您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
小编给大家分享一下C++string底层框架的示例分析,希望大家阅读完这篇文章之后都有所收获,下面让我们一起去探讨吧!
主要说明浅拷贝和深拷贝的优缺点,以及仿写string类的逻辑并分析实现过程
先来上一组代码
class string{
public:
string(char* str="")
:_size(strlen(str))
,_capacity(_size)
{
_str = new char[_capacity+1];
strcpy(_str, str);
}
char& operator[](const char& pos) const {
return _str[pos];
}
~string(){
delete[] _str;
_str = nullptr;
_size = _capacity = 0;
}
private:
char* _str;
size_t _size;
size_t _capacity;
};void Test1(){
string s1("never gonna give you up");
string s2 = s1;
s2[0] = 'Y';
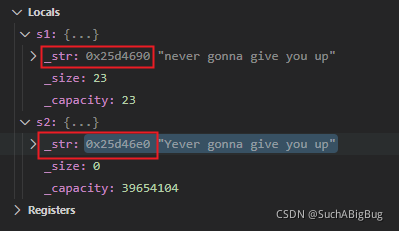
}当我们把s1拷贝给s2,这里是深拷贝还是浅拷贝呢?先不说答案我们debug看一下
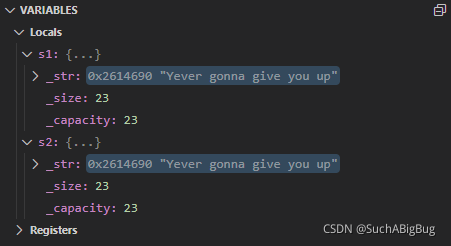
一目了然,这里的s1和s2为同一个地址
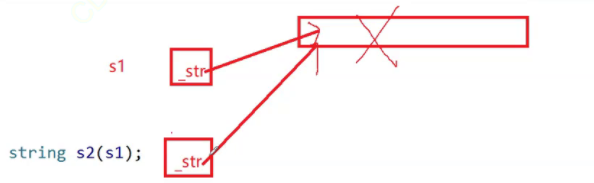
那么当我们改变s2[0]的值时,s1[0]也随之改变,那么还是给人一种藕断丝连的感觉没有完全独立拷贝,这就是浅拷贝,相信我们也看到了浅拷贝带来的弊端
其次,当我们调用析构函数也会出现问题,由于他们指向的是同一块空间,s2会先析构将里面的数组delete并置空
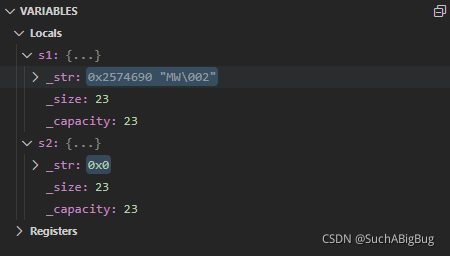
接着s1调用析构函数时就会报错,所以不能指向同一块空间
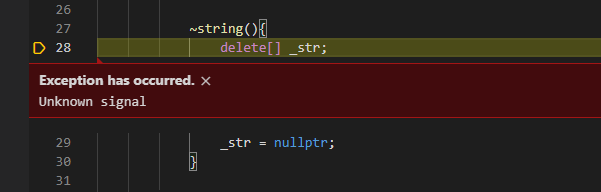
总结一下浅拷贝问题:
这块空间会在两个对象析构函数被delete两次一个对象修改会影响另外一个对象
深拷贝怎么实现?
string(const string& s) //函数重载
:_str(new char[strlen(s._str)+1])
{
strcpy(this->_str, s._str);
}我们重新new一个空间给s2,下面下图可以看到s1和s2在堆上不再是同一个空间
这里第一个参数是this被匿名了,为了方面看,我把this加了进去
和浅拷贝区别就在于指明了当前字符串需重新分配空间和重新赋值到新开的这组新空间,这里的深拷贝就不会出现上面的问题,当我们改变s2[0]的值,s1[0]不会跟着改变
赋值重载的方式解决浅拷贝问题
string& operator=(string& s){
if(this != &s){
char* tmp = new char[strlen(s._str)+1];
delete[] _str; //删除this原来的内容
_str = tmp; //将新空间赋给_str
strcpy(_str, s._str);
_size = _capacity = strlen(s._str);
_str[_size] = '\0';
}
return *this;
}上面都为传统写法,通过new开辟一组新的堆空间,和现代写法的思路是有区别的
这里是重新构造一个临时string tmp变量新开了一组空间,然后再swap把两者进行交换,等于this->_str获得了这个新空间,最后把不需要的空间自动析构
string (const string& str)
:_str(nullptr)
{
string tmp(str);
swap(_str, tmp._str);
}
//这组没有用到引用,因为形参自动调用拷贝构造
string& operator=(string t)
{
swap(_s,t._s);
return *this;
}那么是不是深拷贝一定就是最好的呢?
