您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章给大家分享的是有关Python中如何使用PyTorch实现WGAN的内容。小编觉得挺实用的,因此分享给大家做个参考,一起跟随小编过来看看吧。
在GAN中,有两个模型,一个是生成模型,用于生成样本,一个是判别模型,用于判断样本是真还是假。但由于在GAN中,使用的JS散度去计算损失值,很容易导致梯度弥散的情况,从而无法进行梯度下降更新参数,于是在WGAN中,引入了Wasserstein Distance,使得训练变得稳定。本文中我们以服从高斯分布的数据作为样本。
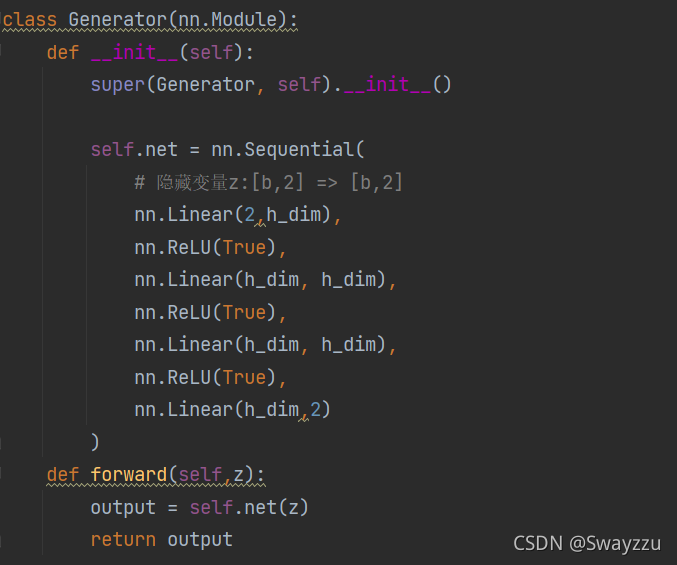
这里从2维数据,最终生成2维,主要目的是为了可视化比较方便。也就是说,在生成模型中,我们输入杂乱无章的2维的数据,通过训练之后,可以生成一个赝品,这个赝品在模仿高斯分布。
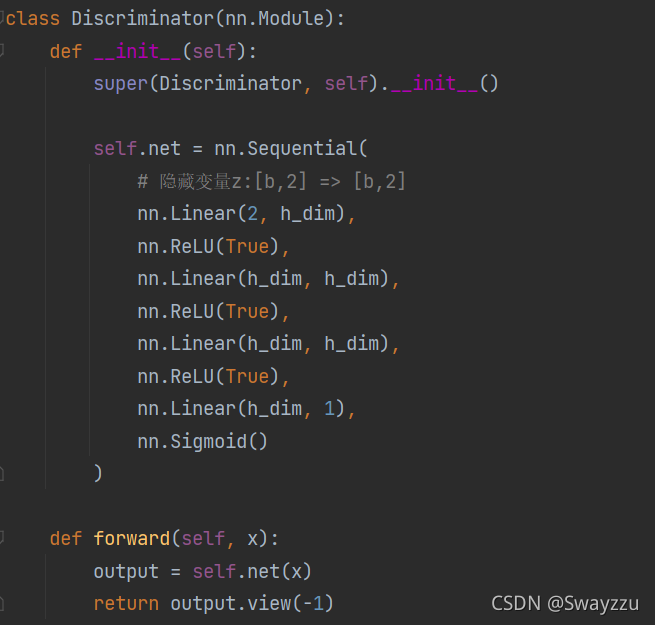
判别器同样输入的是2维的数据。比如我们上面的生成器,生成了一个2维的赝品,输入判别器之后,它能够最终输出一个sigmoid转换后的结果,相当于是一个概率,从而判别,这个赝品到底能不能达到以假乱真的程度。
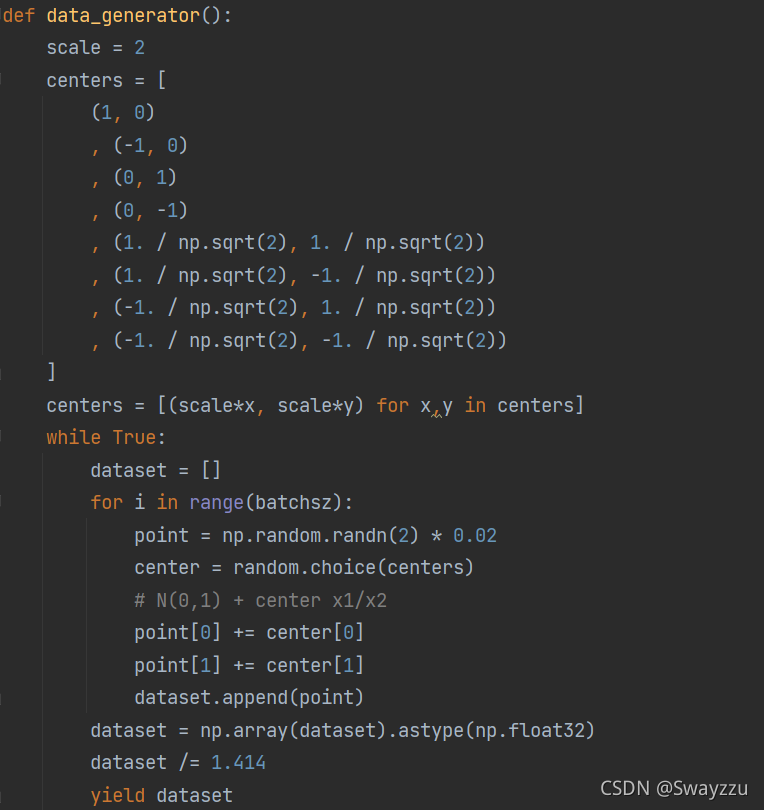
