жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚPythonдёӯеҰӮдҪ•е®һзҺ°MNISTжүӢеҶҷдҪ“иҜҶеҲ«пјҢж–Үдёӯд»Ӣз»Қзҡ„йқһеёёиҜҰз»ҶпјҢе…·жңүдёҖе®ҡзҡ„еҸӮиҖғд»·еҖјпјҢж„ҹе…ҙи¶Јзҡ„е°Ҹдјҷдјҙ们дёҖе®ҡиҰҒзңӢе®ҢпјҒ
жң¬е®һйӘҢйҮҮз”Ёзҡ„иҪҜ硬件е®һйӘҢзҺҜеўғеҰӮиЎЁжүҖзӨәпјҡ

еңЁWindowsж“ҚдҪңзі»з»ҹдёӢпјҢйҮҮз”ЁеҹәдәҺTensorflowзҡ„Kerasзҡ„ж·ұеәҰеӯҰд№ жЎҶжһ¶пјҢеҜ№MNISTиҝӣиЎҢи®ӯз»ғе’ҢжөӢиҜ•гҖӮ
йҮҮз”Ёkerasзҡ„ж·ұеәҰеӯҰд№ жЎҶжһ¶пјҢkerasжҳҜдёҖдёӘдё“дёәз®ҖеҚ•зҡ„зҘһз»ҸзҪ‘з»ңз»„иЈ…иҖҢи®ҫи®Ўзҡ„Pythonеә“пјҢе…·жңүеӨ§йҮҸйў„е…ҲеҢ…иЈ…зҡ„зҪ‘з»ңзұ»еһӢпјҢеҢ…жӢ¬дәҢз»ҙе’Ңдёүз»ҙйЈҺж јзҡ„еҚ·з§ҜзҪ‘з»ңгҖҒзҹӯжңҹе’Ңй•ҝжңҹзҡ„зҪ‘з»ңд»ҘеҸҠжӣҙе№ҝжіӣзҡ„дёҖиҲ¬зҪ‘з»ңгҖӮдҪҝз”Ёkerasжһ„е»әзҪ‘з»ңжҳҜзӣҙжҺҘзҡ„пјҢkerasеңЁе…¶Apiи®ҫи®ЎдёӯдҪҝз”Ёзҡ„иҜӯд№үжҳҜйқўеҗ‘еұӮж¬Ўзҡ„пјҢзҪ‘з»ңз»„е»әзӣёеҜ№зӣҙи§ӮпјҢжүҖд»Ҙжң¬ж¬ЎйҖүз”ЁKerasдәәе·ҘжҷәиғҪжЎҶжһ¶пјҢе…¶дё“жіЁдәҺз”ЁжҲ·еҸӢеҘҪпјҢжЁЎеқ—еҢ–е’ҢеҸҜжү©еұ•жҖ§гҖӮ
MNISTпјҲе®ҳж–№зҪ‘з«ҷпјүжҳҜйқһеёёжңүеҗҚзҡ„жүӢеҶҷдҪ“ж•°еӯ—иҜҶеҲ«ж•°жҚ®йӣҶгҖӮе®ғз”ұжүӢеҶҷдҪ“ж•°еӯ—зҡ„еӣҫзүҮе’ҢзӣёеҜ№еә”зҡ„ж Үзӯҫз»„жҲҗпјҢеҰӮпјҡ

MNISTж•°жҚ®йӣҶеҲҶдёәи®ӯз»ғеӣҫеғҸе’ҢжөӢиҜ•еӣҫеғҸгҖӮи®ӯз»ғеӣҫеғҸ60000еј пјҢжөӢиҜ•еӣҫеғҸ10000еј пјҢжҜҸдёҖдёӘеӣҫзүҮд»ЈиЎЁ0-9дёӯзҡ„дёҖдёӘж•°еӯ—пјҢдё”еӣҫзүҮеӨ§е°ҸеқҮдёә28*28зҡ„зҹ©йҳөгҖӮ
train-images-idx3-ubyte.gz: training set images (9912422 bytes) и®ӯз»ғеӣҫзүҮ
