您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
Hadoop
hadoop-1.2.1.tar.gz jdk-6u32-linux-x64.bin
Useradd -u 900 hadoop
Mv jdk1.6.0_32 /home/hadoop
Mv hadoop-1.2.1.tar.gz/home/hadoop
Chown hadoop.hadoop /home/hadoop -R
Su -hadoop
Ln -s jdk1.6.0_32 java
Tar zxf hadoop-1.2.1.tar.gz hadoop-1.2.1
Ln -s hadoop-1.2.1 hadoop
更改环境变量:
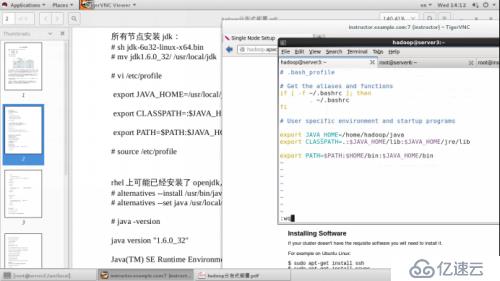
Vim /hadoop/conf/hadoop-env.sh
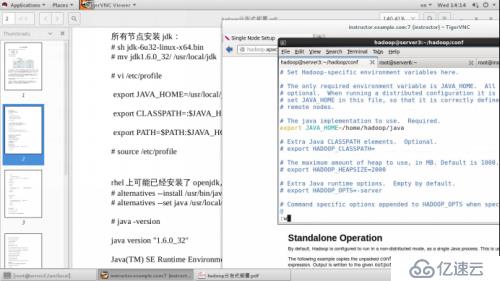
Cd /hadoop
Mkdir input
Cp conf/*.xml input
Bin/hadoop jar hadoop-examples-1.2.1.jar grep input output ‘dfs[a-z.]+’
设置无密码登陆:
Ssh-keygen
Ssh-copy-id 172.25.60.1
保证 master 到所有的 slave 节点都实现无密码登录
Cd ~/hadoop/conf
Vim slaves ---->172.25.60.1
Vim masters---->172.25.60.1
Vim core-site.xml 在configuration中间添加以下内容
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://172.25.60.1:9000</value>
</property>
</configuration>
Vim hdfs-site.xml 在configuration中间添加以下内容
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
Vim mapred-site.xml 在configuration中间添加以下内容
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>172.25.60.1:9001</value>
</property>
</configuration>
格式化一个新的分布式文件系统:
$ bin/hadoop namenode -format
启动 Hadoop 守护进程:
$ bin/start-all.sh
在各个节点查看 hadoop 进程:
$ jps
Hadoop 守护进程的日志写入到 ${HADOOP_HOME}/logs 目录
浏览 NameNode 和 JobTracker 的网络接口,它们的地址默认为:
NameNode – http://172.25.60.1:50070/
JobTracker – http://172.25.60.1:50030/
将输入文件拷贝到分布式文件系统:
$ bin/hadoop fs -put conf input
运行发行版提供的示例程序:
$ bin/hadoop jar hadoop-*-examples.jar grep input output 'dfs[a-z.]+'
查看输出文件:
将输出文件从分布式文件系统拷贝到本地文件系统查看:
$ bin/hadoop fs -get output output
$ cat output/*
或者
在分布式文件系统上查看输出文件:
$ bin/hadoop fs -cat output/*
完成全部操作后,停止守护进程:
$ bin/stop-all.sh
完全分布式(三个节点)server1 server2 server4:
在三个节点上安装 rpcbind nfs-utils 并打开rpcind nfs服务
Vim /etc/exports
/home/hadoop *(rw,all_squash,anonuid=900,anongid=900)
在slave2 4上添加用户 useradd -u 900 hadoop
mount 172.25.60.1:/home/hadoop/ /home/hadoop/
在1上分别进行ssh 连接 ssh 172.25.60.2ssh272.25.60.4
在master上:vim ~/hadoop/conf
Vim slaves
172.25.60.2
172.25.60.4
Vim hdfs-site.xml
<Value>1</value> ------> <Value>2</value>
(删除tmp------>格式化---->bin/start-dfs.sh----->bin/hadoop fs -put conf/ input----->bin/start-mapred.sh