答案是不一定,写时拷贝在浅拷贝基础上增加了引用计数方式,换句话说有多少个对象指向这块空间,计数就会++,那么只有当某个对象去写数据时,那个对象才会进行深拷贝,然后计数–
这本质上是写的时候一种延迟深拷贝,但如果拷贝对象后没有人进行修改,没有进行深拷贝重开一块空间,也就顺理成章的提高效率。但是实际应用场景中不是很理想
这里私有成员结构就类似顺序表,当我们增加或删除数据时需要记录当前的信息,以及是否需要扩容等,npos用于查找是否有此字符,默认返回-1
class string{
public:
private:
char* _str;
size_t _size;
size_t _capacity;
static const size_t npos;
};
const size_t string::npos = -1;void Test2(){
string s1("helloworld");
string s2(5, 'g');
string();
}上面的函数名都构成函数重载,目前实现了三种常见的
string(const char* str="")
:_size(strlen(str))
,_capacity(_size)
{
_str = new char[_capacity+1];
strcpy(_str, str);
}第一种最普遍,直接将字符串赋给s1即可
string(size_t n, char c)
:_size(n)
,_capacity(_size)
{
_str = new char[ _size + 1];
for(size_t i=0; i<n; ++i) _str[i] = c;
}第二种可以创建一组n个相同的字符
string()
:_str(new char[1])
,_size(0)
,_capacity(0)
{
*_str = '\0';
}最后一种创建一个空函数,里面并不为空,默认放一个斜杠零
~string(){
delete[] _str;
_str = nullptr;
_size = _capacity = 0;
}用于释放空间,当我们new完一组空间后需要手动创建析构函数
下列赋值重载中,第一个支持读和写
char& operator[](size_t pos){
return _str[pos];
}第二个不支持写
const char& operator[](size_t pos) const{
return _str[pos];
}这里我把赋值重载都给列出来,push_back函数在下面会提到
//可读可写
String& operator+=(char ch){
push_back(ch);
return *this;
}下列的赋值重载,实现依次比较数组中值的大小
//按照ASCII码进行比较
//s1 > s2 ?
//"abc" "abc" false
//"abc" "ab" true
//"ab" "abc" false
bool operator>(const string& s1, const string& s2){
size_t i1 = 0, i2 =0;
while(i1 < s1.size() && i2 < s2.size()){
if(s1[i1] > s2[i2]){
return true;
}else if(s1[i1] < s2[i2]){
return false;
}else{
++i1;
++i2;
}
}
if(i1 == s1.size()){
return false;
}else{
return true;
}
return true;
}
bool operator==(const string& s1, const string& s2){
size_t i1 = 0, i2 =0;
while(i1 < s1.size() && i2 < s2.size()){
if(s1[i1] > s2[i2]){
return true;
}else if(s1[i1] < s2[i2]){
return false;
}else{
++i1;
++i2;
}
}
if(i1 == s1.size() && i2 == s2.size()){
return true;
}else{
return false;
}
}
bool operator!=(const string& s1, const string& s2){
return !(s1==s2);
}
bool operator>=(const string& s1, const string& s2){
return (s1>s2 || s1==s2);
}
bool operator<(const string& s1, const string& s2){
return !(s1 >= s2);
}
bool operator<=(const string& s1, const string& s2){
return !(s1>s2);
}
String operator+(const string& s1, const string& str){
String ret = s1;
ret += str;
return ret;
}resize分为三种情况
当n小于等于size,则size等于n
当n大于size但小于capacity,无法添加数据
当n大于capacity时,先增容,然后从size开始填数据,填到n
void reserve(size_t n){
if(n > _capacity){
char* tmp = new char[n+1]; //开一个更大的空间
strcpy(tmp, _str); //进行拷贝,然后释放此空间
delete[] _str;
_str = tmp; //然后指向新开的空间
}
_capacity = n;
}
void resize(size_t n, char ch='\0'){
//大于,小于,等于的情况
if(n <= _size){
_size = n;
_str[_size] = '\0';
}else{
if(n > _capacity){ //空间不够,先增容
reserve(n);
for(size_t i = _size; i<n; i++){ //从size开始填数据,填到n
_str[i] = ch;
}
_size = n;
_str[_size] = '\0';
}
}
}在字符串的最后增加一个字符
void push_back(char c){
if(_size >= _capacity){
//这种如果size和capacity都为0,那么计算出的2倍w也为0,最后调用析构的时候报错