train-labels-idx1-ubyte.gz: training set labels (28881 bytes) и®ӯз»ғж Үзӯҫ
t10k-images-idx3-ubyte.gz: test set images (1648877 bytes) жөӢиҜ•еӣҫзүҮ
t10k-labels-idx1-ubyte.gz: test set labels (4542 bytes) жөӢиҜ•ж Үзӯҫ
ж•°жҚ®йў„еӨ„зҗҶйҳ¶ж®өеҜ№еӣҫеғҸиҝӣиЎҢеҪ’дёҖеҢ–еӨ„зҗҶпјҢжҲ‘们е°ҶеӣҫзүҮдёӯзҡ„иҝҷдәӣеҖјзј©е°ҸеҲ° 0 еҲ° 1 д№Ӣй—ҙпјҢ然еҗҺе°Ҷе…¶йҰҲйҖҒеҲ°зҘһз»ҸзҪ‘з»ңжЁЎеһӢгҖӮдёәжӯӨпјҢе°ҶеӣҫеғҸ组件зҡ„ж•°жҚ®зұ»еһӢд»Һж•ҙж•°иҪ¬жҚўдёәжө®зӮ№ж•°пјҢ然еҗҺйҷӨд»Ҙ 255гҖӮиҝҷж ·жӣҙе®№жҳ“и®ӯз»ғ,д»ҘдёӢжҳҜйў„еӨ„зҗҶеӣҫеғҸзҡ„еҮҪж•°пјҡеҠЎеҝ…иҰҒд»ҘзӣёеҗҢзҡ„ж–№ејҸеҜ№и®ӯз»ғйӣҶе’ҢжөӢиҜ•йӣҶиҝӣиЎҢйў„еӨ„зҗҶпјҡ
д№ӢеҗҺеҜ№ж ҮзӯҫиҝӣиЎҢone-hotзј–з ҒеӨ„зҗҶпјҡе°ҶзҰ»ж•Јзү№еҫҒзҡ„еҸ–еҖјжү©еұ•еҲ°дәҶ欧ејҸз©әй—ҙпјҢзҰ»ж•Јзү№еҫҒзҡ„жҹҗдёӘеҸ–еҖје°ұеҜ№еә”欧ејҸз©әй—ҙзҡ„жҹҗдёӘзӮ№пјӣжңәеҷЁеӯҰд№ з®—жі•дёӯпјҢзү№еҫҒд№Ӣй—ҙи·қзҰ»зҡ„и®Ўз®—жҲ–зӣёдјјеәҰзҡ„еёёз”Ёи®Ўз®—ж–№жі•йғҪжҳҜеҹәдәҺ欧ејҸз©әй—ҙзҡ„пјӣе°ҶзҰ»ж•ЈеһӢзү№еҫҒдҪҝз”Ёone-hotзј–з ҒпјҢдјҡи®©зү№еҫҒд№Ӣй—ҙзҡ„и·қзҰ»и®Ўз®—жӣҙеҠ еҗҲзҗҶ
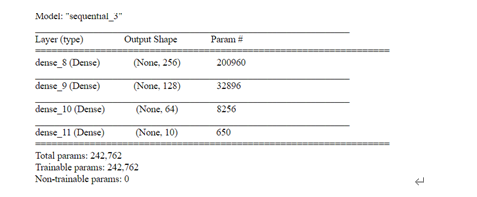
# Build MLP model = Sequential() model.add(Dense(units=256, input_dim=784, kernel_initializer='normal', activation='relu')) model.add(Dense(units=128, kernel_initializer='normal', activation='relu')) model.add(Dense(units=64, kernel_initializer='normal', activation='relu')) model.add(Dense(units=10, kernel_initializer='normal', activation='softmax')) model.summary()
