您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
1.RDD基础:
Spark中RDD是不可变的分布式对象集合。每个RDD被分为多个分区,这些分区运行在集群中的不同节点上。RDD可以包含任意类型的对象(甚至可以是自定义的)。
前面讲到,Spark包含转化操作和行动操作。Spark只会惰性计算这些RDD。它们只有第一次在一个行动操作中用到时,才会真正计算。默认情况下,Spark的RDD会在你每次对它们进行行动操作时重新计算。如果想在多个行动操作中重用同一个RDD,可以使用RDD.persist()让Spark把这个RDD缓存(内存或者磁盘)下来。
2.创建RDD:
Spark提供2种创建方式:
(1)读取外部数据集:之前的sc.textFile()就属于这种类型。更加常用的方式。
(2)在驱动器程序中对一个集合(list、Set等)进行并行化,要使用SparkContext.parallelize()方法。
3.RDD操作:
RDD主要分成数据类型RDD和键值对RDD。有一些操作可以适用于所有类型的RDD,这时候可以直接创建JavaRDD对象,例如map(),filter()等。有些操作只适用于数据类型的RDD,例如 ,这时候创建JavaDoubleRDD对象。有些操作只适用于键值对RDD,例如 ,这时候创建JavaPairRDD对象。
3.1 转化操作:
3.1.1 谱系图:
通过转化操作,从已有的RDD中派生出新的RDD,Spark会使用谱系图来记录这些不同RDD之间的依赖关系。如下图所示:
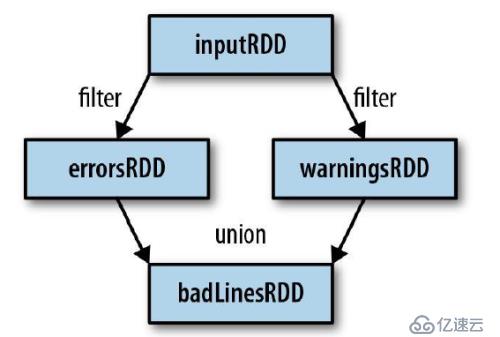
3.1.2 :
基本的转化操作(map、flatMap、filter、distinct、sample),假设RDD的数据{1, 2, 3, 3}:
RDD的集合操作(union、intersection、subtract、cartesian),两个RDD分别是{1,2,3}、{3,4,5}:
| 函数名 | 作用 | 例子 | 运行结果 |
| map() | Apply a function to each element in the RDD and return an RDD of the result. | rdd.map(x => x +1) | {2, 3, 4, 4} |
| flatMap() | Apply a function to each element in the RDD and return an RDD of the contents of the iterators returned. Often used to extract words. | rdd.flatMap(x =>x.to(3)) | {1, 2, 3, 2, 3, 3, 3} |
| filter() | Return an RDD consisting of only elements that pass the condition passed to filter(). | rdd.filter(x => x!= 1) | {2, 3, 3} |
| distinct() | Remove duplicates. | rdd.distinct() | {1, 2, 3} |
| sample(withReplacement,fraction, [seed]) | Sample an RDD, with or without replacement. | rdd.sample(false,0.5) | 不确定 |
| union() | Produce an RDD containing elements from both RDDs. | rdd.union(other) | {1, 2, 3, 3, 4, 5} |
| intersection() | RDD containing only elements found in both RDDs. | rdd.intersection(other) | {3} |
| subtract() | Remove the contents of one RDD (e.g., remove training data). | rdd.subtract(other) | {1, 2} |
| cartesian() | Cartesian product with the other RDD. | rdd.cartesian(other) | {(1, 3), (1, 4),… (3, 5)} |
4.给Spark传递函数:
大多数的转化操作和一部分行动操作,都需要给Spark方法传递函数。在java中,函数式实现了包org.apache.spark.api.java.function下面任意一个接口的类。该包下面有许多接口,下面是一些基础接口:
| 函数名 | 需要实现的方法 | 用法 |
| Function<T, R> | R call(T) | Take in one input and return one output, for use with operations like map()and filter(). |
Function2<T1, T2,R> | R call(T1, T2) | Take in two inputs and return one output, for use with operations like aggregate() or fold(). |
| FlatMapFunction<T,R> | Iterable<R> call(T) | Take in one input and return zero or more outputs, for use with operations like flatMap(). |
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。