bin/hadoop jar hadoop-examples-1.2.1.jar grep input output 'dfs[a-z.]+')
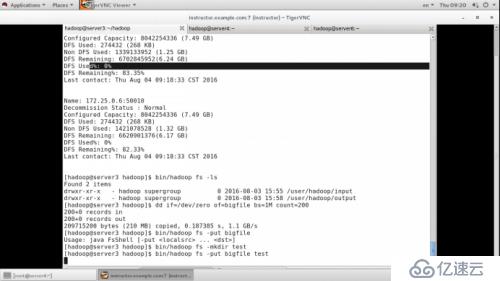
bin/hadoop dfsadmin-report:查看节点运行状态
bin/hadoop fs -ls :查看输出文件
添加一个节点文件:
在线添加节点:
添加用户 useradd -u 900 hadoop
mount 172.25.60.1:/home/hadoop/home/hadoop
su - hadoop
vim slaves加入该节点 ----->>172.25.60.5
bin/hadoop-daemon.sh start datanode
bin/hadoop-daemon.sh start tasktracker
在线删除节点:
先做数据迁移:
在server上:vim mapred-site.xml
<property>
<name>dfs.hosts.exclude</name>
<value>/home/hadoop/hadoop/conf/hostexclude</value>
</property>
Vim hadoop/hadoop/conf/hostexclude------->172.25.60.4
Bin/hadoop dfsadmin -refreshNodes ####刷新节点
回收站功能:
vimcore-site.xml添加以下:
<property>
<name>fs.trash.interval</name>
<value>1440</value> 1440=60*24
</property>
实验:bin/hadoop fs -rm input/hadoop-env.sh
bin/hadoop fs -ls input 查看是否删除
bin/hadoop fs -ls 此时新增目录 .Trash
bin/hadoop fs -ls .Trash/Current/user/hadoop/input
将此文件移回原目录即可恢复
bin/hadoop fs -mv .Trash/Current/user/hadoop/input/hadoop-env.sh input
优化:


更新hadoop至2.6版本
删除之前的链接,解压hadoop-2.6.4.tar.gz jdk-7u79-linux-x64.tar.gz到hadoop家目录,并更改权限为hadoop.hadoop进入hadoop用户,链接成hadoop和java,进入hadoop/etc/hadoop/
vim hadoop-env.sh export JAVA_HOME=/home/hadoop/java
cd /hadoop/etc/hadoop
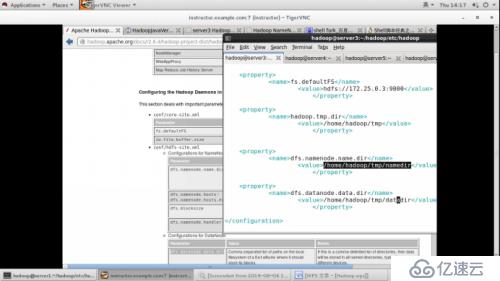
vim core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://172.25.60.1:9000</value>
</property>
vim hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
vim yarn-env.sh
# some Java parameters
export JAVA_HOME=/home/hadoop/java
cp mapred-site.xml.template mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
vim yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
vim slaves
172.25.60.4
172.25.60.5
bin/hdfs namenode -format
sbin/start-dfs.sh
bin/hdfs dfs -mkdir /user
bin/hdfs dfs -mkdir /user/hadoop
bin/hdfs dfs -put etc/hadoop input
sbin/start-yarn.sh
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.4.jar grep input output 'dfs[a-z.]+'
访问 172.25.60.1:50070 172.25.60.1:8088
##########替换lib下文件为64位(不更改的话启动时会有warn警告)
mv hadoop-native-64-2.6.0.tar /home/hadoop/hadoop/lib/native
tarxf hadoop-native-64-2.6.0.tar
###########指定节点目录
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。