# Build LeNet-5 model = Sequential() model.add(Conv2D(filters=6, kernel_size=(5, 5), padding='valid', input_shape=(28, 28, 1), activation='relu')) # C1 model.add(MaxPooling2D(pool_size=(2, 2))) # S2 model.add(Conv2D(filters=16, kernel_size=(5, 5), padding='valid', activation='relu')) # C3 model.add(MaxPooling2D(pool_size=(2, 2))) # S4 model.add(Flatten()) model.add(Dense(120, activation='tanh')) # C5 model.add(Dense(84, activation='tanh')) # F6 model.add(Dense(10, activation='softmax')) # output model.summary()
жЁЎеһӢи®ӯз»ғиҝҮзЁӢдёӯпјҢжҲ‘们用еҲ°LENET-5зҡ„еҚ·з§ҜзҘһз»ҸзҪ‘з»ңз»“жһ„гҖӮ

第дёҖеұӮпјҢеҚ·з§ҜеұӮ
иҝҷдёҖеұӮзҡ„иҫ“е…ҘжҳҜеҺҹе§Ӣзҡ„еӣҫеғҸеғҸзҙ пјҢLeNet-5 жЁЎеһӢжҺҘеҸ—зҡ„иҫ“е…ҘеұӮеӨ§е°ҸжҳҜ28x28x1гҖӮ第дёҖеҚ·з§ҜеұӮзҡ„иҝҮж»ӨеҷЁзҡ„е°әеҜёжҳҜ5x5пјҢж·ұеәҰпјҲеҚ·з§Ҝж ёз§Қзұ»пјүдёә6пјҢдёҚдҪҝз”Ёе…Ё0еЎ«е……пјҢжӯҘй•ҝдёә1гҖӮеӣ дёәжІЎжңүдҪҝз”Ёе…Ё0еЎ«е……пјҢжүҖд»ҘиҝҷдёҖеұӮзҡ„иҫ“еҮәзҡ„е°әеҜёдёә32-5+1=28пјҢж·ұеәҰдёә6гҖӮиҝҷдёҖеұӮеҚ·з§ҜеұӮеҸӮж•°дёӘж•°жҳҜ5x5x1x6+6=156дёӘеҸӮж•°пјҲеҸҜи®ӯз»ғеҸӮж•°пјүпјҢе…¶дёӯ6дёӘдёәеҒҸзҪ®йЎ№еҸӮж•°гҖӮеӣ дёәдёӢдёҖеұӮзҡ„иҠӮзӮ№зҹ©йҳөжңүжңү28x28x6=4704дёӘиҠӮзӮ№пјҲзҘһз»Ҹе…ғж•°йҮҸпјүпјҢжҜҸдёӘиҠӮзӮ№е’Ң5x5=25дёӘеҪ“еүҚеұӮиҠӮзӮ№зӣёиҝһпјҢжүҖд»Ҙжң¬еұӮеҚ·з§ҜеұӮжҖ»е…ұжңү28x28x6xпјҲ5x5+1пјүдёӘиҝһжҺҘгҖӮ
