶е®ҡ_routingеҸӮж•°пјҢиҖҢдёҚжҳҜзӣҙжҺҘи®ҫзҪ®mappingsдёҠгҖӮ
еңЁ2.0д№ӢеҗҺе·Із»ҸдёҚеҶҚж”ҜжҢҒmappingsй…ҚзҪ®_routingеҸӮж•°дәҶгҖӮ
https://www.elastic.co/guide/en/elasticsearch/reference/current/breaking_20_mapping_changes.html#migration-meta-fields
еңЁ1.0йҮҢпјҢжҜ”еҰӮпјҢдҪ еҸҜд»Ҙе°ҶuseridдҪңдёәrouting keyпјҢиҝҷж ·е°ұеҸҜд»Ҙе°ҶеҪ“еүҚз”ЁжҲ·зҡ„жүҖжңүж•°жҚ®йғҪеңЁдёҖдёӘеҲҶзүҮдёҠпјҢеҪ“жҹҘиҜўзҡ„ж—¶еҖҷе°ұдјҡеҠ еҝ«жҹҘиҜўйҖҹеәҰгҖӮ
{
"mappings": {
"post": {
"_routing": {
"required": true,
"path":"userid"
},
"properties": {
"contents": {
"type": "string"
},
"name": {
"store": true,
"type": "string"
},
"id": {
"store": true,
"type": "long"
},
"userId": {
"store": true,
"type": "long"
}
}
}
}
}
иҝҷдёӘ_routingжҳҜи®ҫзҪ®еңЁmappingдёҠзҡ„пјҢдҪңз”ЁдәҺжүҖжңүtypeгҖӮдјҡдҪҝз”ЁuseridдҪңдёәshardingзҡ„keyгҖӮдҪҶжҳҜеңЁ2.0йҮҢпјҢжҳҜеҝ…йЎ»жҳҺзЎ®жҢҮе®ҡrouting pathзҡ„гҖӮ
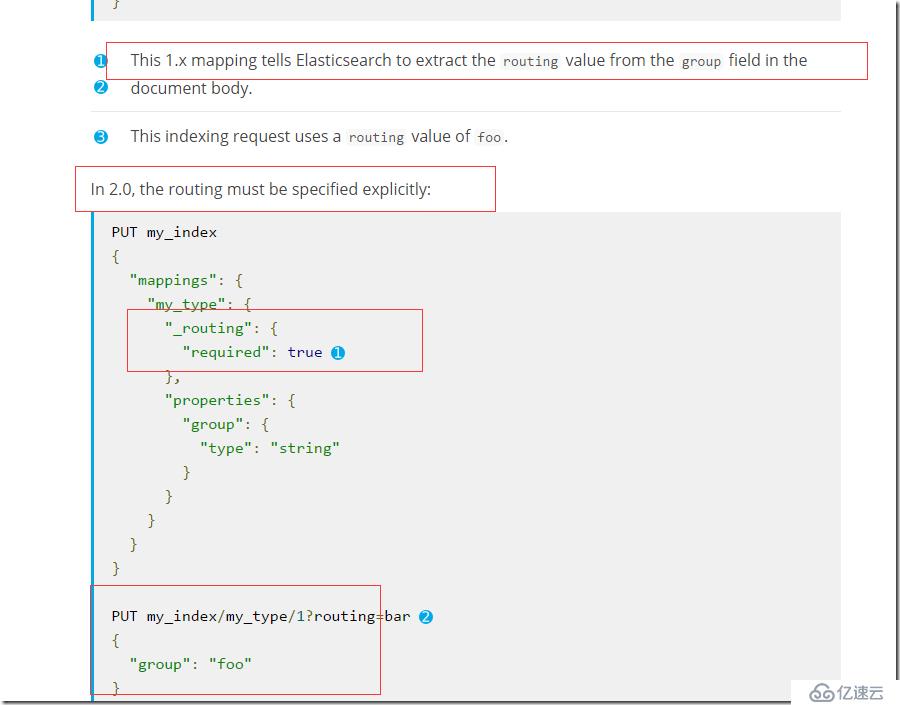
еңЁдҪ ж·»еҠ еҘҪmappingsд№ӢеҗҺпјҢеҲӣе»әеҪ“еүҚзҙўеј•зҡ„ж—¶еҖҷеҝ…йЎ»жҢҮе®ҡ&routing=xxxпјҢеҸӮж•°гҖӮиҝҷжңүдёӘеҫҲеӨ§зҡ„еҘҪеӨ„е°ұжҳҜдҪ еҸҜд»Ҙж №жҚ®дёҚеҗҢзҡ„дёҡеҠЎз»ҙеәҰиҮӘз”ұи°ғж•ҙеҲҶзүҮзӯ–з•ҘгҖӮ
дёҠиҝ°еҶ…е®№е°ұжҳҜElasticSearchеӨ§ж•°жҚ®еҲҶеёғејҸеј№жҖ§жҗңзҙўеј•ж“ҺиҜҘеҰӮдҪ•дҪҝз”ЁпјҢдҪ 们еӯҰеҲ°зҹҘиҜҶжҲ–жҠҖиғҪдәҶеҗ—пјҹеҰӮжһңиҝҳжғіеӯҰеҲ°жӣҙеӨҡжҠҖиғҪжҲ–иҖ…дё°еҜҢиҮӘе·ұзҡ„зҹҘиҜҶеӮЁеӨҮпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