//reserve(_capacity * 2);
size_t newCapacity = _capacity == 0 ? 4 : _capacity*2;
reserve(newCapacity);
}
_str[_size] = c;
++_size;
_str[_size] = '\0';
}在字符串的最后增加一串字符,这里需要注意判断原本容量的大小是否比新增的字符串容量要小,如果是就需要新reserve一组更大的空间
void append(const char* s){
size_t len = strlen(s);
if(_size + len >= _capacity){
reserve(_size + len);
}
strcpy(_str + _size, s); //把这个字符串给拷贝过去
_size += len;
}在pos位置,插入字符或者字符串,这里我们实际应用中,不推荐使用,因为数组数据过于庞大时,在中间插入后,pos后面的数据都需要依次向后挪动
string& insert(size_t pos, char ch){
assert(pos<=_size); //pos不能超出此范围
if(_size == _capacity){
size_t newcapacity = _capacity == 0 ? 4 : _capacity*2;
reserve(newcapacity);
}
size_t end = _size+1;
while( end > _size){
_str[end-1] = _str[end];
--end;
}
_str[_size] = ch;
++_size;
return *this;
}
string& insert(size_t pos, const char* str){
assert(pos <= _size);
size_t len = strlen(str);
if(len == 0){
return *this;
}
if(len + _size > _capacity){
reserve(len + _size);
}
size_t end = _size + len;
while(end >= pos + len){
_str[end] = _str[end-len];
--end;
}
for(size_t i= 0; i<len; ++i){
_str[pos + i] = str[i];
}
_size += len;
return *this;
}String& erase(size_t pos, size_t len=npos){
assert(pos < _size);
//1. pos后面删完
//2. pos后面删一部分
if(len == npos || len+pos >= _size){
_str[pos] = '\0';
_size = pos;
}else{
//删一部分
strcpy(_str + pos, _str + pos + len);
_size -= len;
}
return *this;
}查找匹配的第一个字符,返回其下标
//查找,直接返回字符的下标位置
size_t find(char ch, size_t pos=0){
for(size_t i = pos; i<_size; ++i){
if(_str[i] == ch ){
return i;
}
}
return npos;
}查找字符串,这里就直接调用C语言中的strstr函数进行暴力匹配查找
size_t find(const char* sub, size_t pos=0){
const char* p = strstr(_str+pos, sub);
if(p == nullptr){
return npos;
}else{
return p-_str;
}
}前面不加const的支持数据修改
初次用迭代器玩不明白,其实刨开看也没有特别神奇,只不过是封装起来了
typedef char* iterator;
typedef const char* const_iterator;
iterator begin(){
return _str;
}
iterator end(){
return _str + _size;
}
const_iterator begin() const{
return _str;
}
const_iterator end() const{
return _str + _size;
}//流插入
ostream& operator<<(ostream& out, const String& s){
for(size_t i = 0; i<s.size(); ++i){
out << s[i];
}
return out;
}
//流提取
istream& operator>>(istream& in, String& s){
s.clear();
char ch;
// in >> ch; 遇到换行会自动停止
ch = in.get();
while(ch != ' ' && ch != '\n'){
s += ch; //提取字符串到这个String s字符串中去
ch = in.get();
}
return in;
}//上面的是遇到空格就停止了然后传给cout,而下面我们要实现一行哪怕中间有空格
istream& getline(istream& in, String& s){
s.clear();
char ch;
ch = in.get();
// while(ch != ' ' && ch != '\n'){
while(ch != '\n'){ //遇到空格不结束
s += ch;
ch = in.get();
}
return in;
}我们可以看到流提取和getline的最大区别在于,流提取遇到空格后,就直接结束了
而getline不一样,函数里面忽略判断空格条件,而只保留判断换行符
void test1(){
// cin >> s1;
// cout << s1 << endl; //注意如果有空格的hello world,hello打印出来了但是 world check the rythm还在缓冲区
getline(cin, s1); //打印带有空格的一个字符串
cout << s1 <<endl;
}看完了这篇文章,相信你对“C++string底层框架的示例分析”有了一定的了解,如果想了解更多相关知识,欢迎关注亿速云行业资讯频道,感谢各位的阅读!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。