第дәҢеұӮпјҢжұ еҢ–еұӮ
иҝҷдёҖеұӮзҡ„иҫ“е…ҘжҳҜ第дёҖеұӮзҡ„иҫ“еҮәпјҢжҳҜдёҖдёӘ28x28x6=4704зҡ„иҠӮзӮ№зҹ©йҳөгҖӮжң¬еұӮйҮҮз”Ёзҡ„иҝҮж»ӨеҷЁдёә2x2зҡ„еӨ§е°ҸпјҢй•ҝе’Ңе®Ҫзҡ„жӯҘй•ҝеқҮдёә2пјҢжүҖд»Ҙжң¬еұӮзҡ„иҫ“еҮәзҹ©йҳөеӨ§е°Ҹдёә14x14x6гҖӮеҺҹе§Ӣзҡ„LeNet-5 жЁЎеһӢдёӯдҪҝз”Ёзҡ„иҝҮж»ӨеҷЁе’ҢиҝҷйҮҢе°Ҷз”ЁеҲ°зҡ„иҝҮж»ӨеҷЁжңүдәӣи®ёзҡ„е·®еҲ«пјҢиҝҷйҮҢдёҚиҝҮеӨҡд»Ӣз»ҚгҖӮ
第дёүеұӮпјҢеҚ·з§ҜеұӮ
жң¬еұӮзҡ„иҫ“е…Ҙзҹ©йҳөеӨ§е°Ҹдёә14x14x6пјҢдҪҝз”Ёзҡ„иҝҮж»ӨеҷЁеӨ§е°Ҹдёә5x5пјҢж·ұеәҰдёә16гҖӮжң¬еұӮдёҚдҪҝз”Ёе…Ё0еЎ«е……пјҢжӯҘй•ҝдёә1гҖӮжң¬еұӮзҡ„иҫ“еҮәзҹ©йҳөеӨ§е°Ҹдёә10x10x16гҖӮжҢүз…§ж ҮеҮҶеҚ·з§ҜеұӮжң¬еұӮеә”иҜҘжңү5x5x6x16+16=2416дёӘеҸӮж•°пјҲеҸҜи®ӯз»ғеҸӮж•°пјүпјҢ10x10x16xпјҲ5x5+1пјү=41600дёӘиҝһжҺҘгҖӮ
第еӣӣеұӮпјҢжұ еҢ–еұӮ
жң¬еұӮзҡ„иҫ“е…Ҙзҹ©йҳөеӨ§е°ҸжҳҜ10x10x16пјҢйҮҮз”Ёзҡ„иҝҮж»ӨеҷЁеӨ§е°ҸжҳҜ2x2пјҢжӯҘй•ҝдёә2пјҢжң¬еұӮзҡ„иҫ“еҮәзҹ©йҳөеӨ§е°Ҹдёә5x5x16гҖӮ
第дә”еұӮпјҢе…ЁиҝһжҺҘеұӮ
жң¬еұӮзҡ„иҫ“е…Ҙзҹ©йҳөеӨ§е°Ҹдёә5x5x16гҖӮеҰӮжһңе°ҶжӯӨзҹ©йҳөдёӯзҡ„иҠӮзӮ№жӢүжҲҗдёҖдёӘеҗ‘йҮҸпјҢйӮЈд№Ҳиҝҷе°ұе’Ңе…ЁиҝһжҺҘеұӮзҡ„иҫ“е…ҘдёҖж ·дәҶгҖӮжң¬еұӮзҡ„иҫ“еҮәиҠӮзӮ№дёӘж•°дёә120пјҢжҖ»е…ұжңү5x5x16x120+120=48120дёӘеҸӮж•°гҖӮ
第е…ӯеұӮпјҢе…ЁиҝһжҺҘеұӮ