由于我们使用的是高斯模型,因此,直接生成我们需要的数据即可。我们在这个模块中,生成8个服从高斯分布的数据。
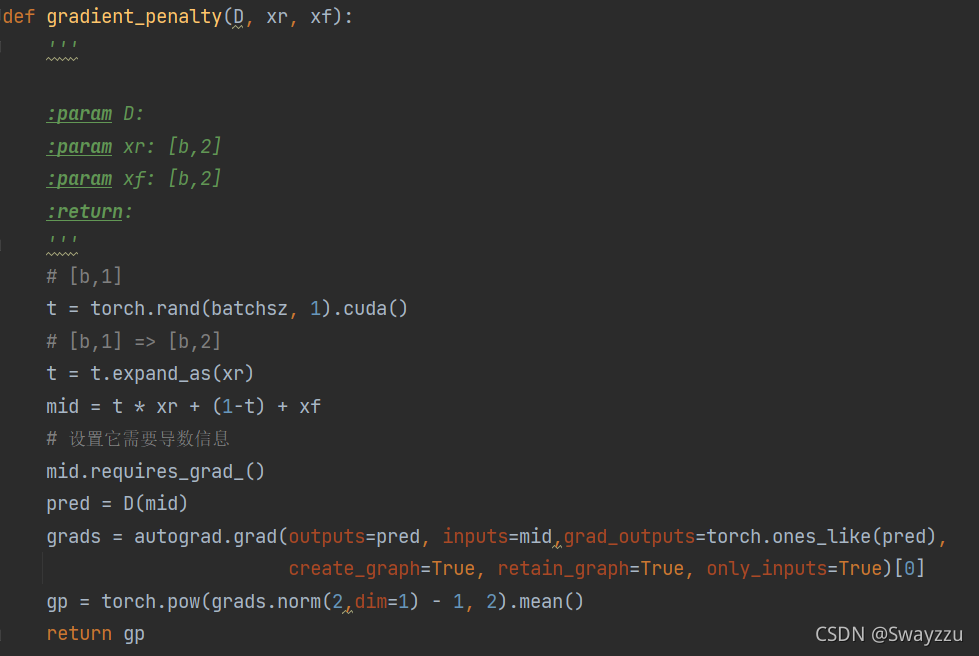
由于使用JS散度去计算损失的时候,会很容易出现梯度极小,接近于0的情况,会使得梯度下降无法进行,因此计算损失的时候,使用了Wasserstein Distance,去度量两个分布之间的差异。因此我们假如了梯度惩罚的因子。
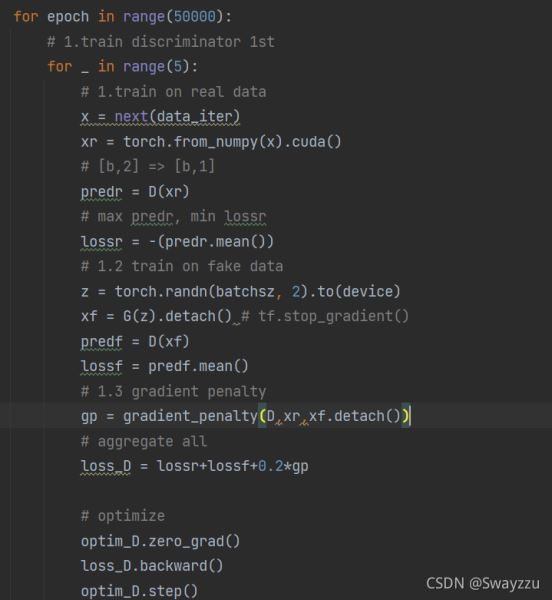
其中,梯度惩罚的模块如下:
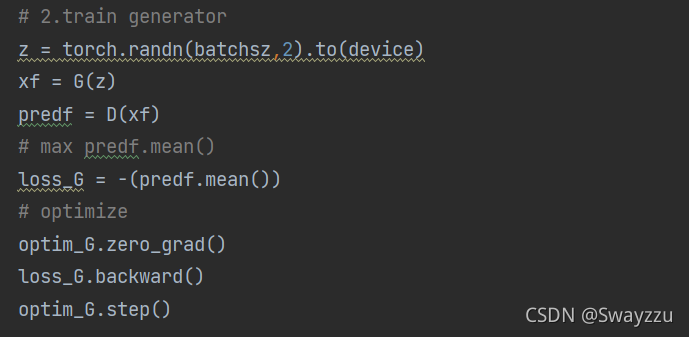
这里的训练是紧接着判别器训练的。也就是说,在一个周期里面,先训练判别器,再训练生成器。
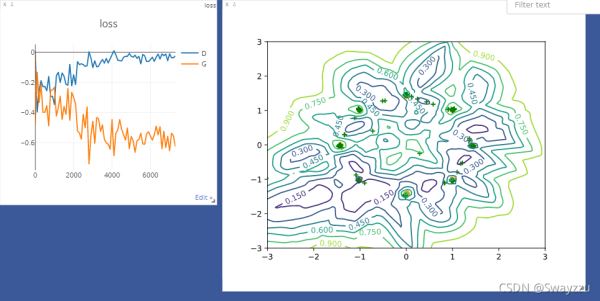
通过visdom可视化损失值,通过matplotlib可视化分布的预测结果。
感谢各位的阅读!关于“Python中如何使用PyTorch实现WGAN”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,让大家可以学到更多知识,如果觉得文章不错,可以把它分享出去让更多的人看到吧!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。