жң¬еұӮзҡ„иҫ“е…ҘиҠӮзӮ№дёӘж•°дёә120дёӘпјҢиҫ“еҮәиҠӮзӮ№дёӘж•°дёә84дёӘпјҢжҖ»е…ұеҸӮж•°дёә120x84+84=10164дёӘгҖӮ
第дёғеұӮпјҢе…ЁиҝһжҺҘеұӮ
LeNet-5 жЁЎеһӢдёӯжңҖеҗҺдёҖеұӮиҫ“еҮәеұӮзҡ„з»“жһ„е’Ңе…ЁиҝһжҺҘеұӮзҡ„з»“жһ„жңүеҢәеҲ«пјҢдҪҶиҝҷйҮҢжҲ‘们用全иҝһжҺҘеұӮиҝ‘дјјзҡ„иЎЁзӨәгҖӮжң¬еұӮзҡ„иҫ“е…ҘиҠӮзӮ№дёә84дёӘпјҢиҫ“еҮәиҠӮзӮ№дёӘж•°дёә10дёӘпјҢжҖ»е…ұжңүеҸӮж•°84x10+10=850дёӘгҖӮ
еҲқе§ӢеҸӮж•°и®ҫе®ҡеҘҪд№ӢеҗҺејҖе§Ӣи®ӯз»ғпјҢжҜҸж¬Ўи®ӯз»ғйңҖиҰҒеҫ®и°ғеҸӮж•°д»Ҙеҫ—еҲ°жӣҙеҘҪзҡ„и®ӯз»ғз»“жһңпјҢз»ҸиҝҮеӨҡж¬Ўе°қиҜ•пјҢжңҖз»Ҳи®ҫе®ҡеҸӮж•°дёәпјҡ
дјҳеҢ–еҷЁпјҡadamдјҳеҢ–еҷЁ
и®ӯз»ғиҪ®ж•°пјҡ10
жҜҸж¬Ўиҫ“е…Ҙзҡ„ж•°жҚ®йҮҸпјҡ500
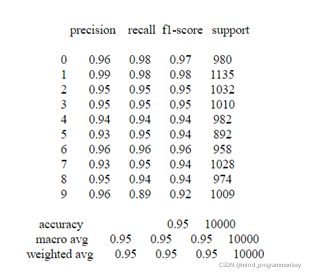
LENET-5зҡ„еҚ·з§ҜзҘһз»ҸзҪ‘з»ңеҜ№MNISTж•°жҚ®йӣҶиҝӣиЎҢи®ӯз»ғпјҢ并йҮҮз”ЁдёҠиҝ°зҡ„жЁЎеһӢеҸӮж•°пјҢиҝӣиЎҢ10иҪ®и®ӯз»ғпјҢеңЁи®ӯз»ғйӣҶдёҠиҫҫеҲ°дәҶ95%зҡ„еҮҶзЎ®зҺҮ

дёәдәҶйӘҢиҜҒжЁЎеһӢзҡ„йІҒжЈ’жҖ§пјҢеңЁдёҠиҝ°жңҖдјҳеҸӮж•°дёӢдҝқеӯҳеңЁйӘҢиҜҒйӣҶдёҠжҖ§иғҪжңҖеҘҪзҡ„жЁЎеһӢпјҢеңЁжөӢиҜ•йӣҶдёҠиҝӣиЎҢжңҖз»Ҳзҡ„жөӢиҜ•пјҢеҫ—еҲ°жңҖз»Ҳзҡ„еҮҶзЎ®зҺҮдёәпјҡ95.13%.
дёәдәҶжӣҙеҘҪзҡ„еҲҶжһҗжҲ‘们зҡ„з»“жһңпјҢиҝҷйҮҢз”Ёж··ж·Ҷзҹ©йҳөжқҘиҜ„дј°жҲ‘们зҡ„жЁЎеһӢжҖ§иғҪгҖӮеңЁжЁЎеһӢиҜ„дј°д№ӢеүҚпјҢе…ҲеӯҰд№ дёҖдәӣжҢҮж ҮгҖӮ
TP(True Positive)пјҡе°ҶжӯЈзұ»йў„жөӢдёәжӯЈзұ»ж•°пјҢзңҹе®һдёә0пјҢйў„жөӢд№ҹдёә0FN(False Negative)пјҡе°ҶжӯЈзұ»йў„жөӢдёәиҙҹзұ»ж•°пјҢзңҹе®һдёә0пјҢйў„жөӢдёә1FP(False Positive)пјҡе°Ҷиҙҹзұ»йў„жөӢдёәжӯЈзұ»ж•°пјҢ зңҹе®һдёә1пјҢйў„жөӢдёә0гҖӮTN(True Negative)пјҡе°Ҷиҙҹзұ»йў„жөӢдёәиҙҹзұ»ж•°пјҢзңҹе®һдёә1пјҢйў„жөӢд№ҹдёә1ж··ж·Ҷзҹ©йҳөе®ҡд№үеҸҠиЎЁзӨәеҗ«д№үпјҡ
ж··ж·Ҷзҹ©йҳөжҳҜжңәеҷЁеӯҰд№ дёӯжҖ»з»“еҲҶзұ»жЁЎеһӢйў„жөӢз»“жһңзҡ„жғ…еҪўеҲҶжһҗиЎЁпјҢд»Ҙзҹ©йҳөеҪўејҸе°Ҷж•°жҚ®йӣҶдёӯзҡ„и®°еҪ•жҢүз…§зңҹе®һзҡ„зұ»еҲ«дёҺеҲҶзұ»жЁЎеһӢйў„жөӢзҡ„зұ»еҲ«еҲӨж–ӯдёӨдёӘж ҮеҮҶиҝӣиЎҢжұҮжҖ»гҖӮе…¶дёӯзҹ©йҳөзҡ„иЎҢиЎЁзӨәзңҹе®һеҖјпјҢзҹ©йҳөзҡ„еҲ—иЎЁзӨәйў„жөӢеҖјпјҢдёӢйқўд»Ҙжң¬ж¬ЎжЎҲдҫӢдёәдҫӢпјҢзңӢдёӢзҹ©йҳөиЎЁзҺ°еҪўејҸпјҢеҰӮдёӢпјҡ

并дёҺеӣӣеұӮе…ЁиҝһжҺҘеұӮжЁЎеһӢиҝӣиЎҢеҜ№жҜ”пјҢе…ЁиҝһжҺҘеұӮзҡ„жЁЎеһӢз»“жһ„еҰӮдёӢпјҡ
е…¶з»“жһңеҰӮдёӢпјҡ
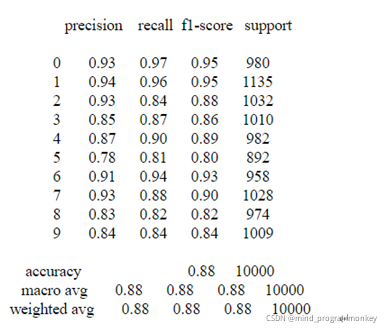
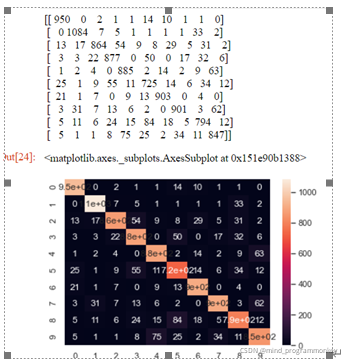
жҖ»д№ӢпјҢд»Һз»“жһңдёҠжқҘзңӢпјҢжңҖеҗҺз»ҸиҝҮдёҚж–ӯең°еҸӮж•°и°ғдјҳжңҖз»Ҳи®ӯз»ғеҮәдәҶдёҖдёӘеҲҶзұ»жӯЈзЎ®зҺҮеңЁ95%е·ҰеҸізҡ„жЁЎеһӢпјҢ并且йҖҡиҝҮе®һйӘҢиҜҒжҳҺдәҶжЁЎеһӢе…·жңүеҫҲејәзҡ„йІҒжЈ’жҖ§гҖӮ
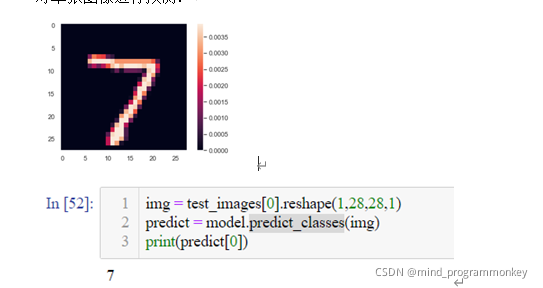
еҜ№еҚ•еј еӣҫеғҸиҝӣиЎҢйў„жөӢпјҡ
д»ҘдёҠжҳҜвҖңPythonдёӯеҰӮдҪ•е®һзҺ°MNISTжүӢеҶҷдҪ“иҜҶеҲ«вҖқиҝҷзҜҮж–Үз« зҡ„жүҖжңүеҶ…е®№пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒеёҢжңӣеҲҶдә«зҡ„еҶ…е®№еҜ№еӨ§е®¶жңүеё®еҠ©пјҢжӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